







 本文是作者殷剑宏关于第三届拍拍贷“魔镜杯”大赛的参赛总结,分享了NLP语义相似度任务的介绍、数据集分析、模型构建、数据增强和融合策略。比赛中,作者采用了深度学习模型,包括LSTM、CNN和交互层,通过数据增强和模型融合提升性能。此外,文中还探讨了个人经验和技巧,如两次训练、10Fold CV等。
本文是作者殷剑宏关于第三届拍拍贷“魔镜杯”大赛的参赛总结,分享了NLP语义相似度任务的介绍、数据集分析、模型构建、数据增强和融合策略。比赛中,作者采用了深度学习模型,包括LSTM、CNN和交互层,通过数据增强和模型融合提升性能。此外,文中还探讨了个人经验和技巧,如两次训练、10Fold CV等。

因为微信外链限制,读者可以在公众号AI圈终身学习(ID:AIHomie)首页回复“2018语义相似度”,或者复制文中的链接在浏览器中打开外链。
目录
- 语义相似度任务介绍
- 数据介绍
- 模型介绍
- 数据增强、Finetune与模型融合
- 个人经验
- Trick
- 总结
作者介绍
殷剑宏,江湖人称Yin叔,业余做各种数据竞赛,喜欢NLP和交通类的竞赛。以下是部分竞赛参赛经历:
2016年 DataCastle 微博热度预测竞赛 第二名
2017年 DataCastle&成都市政府 智慧中国杯交通算法赛 第二名
2017年 Biendata&中国人工智能学会 知乎看山杯机器学习挑战赛 第七名
2017年 Biendata&中国人工智能学会 摩拜杯算法挑战赛 第一名
2018年 Biendata神州优车UAI数据大赛 第二名
2018年 Datafountain云移杯景区口碑评价分值预测 第一名
2018年 拍拍贷第三届魔镜杯大赛 第九名
2018年 DataCastle 华录杯 公交线路准点预测 第一名
2018年 DataCastle 达观杯 文本智能处理挑战赛 第五名
一、语义相似度任务介绍
第三届“魔镜杯”由拍拍贷智慧金融研究院主办,总奖池高达10万美金,是一个问题相似度问题。“问题相似度计算”这个问题,顾名思义,就是判断两个问题是否表达相同的含义。
比如用户询问:“彩虹年化多少?”就和知识库的“彩虹产品收益率”相似,从而app可以触发相应的业务。
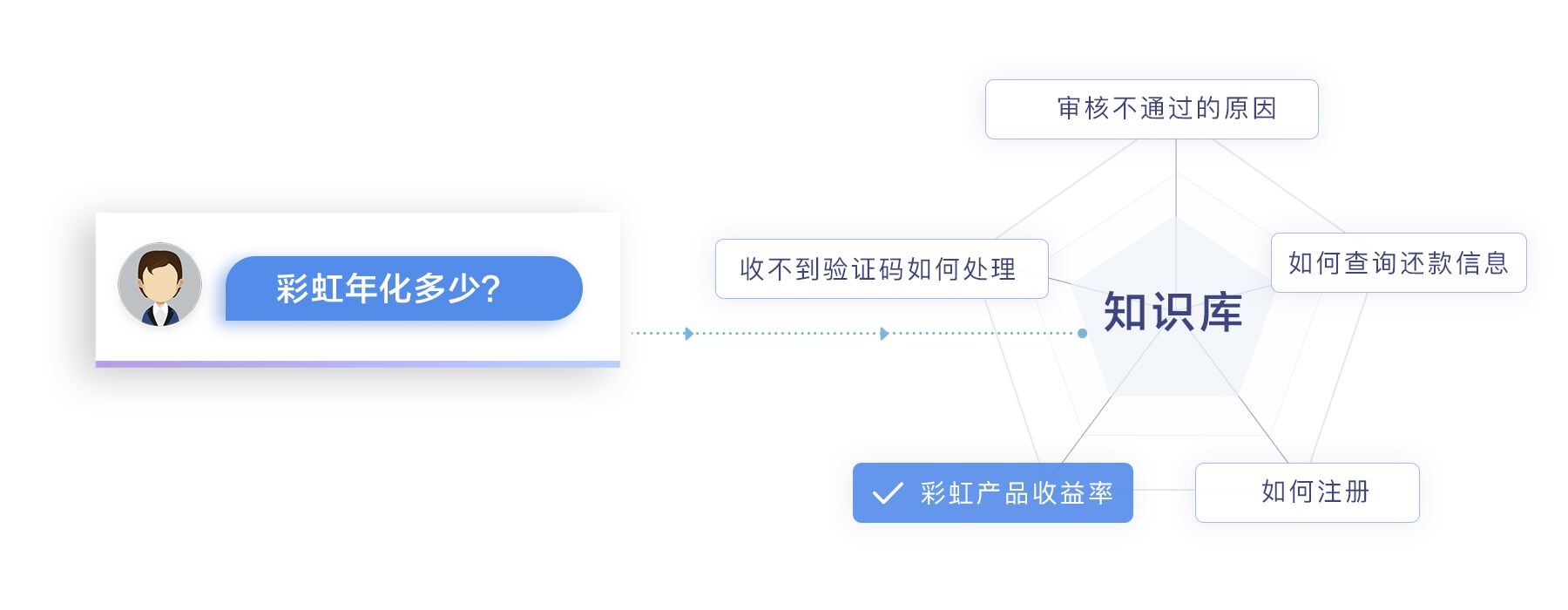
语义相似度是NLP领域很重要的一个任务,有非常大的应用价值。目前它常用于:
- 通过标注数据找寻新的相似未标注数据,从而扩充训练集(和本题无关)
- 智能客服,计算客户提出的问题与知识库中问题的相似度(本赛题)
不论是在这个比赛之前,还是这个比赛之后,国内外竞赛平台都有很多类似题目,比如:
- Kaggle Quora
- 天池 CIKM
- 蚂蚁金服
笔者在2018年也投入了很多精力研究这个任务,因此有一些心得体会。为了巩固自身知识体系,并且可以帮助一些对NLP语义相似度比赛或任务感兴趣的朋友,我在DataCastle产出了自己的视频、PPT和开源代码。如果本文看得不过瘾的朋友可以作为额外的知识补充。
我比较高兴的是,在之后的比赛中,有选手也参考这个课程取得了不错的成绩。
感兴趣的同学可以看看,获取方式已经在文首给出。
二、数据介绍
2.1 任务定义
魔镜杯比赛的任务非常明确,就是给定一个句子q1和另一个句子q2,系统自动判断这两个句子的含义:
- 相同(label=1)
- 不同(label=0)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









