







文章目录
1、安装P40显卡驱动
1.1 查看机器上有哪些显卡
lspci | grep -i vga
lspci | grep -i nvidia

1.2 禁用nouveau
nouveau是N卡的开源驱动,linux会自动安装,不是NVIDIA官方的,安装官方驱动前需先禁止掉它。
执行
lsmod | grep nouveau
如果有输出,说明未禁用;如果没有输出,说明已禁用。
如果未禁用则执行如下操作:
vim /usr/lib/modprobe.d/dist-blacklist.conf
注释掉 blacklist nvidiafb 这一行,然后添加下面两行:
blacklist nouveau
options nouveau modeset=0
然后重建initramfs image,执行下面的命令:
mv /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r)-nouveau.img
dracut /boot/initramfs-$(uname -r).img $(uname -r)
重启系统:
reboot
再执行:
lsmod | grep nouveau

如果没有输出,说明已禁用。
1.3 安装依赖
yum install kernel-devel kernel-headers gcc dkms gcc-c++
- 可能出现问题的解决(是因为我安装了anaconda3引起的)
(base) [root@clang ~]# yum install kernel-devel kernel-headers gcc dkms gcc-c++
There was a problem importing one of the Python modules
required to run yum. The error leading to this problem was:
/home/anaconda3/lib/liblzma.so.5: version `XZ_5.1.2alpha' not found (required by /lib64/librpmio.so.3)
Please install a package which provides this module, or
verify that the module is installed correctly.
It's possible that the above module doesn't match the
current version of Python, which is:
2.7.5 (default, Jun 20 2023, 11:36:40)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)]
If you cannot solve this problem yourself, please go to
the yum faq at:
http://yum.baseurl.org/wiki/Faq
找了一些方案是做软链接,但是这个问题修复之后,还会出现其他库找不到的情况。这时简单的处理方法就是先卸载anaconda3,安装完之后再重装上。
1.4 安装驱动
官方下载页,根据你的显卡型号搜索。我的显卡是Tesla P4,用的是CUDA 11.2,所以这是我的型号的下载链接。

下载完后执行:
chmod +x NVIDIA-Linux-x86_64-460.106.00.run
./NVIDIA-Linux-x86_64-460.106.00.run --kernel-source-path=/usr/src/kernels/3.10.0-1160.83.1.el7.x86_64 -no-x-check --no-opengl-files
# --kernel-source-path的值是装完依赖后才有这个路径
# 远程安装会检测x server,要让它不检测
# 不安装opengl,因为安装opengl,CentOS界面UI不能正常启动
–kernel-source-path=/usr/src/kernels/3.10.0-1160.83.1.el7.x86_64 参数的路径需要根据自己内核的目录来修改
- 安装过程中
Would you like to register the kernel module sources with DKMS? 选yes(服务器选yes,本地选no)
Install NVIDIA’s 32-bit compatibility libraries? 选yes
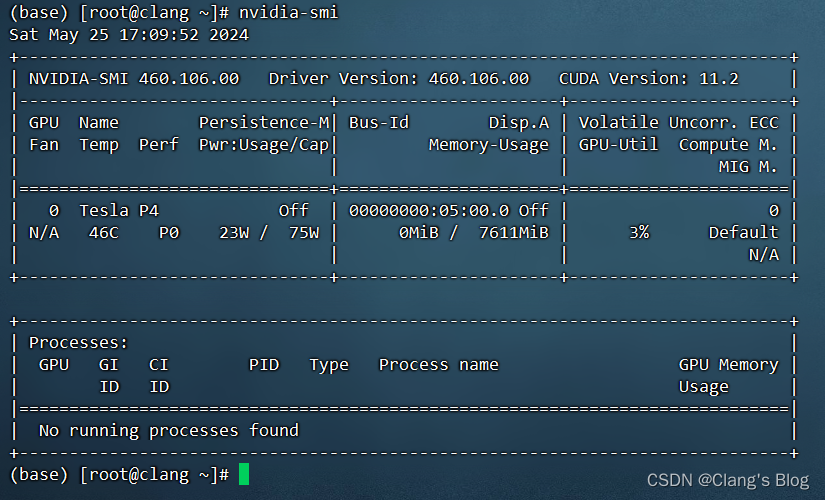
安装完成后执行:
nvidia-smi
如果有输出,说明驱动已安装。
- 安装过程中可能出现异常的解决
在安装驱动的过程中,我遇到了找不到内核的问题,这时可以通过yum命令安装相应内核来解决,可能用到的命令(需根据自己报错来修改内核版本名称)
sudo yum install linux-headers-3.10.0-1160.92.1.el7.x86_64
sudo yum install kernel-devel-3.10.0-1160.92.1.el7.x86_64
2、安装CUDA
2.1 安装
官方下载页,我下载的是11.2.2的run版本。
chmod +x cuda_11.2.2_460.32.03_linux.run
./cuda_11.2.2_460.32.03_linux.run --no-opengl-libs
安装时,X表示选中,即安装,空白表示不选中,即不安装。驱动前面已经安装了,不用再安装。设成下面的样子,再Install。
CUDA Installer
- [ ] Driver
[ ] 460.32.03
+ [X] CUDA Toolkit 11.2
[X] CUDA Samples 11.2
[X] CUDA Demo Suite 11.2
[X] CUDA Documentation 11.2
Options
Install
安装完后配置环境变量:
vim /etc/profile
# 添加下面两行,路径要和上图中一样
export PATH=/usr/local/cuda-11.2/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.2/lib64:$LD_LIBRARY_PATH
# 保存并重新加载
source /etc/profile
2.2 测试是否安装成功
终端输入cuda并连按两次tab,若有候选命令,则再执行nvcc --version,有输出版本信息就是安装成功。


3、安装cuDNN
3.1 安装
官方下载页,在页面内下载针对前面匹配的11.x版本,下载时会提示登录NVIDIA账号,注册账号并登录就可以下载了,下载后执行下面的命令:
tar -xvf cudnn-linux-x86_64-8.7.0.84_cuda11-archive.tar.xz
# 以下三行命令from https://docs.nvidia.com/deeplearning/cudnn/install-guide/index.html
# 参考链接中这一步复制的文件和官方文档中不太一样
cp cudnn-*-archive/include/cudnn*.h /usr/local/cuda/include
cp -P cudnn-*-archive/lib/libcudnn* /usr/local/cuda/lib64
chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
3.2 测试是否安装成功
新建一个cudnn_test.cu文件:
#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>
#include <cudnn.h>
#define CHECK_CUDA_ERROR(call) { \
cudaError_t error = call; \
if (error != cudaSuccess) { \
printf("CUDA error: %s, line %d\n", cudaGetErrorString(error), __LINE__); \
exit(1); \
} \
}
#define CHECK_CUDNN_ERROR(call) { \
cudnnStatus_t status = call; \
if (status != CUDNN_STATUS_SUCCESS) { \
printf("CUDNN error: %s, line %d\n", cudnnGetErrorString(status), __LINE__); \
exit(1); \
} \
}
void initialize(float *matrix, int size) {
for (int i = 0; i < size; ++i) {
matrix[i] = rand() / (float)RAND_MAX; // Initialize with random values
}
}
int main() {
const int N = 1024; // Matrix size
const int K = 1024;
const int M = 1024;
// Allocate memory on host
float *A = (float*)malloc(N * K * sizeof(float));
float *B = (float*)malloc(K * M * sizeof(float));
float *C = (float*)malloc(N * M * sizeof(float));
// Initialize matrices
initialize(A, N * K);
initialize(B, K * M);
// Allocate memory on device
float *d_A, *d_B, *d_C;
CHECK_CUDA_ERROR(cudaMalloc(&d_A, N * K * sizeof(float)));
CHECK_CUDA_ERROR(cudaMalloc(&d_B, K * M * sizeof(float)));
CHECK_CUDA_ERROR(cudaMalloc(&d_C, N * M * sizeof(float)));
// Copy data from host to device
CHECK_CUDA_ERROR(cudaMemcpy(d_A, A, N * K * sizeof(float), cudaMemcpyHostToDevice));
CHECK_CUDA_ERROR(cudaMemcpy(d_B, B, K * M * sizeof(float), cudaMemcpyHostToDevice));
// Create CUDNN context
cudnnHandle_t cudnn;
CHECK_CUDNN_ERROR(cudnnCreate(&cudnn));
// Define tensor descriptors
cudnnTensorDescriptor_t descA, descB, descC;
CHECK_CUDNN_ERROR(cudnnCreateTensorDescriptor(&descA));
CHECK_CUDNN_ERROR(cudnnCreateTensorDescriptor(&descB));
CHECK_CUDNN_ERROR(cudnnCreateTensorDescriptor(&descC));
CHECK_CUDNN_ERROR(cudnnSetTensor4dDescriptor(descA, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, 1, N, K, 1));
CHECK_CUDNN_ERROR(cudnnSetTensor4dDescriptor(descB, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, 1, K, M, 1));
CHECK_CUDNN_ERROR(cudnnSetTensor4dDescriptor(descC, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, 1, N, M, 1));
// Define convolution descriptors (in this case, it's just matrix addition)
cudnnOpTensorDescriptor_t opDesc;
CHECK_CUDNN_ERROR(cudnnCreateOpTensorDescriptor(&opDesc));
CHECK_CUDNN_ERROR(cudnnSetOpTensorDescriptor(opDesc, CUDNN_OP_TENSOR_ADD, CUDNN_DATA_FLOAT, CUDNN_NOT_PROPAGATE_NAN));
// Perform the operation
float alpha = 1.0f;
float beta = 0.0f;
CHECK_CUDNN_ERROR(cudnnOpTensor(cudnn, opDesc, &alpha, descA, d_A, &alpha, descB, d_B, &beta, descC, d_C));
// Copy the result back to host
CHECK_CUDA_ERROR(cudaMemcpy(C, d_C, N * M * sizeof(float), cudaMemcpyDeviceToHost));
// Cleanup
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
cudnnDestroyTensorDescriptor(descA);
cudnnDestroyTensorDescriptor(descB);
cudnnDestroyTensorDescriptor(descC);
cudnnDestroyOpTensorDescriptor(opDesc);
cudnnDestroy(cudnn);
free(A);
free(B);
free(C);
printf("Operation completed successfully.\n");
return 0;
}
编译:
nvcc -o cudnn_test cudnn_test.cu -lcudnn
执行:
./cudnn_test
4、总结
至此显卡驱动、CUDA和cuDNN就安装完成了,安装过程中主要是禁用开源显卡驱动和操作系统内核版本的匹配安装。
提示:更多内容可以访问Clang’s Blog:https://www.clang.asia















 3408
3408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









