









有趣的爬虫,独有的意义召唤着我去学习,去尝试。最近有感于每天对于论文的收集,感觉自己的收集速度赶不上论文的更新速度,同时对于自己想找到的论文的收集比较麻烦。因此,学习用python写一个很简单的爬虫,完成对最新论文的概括或查找。对于计算机领域的最新论文,一般都可以在 http://arxiv.org/list/cs/recent 找到,因此,对此网页尝试简单爬虫。 本博客简要介绍简单爬虫快速获取相关新论文标题和pdf。
所需网页的抓取
首先加载爬虫所需的模块,urllib和urllib2是常见的打开url网页的模块,如urllib.urlopen(url[,data[,proxies]]),打开一个url,并返回一个文件对象
我们这里使用urllib2模块,发送一个打开网页的请求,并使用urlopen打开网页,代码如下:
import urllib2
req = urllib2.Request('http://arxiv.org/list/cs/recent')
response = urllib2.urlopen(req)
the_page = response.read()
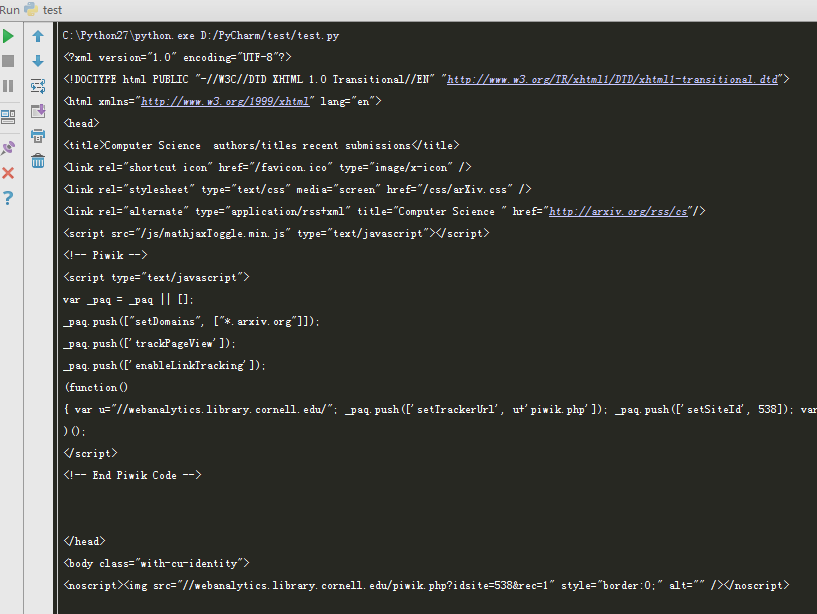
print(the_page)输出得到的结果即为整个网页源代码:
信息的匹配与搜索
抓取到所需要的网页后会发现,网页的源代码杂乱,这时需要在杂乱的代码中找到自己所需要的信息,将有用的信息输出。因此,信息的匹配与正则化的运用由此生出。例如,需要对所有的文章标题进行输出,那么需要找到每个论文标题处的独有特征,正则化表达后表示出标题,将其全部输出。
具体的正则化规则在其他人的博客中也有详细介绍,如:http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html ,正则表达式并不是Python的一部分。正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大。得益于这一点,在提供了正则表达式的语言里,正则表达式的语法都是一样的,区别只在于不同的编程语言实现支持的语法数量不同;但不用担心,不被支持的语法通常是不常用的部分。如果已经在其他语言里使用过正则表达式,只需要简单看一看就可以上手了。
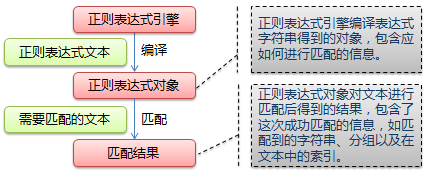
其匹配流程如下:
具体我们来看我们的例子,对于论文标题的表达,首先提取网页源代码中涉及每一篇最新论文的部分,如下(随机举例):
<dt><a name="item18">[18]</a> <span class="list-identifier"><a href="/abs/1609.04722" title="Abstract">arXiv:1609.04722</a> [<a href="/pdf/1609.04722" title="Download PDF">pdf</a>, <a href="/ps/1609.04722" title="Download PostScript">ps</a>, <a href="/format/1609.04722" title="Other formats">other</a>]</span></dt>
<dd>
<div class="meta">
<div class="list-title mathjax">
<span class="descriptor">Title:</span> Concordance and the Smallest Covering Set of Preference Orderings
</div>
<div class="list-authors">
<span class="descriptor">Authors:</span>
<a href="/find/cs/1/au:+Lin_Z/0/1/0/all/0/1">Zhiwei Lin</a>,
<a href="/find/cs/1/au:+Wang_H/0/1/0/all/0/1">Hui Wang</a>,
<a href="/find/cs/1/au:+Elzinga_C/0/1/0/all/0/1">Cees H. Elzinga</a>
</div>
<div class="list-comments">
<span class="descriptor">Comments:</span> 21 pages
</div>
<div class="list-subjects">
<span class="descriptor">Subjects:</span> <span class="primary-subject">Artificial Intelligence (cs.AI)</span>; Data Structures and Algorithms (cs.DS); Computer Science and Game Theory (cs.GT); Information Theory (cs.IT)这里,下面句子即为该论文的title部分描述:
<span class="descriptor">Title:</span> Concordance and the Smallest Covering Set of Preference Orderings
</div>我们想要的结果,即为<span class="descriptor">Title:</span>之后和</div>之前的部分文字进行输出,对应于正则表达式规则,可以表达如下:
import re #加载正则化匹配模块
myItems = re.findall('<span class="descriptor">Title:</span>(.*?)</div>',page,re.S)这就是正则化的方法,类似该方法可以进行所需信息的匹配的查找。
同时,python中函数功能的使用,可以使得代码更简洁,爬虫的功能添加也更加方便,python中的函数主要用def表示,如上文中的论文标题输出函数可以写成如下形式,输出即为所有该网页新论文的标题。
def paper_title(page):
myItems = re.findall('<span class="descriptor">Title:</span>(.*?)</div>',page,re.S)
for item in myItems:
print item简单实例
这里我们完成论文的标题输出部分的爬虫,代码如下:
import urllib2
import re
req = urllib2.Request('http://arxiv.org/list/cs/recent')
response = urllib2.urlopen(req)
the_page = response.read()
def paper_title(page):
myItems = re.findall('<span class="descriptor">Title:</span>(.*?)</div>',page,re.S)
for item in myItems:
print item
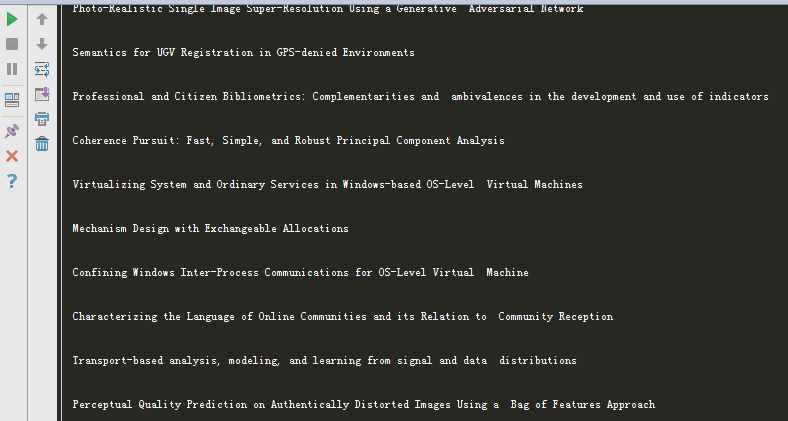
paper_title(the_page)输入结果如下:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









