







图像识别:猫
一.样本准备
选取网站:
- 首先自网络上选取网站爬取或批量下载图片文件素材 将其保存在文件夹中
- 选取网站时候需要稍稍注意下 可以随意搜索个关键字看看搜索结果中图片的质量怎么样
- 有些网站可能搜索“猫” 它会把动漫形象的猫或者是其他动物一并返回在结果中
- 这样的情况下爬取的效果就较为糟糕 对爬取的图片还需要做很多人工筛选的工作。
保存方式:
-
其中正例与负例需要分开放置 同时我利用代码分别完成了正负例图片的重命名
-
对图片文件进行批量重命名的python代码:
import os
path = "cat\\"
n = 0
for file in os.listdir(path):
os.rename(path+file, path+""+str(n+1) + '.jpg')
n += 1
正负例样本:
- 正例与负例样本数量比例最好为1:3
- 正例要求严格 一定要清晰地包含识别的主体
- 负例选取的范围很广 但仍需要与正例拥有一定相关性 不应该天马行空。
样本初步完成收集后 如下所示:


二.图像处理
- 将正例图像处理为统一尺寸 ,图片尺寸可以自己选择
- 但过大的尺寸会导致难以训练(特别是个人笔记本电脑配置不佳)
- 同时图片转化为灰度图 ,利用灰度图能够加快模型训练速度
- 负例图片尺寸可以不进行处理 但仍需要转化为灰度图
weight = 40
height = 40
path = "cat\\"
outpath = "positive\\"
for file in os.listdir(path):
img = cv.imread(path+file)
img = cv.resize(img, (weight, height))
gray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
cv.imwrite(outpath+file,gray)
完成处理后,图像如下:

三.样本描述
对正例输出样本描述的文本文件
workpath = os.getcwd()+"\\"
path = "positive\\"
f = "positive.txt"
for file in os.listdir(path):
with open(f,"a") as f1:
f1.write(str(workpath+path+file)+" 1 0 0 "+str(weight)+" "+str(height)+" \n")
文本内容如下:
<图片绝对地址 识别对象 图像起始坐标 图像宽高>

对于负例同样需要进行处理 但是只需要保存图片地址即可
不必如正例一般添加详细信息

四.训练分类器
OpenCV库训练采用的是Viola-Jones框架,选择了一种类Haar矩形特征,采用Ada-Boost这种自适应上升的算法来选择用于分类的特征并进行分类,最后使用弱分类器级联的架构来实现快速运算。
在项目文件夹目录下 进入cmd环境

输入如下语句生成vec文件
opencv_createsamples.exe -info 正例样本描述.txt -vec cat.vec -bg negative.txt -num 2037 -w 40 -h 40
如下:

而后利用该vec文件 生成属于自身的分类器:
opencv_traincascade.exe -data xml -vec cat.vec -bg negative.txt -numPos 1800 -numNeg 5015 -numStages 10 -featureType HAAR -w 40 -h 40 -maxDepth 3
如下 该cascade.xml文件便是我们使用的分类器:

五.识别效果及调整
5.1 少量样本模型
-
正例 40×30 灰度图 数量25
-
负例 40×30 灰度图 数量25
-
模型参数 stage=2 type=harr maxDepth=1
-
训练用时:0s
-
效果如下:
-

-
评价:
-
将非生物的物品如窗帘地板均当作特征进行了抓取
-
较为混乱 基本没能抓住重要特征。
5.2 模型调整:补充样本集合
-
正例 40×30 灰度图 数量772
-
负例 120×90 灰度图 数量2599
-
模型参数 stage=10 type=LBP maxDepth=1
-
训练用时:3mins
-
效果如下:
-

-
评价:
-
能够抓住一定的猫的特征了 比如独特的猫耳朵 猫爪子
-
但是还是效果不佳 如无环境干扰下将狗的毛发认作了猫的特征
-

5.3 模型调整:增大图片尺寸
-
正例 60×45 灰度图 数量772
-
负例 180×135 灰度图 数量2599
-
模型参数 stage=10 type=LBP maxDepth=1
-
训练用时:1h30mins
-
效果如下:
-

-

-

5.4 模型调整:补充样本集合
-
正例 20×20 灰度图 数量2037
-
负例 60×60 灰度图 数量5015
-
模型参数 stage=10 type=HAAR maxDepth=3
-
训练用时: 5h 30mins
-
效果如下:
-
当干扰较少时 能够较好地抓取到猫猫的独特特征
-

-
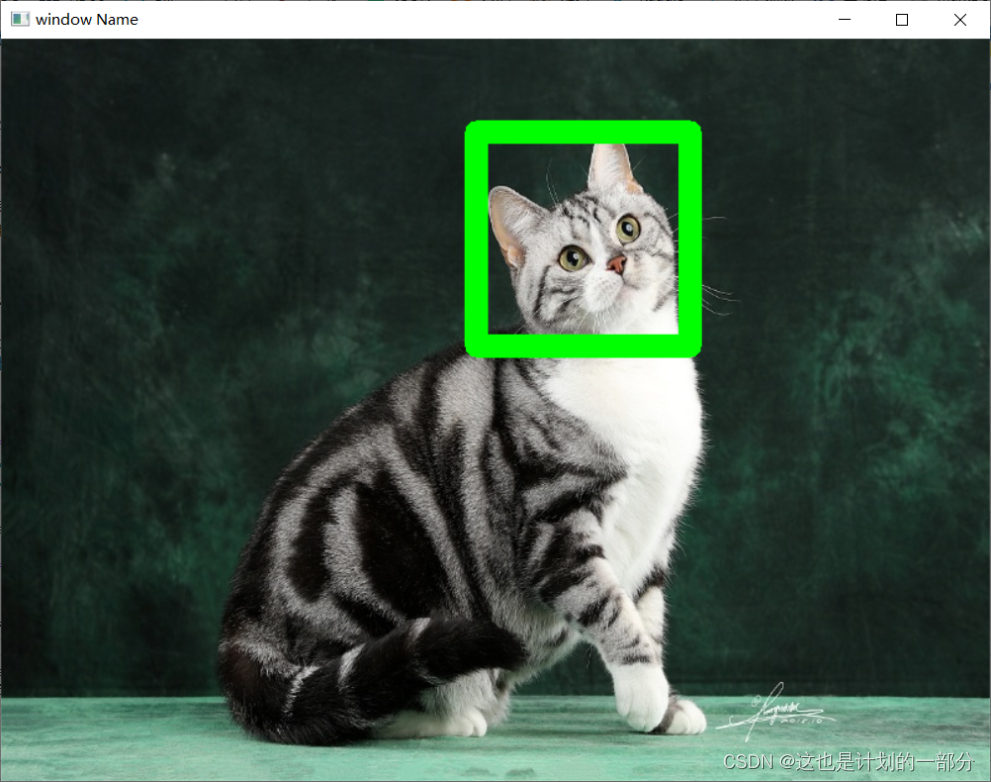
-
但如果环境较为复杂 则极容易出错
-

-
将地毯的绒毛看作了猫猫的特征:
-

5.5 模型调整:增大图片尺寸
- 正例 30×30 灰度图 数量2037
- 负例 90×90 灰度图 数量5015
- 模型参数 stage=10 type=HAAR maxDepth=3
- 训练用时: 47h01mins

















 2401
2401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









