






在创建一个多任务嵌入式系统时,有一个简单的方法来编写、加载和运行独立的应用任务是很有意义的。许多现代嵌入式系统使用操作系统,而不是自定义专有的控制系统来简化这个过程。更先进的操作系统使用基于硬件的内存管理单元(MMU)。
MMU 提供的一个关键服务是能够将任务作为独立程序在自己的私有内存空间中运行。在受 MMU 控制的操作系统下运行的任务不需要知道不相关任务的内存需求。这简化了在操作系统控制下运行的各个任务的设计要求。
在第13章中,我们介绍了带有内存保护单元的处理器核心。这些核心具有一个可寻址的物理内存空间。处理器核心在运行任务时生成的地址直接用于访问主存储器,这使得如果使用重叠的地址编译,两个程序同时驻留在主存储器中是不可能的。这使得在嵌入式系统中运行多个任务变得困难,因为每个任务必须在主存储器中运行在一个不同的地址块中。
MMU简化了应用任务的编程,因为它提供了启用虚拟内存所需的资源,这是一个独立于系统上连接的物理内存的额外内存空间。MMU充当一个翻译器,将编译为在虚拟内存中运行的程序和数据的地址转换为实际物理地址,在物理主存储器中存储程序的位置。这个转换过程允许程序在不同的物理内存位置上以相同的虚拟地址运行。
这种对内存的双重视图导致了两种不同的地址类型:虚拟地址和物理地址。虚拟地址在定位程序在内存中时由编译器和链接器分配。物理地址用于访问程序所在的实际主存储器的硬件组件。
ARM提供了几个带有集成MMU硬件的处理器核心,可以高效支持使用虚拟内存的多任务环境。本章的目标是学习ARM内存管理单元的基础知识和支持虚拟内存使用的一些基本概念。
我们首先回顾MPU的保护特性,然后介绍MMU提供的附加功能。我们介绍重新定位寄存器,它保存转换数据,以将虚拟内存地址转换为物理内存地址,并介绍最近地址重新定位的缓存——翻译后备缓冲器(TLB)。然后,我们解释如何使用页和页表来配置重新定位寄存器的行为。
接下来,我们讨论如何通过在虚拟内存中配置页面块来创建区域。我们通过展示如何操作MMU和页表以支持多任务来结束对MMU及其对虚拟内存的支持的概述。
接下来,我们通过针对ARM MMU中的每个组件提供一个部分来呈现配置MMU硬件的详细信息:页表、翻译后备缓冲器(TLB)、访问权限、缓存和写缓冲区、CP15:c1控制寄存器以及快速上下文切换扩展(FCSE)。
我们通过提供演示软件来结束本章,演示如何使用虚拟内存设置嵌入式系统。演示支持在多任务环境中运行的三个任务,并展示如何通过将任务编译为在共同的虚拟内存执行地址上运行并将它们放置在物理内存的不同位置来保护每个任务免受系统中运行的其他任务的干扰。演示的关键部分是展示如何配置MMU来将任务的虚拟地址转换为任务的物理地址,以及如何在任务之间切换。
演示已经集成到第11章介绍的SLOS操作系统中,作为称为mmuSLOS的变体。
14.1 Moving from an MPU to an MMU
在第13章中,我们介绍了带有内存保护单元(MPU)的ARM核心。更重要的是,我们介绍了区域作为一种方便的方式来组织和保护内存。区域可以是活动的或休眠的:活动区域包含当前系统正在使用的代码或数据;休眠区域包含当前未使用但可能在短时间内变为活动状态的代码或数据。休眠区域受到保护,因此对当前运行的任务来说是不可访问的。
MPU具有专用硬件,用于为区域分配属性。表14.1展示了分配给区域的属性。

在本章中,我们假设读者已经理解了第13章介绍的关于内存保护的概念,并且简单地展示如何配置MMU上的保护硬件。
MPU和MMU之间的主要区别是MMU增加了支持虚拟内存的硬件。MMU硬件还通过将表14.1中显示的区域属性从CP15寄存器移动到保存在主存储器中的表格中,扩展了可用区域的数量。
14.2 How Virtual Memory Works
在第13章中,我们介绍了MPU,并展示了一个多任务嵌入式系统,该系统在主存储器中以明显不同的、固定的地址区域编译和运行每个任务。每个任务只在一个进程区域中运行,并且没有任何任务在主存储器中具有重叠的地址。为了运行一个任务,一个保护区域被放置在固定地址的程序上,以便访问由该区域定义的内存区域。保护区域的放置允许任务在其他任务受保护时执行。
在MMU中,即使任务被编译和链接以在主存储器中具有重叠地址的区域中运行,它们仍然可以运行。MMU中的虚拟内存支持使得可以构建一个具有多个虚拟内存映射和单个物理内存映射的嵌入式系统。为了编译和链接构成任务的代码和数据,每个任务都提供了自己的虚拟内存映射。然后,内核层在物理内存中管理多个任务的位置,以便它们在物理内存中具有与其设计用于运行的虚拟位置不同的独特位置。
为了允许任务拥有自己的虚拟内存映射,MMU硬件在到达主存储器之前对处理器核心输出的内存地址进行重新定位和转换。理解转换过程的最简单方法是想象在核心和主存储器之间的MMU中有一个重新定位寄存器。
当处理器核心生成一个虚拟地址时,MMU会获取虚拟地址的高位,并用重定位寄存器的内容替换它们,从而创建一个物理地址,如图14.1所示。
虚拟地址的低部分是一个偏移量,将转换为物理内存中的特定地址。可以使用这种方法进行转换的地址范围受限于虚拟地址的偏移量部分的最大大小。
图14.1显示了一个任务编译为在虚拟内存中的起始地址为0x4000000运行的示例。重定位寄存器将任务1的虚拟地址转换为以0x8000000开始的物理地址。
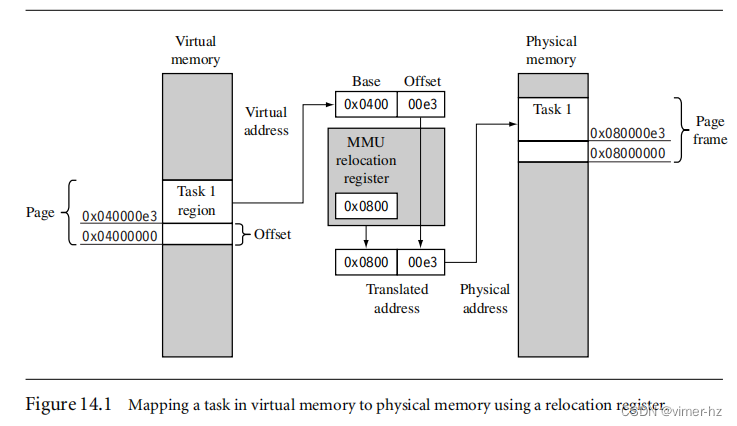
第二个任务编译为在相同的虚拟地址上运行,这里是0x400000,它可以被放置在物理内存中的任何其他0x10000(64KB)的倍数处,并映射到0x400000,只需更改重定位寄存器中的值。
单个重定位寄存器只能转换单个内存区域,这由虚拟地址的偏移量部分中的位数确定。虚拟内存的这个区域称为页。翻译过程指向的物理内存区域称为页帧。
图14.2显示了页面、MMU和页帧之间的关系。ARM MMU硬件具有支持将虚拟内存转换为物理内存的多个重定位寄存器。MMU需要许多重定位寄存器来有效地支持虚拟内存,因为系统必须将许多页面转换为许多页帧。
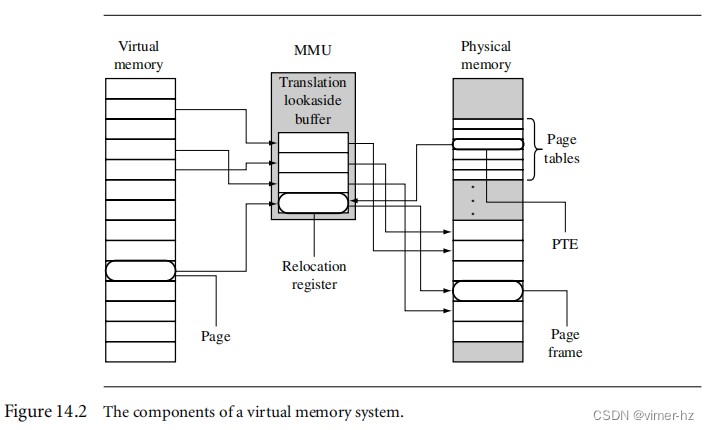
ARM MMU中用于暂时存储翻译的重定位寄存器实际上是一个完全关联的缓存,包含64个重定位寄存器。这个缓存被称为Translation Lookaside Buffer(TLB)。TLB缓存最近访问的页面的翻译结果。
除了具有重定位寄存器之外,MMU还使用主存中的表格来存储描述系统中使用的虚拟内存映射的数据。这些翻译数据的表格称为页表。页表中的一个条目表示将虚拟内存中的一页翻译为物理内存中的页帧所需的所有信息。
//Page Table Entry
页表中的一个页表条目(PTE)包含关于虚拟页的以下信息:用于将虚拟页翻译为物理页帧的物理基地址、分配给该页的访问权限,以及该页的高速缓存和写缓冲区配置。如果参考表14.1,可以看到大多数MPU中的区域配置数据现在都保存在页表条目中。这意味着访问权限、缓存和写缓冲区行为是以页面大小的粒度进行控制的,从而更精细地控制内存的使用。
MMU中的区域是通过将内存中的虚拟页面块分组来在软件中创建的。
14.2.1 Defining Regions Using Pages
在第13章中,我们解释了使用区域来组织和控制用于特定功能(如任务代码、数据或内存输入/输出)的内存区域。在那个解释中,我们将区域显示为MPU架构的硬件组件。在MMU中,区域被定义为页表的组合,并且完全由软件在虚拟内存中的连续页面上进行控制。
由于虚拟内存中的每一页都在页表中有一个对应的条目,一块虚拟内存页面映射到页表中的一组连续条目。因此,区域可以被定义为连续的页表条目集合。区域的位置和大小可以保存在软件数据结构中,而实际的翻译数据和属性信息则保存在页表中。
图14.3显示了一个单一任务具有三个区域的示例:一个用于文本,一个用于数据,第三个用于支持任务堆栈。虚拟内存中的每个区域都映射到物理内存中的不同区域。在该图中,可执行代码位于闪存中,数据区和堆栈区位于RAM中。这种使用区域的方式是支持任务之间共享代码的操作系统的典型示例。
//闪存也算在Physical memory里?
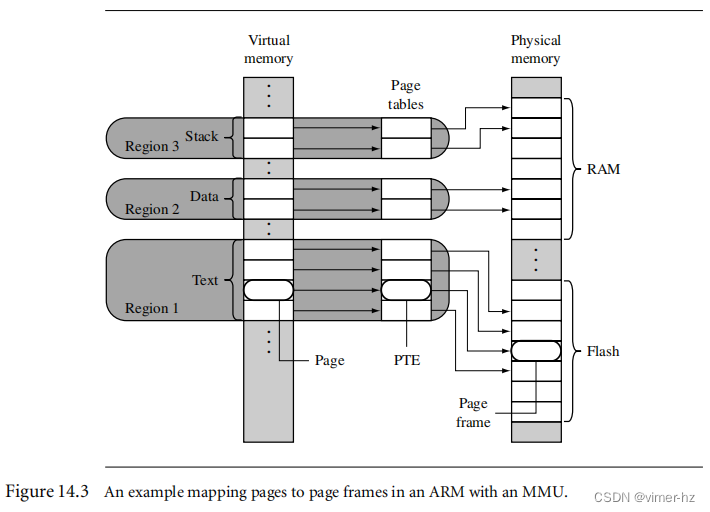
除了主级别1(L1)页表之外,所有页表表示1 MB的虚拟内存区域。如果一个区域的大小大于1 MB或跨越了分隔页表的1 MB边界地址,那么该区域的描述还必须包括页表列表。一个区域的页表将始终从主L1页表中的连续页表条目中派生。然而,物理内存中L2页表的位置不需要连续。页表级别将在第14.4节中有更详细的说明。
14.2.2 Multitasking and the MMU
页表可以存储在内存中,并且不需要映射到MMU硬件上。构建多任务系统的一种方法是创建独立的页表集,每个集合将为一个任务映射一个唯一的虚拟内存空间。要激活一个任务,需要将该任务及其虚拟内存空间的页表集映射到MMU中使用。其他处于非活动状态的页表集表示休眠任务。这种方法使得所有任务都可以保留在物理内存中,并且在上下文切换发生时立即可用。
通过在上下文切换期间激活不同的页表,可以执行具有重叠虚拟地址的多个任务。MMU可以重新定位任务的执行地址,而无需将其移动到物理内存中。任务的物理内存只需通过激活和停用页表来映射到虚拟内存中。图14.4展示了三个任务的三个视图,每个任务都有自己的页表集,并在共同的执行虚拟地址0x0400000下运行。
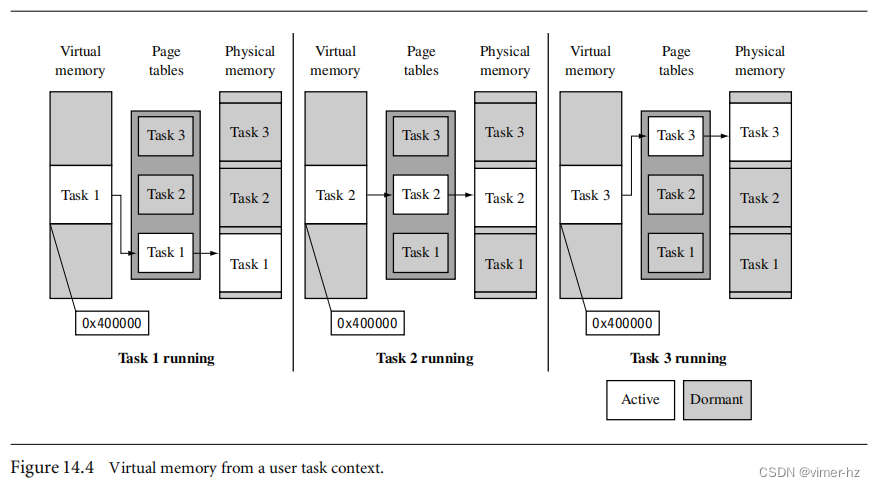
在第一个视图中,任务1正在运行,任务2和任务3处于休眠状态。在第二个视图中,任务2正在运行,任务1和任务3处于休眠状态。在第三个视图中,任务3正在运行,任务1和任务2处于休眠状态。三个视图中的每个虚拟内存都代表了运行任务所见到的内存。物理内存的视图在所有视图中都是相同的,因为它代表真实物理内存的实际状态。
图中还显示了活动和休眠的页表,只有正在运行的任务具有一组活动的页表。休眠任务的页表保持驻留在特权物理内存中,并且对于运行的任务来说是不可访问的。因此,休眠任务完全受到活动任务的保护,因为虚拟内存中没有与休眠任务的映射关系。
当页表被激活或停用时,虚拟到物理地址的映射将发生变化。因此,在激活页表后,访问虚拟内存中的地址可能会突然转换为物理内存中的不同地址。正如在第12章中提到的,ARM处理器核心具有逻辑缓存,并将缓存的数据存储在虚拟内存中。当发生这种转换时,缓存中可能会包含来自旧的页表映射的无效虚拟数据。为确保内存一致性,缓存可能需要进行清理和刷新。TLB(转换查找缓冲器)也可能需要刷新,因为它将缓存旧的转换数据。
//cache里存储的是虚拟内存地址
清理和刷新缓存和TLB的效果会减慢系统操作。然而,清除缓存中的过时代码或数据以及TLB中的过时转换物理地址可以防止系统使用无效数据并避免错误发生。
在上下文切换期间,页表数据不会在物理内存中移动,只有指向页表位置的指针会发生变化。
切换任务需要以下步骤:
1. 保存活动任务的上下文并将任务置于休眠状态。
2. 清除缓存;如果使用写回策略,则可能需要清理D缓存。
3. 刷新TLB以删除当前任务的转换。
4. 配置MMU以使用新的页表,将虚拟内存执行区域转换为唤醒任务在物理内存中的位置。
5. 恢复唤醒任务的上下文。
6. 恢复执行已恢复的任务。
注意:为了减少执行上下文切换所需的时间,在ARM9系列中可以使用写穿策略的缓存。清理数据缓存可能需要对CP15寄存器进行数百次写操作。通过配置数据缓存使用写穿策略,在执行上下文切换时无需清理数据缓存,这将提供更好的上下文切换性能。使用写穿策略可以将这些写操作分散到任务的生命周期中。尽管写回策略可以提供更好的总体性能,但在小型嵌入式系统中使用写穿策略更加简单。这种简化适用于大多数系统在非易失性存储器中使用闪存存储程序,并在系统运行期间将程序复制到RAM中。如果您的系统具有文件系统并使用动态分页,那么是时候切换到写回策略了,因为访问文件系统存储的速度比访问RAM存储慢上数十到数百万倍。
如果在性能分析后发现写穿系统的效率不够,可以使用写回缓存来提高性能。如果您使用的是磁盘驱动器或其他非常慢的辅助存储器,几乎必须使用写回策略。该论点仅适用于使用逻辑缓存的ARM内核。如果存在物理缓存,例如ARM11系列中的情况,当MMU更改其虚拟内存映射时,缓存中的信息仍然有效。使用物理缓存可以消除更改虚拟内存地址时执行缓存管理活动的需要。有关缓存的更多信息,请参阅第12章。
14.2.3 Memory Organization in a Virtual Memory System
通常,页表位于主存储器的一个区域,其中虚拟到物理地址映射是固定的。所谓"固定"是指在正常操作期间,页表中的数据不会改变,如图14.5所示。这个固定的存储区域还包含操作系统内核和其他进程。MMU(包括图14.5中显示的TLB)是在虚拟或物理内存空间之外操作的硬件,其功能是在两个内存空间之间进行地址转换。
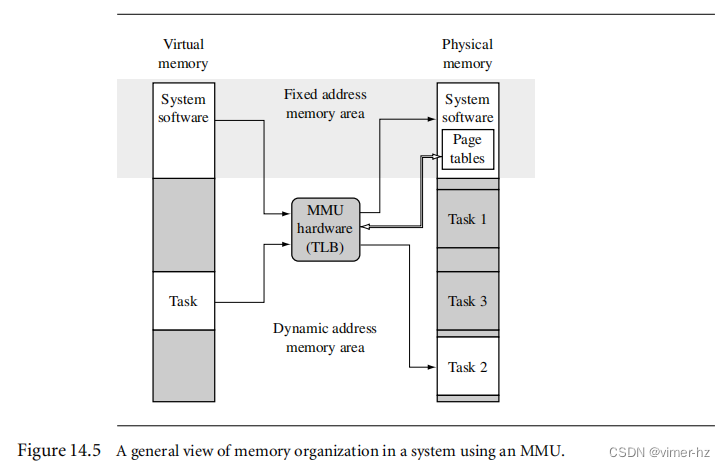
//Virtual memory的System software包含操作系统内核和其他进程是什么意思?,然后再往下是Tasks?
这种固定映射的优势在上下文切换时体现出来。将系统软件放置在固定的虚拟内存位置上,可以消除一些内存管理任务,并消除如果处理器在一个虚拟内存区域中执行,而该区域突然重新映射到不同的物理内存位置,产生的流水线效应。
当两个应用任务之间发生上下文切换时,实际上处理器进行了许多上下文切换。它从用户模式任务切换到内核模式任务,执行实际的上下文数据移动,以准备运行下一个应用任务。然后,它再从内核模式任务切换到下一个上下文的新用户模式任务。
通过在所有用户任务中共享固定虚拟内存区域中的系统软件,系统调用可以直接转到系统区域,而不需要担心需要更改页表来映射内核进程。在所有任务中将内核代码和数据映射到相同的虚拟地址,消除了更改内存映射和需要独立的内核进程来占用时间片的需要。
转到固定的内核内存区域还消除了流水线架构固有的一个问题。如果处理器核心在一个地址会发生变化的内存区域中执行代码,那么核心将从旧的物理内存空间预取多条指令,当新的指令从新映射的内存空间填充流水线时,这些预取的指令将被执行。除非特别注意,从旧的内存映射中仍在流水线中执行的指令可能会破坏程序的执行。
我们建议在执行系统代码时激活页表,并将其放置于一个虚拟地址区域,其中虚拟到物理内存映射永远不会改变。这种方法确保了用户任务之间的安全切换。
许多嵌入式系统不使用复杂的虚拟内存,而只是创建一个"固定"的虚拟内存映射,以整合物理内存的使用。这些系统通常将分散在大地址空间上的物理内存块集合到一个连续的虚拟内存块中。它们通常在初始化过程中创建一个"固定"的映射,而在系统运行过程中该映射保持不变。
14.3 Details of the ARM MMU
ARM MMU执行多个任务:它将虚拟地址转换为物理地址,控制内存访问权限,并确定内存中每个页面的缓存和写缓冲区的个别行为。当MMU被禁用时,所有虚拟地址都一对一地映射到相同的物理地址。如果MMU无法转换地址,则会生成异常中断。MMU只会在转换、权限和域故障时中止。
MMU中的主要软件配置和控制组件包括:
- 页表
- 翻译后备缓冲器(TLB)
- 域和访问权限
- 缓存和写缓冲区
- CP15:c1控制寄存器
- 快速上下文切换扩展功能
我们将在以下部分介绍这些组件的操作细节和配置方法。
14.4 Page Tables
ARM MMU硬件采用多级页表结构。有两个级别的页表:第一级(L1)和第二级(L2)。
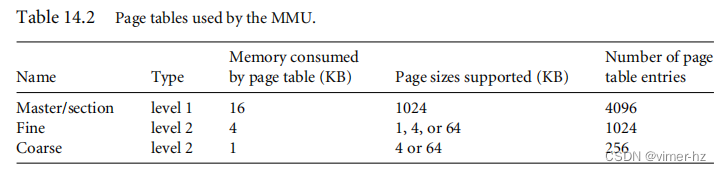
存在一个单独的第一级页表,称为L1主页表,可以包含两种类型的页表项。它可以保存指向第二级页表起始地址的指针,以及用于翻译1 MB页面的页表项。L1主表也称为节页表。
主L1页表将4 GB的地址空间划分为1 MB的节,因此L1页表包含4096个页表项。主表是一个混合表,既充当L2页表的页目录,又充当翻译1 MB虚拟页面(称为节)的页表。如果L1表充当目录,则PTE包含指向表示1 MB虚拟内存的L2粗粒度页表或L2细粒度页表的指针。如果L1主表正在翻译1 MB节,则PTE包含物理内存中1 MB页框的基地址。目录项和1 MB节项可以共存于主页表中。
粗粒度L2页表有256个项,占用1 KB的主存。粗粒度页表中的每个PTE将4 KB的虚拟内存块翻译为4 KB的物理内存块。粗粒度页表支持4 KB或64 KB页面。粗粒度页中的PTE包含指向4 KB或64 KB页框的基地址;如果该条目翻译一个64 KB页面,则每个64 KB页面必须在页表中重复16次。
细粒度L2页表有1024个项,占用4 KB的主存。细粒度页表中的每个PTE将1 KB的内存块翻译为相应的大小。细粒度页表支持1 KB、4 KB或64 KB的虚拟内存页面。这些条目包含物理内存中1 KB、4 KB或64 KB的页框的基地址。如果细粒度表翻译一个4 KB页面,则同一PTE必须在页表中连续重复4次。如果表翻译一个64 KB页面,则同一PTE必须在页表中连续重复64次。
表14.2总结了ARM内存管理单元中使用的三种页表的特性。
14.4.1 Level 1 Page Table Entries
第一级页表(L1页表)接受四种类型的条目:
■ 一个1 MB节翻译条目
■ 一个指向细粒度L2页表的目录条目
■ 一个指向粗粒度L2页表的目录条目
■ 一个生成中止异常的故障条目
系统通过条目字段中的低两位[1:0]来确定条目的类型。PTE的格式要求L2页表的地址要对其于其页面大小的倍数。图14.6显示了L1页表中每个条目的格式。
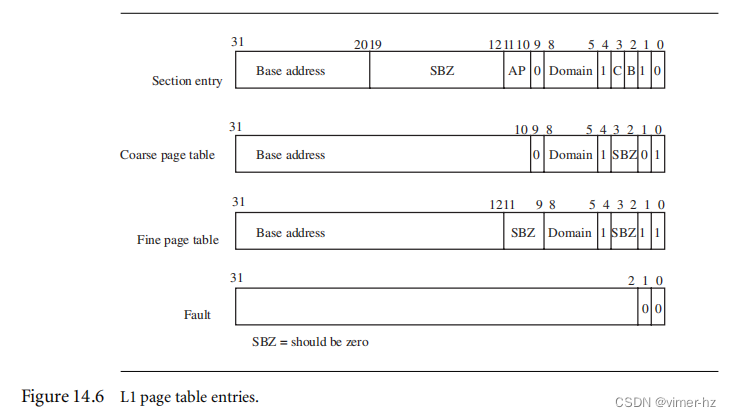
节页表条目指向1 MB的内存节。页表条目的高12位取代虚拟地址的高12位以生成物理地址。节条目还包含域、缓存、缓冲和访问权限属性,我们将在第14.6节中讨论这些属性。
粗粒度页条目包含指向第二级粗粒度页表的基地址的指针。粗粒度页表条目还包含L1表条目所表示的1 MB虚拟内存的域信息。对于粗粒度页,表必须对齐于1 KB的地址倍数。
细粒度页表条目包含指向第二级细粒度页表的基地址的指针。细粒度页表条目还包含L1表条目所表示的1 MB虚拟内存的域信息。细粒度页表必须对齐于4 KB的地址倍数。
故障页表条目会引发内存页故障。故障条件导致预取或数据中止,具体取决于尝试的内存访问类型。
//故障页表条目和page fault有关系么?
L1主页表在内存中的位置通过写入CP15:c2寄存器来设置。
14.4.2 The L1 Translation Table Base Address
CP15:c2寄存器保存着翻译表基地址(TTB),即指向主L1表在虚拟内存中的位置的地址。图14.7显示了CP15:c2寄存器的格式。
例子14.1:
这里有一个名为ttbSet的例程,它设置了主L1页表的TTB。ttbSet例程使用MRC指令写入到CP15:c2:c0:0。该例程使用以下函数原型进行定义:
void ttbSet(unsigned int ttb);
该过程只接受一个参数,即翻译表的基地址。TTB地址必须在内存中16 KB的边界上对齐。
void ttbSet(unsigned int ttb)
{
ttb &= 0xffffc000;
__asm{MRC p15, 0, ttb, c2, c0, 0 } /* 设置翻译表基地址 */
}14.4.3 Level 2 Page Table Entries
L2页表中有四种可能的条目类型:
■ 大页面条目定义了一个64 KB的物理页框的属性。
■ 小页面条目定义了一个4 KB的物理页框。
■ 微小页面条目定义了一个1 KB的物理页框。
■ 故障页面条目在访问时会生成页面故障终止异常。
图14.8显示了L2页表条目的格式。MMU通过条目字段中的低两位来识别L2页表条目的类型。
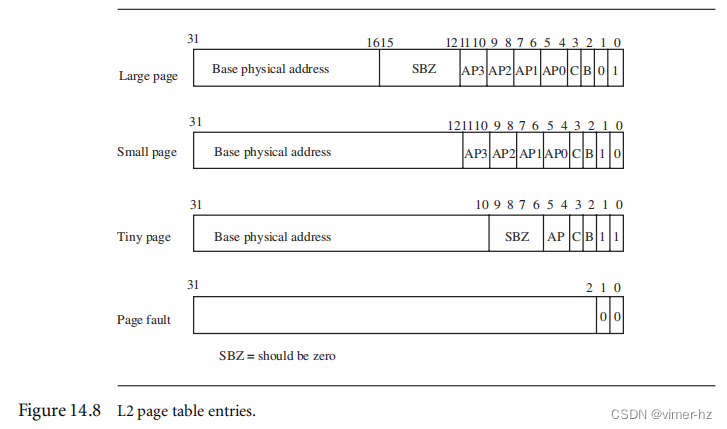
大页面条目包括一个64 KB物理内存块的基地址。该条目还有四组权限位字段,以及页面的缓存和写缓冲属性。每组访问权限位字段代表虚拟内存中页面的四分之一。这些条目可以看作是16 KB的子页面,在64 KB页面内提供了更精细的访问权限控制。
小页面条目保存了一个4 KB物理内存块的基地址。该条目还包括四组权限位字段和页面的缓存和写缓冲属性。每组权限位字段代表虚拟内存中页面的四分之一。这些条目可以看作是1 KB的子页面,在4 KB页面内提供了更精细的访问权限控制。
微小页面条目提供了一个1 KB物理内存块的基地址。该条目还包括一个单独的访问权限位字段和页面的缓存和写缓冲属性。微小页面没有在ARMv6架构中使用。如果您打算创建一个易于迁移至未来架构的系统,我们建议避免在系统中使用1 KB的微小页面。
故障页面条目会生成内存页访问故障。故障条件导致预取或数据中止,具体取决于内存访问类型。
14.4.4 Selecting a Page Size for Your Embedded System
以下是设置系统页面大小的一些建议和提示:
■ 页面大小越小,在给定的物理内存块中会有更多的页框。
■ 页面大小越小,内部碎片化越少。内部碎片化是指页面中未使用的内存区域。例如,一个大小为9 KB的任务可以适应三个4 KB的页面或一个64 KB的页面。在第一种情况下,使用4 KB的页面,有3 KB的未使用空间。而在使用64 KB页面的情况下,有55 KB的未使用页面空间。
■ 页面大小越大,系统加载引用的代码和数据的可能性越高。
■ 大页面在访问次存储增加时效率更高。
■ 随着页面大小增加,每个TLB条目表示的内存区域也增加。因此,系统可以缓存更多的翻译数据,TLB加载整个任务的所有翻译数据的速度更快。
■ 如果使用L2粗页面,每个页表占用1 KB的内存。而每个L2细页面表占用4 KB的内存。每个L2页表可翻译1 MB的地址空间。每个任务的最大页表内存使用量可以通过以下公式计算:
((task size/1 megabyte) + 1) ∗ (L2 page table size) (14.1)
14.5 The Translation Lookaside Buffer
TLB是最近使用的页面翻译的特殊高速缓存。TLB将虚拟页面映射到活动页面帧,并存储限制对页面访问的控制数据。TLB是一个缓存,因此具有受害者指针和TLB行替换策略。在ARM处理器核心中,TLB使用循环轮询算法来选择在TLB未命中时要替换的重定位寄存器。
ARM处理器核心中的TLB没有许多可用于控制其操作的软件命令。TLB支持两种类型的命令:可以刷新TLB,也可以在TLB中锁定翻译。
在内存访问过程中,MMU将虚拟地址的一部分与TLB中缓存的所有值进行比较。如果请求的翻译可用,则为TLB命中,TLB提供物理地址的翻译。
如果TLB中不包含有效的翻译,则为TLB未命中。MMU通过在主存中搜索有效的翻译并将其加载到TLB的64行之一来自动处理TLB未命中。在页表中搜索有效的翻译称为页表遍历。如果存在有效的PTE,则硬件将翻译地址从PTE复制到TLB,并生成用于访问主存的物理地址。如果在搜索结束时在页表中存在故障条目,则MMU硬件会生成中止异常。
在TLB未命中期间,MMU可能要在加载数据到TLB并生成所需的地址翻译之前搜索多达两个页表。未命中的成本通常是一到两个主存访问周期,因为MMU翻译表硬件搜索页表。循环的次数取决于翻译数据所在的页表。如果搜索以L1主页表结束,则发生单级页表遍历;如果搜索以L2页表结束,则发生两级页表遍历。
如果MMU生成中止异常,TLB未命中可能需要额外的多个周期。额外的周期是由于中止处理程序映射请求的虚拟内存而产生的。ARM720T只有一个TLB,因为它具有统一总线架构。ARM920T、ARM922T、ARM926EJ-S和ARM1026EJ-S具有两个TLBs,因为它们使用了哈佛总线架构:一个用于指令翻译,一个用于数据翻译。
14.5.1 Single-Step Page Table Walk
如果MMU正在搜索1MB的分段页,硬件可以通过单步搜索找到该条目,因为1MB的页表条目位于主L1页表中。图14.9展示了对于1MB分段页翻译的L1表的表遍历过程。
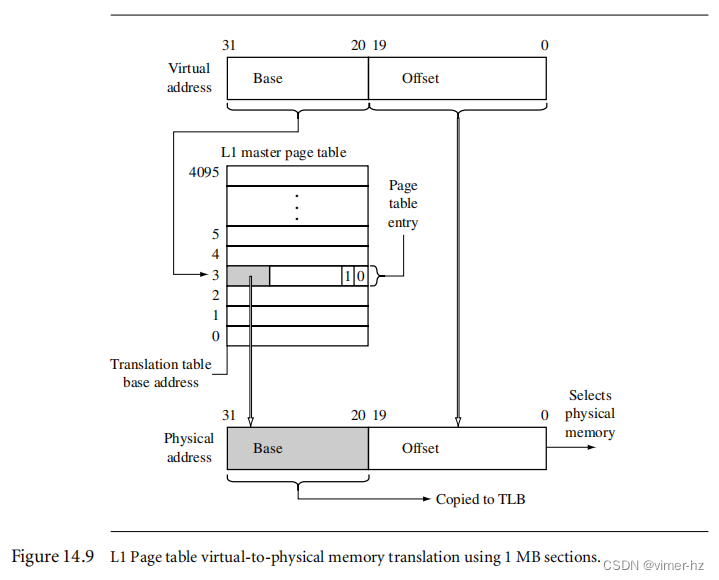
MMU使用虚拟地址的基地址部分,即[31:20]位,来选择L1主页表中的4096个条目之一。如果[1:0]位的值是二进制10,则PTE具有一个有效的1MB页面。PTE中的数据被传输到TLB(MMU),并通过将其与虚拟地址的偏移部分组合来翻译物理地址。如果低两位为00,则生成故障。如果是其他两个值中的任意一个,则MMU执行两级搜索。
//注意:发生Page Table Walk的前提是TLB已经未命中了
14.5.2 Two-Step Page Table Walk
如果MMU在搜索大小为1KB、4KB、16KB或64KB的页面时结束搜索,那么页表遍历将需要两个步骤来找到地址转换。图14.10详细描述了保存在粗略L2页表中的两阶段过程。请注意,虚拟地址分为三个部分。
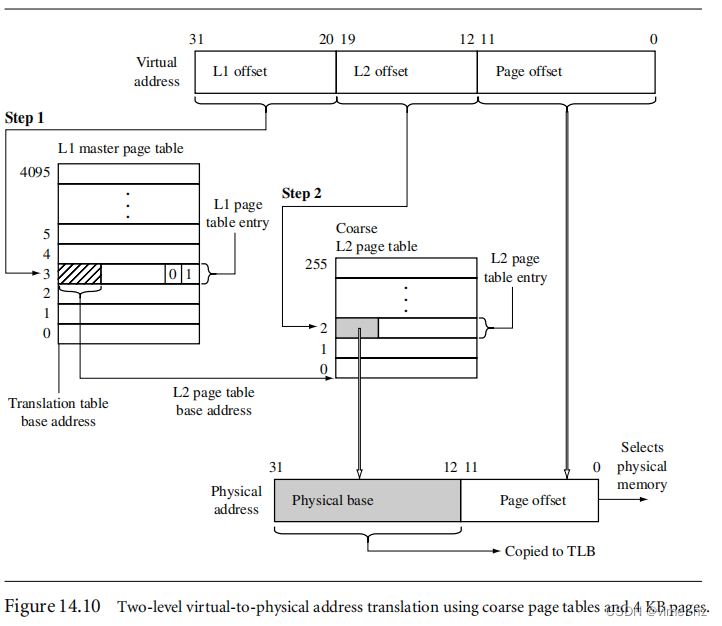
在第一步中,使用L1偏移部分作为索引进入主L1页表,并找到虚拟地址对应的L1 PTE。如果PTE的低两位包含二进制值01,则该条目包含到粗略页的L2页表基地址(参见图14.6)。
在第二步中,将L2偏移与在第一阶段找到的L2页表基地址相结合;得到的地址选择包含页面翻译的PTE。MMU将L2 PTE中的数据传输到TLB,并将基地址与虚拟地址的偏移部分相结合,生成所请求的物理内存地址。
14.5.3 TLB Operations
如果操作系统更改页表中的数据,缓存在TLB中的翻译数据可能不再有效。为了使TLB中的数据无效,核心具有CP15指令来刷新TLB。有几个可用的指令(参见表14.3):一个用于刷新所有TLB数据,一个用于刷新指令TLB,另一个用于刷新数据TLB。TLB也可以逐行刷新。
以下是一个简单的C例程14.2,用于使TLB无效。
void flushTLB(void)
{
unsigned int c8format = 0;
__asm{MCR p15, 0, c8format, c8, c7, 0 } /* flush TLB */
}14.5.4 TLB Lockdown
ARM920T、ARM922T、ARM926EJ-S、ARM1022E和ARM1026EJ-S支持在TLB中锁定翻译。如果在TLB中锁定了一行,当发出TLB刷新命令时,它将保留在TLB中。我们在表14.4中列出了各种ARM核心可用的锁定命令。用于在MCR指令中锁定TLB中数据的核心寄存器Rd的格式如图14.11所示。


14.6 Domains and Memory Access Permission
有两种不同的控制方式来管理任务对内存的访问权限:主要控制方式是域(domain),而次要控制方式是在页表中设置的访问权限。
通过隔离内存区域,域控制对虚拟内存的基本访问,当共享一个共同的虚拟内存映射时将一个内存区域与另一个隔离开来。可以将16个不同的域分配给1MB的虚拟内存段,并通过设置主L1 PTE中的域位字段来为段分配域(见图14.6)。
当为一个段分配了一个域时,它必须遵守分配给该域的域访问权限。域访问权限存储在CP15:c3寄存器中,并控制处理器核心对虚拟内存段的访问能力。
CP15:c3寄存器使用两个位来定义每个域的访问权限,用于说明16个可用域的值和含义。表14.5显示了域访问位字段的值和含义。图14.12给出了CP15:c3:c0寄存器的格式,该寄存器存储了域访问控制信息。图中将16个可用域标记为D0到D15。


即使您不使用MMU提供的虚拟内存功能,您仍然可以将这些核心用作简单的内存保护单元:首先,通过直接映射虚拟内存到物理内存,并为每个任务分配一个不同的域,然后使用域将休眠任务的域访问权限设置为“无访问”来保护它们。
14.6.1 Page-Table-Based Access Permissions
PTE中的AP位确定页面的访问权限。AP位显示在图14.6和图14.8中。表14.6展示了MMU如何解释AP位字段中的两个位。
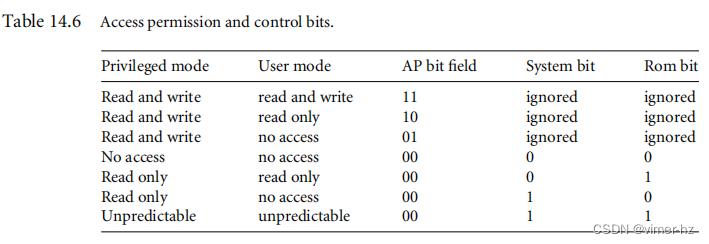
除了PTE中的AP位外,CP15:c1控制寄存器中还有两个位全局地修改对内存的访问权限:系统(S)位和只读(R)位。这些位可用于在操作期间的不同时间段从系统中提取大块内存。
设置S位将所有具有“无访问”权限的页面更改为允许特权模式任务的读访问。因此,通过改变CP15:c1中的单个位,所有标记为无访问的区域都可以立即使用,而无需更改每个PTE中的AP位字段。
改变R位将所有具有“无访问”权限的页面更改为允许特权模式和用户模式任务的读访问。同样,这个位可以加速对大块内存的访问,无需改变大量的PTE。
14.7 The Caches and Write Buffer
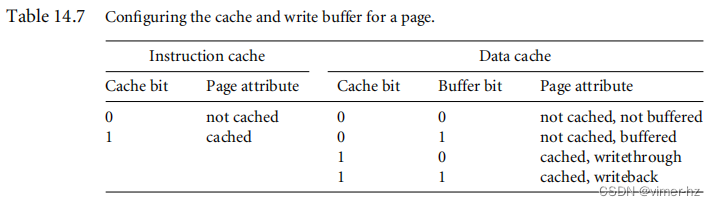
我们在第12章介绍了缓存和写缓冲区的基本操作。您可以使用PTE中的两个位来为内存中的每个页面配置缓存和写缓冲区(参见图14.6和图14.8)。在配置指令页时,忽略写缓冲区位,而缓存位确定缓存操作。当该位设置时,页面被缓存;当该位清除时,页面不被缓存。
在配置数据页面时,写缓冲区位有两种用途:启用或禁用页面的写缓冲区,并设置页面缓存的写策略。缓存位控制着写缓冲区位的含义。当缓存位为零时,当写缓冲区位值为1时,缓冲区位启用写缓冲区;当写缓冲区位值为0时,缓冲区位禁用写缓冲区。当缓存位设置为1时,写缓冲区被启用,并且缓冲区位的状态决定了缓存的写策略。如果缓冲区位为0,则页面使用写直通策略;如果缓冲区位被设置,则使用写回策略。请参阅表14.7,该表以表格形式展示了各种缓存和写缓冲区位的状态及其含义。
14.8 Coprocessor 15 and MMU Configuration
我们在第12章首次介绍了changeControl过程。示例14.3重新讲解了changeControl过程,该过程用于启用MMU、缓存和写缓冲区。控制MMU操作的控制寄存器值显示在表格14.8和图14.13中。ARM720T、ARM920T和ARM926EJ-S在控制寄存器的相同位置上具有控制MMU启用位[0]和缓存启用位[2]。ARM720T和ARM1022E还具有写缓冲区启用位[3]。ARM920T、ARM922T和ARM926EJS具有分离的指令和数据缓存,需要一个额外的位来启用I-cache,即位[12]。所有支持MMU的处理器核心都可以将向量表更改为高内存的地址0xffff0000,位[13]。

对于这三个核心,使能配置的MMU非常相似。要启用MMU、缓存和写缓冲区,您需要在控制寄存器中更改位[12]、位[3]、位[2]和位[0]。changeControl过程操作寄存器CP15:c1:c0:0,以更改控制寄存器c1中的值。示例14.3提供了一个设置控制寄存器位的小型C例程;它使用以下函数原型进行调用:
void controlSet(unsigned int value, unsigned int mask)
传递给该过程的第一个参数是一个无符号整数,其中包含您想要更改的控制值的状态。第二个参数mask是一个位模式,用于选择需要更改的位。在mask变量中设置为1的位将使CP15:c1c0寄存器中的相应位更改为value输入参数中相同位的值。如果为0,则无论value参数中的位状态如何,都不会更改控制寄存器中的位。
示例14.3 控制过程controlSet设置了CP15:c1中的控制位寄存器。该过程首先读取CP15:r3寄存器,并将其放入变量c1format中。然后,该过程使用输入的掩码值来清除c1format中需要更新的位。更新是通过将c1format与value输入参数进行或操作来完成的。最终更新的c1format被写回到CP15:c1寄存器中,以启用MMU、缓存和写缓冲区。
void controlSet(unsigned int value, unsigned int mask)
{
unsigned int c1format;
__asm{MRC p15, 0, c1format, c1, c0, 0 } /* read control register */
c1format &= ∼mask;
/* clear bits that change */
c1format |= value;
/* set bits that change */
__asm{MCR p15, 0, c1format, c1, c0, 0 } /* write control register */
}以下是一个调用controlSet过程的代码序列,用于在ARM920T中启用I-cache、D-cache和MMU:
#define ENABLEMMU 0x00000001
#define ENABLEDCACHE 0x00000004
#define ENABLEICACHE 0x00001000
#define CHANGEMMU 0x00000001
#define CHANGEDCACHE 0x00000004
#define CHANGEICACHE 0x00001000
unsigned int enable, change;
#if defined(__TARGET_CPU_ARM920T)
enable = ENABLEMMU | ENABLEICACHE | ENABLEDCACHE;
change = CHANGEMMU | CHANGEICACHE | CHANGEDCACHE;
#endif
controlSet(enable, change);14.9 The Fast Context Switch Extension
快速上下文切换扩展(FCSE)是MMU中的附加硬件,被认为是一种增强特性,可以提高ARM嵌入式系统的系统性能。FCSE使多个独立任务在内存的固定重叠区域中运行,无需在上下文切换期间清理或刷新缓存或刷新TLB。FCSE的关键特性是消除了清空缓存和TLB的必要性。
如果没有FCSE,从一个任务切换到另一个任务需要改变虚拟内存映射。如果更改涉及到两个具有重叠地址范围的任务,则缓存和TLB中存储的信息会变得无效,系统必须清空缓存和TLB。清空这些组件的过程会增加任务切换的时间,因为核心不仅必须清除无效数据的缓存和TLB,还必须重新从主存中加载数据到缓存和TLB中。
使用FCSE时,在管理虚拟内存时会有额外的地址转换。FCSE使用一个包含进程ID值的特殊重定位寄存器,在到达缓存和TLB之前修改虚拟地址。ARM将第一次转换前的虚拟内存地址称为虚拟地址(VA),将第一次转换后的地址称为修改后的虚拟地址(MVA),如图14.4所示。使用FCSE时,所有修改后的虚拟地址都是活动的。通过使用域访问权限来阻止对休眠任务的访问,来保护任务。我们在下一节中将详细讨论这一点。

在任务之间切换不涉及更改页表;它只需要将新任务的进程ID写入位于CP15中的FCSE进程ID寄存器中。由于任务切换不需要更改页表,所以在切换后缓存和TLB仍然有效,不需要清空。
使用FCSE时,每个任务必须在虚拟地址范围从0x00000000到0x1FFFFFFF的固定虚拟地址范围内执行,并且必须位于不同的32 MB的修改后的虚拟内存区域中。系统共享所有大于0x2000000的内存地址,并使用域来保护任务之间的隔离。当前运行的任务由其当前的进程ID来标识。
要利用FCSE,在编译和链接所有任务以在虚拟内存(VA)的第一个32 MB块中运行并分配唯一的进程ID。然后,使用以下重定位公式将每个任务放置在不同的32 MB修改后的虚拟内存分区中:
MVA = VA + (0x2000000 ∗ process ID) (14.2)
要计算修改后虚拟内存中任务分区的起始地址,可以将VA和任务的进程ID的值置为零,并将这些值代入方程式(14.2)中。
CP15:c13:c0寄存器中保存的值包含当前的进程ID。寄存器中的进程ID位字段宽度为7位,支持128个进程ID。寄存器的格式如图14.15所示。

示例14.4展示了一个小的例程processIDSet,用于设置FCSE中的进程ID。可以使用以下函数原型调用它:
void processIDSet(unsigned value);
示例14.4
该例程接受一个无符号整数作为输入,将其剪辑为七位,并通过将该值乘以0x20000000(32 MB)来对128取模,然后使用MCR指令将结果写入进程ID寄存器。
void processIDSet(unsigned int value)
{
unsigned int PID;
PID = value << 25;
__asm{MCR p15, 0, PID, c13, c0, 0 } /* write Process ID register */
}14.9.1 How the FCSE Uses Page Tables and Domains
为了有效使用FCSE,系统使用页表来控制区域配置和操作,并使用域来隔离任务。再次参考图14.14,该图显示了从Task 1切换到Task 2的上下文切换前后的内存布局。表14.9显示了创建图14.14所使用的数值细节。

图14.16展示了如何通过更改CP15:c3:c0中域访问寄存器的值从Task 1切换到Task 2。在任务之间切换需要更改进程ID,并在域访问寄存器中添加一个新条目。

表14.9显示Task 1被分配给域 1,而Task 2则被分配给域 2。当从Task 1切换到Task 2时,将域访问寄存器更改为允许对域 2 进行客户端访问,并且对域 1 没有访问权限。这样可以防止Task 2访问Task 1的内存空间。请注意,对于内核域 0,客户端访问权限保持不变。这使得页表可以控制对系统内存区域的访问。
通过使用“共享”域,可以在任务之间共享内存,如图14.16和表14.9中的域 15所示。共享域在图14.15中没有显示。任务可以共享一个允许客户端访问修改后的虚拟内存分区的域。这种共享内存可以被两个任务看到,并且访问权限由映射内存空间的页表项确定。
以下是在使用FCSE时执行上下文切换所需的步骤:
1.保存活动任务的上下文,并将任务置于休眠状态。
2.将待唤醒任务的进程ID写入CP15:c13:c0中。
3.通过写入CP15:c3:c0,将当前任务的域设置为无访问权限,将待唤醒任务的域设置为客户端访问权限。
4.恢复待唤醒任务的上下文。
5.恢复任务的执行。
14.9.2 Hints for Using the FCSE
■ 一个任务的大小有一个固定的最大限制为32MB。
■ 内存管理器必须使用32MB大小的固定分区,且起始地址必须是32MB的倍数。
■ 除非您想为每个任务管理一个异常向量表,否则可以使用CP15寄存器1中的V位将异常向量表放置在虚拟地址0xffff0000处。
■ 您必须定义并使用一个活动域控制系统。
■ 当进程ID从上一个进程空间变化时,核心会获取执行位于第一个32MB块内的两条指令。因此,最好从内存中的“固定”区域切换任务。
■ 如果您使用域来控制任务访问,那么正在运行的任务也会在虚拟内存中以VA + (0x2000000 * 进程ID)的形式出现为别名。
■ 如果您使用域来保护任务之间的隔离,除非愿意在上下文切换时修改级别1页表中的域字段并刷新TLB,否则最多只能同时运行16个任务。
14.10 Demonstration: A Small Virtual Memory System
这是一个小型嵌入式系统的基础原理演示,使用虚拟内存。它设计用于在ARM720T或ARM920T核心上运行。该演示提供了一个静态的多任务系统,展示了运行三个并发任务所需的基础设施。我们使用ARM ADS1.2开发套件编写了这个演示。有很多方法可以改进演示,但它的主要目的是帮助理解底层ARM MMU硬件。演示没有展示分页或交换到辅助存储器的功能。
演示中所有用户任务使用相同的执行区域,这简化了这些任务的编译和链接。每个任务被编译为一个独立的程序,在单个区域中包含文本、数据和堆栈信息。
硬件要求是一个基于ARM的评估板,其中包括一个ARM720T或ARM920T处理器核心。该示例需要从地址0x00000000开始的256 KB RAM,并且需要一种将代码和数据加载到内存中的方法。此外,还有几个内存映射的外设分布在从地址0x10000000到0x20000000的256 MB范围内。
软件要求是一个操作系统基础设施,比如前面章节中提供的SLOS。系统必须支持固定分区多任务处理。该示例仅使用1 MB和4 KB页面。但是,编码示例支持所有的页面大小。任务限制在小于1 MB,因此可以适应单个L2页表。因此,通过更改主L1页表中的单个L2 PTE即可执行任务切换。这种方法比尝试为每个任务创建和维护一整套页表,并在每次上下文切换时更改TTB地址要简单得多。更改TTB以在任务内存映之间切换将需要创建主表和所有L2系统表的三组不同的页表。这还需要额外的内存来存储这些额外的页表。交换单个L2表的目的是消除多组页表中系统信息的重复。减少重复页表的数量减少了运行系统所需的内存。
我们使用七个步骤来设置演示的MMU:
1. 定义固定的系统软件区域;此固定区域在图14.5中显示。
2. 为三个任务定义三个虚拟内存映射;这些映射的一般布局在图14.4中显示。
3. 将步骤1和2中列出的区域定位到物理内存映射中;这是图14.5右侧所示的实现。
4. 在页表区域内定义并定位页表。
5. 定义用于创建和管理区域和页表的数据结构。这些结构是与实现相关的,特定于示例进行定义。但是,这些结构的一般形式对大多数简单系统来说是一个很好的起点。
6. 初始化MMU、缓存和写缓冲区。
7. 设置上下文切换例程,以优雅地从一个任务过渡到下一个。
我们将在下面的章节中详细介绍这些步骤。
14.10.1 Step 1: Define the Fixed System Software Regions
操作系统使用四个固定的系统软件区域:0x00000处的专用32 KB内核区域,0x8000处的32 KB共享内存区域,0x10000处的专用32 KB页表区域以及0x10000000处的256 MB外围区域(见图14.17)。我们在初始化过程中定义这些区域,并永远不会再次更改它们的页表。

特权内核区域用于存储系统软件,包括操作系统内核代码和数据。该区域使用固定寻址方式,避免在切换到系统模式上下文时重新映射的复杂性。它还包含了处理FIQ、IRQ、SWI、UND和ABT异常的向量表和堆栈。
共享内存区域位于虚拟内存中的固定地址。所有任务都使用此区域来访问共享的系统资源。共享内存区域包含了共享库以及在上下文切换期间从特权模式切换到用户模式的过渡例程。
页表区域包含五个页表。虽然页表区域大小为32 KB,但系统仅使用20 KB:16 KB用于主表,每个L2表使用1 KB。
外围区域控制系统设备I/O空间。这个区域的主要目的是将此区域设置为不缓存、不缓冲区域。您不希望输入、输出或控制寄存器受到缓存的过期数据问题或使用写缓冲区所涉及的时间序列延迟。此区域还防止用户模式访问外围设备;因此,必须通过设备驱动程序访问这些设备。此区域仅允许特权访问;不允许用户访问。在演示中,这是一个单独的区域,但在更精细的系统中,将定义更多的区域,以提供对各个设备的更细粒度的控制。
14.10.2 Step 2: Define Virtual Memory Maps for Each Task
在三个时间片间隔内运行三个用户任务。每个任务都有相同的虚拟内存映射。
每个任务在其内存映射中看到两个区域:0x400000处的专用32 KB任务区域,以及0x8000处的32 KB共享内存区域(见图14.18)。
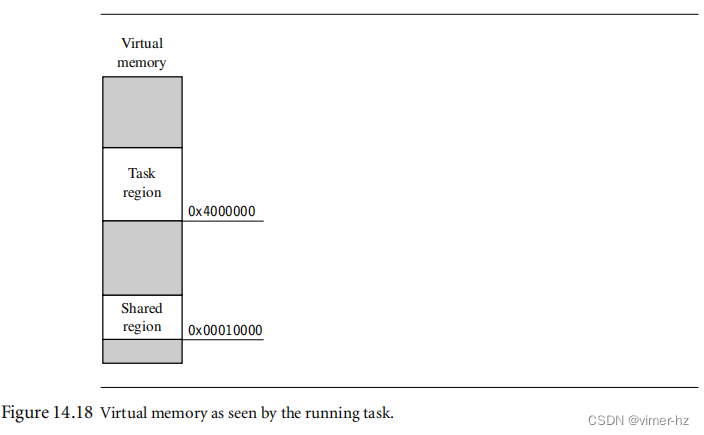
任务区域包含正在运行的用户任务的代码、数据和堆栈。当调度器从一个任务转移到另一个任务时,它必须通过改变L1页表项来重新映射任务区域,使其指向即将运行的任务的L2页表。完成这个映射后,任务区域将指向下一个运行任务的物理位置。
共享区域是一个固定的系统软件区域。其功能在第14.10.1节中描述。
14.10.3 Step 3: Locate Regions in Physical Memory
我们为演示定义的区域必须位于物理内存中不重叠或冲突的地址。表14.10显示了我们在物理内存中定位所有区域及其虚拟地址和大小的位置。该表还列出了每个区域的页面大小选择以及需要翻译的页面数,以支持每个区域的大小。
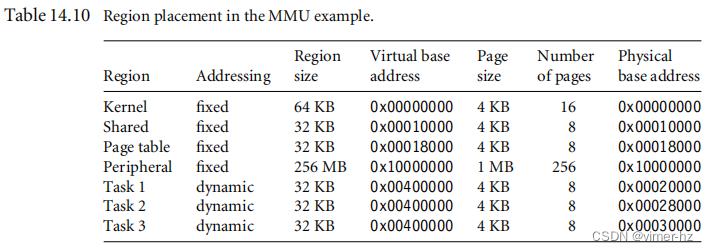
表14.10列出了在系统操作期间使用固定页表的四个区域:内核、共享内存、页表和外围区域。
任务区域在系统运行过程中动态更改页表。任务区域将相同的虚拟地址翻译为不同的物理地址,这取决于正在运行的任务。
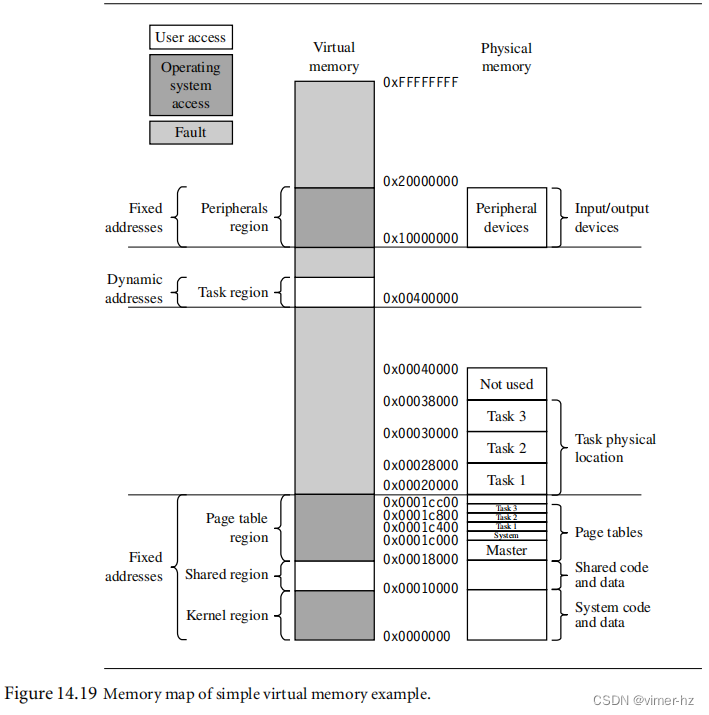
图14.19以图形方式显示了区域在虚拟内存和物理内存中的放置位置。内核、共享内存和页表区域直接映射到物理内存,作为连续页帧块。在此区域之上是专用于三个用户任务的页帧。物理内存中的任务是32 KB的固定分区,也是连续的页帧。稀疏地分布在256 MB的物理内存中的是内存映射的外围I/O设备。
14.10.4 Step 4: Define and Locate the Page Tables
我们先前分配了一个区域来保存系统中的页表。下一步是将实际的页表定位到物理内存的区域内。图14.20显示了页表区域映射到物理内存的近距离细节。这是图14.19中显示的页表的放大图。我们稍微展开了内存,以显示L1主页表和四个L2页表之间的关系。我们还展示了页表中的翻译数据的位置。
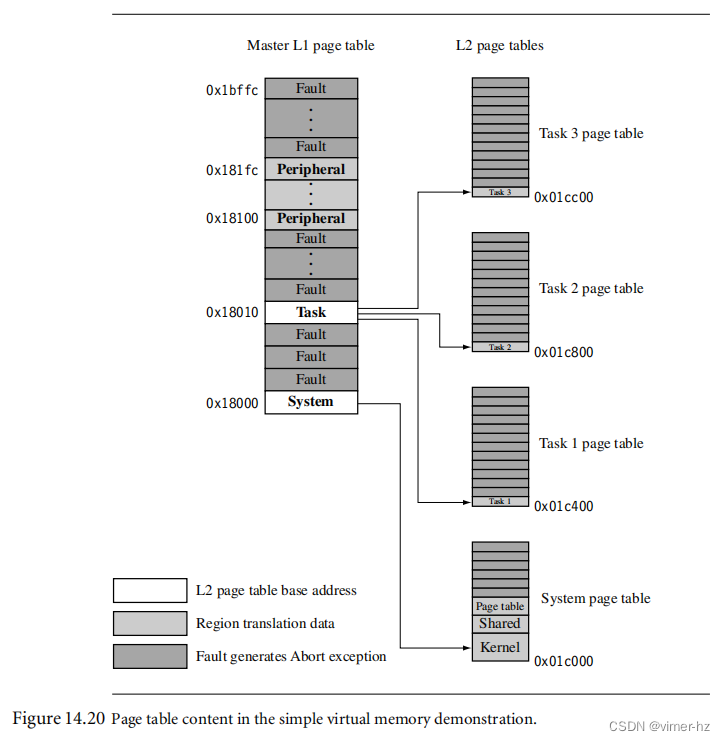
一个主L1页表定位L2表并翻译外围区域的1 MB部分。系统L2页表包含三个系统区域的翻译地址数据:内核区域、共享内存区域和页表区域。有三个任务L2页表,分别映射到三个并发任务的物理地址。
运行时只有五个页表中的三个同时处于活动状态:L1主表、L2系统表和三个L2任务页表中的一个。
调度器通过在上下文切换期间重新映射任务区域来控制哪个任务处于活动状态,哪些任务处于休眠状态。具体而言,在上下文切换期间,位于地址0x18010处的主L1页表项会更改为指向下一个活动任务的L2页表基址。
14.10.5 Step 5: Define Page Table and Region Data Structures
对于这个例子,我们定义了两个数据结构来配置和控制系统。这两个数据结构代表了用于定义和初始化前几节中讨论的页表和区域的实际代码。我们定义了两种数据类型,一种是包含页表数据的Pagetable类型,另一种是定义和控制系统中每个区域的Region类型。
Pagetable结构的类型定义,以及对Pagetable结构成员的描述如下:
typedef struct {
unsigned int vAddress;
unsigned int ptAddress;
unsigned int masterPtAddress;
unsigned int type;
unsigned int dom;
} Pagetable;■ vAddress标识由段条目或L2页表控制的虚拟内存中1MB部分的起始地址。
■ ptAddress是页表在虚拟内存中的位置。
■ masterPtAddress是父主L1页表的地址。如果该表是L1表,则该值与ptAddress相同。
■ type标识页表的类型,可以是COARSE、FINE或MASTER。
■ dom设置分配给L1表项的1MB内存块的域。
我们使用Pagetable类型来定义系统中使用的五个页表。这些Pagetable结构共同形成了一个页表数据块,我们使用它来管理、填充、定位、识别和设置所有活动和非活动页表的域。在接下来的演示中,我们将称这个Pagetables块为页表控制块(PTCB)。
前面章节中描述的五个Pagetables在图14.20中显示出来,并附带它们的初始化值,它们分别是:
#define FAULT 0
#define COARSE 1
#define MASTER 2
#define FINE 3
/* Page Tables */
/* VADDRESS, PTADDRESS, PTTYPE, DOM */
Pagetable masterPT = {0x00000000, 0x18000, 0x18000, MASTER, 3};
Pagetable systemPT = {0x00000000, 0x1c000, 0x18000, COARSE, 3};
Pagetable task1PT = {0x00400000, 0x1c400, 0x18000, COARSE, 3};
Pagetable task2PT = {0x00400000, 0x1c800, 0x18000, COARSE, 3};
Pagetable task3PT = {0x00400000, 0x1cc00, 0x18000, COARSE, 3};Region结构的类型定义,以及对Region结构成员的描述如下:
typedef struct {
unsigned int vAddress;
unsigned int pageSize;
unsigned int numPages;
unsigned int AP;
unsigned int CB;
unsigned int pAddress;
Pagetable *PT;
} Region;■ vAddress是区域在虚拟内存中的起始地址。
■ pageSize是虚拟页的大小。
■ numPages是该区域中页面的数量。
■ AP是区域的访问权限。
■ CB是区域的缓存和写缓冲区属性。
■ pAddress是区域在虚拟内存中的起始地址。
■ *PT是指向包含该区域的Pagetable的指针。
所有的Region数据结构共同形成了第二个数据块,我们使用它来定义系统中使用的区域的大小、位置、访问权限、缓存和写缓冲区操作以及页表位置。在接下来的演示中,我们将称这个Region块为区域控制块(RCB)。
这里有七个Region结构,它们定义了前面章节中描述的区域,并在图14.19中显示出来。以下是RCB中四个系统软件和三个任务区域的初始化值:
#define NANA 0x00
#define RWNA 0x01
#define RWRO 0x02
#define RWRW 0x03
/* NA = no access, RO = read only, RW = read/write */
#if defined(__TARGET_CPU_ARM920T)
#define cb 0x0
#define cB 0x1
#define WT 0x2
#define WB 0x3
#endif
/* 720 */
#if defined(__TARGET_CPU_ARM720T)
#define cb 0x0
#define cB 0x1
#define Cb 0x2
#define WT 0x3
#endif
/* cb = not cached/not buffered */
/* cB = not Cached/Buffered */
/* Cb = Cached/not Buffered */
/* WT = write through cache */
/* WB = write back cache */
/* REGION TABLES */
/* VADDRESS, PAGESIZE, NUMPAGES, AP, CB, PADDRESS, &PT */
Region kernelRegion
= {0x00000000, 4, 16, RWNA, WT, 0x00000000, &systemPT};
Region sharedRegion
= {0x00010000, 4, 8, RWRW, WT, 0x00010000, &systemPT};
Region pageTableRegion
= {0x00018000, 4, 8, RWNA, WT, 0x00018000, &systemPT};
Region peripheralRegion
= {0x10000000, 1024, 256, RWNA, cb, 0x10000000, &masterPT};
/* Task Process Regions */
Region t1Region
= {0x00400000, 4, 8, RWRW, WT, 0x00020000, &task1PT};
Region t2Region
= {0x00400000, 4, 8, RWRW, WT, 0x00028000, &task2PT};
Region t3Region
= {0x00400000, 4, 8, RWRW, WT, 0x00030000, &task3PT}14.10.6 Step 6: Initialize the MMU, Caches, and Write Buffer
在激活MMU、缓存和写缓冲区之前,它们必须进行初始化。PTCB和RCB保存了这三个组件的配置数据。有五个部分需要初始化MMU:
1. 通过用FAULT条目填充它们来初始化主存中的页表。
2. 使用映射将区域映射到物理内存,填充页表。
3. 激活页表。
4. 分配域访问权限。
5. 启用内存管理单元和高速缓存硬件。

前四个部分配置系统,最后一个部分启用系统。在接下来的章节中,我们提供了执行初始化过程的五个部分的例程;这些例程按功能和示例编号在图14.21中列出。
14.10.6.1 Initializing the Page Tables in Memory
初始化MMU的第一部分是将页表设置为已知状态。最简单的方法是用FAULT页表条目填充页表。使用FAULT条目可以确保在PTCB定义的范围之外不存在有效的转换。通过将所有活动页表中的所有页表条目设置为FAULT,系统将生成一个异常中断,以指示使用PTCB填充的条目稍后才会被填入。
例子14.5
函数mmuInitPT通过使用分配给页表的内存区域并设置FAULT值来初始化页表。它使用以下函数原型进行调用:
void mmuInitPT(Pagetable *pt);
这个例程接受一个参数,即指向PTCB中的Pagetable的指针。
void mmuInitPT(Pagetable *pt)
{
int index; /* number of lines in PT/entries written per loop*/
unsigned int PTE, *PTEptr; /* points to page table entry in PT */
PTEptr = (unsigned int *)pt->ptAddress; /* set pointer base PT */
PTE = FAULT;
switch (pt->type)
{
case COARSE: {index = 256/32; break;}
case MASTER: {index = 4096/32; break;}
#if defined(__TARGET_CPU_ARM920T)
case FINE: {index = 1024/32; break;} /* no FINE PT in 720T */
#endif
default:
{
printf("mmuInitPT: UNKNOWN pagetable type\n");
return -1;
}
}
__asm
{
mov r0, PTE
mov r1, PTE
mov r2, PTE
mov r3, PTE
}
for (; index != 0; index--)
{
__asm
{
STMIA PTEptr!, {r0-r3} /* write 32 entries to table */
STMIA PTEptr!, {r0-r3}
STMIA PTEptr!, {r0-r3}
STMIA PTEptr!, {r0-r3}
STMIA PTEptr!, {r0-r3}
STMIA PTEptr!, {r0-r3}
STMIA PTEptr!, {r0-r3}
STMIA PTEptr!, {r0-r3}
}
}
return 0;
}mmuInitPT从基本页表地址PTEptr开始,并用FAULT条目填充页表。表的大小通过读取pt->type中定义的Pagetable类型来确定。表类型可以是具有4096个条目的主L1页表,具有256个条目的粗糙L2页表,或具有1024个条目的细致L2页表。
该例程通过使用循环将小块写入内存来填充表格。例程根据页表中的条目数除以每个循环写入的条目数来确定要写入的块数。switch语句选择Pagetable类型,并跳转到设置表索引大小的情况。通过执行填充表的循环来完成过程。请注意__asm关键字用于调用内联汇编程序;这通过使用stmia存储多个指令来减少循环的执行时间。
14.10.6.2 Filling Page Tables with Translations
初始化MMU的第二部分是将RCB中保存的数据转换为页表条目,并将它们复制到页表中。我们提供了几个例程来将RCB中的数据转换为页表条目。第一个高级例程mmuMapRegion确定了页表的类型,然后调用三个例程之一来创建页表条目:mmuMapSectionTableRegion、mmuMapCoarseTableRegion或mmuMapFineTableRegion。
为了方便将来的代码移植,我们建议不使用tiny pages和mmuMapFineTableRegion例程,因为ARMv6架构不使用tiny page。在ARMv6架构中,细粒度页表类型也已被移除,因为没有tiny pages的需要。
下面是四个例程的描述:
- mmuMapRegion例程确定页表类型并跳转到下面列出的例程之一;示例代码见14.6节。
- mmuMapSectionTableRegion例程使用section条目填充L1主表;示例代码见14.7节。
- mmuMapCoarseTableRegion例程使用region条目填充L2粗糙页表;示例代码见14.8节。
- mmuMapFineTableRegion例程使用region条目填充L2细粒度页表;示例代码见14.9节。
以下是这四个例程的C函数原型列表:
int mmuMapRegion(Region *region);
void mmuMapSectionTableRegion(Region *region);
int mmuMapCoarseTableRegion(Region *region);
int mmuMapFineTableRegion(Region *region);
这四个过程都有一个输入参数,即指向包含生成页表条目所需配置数据的Region结构的指针。
示例14.6中是选择页表类型的高级例程。
int mmuMapRegion(Region *region)
{
switch (region->PT->type)
{
case SECTION:
/* map section in L1 PT */
{
mmuMapSectionTableRegion(region);
break;
}
case COARSE:
/* map PTE to point to COARSE L2 PT */
mmuMapCoarseTableRegion(region);
break;
}
#if defined(__TARGET_CPU_ARM920T)
case FINE:
/* map PTE to point to FINE L2 PT */
{
mmuMapFineTableRegion(region);
break;
}
#endif
default:
{
printf("UNKNOWN page table type\n");
return -1;
}
}
return 0;
}在Region结构中,包含了指向Pagetable的指针,该Pagetable中包含了区域翻译数据。这个例程确定了页表类型region->PT->type,并调用一个例程将该区域以指定的页表类型的格式映射到页表中。
对于三种类型的页表(section,粗糙和细粒度),分别有各自独立的过程(参见第14.4节)。
以下是其中之一的三个例程,用于将区域数据转换为页表条目。
void mmuMapSectionTableRegion(Region *region)
{
int i;
unsigned int *PTEptr, PTE;
PTEptr = (unsigned int *)region->PT->ptAddress; /* base addr PT */
PTEptr += region->vAddress >> 20; /* set to first PTE in region */
PTEptr += region->numPages - 1; /* set to last PTE in region */
PTE = region->pAddress & 0xfff00000; /* set physical address */
PTE |= (region->AP & 0x3) << 10; /* set Access Permissions */
PTE |= region->PT->dom << 5; /* set Domain for section */
PTE |= (region->CB & 0x3) << 2; /* set Cache & WB attributes */
PTE |= 0x12;
/* set as section entry */
for (i =region->numPages - 1; i >= 0; i--) /* fill PTE in region */
{
*PTEptr-- = PTE + (i << 20);
/* i = 1 MB section */
}
}mmuMapSectionTableRegion过程首先将一个局部指针变量PTEptr设置为主L1页表的基地址。然后,它使用区域的虚拟起始地址创建一个索引,该索引指向区域页表条目在页表中的位置。这个索引被加到变量PTEptr上,使得PTEptr指向页表中区域条目的起始位置。下一行代码计算出区域的大小,并将该值加到PTEptr上。现在,变量PTEptr指向区域的最后一个PTE。
PTEptr变量设置为区域的末尾,这样我们可以在填充页表条目的循环中使用倒计数器。
接下来,该例程使用Region结构中的值构建一个section页表条目,并将其保存在局部变量PTE中。通过一系列的按位或操作,从起始物理地址、访问权限、域和缓存以及写缓冲区属性构造了这个PTE。PTE的格式如图14.6所示。
现在,PTE中包含了指向区域第一个物理地址及其属性的指针。计数器变量i用于两个目的:作为页表的偏移量,并且加到PTE变量上,以增加页面帧的物理地址转换。请记住,在演示中,所有的区域都映射到物理内存中的连续页面帧。
该过程通过将所有的区域PTE写入页表来结束。它从最后一个翻译条目开始,逐个向前计数到第一个翻译条目。
int mmuMapCoarseTableRegion(Region *region)
{
int i,j;
unsigned int *PTEptr, PTE;
unsigned int tempAP = region->AP & 0x3;
PTEptr = (unsigned int *)region->PT->ptAddress; /* base addr PT */
switch (region->pageSize)
{
case LARGEPAGE:
{
PTEptr += (region->vAddress & 0x000ff000) >> 12; /* 1st PTE */
PTEptr += (region->numPages*16) - 1; /* region last PTE */
PTE = region->pAddress & 0xffff0000; /* set physical address */
PTE |= tempAP << 10; /* set Access Permissions subpage 3 */
PTE |= tempAP << 8;
/* subpage 2 */
PTE |= tempAP << 6;
/* subpage 1 */
PTE |= tempAP << 4;
/* subpage 0 */
PTE |= (region->CB & 0x3) << 2; /* set cache & WB attributes */
PTE |= 0x1;
/* set as LARGE PAGE */
/* fill in table entries for region */
for (i = region->numPages-1; i >= 0; i--)
{
for (j = 15 ; j >= 0; j--)
*PTEptr-- = PTE + (i << 16); /* i = 64 KB large page */
}
break;
}
case SMALLPAGE:
{
PTEptr += (region->vAddress & 0x000ff000) >> 12; /* first */
PTEptr += (region->numPages - 1);
/* last PTEptr */
PTE = region->pAddress & 0xfffff000; /* set physical address */
PTE |= tempAP << 10; /* set Access Permissions subpage 3 */
PTE |= tempAP << 8;
/* subpage 2 */
PTE |= tempAP << 6;
/* subpage 1 */
PTE |= tempAP << 4;
/* subpage 0 */
PTE |= (region->CB & 0x3) << 2; /* set cache & WB attrib */
PTE |= 0x2;
/* set as SMALL PAGE */
/* fill in table entries for region */
for (i = region->numPages - 1; i >= 0; i--)
{
*PTEptr-- = PTE + (i << 12); /* i = 4 KB small page */
}
break;
}
default:
{
printf("mmuMapCoarseTableRegion: Incorrect page size\n");
return -1;
}
}
return 0;
}该例程首先设置一个名为tempAP的局部变量,用于保存区域中页面或子页面的访问权限。接下来,它将变量PTEptr设置为指向将保存映射区域的页表的基地址。
然后,该过程根据是大页面还是小页面进行处理。这两种情况的算法是相同的,只是PTE的格式和写入页表的方式不同。
此时,变量PTEptr包含L2页表的起始地址。然后,该例程使用区域region->vAddress的起始地址来计算在页表中指向区域第一个条目的索引。将该索引值加到PTEptr上。
接下来一行代码计算出区域的大小,并将该值加到PTEptr上。现在,PTEptr指向区域的最后一个PTE。
然后,该例程根据传入的区域值构建一个大页面或小页面的页表条目变量PTE。该例程使用一系列的按位或操作来从区域中的起始物理地址、访问权限以及缓存和写缓冲区属性构建PTE。请参考图14.8来查看大页面和小页面PTE的格式。
现在,PTE包含指向区域第一个页面帧的物理地址的指针。计数器变量i用于两个目的:首先,它是页表的偏移量;其次,它加到PTE变量上,以修改地址转换位字段,使其指向物理内存中的下一个更低的页面帧。该例程最后通过将所有区域的PTE写入页表来结束。请注意,在LARGEPAGE情况下有一个嵌套的循环:j循环将所需的相同PTE写入粗略页表以映射一个大页面(详见第14.4节)。
示例14.9
这个示例填充了一个细粒度页表的区域翻译信息。细粒度页表在ARM720T中不可用,并在v6架构中已停用。为了与这些变化保持兼容性,我们建议在新项目中避免使用细粒度页表。
#if defined(__TARGET_CPU_ARM920T)
int mmuMapFineTableRegion(Region *region)
{
int i,j;
unsigned int *PTEptr, PTE;
unsigned int tempAP = region->AP & 0x3;
PTEptr = (unsigned int *)region->PT->ptAddress; /* base addr PT */
switch (region->pageSize)
{
case LARGEPAGE:
{
PTEptr += (region->vAddress & 0x000ffc00) >> 10; /* first PTE*/
PTEptr += (region->numPages*64) - 1;
/* last PTE */
PTE = region->pAddress & 0xffff0000; /* get physical address */
PTE |= tempAP << 10; /* set Access Permissions subpage 3 */
PTE |= tempAP << 8;
/* subpage 2 */
PTE |= tempAP << 6;
/* subpage 1 */
PTE |= tempAP << 4;
/* subpage 0 */
PTE |= (region->CB & 0x3) << 2; /* set cache & WB attrib */
PTE |= 0x1;
/* set as LARGE PAGE */
/* fill in table entries for region */
for (i = region->numPages-1; i >= 0; i--)
{
for (j = 63 ; j >= 0; j--)
*PTEptr-- = PTE + (i << 16); /* i = 64 KB large page */
}
break;
}
case SMALLPAGE:
{
PTEptr += (region->vAddress & 0x000ffc00) >> 10; /* first PTE*/
PTEptr += (region->numPages*4) - 1;
/* last PTE */
PTE = region->pAddress & 0xfffff000; /* get physical address */
PTE |= tempAP << 10; /* set Access Permissions subpage 3 */
PTE |= tempAP << 8;
/* subpage 2 */
PTE |= tempAP << 6;
/* subpage 1 */
PTE |= tempAP << 4;
/* subpage 0 */
PTE |= (region->CB & 0x3) << 2; /* set cache & WB attrib */
PTE |= 0x2;
/* set as SMALL PAGE */
/* fill in table entries for region */
for (i = region->numPages-1; i >= 0; i--)
{
for (j = 3 ; j >= 0; j--)
*PTEptr-- = PTE + (i << 12); /* i = 4 KB small page */
}
break;
}
case TINYPAGE:
{
PTEptr += (region->vAddress & 0x000ffc00) >> 10; /* first */
PTEptr += (region->numPages - 1);
/* last PTEptr */
PTE = region->pAddress & 0xfffffc00; /* get physical address */
PTE |= tempAP << 4;
/* set Access Permissions */
PTE |= (region->CB & 0x3) << 2; /* set cache & WB attribu */
PTE |= 0x3;
/* set as TINY PAGE */
/* fill table with PTE for region; from last to first */
for (i =(region->numPages) - 1; i >= 0; i--)
{
*PTEptr-- = PTE + (i << 10);
/* i = 1 KB tiny page */
}
break;
}
default:
{
printf("mmuMapFineTableRegion: Incorrect page size\n");
return -1;
}
}
return 0;
}
#endif该例程开始设置一个名为tempAP的局部变量,用于保存区域中页面或子页面的访问权限。该例程不支持具有不同访问权限的子页面。接下来,该例程将变量PTEptr设置为指向将保存精细页的区域的页表的基地址。
然后,该例程根据大页面、小页面或微小页面进行处理。这三种情况下的算法是相同的;只是PTE的格式和写入页表的方式不同。
在此时,变量PTEptr包含L2页表的起始地址。然后,该例程使用区域region->vAddress的起始地址来计算在页表中指向区域第一个条目的索引。将该索引值加到PTEptr上。
下一行代码确定区域的大小,并将该值加到PTEptr上。现在,PTEptr指向区域的最后一个PTE。
接下来,该例程根据区域中的值构建一个大页面、小页面或微小页面的PTE。通过一系列的按位或操作,将从区域中的起始物理地址、访问权限以及缓存和写缓冲区属性构建PTE。图14.8显示了大页面、小页面和微小页面的PTE格式。
现在,PTE包含指向第一个页面帧的物理地址的指针,以及区域的属性。计数器变量i用于两个目的:它是页表的偏移量,并且它加到PTE变量上,以修改地址转换,使其指向物理内存中下一个较低的页面帧。该例程通过循环直到将区域的所有PTE映射到页表中来结束。注意,在LARGEPAGE和SMALLPAGE情况下有一个嵌套循环:j循环将所需的相同PTE写入细粒度页表以正确映射给定页面。
14.10.6.3 Activating a Page Table
页表可以存在于内存中,但不被MMU硬件使用。这种情况发生在任务处于休眠状态并且其页表被映射到非活动虚拟内存之外时。然而,任务仍然驻留在物理内存中,因此当发生上下文切换以激活它时,它立即可用。
初始化MMU的第三部分是激活执行位于固定区域的代码所需的页表。
例如14.10
例程mmuAttachPT通过将地址放入CP15:c2:c0寄存器中的TTB来激活L1主页表,或者通过将其基地址放入L1主页表条目中来激活L2页表。
可以使用以下函数原型来调用它:
int mmuAttachPT(Pagetable *pt);
该过程接受一个参数,即要激活并添加从虚拟内存到物理虚拟内存的新转换的Pagetable指针。
int mmuAttachPT(Pagetable *pt) /* attach L2 PT to L1 master PT */
{
unsigned int *ttb, PTE, offset;
ttb = (unsigned int *)pt->masterPtAddress; /* read ttb from PT */
offset = (pt->vAddress) >> 20; /* determine PTE from vAddress */
switch (pt->type)
{
case MASTER:
{
__asm{ MCR p15, 0, ttb, c2, c0, 0 } ; /* TTB -> CP15:c2:c0 */
break;
}
case COARSE:
{
/* PTE = addr L2 PT | domain | COARSE PT type*/
PTE = (pt->ptAddress & 0xfffffc00);
PTE |= pt->dom << 5;
PTE |= 0x11;
ttb[offset] = PTE;
break;
}
#if defined(__TARGET_CPU_ARM920T)
case FINE:
{
/* PTE = addr L2 PT | domain | FINE PT type*/
PTE = (pt->ptAddress & 0xfffff000);
PTE |= pt->dom << 5;
PTE |= 0x13;
ttb[offset] = PTE;
break;
}
#endif
default:
{
printf("UNKNOWN page table type\n");
return -1;
}
}
return 0;
}该例程的第一步是准备两个变量,即L1主页表的基地址ttb和L1页表中的偏移量offset。从页面表的虚拟地址创建偏移量变量。要计算偏移量,将虚拟地址右移20位以将其除以1 MB。将此偏移量添加到主L1基地址上生成指向表示1 MB区域转换的L1主表内部地址的指针。
该过程使用Pagetable类型pt->type变量将页面表附加到MMU硬件,以切换到附加页面表的情况。下面描述了三种可能的情况。
Master情况附加主L1页表。该例程使用汇编语言的MCR指令将此特殊表附加到CP15:c2:c0寄存器中。
Coarse情况将粗略页表附加到主L1页表。此情况需要将存储在Pagetable结构中的L2页表地址与域和粗略表类型组合起来构建PTE。然后,将PTE写入L1页表,使用先前计算的偏移量。粗略PTE的格式如图14.6所示。
Fine情况将细粒度的L2页表附加到主L1页表。此例程需要将找到在Pagetable结构中存储的L2页表地址与域和细粒度表类型相结合以构建PTE。然后,将PTE写入L1页表,使用先前计算的偏移量。
前几个部分介绍了在初始化MMU时对页表进行条件、加载和激活的例程。最后两个部分设置域访问权限并启用MMU。
14.10.6.4 Assigning Domain Access and Enabling the MMU
初始化MMU的第四部分是配置系统的域访问权限。示例中不使用FCSE,也不需要快速地公开和隐藏大块内存,因此无需在CP:c1:c0寄存器中使用S和R访问控制位。这意味着在页表中定义的访问权限足以保护系统,并且有理由使用域。
然而,硬件要求所有活动内存区域都具有域分配并被授予域访问特权。最小域配置将所有区域放置在同一域中,并将域访问设置为客户机访问。这种域配置使得页表中的访问权限条目成为唯一的活动权限系统。
在本示例中,所有区域都被分配到域3,并具有客户机域访问权限。其他域未使用,并且由L1主页表中未使用的页表条目的错误条目屏蔽。域分配在主L1页表中完成,并在CP15:c3:c0寄存器中定义域访问权限。
示例14.11
domainAccessSet是一个设置域访问控制寄存器CP15:c3:c0:0中16个域的访问权限的例程。可以使用以下函数原型从C中调用它:
void domainAccessSet(unsigned int value, unsigned int mask);
传递给该过程的第一个参数是一个无符号整数,其中包含设置16个域的域访问权限的位字段。第二个参数定义需要更改其访问权限的域。该例程首先读取CP15:r3寄存器,并将其放入变量c3format中。然后,该例程使用输入的掩码值来清除c3format中需要更新的位。更新通过将c3format与valueinput参数进行逻辑或运算来完成。最后,更新后的c3format写回到CP15:c3寄存器中以设置域访问权限。
void domainAccessSet(unsigned int value, unsigned int mask)
{
unsigned int c3format;
__asm{MRC p15, 0, c3format, c3, c0, 0 } /* read domain register */
c3format &= ∼mask;
/* clear bits that change */
c3format |= value;
/* set bits that change */
__asm{MCR p15, 0, c3format, c3, c0, 0 } /* write domain register */
}启用MMU是MMU初始化过程的第五个也是最后一个部分。例程controlSet(示例14.3)用于启用MMU。建议从一个"固定"的地址区域调用controlSet过程。
14.10.6.5 Putting It All Together: Initializing the MMU for the Demonstration.
例程mmuInit调用在前几节中描述的例程以初始化演示中的MMU。在阅读代码的这一部分时,回顾第14.10.5节中展示的控制块将会有所帮助。
可以使用以下C函数原型调用该例程:
void mmuInit(void)
示例14.12
该示例调用了前面描述的初始化MMU过程的五个例程。这五个部分在示例代码中标记为注释。
mmuInit从初始化页表和映射特权系统区域开始。第一个部分使用对例程mmuInitPT的调用来初始化固定的系统区域。这些调用使用FAULT值填充L1主页表和L2页表。该例程调用mmuInitPT五次:一次用于初始化L1主页表,一次用于初始化系统L2页表,然后再次调用mmuInitPT三次以初始化三个任务页表:
#define DOM3CLT 0x00000040
#define CHANGEALLDOM 0xffffffff
#define ENABLEMMU 0x00000001
#define ENABLEDCACHE 0x00000004
#define ENABLEICACHE 0x00001000
#define CHANGEMMU 0x00000001
#define CHANGEDCACHE 0x00000004
#define CHANGEICACHE 0x00001000
#define ENABLEWB 0x00000008
#define CHANGEWB 0x00000008
void mmuInit()
{
unsigned int enable, change;
/* Part 1 Initialize system (fixed) page tables */
mmuInitPT(&masterPT); /* init master L1 PT with FAULT PTE */
mmuInitPT(&systemPT); /* init system L2 PT with FAULT PTE */
mmuInitPT(&task3PT); /* init task 3 L2 PT with FAULT PTE */
mmuInitPT(&task2PT); /* init task 2 L2 PT with FAULT PTE */
mmuInitPT(&task1PT); /* init task 1 L2 PT with FAULT PTE */
/* Part 2 filling page tables with translation & attribute data */
mmuMapRegion(&kernelRegion); /* Map kernelRegion SystemPT */
mmuMapRegion(&sharedRegion); /* Map sharedRegion SystemPT */
mmuMapRegion(&pageTableRegion); /* Map pagetableRegion SystemPT */
mmuMapRegion(&peripheralRegion);/* Map peripheralRegion MasterPT */
mmuMapRegion(&t3Region); /* Map task3 PT with Region data */
mmuMapRegion(&t2Region); /* Map task3 PT with Region data */
mmuMapRegion(&t1Region); /* Map task3 PT with Region data */
/* Part 3 activating page tables */
mmuAttachPT(&masterPT); /* load L1 TTB to cp15:c2:c0 register */
mmuAttachPT(&systemPT); /* load L2 system PTE into L1 PT */
mmuAttachPT(&task1PT); /* load L2 task 1 PTE into L1 PT */
/* Part 4 Set Domain Access */
domainAccessSet(DOM3CLT , CHANGEALLDOM); /* set Domain Access */
/* Part 5 Enable MMU, caches and write buffer */
#if defined(__TARGET_CPU_ARM720T)
enable = ENABLEMMU | ENABLECACHE | ENABLEWB ;
change = CHANGEMMU | CHANGECACHE | CHANGEWB ;
#endif
#if defined(__TARGET_CPU_ARM920T)
enable = ENABLEMMU | ENABLEICACHE | ENABLEDCACHE ;
change = CHANGEMMU | CHANGEICACHE | CHANGEDCACHE ;
#endif
controlSet(enable, change);
/* enable cache and MMU */
}第二部分通过调用mmuMapRegion七次来将系统中的七个区域映射到它们的页表中:四次映射内核、共享、页表和外围设备区域,三次映射三个任务区域。mmuMapRegion将控制块中的数据转换为页表项,然后写入页表。
初始化MMU的第三部分是激活启动系统所需的页表。通过调用mmuAttachPT三次完成此操作。首先,它通过将其基地址加载到CP15:c2:c0中的TTB条目中来激活主L1页表。然后,该例程激活L2系统页表。外围设备区域由位于主L1页表中的1MB页组成,在激活主L1表时也会激活该区域。第三部分通过调用mmuAttachPT来激活系统启用后运行的第一个任务,示例中的第一个任务是任务1。
初始化MMU的第四部分是通过调用domainAccessSet来设置域访问权限。所有区域都分配给域3,并将域3的访问权限设置为客户端访问。
mmuInit通过调用controlSet来启用MMU和缓存,从而完成第五部分。
当mmuInit例程完成时,MMU将被初始化并启用。建立多任务演示系统的最后一个任务是定义在两个任务之间进行上下文切换所需的过程步骤。
14.10.7 Step 7: Establish a Context Switch Procedure
在演示系统中,上下文切换相对简单。执行上下文切换有六个步骤:
1. 保存当前活动任务的上下文,并将该任务置于休眠状态。
2. 刷新缓存;如果使用写回策略,则可能需要清理D缓存。
3. 刷新TLB以移除即将退出的任务的翻译信息。
4. 配置MMU以使用新的页表,将共享的虚拟内存执行区域翻译为等待唤醒的任务在物理内存中的位置。
5. 恢复等待唤醒任务的上下文。
6. 恢复已恢复任务的执行。
//这就是执行上下文切换的所有开销啊!!!
执行以上所有步骤所需的例程已在前面的部分中介绍过。我们在这里列出了程序。第1、5和6部分已在第11章中提供;有关更多详细信息,请参考该章节。第2、3和4部分是支持使用MMU进行上下文切换所需的补充部分,并在此处显示了从任务1切换到任务2所需的参数。
SAVE 要退出任务的上下文;/* 第1部分,在第11章中显示 */
flushCache(); /* 第2部分,在第12章中显示 */
flushTLB(); /* 第3部分,在示例14.2中显示 */
mmuAttachPT(&task2PT); /* 第4部分,在示例14.10中显示 */
RESTORE 要唤醒任务的上下文;/* 第5部分,在第11章中显示 */
RESUME 已恢复任务的执行;/* 第6部分,在第11章中显示 */14.11 The Demonstration as mmuSLOS
许多关于MMU演示代码的概念和示例已经被纳入到一个功能控制系统中,我们称之为mmuSLOS。它是在第11章介绍的SLOS控制系统的扩展。
mpuSLOS是SLOS的内存保护单元扩展,在第13章中进行了描述。我们使用mpuSLOS变体作为mmuSLOS的基本源代码。这三个变体可以在出版商的网站上找到。我们对mpuSLOS代码进行了三个重要的更改:
■ MMU表在mmuSLOS初始化阶段被创建。
■ 应用任务被构建为在0x400000处执行,但加载到不同的物理地址。每个应用任务在以执行地址开始的虚拟内存中执行。堆栈顶部位于距离执行地址偏移32KB的位置。
■ 每次调度程序调用时,MMU表中的活动32KB页面会更改,以反映新的活动应用程序/任务。
14.12 Summary
这一章介绍了内存管理和虚拟内存系统的基础知识。
MMU的一个关键功能是能够将任务作为独立程序在其自己的私有虚拟内存空间中运行。
虚拟内存系统的一个重要特性是地址重定位。地址重定位是将处理器核心发出的地址转换为主存中的不同地址。这个转换由MMU硬件完成。
在虚拟内存系统中,虚拟内存通常分为固定区域和动态区域。在固定区域,页面表中映射的转换数据在正常操作过程中不会改变;而在动态区域中,虚拟内存和物理内存之间的内存映射经常发生变化。
页表包含了虚拟页面信息的描述。一个页表项(PTE)将虚拟内存中的页面转换为物理内存中的页面帧。页表项按照虚拟地址进行组织,并包含了将页面映射到页面帧所需的转换数据。
ARM MMU的功能包括:
■ 读取一级和二级页表,并将其加载到TLB中
■ 在TLB中存储最近的虚拟-物理内存地址转换
■ 执行虚拟-物理地址转换
■ 强制访问权限并配置缓存和写缓冲区
ARM MMU的另一个特殊功能是快速上下文切换扩展。快速上下文切换扩展在多任务环境中提高了性能,因为在上下文切换期间不需要刷新缓存或TLB。
提供了一个小型虚拟内存系统的工作示例,详细介绍了如何设置MMU以支持多任务。设置演示的步骤包括定义在虚拟内存的固定系统软件中使用的区域,为每个任务定义虚拟内存映射,将固定区域和任务区域定位到物理内存映射中,定义并定位页表在页表区域内,定义创建和管理区域和页表所需的数据结构,通过使用定义的区域数据初始化MMU以创建页表项并将其写入页表,并建立上下文切换过程以从一个任务切换到下一个任务。


















 1375
1375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









