






你的好坏取决于你的工具,而你的工具的好坏也取决于你。
未知的
本章简要介绍了并行编程的一些基本工具,主要关注运行在类似于Linux的操作系统上的用户应用程序可用的那些工具。第4.1节从脚本语言开始,第4.2节描述了POSIX API支持的多进程并行性以及对POSIX线程的讨论,参见第4.3节在其他环境中呈现模拟操作,最后,第4.4节帮助选择完成工作的工具。

请注意,本章仅提供简要介绍。更多细节可参见参考文献(和因特网),并在后续章节中提供更多信息。
至高无上的美德是简单。
亨利·沃兹沃斯·朗费罗,简化
Linux命令行脚本语言提供了简单而有效的并行处理方法。例如,假设您有一个需要使用两组不同的参数运行两次的程序compute_it。可以使用UNIX命令行脚本来实现这一点:
| compute_it 1 > compute_it .1 .out &compute_it 2 > compute_it .2.out & |
第1行 和2 启动此程序的两个实例,将它们的输出重定向到两个单独的文件中,并使用&字符将shell指向在后台运行此程序的两个实例。第3行 等待两个实例完成,以及第4行 和5 显示它们的输出。结果执行如图4.1所示 :compute_它执行的两个实例并行执行,等待在它们都完成后完成,然后cat的两个实例依次执行。
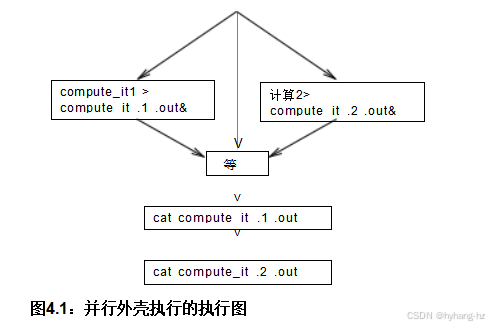

希望这些简单的例子能让你相信并行编程并不总是复杂或困难的。

骆驼是委员会设计的马。
未知的
本节简要介绍了POSIX环境,其中包括线程[ Ope97],因为该环境易于使用且广泛实现。第4.2.1节提供了对POSIX fork()和相关原语的简要介绍,第4.2.2节涉及线程创建和销毁,第4.2.3节 简要介绍了POSIX锁定,最后是第4.2.4节 描述了一个特定的锁,可用于读取由多个线程读取且仅偶尔更新的数据。
进程使用fork()原语创建,可以使用kill()原语销毁,可以使用exit()原语销毁自身。一个进程
| 1 pid=fork(); 5/*有错误时,父级*/ 7退出(EXIT_FAILURE);8} else{ 10} |
| 1静态2{ 3 4 5 6 7 8 9 10 11 12 13 14 15} | __inline__ void waitall(void) intpid; intstatus; pid=wait(&status);如果(pid==-1){ }} |
执行fork()原语被称为新创建进程的“父”进程。父进程可以使用wait()原语等待其子进程。
请注意,本节中的示例相当简单。实际应用中使用这些基本组件时,可能需要处理信号、文件描述符、共享内存段以及其他多种资源。此外,某些应用程序在某个子进程终止时需要采取特定行动,并且可能还需要关注子进程终止的原因。这些问题当然会大大增加代码的复杂性。如需更多信息,请参阅相关教科书[Ste92,Wei13]。
如果fork()成功,它会返回两次,一次给父进程,一次给子进程。fork()返回的值允许调用者区分两者,如清单4.1所示。 (forkjoin .c)。第1行 执行fork()原语,并将其返回值保存在局部变量pid中。第2行 检查pid是否为零,如果是,则这是子进程,继续执行第3行。 如前所述,子进程可能通过exit()原语终止。否则,这是父进程,在第4行检查fork()原语返回的错误 ,打印错误信息并在第5行退出 – 7 如果是,否则fork()已成功执行,父进程因此执行第9行 变量pid包含子进程的进程ID。
父进程可以使用wait()原语等待其子进程完成。然而,使用此原语比其外壳脚本对应物更为复杂,因为每次调用wait()仅等待一个子进程。因此,通常会将wait()封装到类似于清单4.2中所示的waitall()函数的功能中。 (api-pthreads.h),通过这个waitall()函数具有类似于shell脚本wait命令的语义。每个循环遍历第6行 – 14等待一个子进程。第7行 调用wait()原语,该原语会阻塞直到子进程退出,并返回该子进程的进程ID。如果进程ID为-1,则表示wait()原语无法等待子进程。如果是这样,请参见第9行 支票
第48章第4节工具
清单4.3:通过fork()创建的过程,不共享内存
1 int x=0; 2
3 int main(int argc,char*argv[])4{
5 intpid; 6
7 pid=fork();
9 x =1;
11退出( EXIT_成功);12}
13 if(pid< 0){/* parent,出错时*/
14perror("fork");
15退出(EXIT_FAILURE);16}
17
18/* parent*/ 19
23返回EXIT_成功;24}
对于ECHILD errno,它表示没有更多的子进程,所以第10行 退出循环。否则,行11 和12 打印错误并退出。

必须注意的是,父母和孩子并不共享记忆。这可以通过清单4.3中所示的程序来说明。 (forkjoinvar.c),其中子进程在第9行将全局变量x设置为1 在第10行打印一条消息, 并在第11行退出。 父类在第20行继续 ,它在那儿等着孩子,在第21行 发现变量x的副本仍然是零。因此,输出如下:
| 子进程setx=1 父进程看到x=0 |
![]()
最细粒度的并行需要共享内存,这一点在第4.2.2节中进行了介绍。 也就是说,共享内存并行处理可能比分叉-连接并行处理复杂得多。
要在现有进程中创建一个线程,可以调用pthread_create()原语,例如,如第16行所示 和17见清单4.4 (pcreate.c)。第一个参数是指向一个pthread_t的指针,用于存储要创建的线程ID;第二个参数NULL是指向可选pthread_attr_t的指针;第三个参数是新线程将要调用的函数(在此例中为mythread());最后一个参数NULL将传递给mythread()。
在本例中,mythread()只是返回,但它也可以调用pthread_ exit()。
清单4.4:通过pthread_创建的线程create()Share Memory
1 int x=0; 2
3 void *mythread(void *arg)4{
5 x =1;
6printf(“子进程setx=1\n”);
7 returnNULL; 8}
9
10 int main(int argc,char*argv[])11{
12级;
13pthread_ttid;
14 void*vp; 15
16if ((en =pthread_create(&tid,NULL,
17 mythread,NULL ))!= 0) {
18 fprintf(stderr,“pthread_create:%s\n”,strerror(en));
19退出(EXIT_FAILURE);20}
21
22/* parent*/ 23
24 if((en=pthread_join(tid,&vp))!= 0){
25 fprintf(stderr,“pthread_join:%s\n”,strerror(en));
26退出(EXIT_FAILURE);27}
28printf(“父进程看到x=%d\n”,x);29
30返回EXIT_成功;31}

pthread_join()原语,如第24行所示 ,类似于叉连接等待()原语。它会阻塞直到由tid变量指定的线程完成执行,无论是通过invokingpthread_exit()还是从线程的顶级函数返回。线程的退出值将通过传递给pthread_ join()的第二个参数的指针存储。线程的退出值要么是传递给pthread_ exit()的值,要么是从线程的顶级函数返回的值,具体取决于该线程的退出方式。
清单4.4中所示程序 按以下顺序生成输出,证明两个线程之间确实共享内存:
| 子进程setx=1 父进程看到x=1 |
请注意,该程序仔细确保每次只有一个线程将值存储到变量x中。任何情况下,如果一个线程可能向某个变量存储值,而另一个线程要么从中加载数据,要么向该变量存储数据,则这种情况被称为数据竞争。由于C语言不保证数据竞争的结果会合理,我们需要某种方法来安全地并发访问和修改数据,例如下一节讨论的锁定原语。
但是你说你的数据竞赛是良性的?也许它们是。但是请帮大家(包括你自己)一个大忙,阅读第4.3.4.1节非常谨慎。随着编译器越来越积极地进行优化,真正良性数据竞争的数据越来越少。

POSIX标准允许程序员通过“POSIX锁定”来避免数据竞争。POSIX锁定包含多个基本操作,其中最基础的是arepthread_mutex_lock()和pthread_mutex_unlock()。这些基本操作作用于pthread_mutex_t类型的锁。这些锁可以静态声明并用PTHREAD_MUTEX_INITIALIZER初始化,也可以动态分配并使用pthread_ mutex_ init()基本操作初始化。本节的示例代码将采用前者。
Thepthread_mutex_lock()获取指定的锁,而thepthread_mutex_unlock()释放指定的锁。由于这些是“独占”锁定原语,任何时候只有一个线程可以“持有”给定的锁。例如,如果一对线程同时尝试获取同一个锁,其中一个线程会先被“授予”锁,另一个线程则等待第一个线程释放锁。一个简单且相当实用的编程模型允许在持有相应锁的情况下访问给定的数据项[Ho74]。
![]()
使用清单4.5中所示的代码演示了这种独占锁定属性。 (lock .c)第1行 定义并初始化名为lock_a的POSIX锁,而第2行同样定义并初始化名为lock_b的锁。第4行 定义并初始化共享变量x。
第6行 – 33 定义一个函数lock_ reader(),它在保持由arg指定的锁的同时反复读取共享变量x。第12行 将参数arg赋值给指向pthread_ mutex_t的指针,这是pthread_ mutex_ lock()和pthread_mutex_unlock()原语所要求的。

第14行–18获取specifiedpthread_mutex_t,检查错误,如果出现错误则退出程序。第19行 – 26反复检查x的值,每次改变时打印新的值。第25行 睡眠一毫秒,这使得该演示在单处理器机器上运行良好。第27行 – 31 释放thepthread_mutex_t,再次检查错误,如果出现任何错误则退出程序。最后,第32行 返回NULL,再次与所需函数类型bypthread_create()匹配。

第35行–56 见清单4.5 显示锁_writer(),它在持有指定的pthread_ mutex_t时定期更新共享变量x。与锁_reader()一样,第39行将参数arg赋值给指向pthread_ mutex_t的指针,第41行 – 45 获得
| 1printf(“创建两个线程sw/differentlocks:\n”); 2x = 0; 3 en=pthread_create(&tid1,NULL,lock_reader,&lock_a); 4如果(en!= 0){ 5 fprintf(stderr,“pthread_create:%s\n”,strerror(en); 6退出(EXIT_FAILURE);7} 8 en=pthread_create(&tid2,NULL,lock_writer,&lock_b); 9如果(en!= 0){ 10fprintf(stderr,“pthread_create:%s\n”,strerror(en); 11退出(EXIT_FAILURE);12} 13如果((en=pthread_jo在(tid1,&vp))!=0){ 14 fprintf(stderr,“pthread_join:%s\n”,strerror(en)); 15退出(EXIT_FAILURE);16} 17 if((en=pthread_jo in(tid2,&vp))!= 0){ 18 fprintf(stderr,“pthread_join:%s\n”,strerror(en)); 19退出(EXIT_FAILURE);20} |
指定的锁,以及第50行 – 54 释放它。在保持锁的情况下,行46 – 49 增加共享变量x,在每次增量之间休眠5毫秒。最后,第50行 – 54松开锁。
清单4.6显示了一个代码片段,它使用同一个锁lock_a以线程的形式运行lock_reader()和lock_writer()。第2行 – 6创建一个运行锁_reader()的线程,然后是第7行 – 11创建一个运行锁_writer()的线程。第12行 – 19 等待两个线程都完成。此代码片段的输出如下:
| 使用同一个锁创建两个线程:lock_reader():x=0 |
由于两个线程都使用同一个锁,thelock_reader()线程在保持锁的同时无法看到lock_writer()生成的x的所有中间值。

清单4.7 显示了类似的代码片段,但这次使用了不同的锁:lock_a forlock_reader()andlock_b forlock_wr iter()。此代码片段的输出如下:
| 创建两个threadsw/differentlocks: 锁读器():x=0lock_reader():x=1lock_reader():x=2lock_reader():x=3 |
由于这两个线程使用不同的锁,它们不会相互排斥,并且可以并发运行。因此,lock_reader()函数可以查看lock_writer()存储的x的中间值。

尽管POSIX排他锁还有更多的内容,但这些基本操作提供了良好的开端,并且在许多情况下是足够的。下一节将简要介绍POSIX读写锁。
The POSIX API provides a reader-wr iter lock, which is represented by apthread_rwlock_t.As with pthread_mutex_t,pthread_rwlock_t may be statically initial-ized via PTHREAD_RWLOCK_INITIALIZER or dynamically initialized via the pthread_rwlock_init() primitive. Thepthread_rwlock_rdlock() primitiveread-acquiresthe specified pthread_rwlock_t, the pthread_rwlock_wrlock() primitive write- acquires it , and the pthread_ rwlock_ unlock () primitive releases it . Only a single thread maywrite-hold agiven pthread_rwlock_t at any given time, but multiple threads may read- hold a given pthread_ rwlock_t, at least while there is no thread currently write- holding it .
正如你可能预料的那样,读写锁是为大多数读取情况设计的。在这种情况下,读写锁比独占锁具有更高的可扩展性,因为独占锁按定义只能由一个线程持有,而读写锁允许多个读者同时持有锁。然而,在实际应用中,我们需要了解读写锁能提供多少额外的可扩展性。
清单4.8 (rwlockscale .c)显示了测量读写锁可伸缩性的方法之一。第1行 显示了读写锁的定义和初始化,第2行 显示holdtime参数控制每个线程持有读写锁的时间,第3行 显示了t hinktime参数,它控制读写锁释放和下一次获取之间的时间,第4行 定义了读取计数数组,每个读取线程将它获得锁的次数放入该数组,以及第5行 定义thenreadersrunning变量,它确定所有读取器线程是否已开始运行。
第7行 – 10定义goflag,它同步测试的开始和结束。此变量最初设置为GOFLAG_INIT,然后在所有读取器线程启动后设置为toGOFLAG_RUN,最后设置为GOFLAG_STOP以终止测试运行。
第12行 – 44 定义读取器(),即读取器线程。第19行 原子式地增加nreadersrunning变量,以指示此线程现在正在运行,并且行20 – 22 等待测试开始。TheREAD_ONCE()原始函数迫使编译器在每次循环中获取goflag——否则编译器有权假设goflag的值永远不会改变。
跨越线路23的环 – 41执行性能测试。行24 – 28 获取锁,第29行 – 31保持锁住指定的微秒数,第32行 – 36 释放锁,行37 – 39在获取锁之前,等待指定的微秒数。第40行计算此位置的采集。
第42行 将锁获取计数移动到此线程的readcounts[]数组元素中,第43行返回,终止此线程。
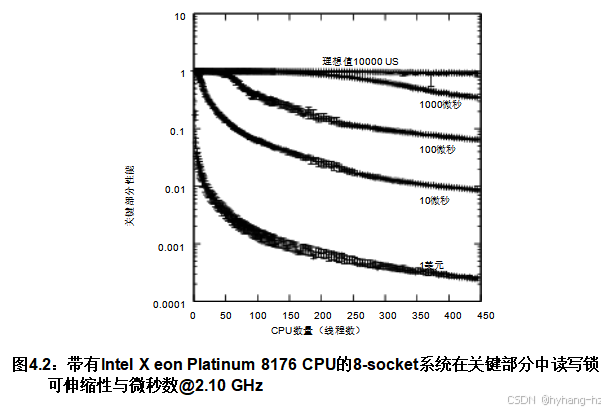
图4.2 展示了在配备224个核心的Xeon系统上运行此测试的结果,每个核心有两个硬件线程,总计448个软件可见CPU。所有这些测试中,思考时间参数均为零,而保持时间参数则设置为从一微秒(图中标记为“1us”)到一万微秒(图中标记为“10000us”)不等。
![]()
其中N是当前运行中的线程数,L N是当前运行中所有N个线程获取的锁总数,L 1是单线程运行中获取的锁数。在硬件和软件可扩展性理想的情况下,这个值总是1.0。
如图所示,读写锁的可扩展性显然不够理想,特别是对于较小的关键部分。要了解为什么读取操作如此缓慢,可以考虑所有获取线程都必须更新pthread_ rwlock_t数据结构。因此,如果所有448个执行线程同时尝试读取-获取读写锁,它们必须一个接一个地更新底层的pthread_ rwlock_t。幸运的线程可能几乎立即完成,但最不幸运的线程则必须等待其他447个线程完成更新。随着CPU数量的增加,这种情况只会变得更糟。请注意对数轴。尽管10,000微秒的轨迹看似理想,但实际上已经下降了约10%。
 尽管存在这些限制,读写锁定在许多情况下仍然非常有用,例如当读取器必须执行高延迟的文件或网络I/O时。还有其他替代方案,其中一些将在第5章和第9章中介绍。
尽管存在这些限制,读写锁定在许多情况下仍然非常有用,例如当读取器必须执行高延迟的文件或网络I/O时。还有其他替代方案,其中一些将在第5章和第9章中介绍。
图4.2显示了读写锁的开销在最小的关键段中最严重,因此最好有其他方法来保护这些微小的关键段。一种这样的方法是使用原子操作。我们已经见过一个原子操作,即第19行的__sync_fetch_and_add()原语。 见清单4.8。 这个原始原子操作会将其第二个参数的值加到第一个参数引用的值上,返回旧的值(在这种情况下被忽略)。如果两个线程同时对同一个变量执行__sync_fetch_and_add(),那么该变量的结果将包含两次加法的值。
GNU C编译器提供了一系列额外的原子操作,包括__ sync_ fetch_和sub()、__ sync_ fetch_和or()、__ sync_ fetch_和and()、__ sync_ fetch_和xor()以及__ sync_ fetch_和nand(),这些操作都返回旧值。如果您需要新值,则可以使用 同步添加和提取()、__同步子和提取()、__同步或和提取()、__同步_和_和提取()、__同步_xor_和_提取()、__同步_与_和提取()等原语。
![]()
| 清单4.9:编译器屏障原语(用于GCC) | |
| #define#define #define #define | ACCESS_ONCE(x)(*volatiletypeof(x)*)&(x))READ_ONCE(x) ({ typeof (x) x = ACCESS_ ONCE (x);x;})WRITE_ ONCE(x,val)\ do { ACCESS_ ONCE(x) =(val);}while(0)barrier()__asmvolatile__(“”:::“memory”) |
经典 比较交换操作由一对原语提供, 同步操作`()`和`__`,比较和交换`val_`。这两种原语原子地将一个位置更新为新值,但前提是该位置的先前值必须等于指定的旧值。第一个变体如果操作成功返回1,失败则返回0,例如,如果先前值不等于指定的旧值。第二个变体返回该位置的先前值,如果等于指定的旧值,则表示操作成功。比较-交换操作具有“通用性”,即任何对单个位置的原子操作都可以通过比较-交换来实现,尽管早期的操作在适用时通常更高效。比较-交换操作还可以作为更广泛原子操作的基础,但这些更复杂的操作往往存在复杂性、可扩展性和性能问题[Her90]。
 __的同步_()原语会发出一个“内存屏障”,这限制了编译器和CPU重新排序操作的能力,如第15章所述。在某些情况下,只需限制编译器重新排序操作的能力,而让CPU自由操作,此时可以使用barrier()原语。在某些情况下,只需确保编译器不会优化掉某个内存读取,此时可以使用READ_ONCE()原语,正如第20行所示。 见清单4.5。 同样,WRITE_ONCE()原语可用于防止编译器优化掉给定的内存写入。GCC并不直接提供最后三个原语,但可以如清单4.9所示进行简单实现。 ,这三者都在第4.3.4节中进行了详细讨论。 另外,READ_ONCE(x)与GCC内含函数__atomic_load_n(&x有许多共同之处, ATOMIC_RELAXED) andWRITE_ONCE()与GCC intrinsic__原子_store_n(&x,v,__ATOMIC_relaxed)有μch的共同点。
__的同步_()原语会发出一个“内存屏障”,这限制了编译器和CPU重新排序操作的能力,如第15章所述。在某些情况下,只需限制编译器重新排序操作的能力,而让CPU自由操作,此时可以使用barrier()原语。在某些情况下,只需确保编译器不会优化掉某个内存读取,此时可以使用READ_ONCE()原语,正如第20行所示。 见清单4.5。 同样,WRITE_ONCE()原语可用于防止编译器优化掉给定的内存写入。GCC并不直接提供最后三个原语,但可以如清单4.9所示进行简单实现。 ,这三者都在第4.3.4节中进行了详细讨论。 另外,READ_ONCE(x)与GCC内含函数__atomic_load_n(&x有许多共同之处, ATOMIC_RELAXED) andWRITE_ONCE()与GCC intrinsic__原子_store_n(&x,v,__ATOMIC_relaxed)有μch的共同点。
![]()
C 11标准增加了原子操作,包括加载(atomic_ load())、存储(atomic_store())、内存屏障(atomic_thread_f ence()和atomic_ signal_ fence())以及读-改-写原子操作。读-改-写原子操作包括atomic_fetch_add()、atomic_fetch_sub(),atomic_fetch_and(),atomic_fetch_xor(),atomic_exchange()、atomic_ compare_ exchange_ weak()和atomic_compare_exchange_strong()。这些操作的机制与第4.2.5节中描述的类似。 ,但是为所有操作的_显式变体添加了内存顺序参数。没有内存顺序
参数,所有操作都是完全有序的,参数允许较弱的排序。对于example,“atomic_load_explicit(&a,memory_order_relaxed)”is与Linux内核的“READ_ONCE()”大致类似。1
C11原子操作的一个限制是它们仅适用于特定类型的原子,这可能会带来问题。因此,GNU C编译器提供了原子内核函数,如including__atomic_load(),__atomic_load_n(),__atomic_store(),__ atomic_ store_n()、__atomic_thread_fence_()等。这些内核函数提供与其C11对应函数相同的语义,但也可以用于普通的非原子对象。其中一些内核函数可以从以下列表中传递一个内存顺序参数: ATOMIC_RELAXED、atomic_consume、atomic_acquire、atomic_release ATOMIC_ACQ_REL, andATOMIC_SEQ_CST .
线程变量,也称为线程特定数据、线程局部存储和其他不太礼貌的名字,在并发代码中被极其频繁地使用,这将在第5章和第8章中探讨。POSIX提供了pthread_ key_ create()函数来创建一个线程变量(并返回相应的键),pthread_key_delete()用于删除与键对应的线程变量,pthread_setspecific()用于设置当前线程中与指定键对应的变量值,andpthread_getspecific()用于返回该值。
许多编译器(包括GCC)提供了一个线程标识符,可以在变量定义中使用,以指定该变量是按线程分配的。然后可以正常使用变量名来访问当前线程实例的值。当然,线程比POSIX头文件特有的数据更容易使用,因此对于仅使用GCC或其他支持线程的编译器构建的代码,通常更倾向于使用线程。
幸运的是,C11标准引入了一个_thread_local关键字,可以用来代替thread。随着时间的推移,这个新关键字应该结合了thread的易用性和POSIX特定于线程数据的可移植性。
开源的战略营销范式是一个被过滤了的大量并行醉汉的行走
达尔文主义过程。
布鲁斯·佩伦斯
不幸的是,在各种标准委员会着手处理线程操作、锁定原语和原子操作之前,这些操作早已被广泛使用。因此,这些操作的支持方式存在相当大的差异。至今仍常见的是,这些操作以汇编语言实现,这要么是出于历史原因,要么是为了在特定情况下获得更好的性能。例如,GCC‘ssync_系列的原语都提供了完整的
| 清单4.10:Thread API |
| intsmp_thread_id(音调) thread_id_tcreate_thread(void(*func)(void*),void*arg)for_each_thread(t) for_each_running_thread(t) void*wait_thread(thread_id_t tid)voidwait_all_threads(void) |
| 内存排序语义,过去曾促使许多开发人员为不需要完整内存排序语义的情况创建自己的实现。以下各节将展示一些来自Linux内核的替代方案以及本书示例代码中使用的一些历史原始语句。 虽然许多环境不需要任何特殊的初始化代码,但本书中的代码示例都以调用smp_init()开头,该函数初始化一个映射frompthread_t到连续的整数。用户空间RCU库2 同样需要调用rcu_init()。尽管这些调用可以在支持构造函数的环境(如GCC环境)中隐藏,但大多数由用户空间RCU库支持的RCU版本也要求每个线程在创建时调用rcu_register_thread(),并在退出前调用rcu_unregister_thre ad()。 对于Linux内核而言,是否不需要调用特殊初始化代码或者内核的启动时间代码实际上是必需的初始化代码,这是一个哲学问题。 Linux内核使用struct task_struct指针来跟踪kthreads,kthread_ create()创建它们,kthread_should_stop()外部建议它们停止(没有POSIX等效函数),3 kthread_停止()等待它们停止,并为定时等待调度timeout_interruptible()。还有一些额外的kthread管理API,但这个提供了很好的开始,以及好的搜索术语。 CodeSamples API专注于“线程”,它们是控制的中心。4 每个这样的线程都有一个类型为thread_id_t的标识符,而且在给定时间运行的两个线程不会有相同的标识符。线程共享除每个线程的本地状态外的所有内容,5 其中包括程序计数器和堆栈。 线程API如清单4.10所示 ,成员在下面的章节中描述。 4.3.2.1 API成员 create_thread()原语创建新线程,启动新线程的 |
在创建线程()的第一个参数指定的函数中执行,并传递创建线程()的第二个参数指定的参数。新创建的线程将在从由函数指定的启动函数返回时终止。create_thread()原语返回新创建子线程对应的thread_id_t。
如果创建了更多的thanNR_THREADS线程,这个原始函数将终止程序,其中包括运行程序时隐式创建的线程。NR_THREADS是一个编译时常量,可以修改,但有些系统可能对允许的线程数有一个上限。
smp_线程id()
由于从create_ thread()返回的thread_ id_ t是系统依赖的,smp_thread_id()的p原语返回一个与请求该线程的线程索引相对应的索引。这个索引保证小于自程序启动以来存在的最大线程数,因此对于位掩码、数组索引等非常有用。
for_each_thread()
for_each_thread()宏遍历所有存在的线程,包括如果创建的话将存在的所有线程。此宏对于处理第4.2.8节中介绍的每个线程变量很有用。
for_each_running_thread()
for_ each_ running_ thread()宏只循环当前存在的线程。如果需要,调用者有责任在创建和删除线程时进行同步。
等待()
wait_thread()原语等待由thread_id__t传递给它的线程指定的读取完成。这不会干扰指定线程的执行;相反,它只是等待该线程。请注意,wait_thread()返回的是相应线程返回的值。
等待所有线程()
Thewait_all_threads()原语等待所有当前正在运行的线程完成。如果需要,调用者有责任与线程的创建和删除进行同步。然而,这个原语通常不用于在运行结束时清理,因此这种同步通常不需要。
4.3.2.2示例用法
清单4.11 (threadcreate .c)展示了一个类似hello-world的子线程示例。如前所述,每个线程都会分配自己的栈,因此每个线程都有自己的私有参数和myarg变量。每个子线程在退出前仅打印其参数和itssmp_thread_id()。请注意第7行的返回语句。 终止该线程,将NULL返回给在此线程上调用wait_t hread()的用户。
父程序如清单4.12所示。 它在第6行调用smp_init()来初始化线程系统 ,解析第8行的参数 – 15,并宣布它出现在第16线。 它在第18行创建指定数量的子线程 – 19 ,并等待它们在第21行完成。 请注意,wait_ all_ threads()会丢弃线程返回值,因为在这种情况下它们都是NULL,这并不十分有趣。
1 void *thread_test(void*arg)2{
3 int myarg= (intptr_t)arg; 4
5printf(“子线程%d:smp_thread_id()=%d\n”,
7 returnNULL; 8}
1个主参数(int argc,char*argv[]) 2{
3 inti;
4 int nkids=1; 5
9 nkids=strtoul(argv[1],NULL,0);
10如果(nkids > NR_ THREADS){
11fprintf(stderr,“nkids=%d太大,最大值=%d\n”,
12名儿童,NR_THREADS);
15}
16printf(“父线程正在创建%d个线程。\n”,nkids);17
18个(i=0;i<nkids;i++)
19create_thread(thread_test,(void*)(intptr_t)i);20
21wait_all_threads(); 22
23printf(“所有生成的线程已完成。\n”);24
25退出(0);26}
| voidspin_lock_init(spinlock_t*sp);voidspin_lock(spinlock_t*sp); intspin_trylock(spinlock_t*sp);voidspin_unlock(spinlock_t*sp); |
Linux内核锁定API的一个好的初始子集如清单4.13所示, 每个API元素在下面的章节中都有描述。本书的CodeSamples锁定API与Linux内核紧密地遵循了这一过程。
4.3.3.1 API成员
spin_lock_init()
spin_lock_init()原语初始化指定的spinlock_t变量,并且必须在该变量传递给任何其他spinlock原语之前调用。
自旋锁()
spin_lock()原语如果需要,会获取指定的自旋锁并等待
| 1 | ptr | =global_ptr; | ||
| 2 | 如果 | ( ptr!= NULL&& ptr | < | 高地址) |
| 3 | ||||
| 1如果 | |
| 2 | |
| 3 | do_low(global_ptr); |
直到自旋锁可用为止。在某些环境中,例如pthr线程中,等待将涉及阻塞,而在其他环境中,例如Linux内核中,则可能涉及CPU周期的自旋循环。
关键在于任何时候只有一个线程可以持有自旋锁。
spin_trylock()
spin_trylock()原语获取指定的自旋锁,但仅在它立即可用时才获取。如果它能够获取自旋锁,则返回true,否则返回false。
旋转解锁()
spin_ unlock()原语释放指定的自旋锁,允许其他线程获取它。
4.3.3.2示例用法
可以使用名为mutex的自旋锁来保护变量counter,如下所示:
| spin_lock(&mutex);counter++; spin_unlock(&mutual); |

但是,spin_lock()和spin_unlock()这两个原语确实存在性能问题,这将在C第10章中看到。
直到2011年,C标准才定义了并发读写共享变量的语义。然而,至少在四分之一个世纪前[BK85,Inm85],就已经有人编写并发C代码了。这不禁让人思考,如今的老前辈们在遥远的C11之前的日子里做了些什么。简短的回答是“他们活得危险”。
至少,如果他们使用的是2021年的编译器,他们的生活将会非常危险。在(比如说)20世纪90年代初,编译器进行的优化较少,部分原因是编译器编写者较少,部分原因在于那个时代的内存相对较小。尽管如此,问题还是出现了,如清单4.14所示。 编译器有权将其转换为清单4.15。 如您所见,临时在线1 见清单4.14 已经被优化掉,所以global_ptr将被加载到3次。

第4.3.4.1节 描述了普通访问引起的其他问题,第4.3.4.2节 和4.3.4.3 描述一些C11之前的解决方案。当然,如果可行,直接C语言内存引用应该被第4.2.5节中描述的原语所取代 或(特别是)第4.2 .6节。 使用这些原语可以避免数据竞争,即确保如果多个并发的C语言访问给定变量,所有这些访问都是加载。
4.3.4.1共享变量恶作剧
给定一个执行普通加载和存储的代码,6编译器有权假设受影响的变量既未被其他线程访问也未被修改。这一假设使得编译器能够执行大量转换操作,包括加载拆分、存储拆分、加载融合、存储融合、代码重排序、虚拟加载、虚拟存储、存储到加载转换以及消除死代码,这些操作在单线程代码中都能正常工作。但并发代码可能会因这些转换或共享变量的花招而失效,如下所述。
加载撕裂发生在编译器为单个访问使用多个加载指令时。例如,理论上编译器可以编译从global_ ptr中加载的指令(见第1行见清单4.14 )作为一系列逐字节加载。如果其他线程同时将global_ptr设置为NULL,结果可能是指针除一个字节外全部被置零,从而形成一个“野指针”。使用这种野指针进行存储可能会损坏任意内存区域,导致罕见且难以调试的崩溃。
更糟糕的是,在(比如说)一个8位系统中,使用16位指针时,编译器可能别无选择,只能使用一对8位指令来访问给定的指针。由于C标准必须支持所有类型的系统,因此标准不能排除在一般情况下发生加载撕裂的可能性。
存储撕裂发生在编译器为单次访问使用多个存储指令时。例如,一个线程可能同时将0x12345678存储到一个四字节整型变量中,而另一个线程则存储了0xabcdef00。如果编译器在这两种访问中都使用了16位存储,结果可能会是0x1234ef00,这可能会让从这个整型加载代码感到非常意外。这也不是纯粹的理论问题。例如,有些CPU具有小的即时指令字段,在这样的CPU上,编译器可能会将一个64位存储拆分为两个32位存储,以减少显式形成寄存器中64位常量的开销,即使是在64位CPU上也是如此。有历史报告指出这种情况实际上已经发生(例如[KM13]),但也有最近的一份报告[Dea19]。
当然,编译器别无选择,只能在通用中撕裂一些存储器
在这种情况下,考虑到代码使用64位整数在32位系统上运行的可能性。
| 清单4.16:邀请负载熔断 |
| 1,同时(need_to_stop) 2do_something_quickly(); |
| 1如果(!need_to_stop) 2 for(;;){ 3do_something_quickly(); 4do_something_quickly(); 5do_something_quickly(); 6do_something_quickly(); 7do_something_quickly(); 8do_something_quickly(); 9do_something_quickly(); 10do_something_quickly(); 11do_something_quickly(); 12do_something_quickly(); 13do_something_quickly(); 14do_something_quickly(); 15do_something_quickly(); 16do_something_quickly(); 17do_something_quickly(); 18do_something_quickly(); 19} |
| 但对于机器大小的正确对齐存储器,WRITE_ONCE()将防止存储器撕裂。 加载融合发生在编译器使用先前从给定变量加载的结果而不是重复加载时。这种优化不仅在单线程代码中效果很好,在多线程代码中也常常有效。不幸的是,“通常”这个词掩盖了一些真正令人烦恼的例外情况。 例如,假设一个实时系统需要快速调用一个名为do_ something_的函数()重复执行,直到设置变量need_ to_ stop,而编译器可以发现do_something_quick()不存储toneed_to_stop。一种(不安全的)编码方法如清单4.16所示。 编译器可能会合理地将这个循环展开十六次,以减少循环末尾反向分支的每次调用。更糟糕的是,由于编译器知道`do_ something_ quickly`()不需要存储`to_ stop`,因此编译器可以合理地决定只检查一次这个变量,从而产生如清单4.17所示的代码。 一旦进入,第2行的循环 – 19 无论其他线程存储了多少次非零值need_to_stop,它都不会退出。结果最坏的情况是令人困惑,而且很可能还会造成严重的物理损坏。 编译器可以将跨代码的大量代码的加载合并在一起。例如,在清单4.18中, t0()和t 1()同时运行,do something()和do something_ else()是内联函数。第1行 声明指针gp,C默认初始化为NULL。在某一点,第5行 t0()存储一个指向gp的非NULL指针。同时,t1()在第10行从gp加载三次, 12 ,和15。 鉴于第13行 发现gp是非空的,人们可能会希望第15行的解引用 将保证永远不会出错。不幸的是,编译器有权将第10行的读取合并 和15, 这意味着如果第10行 加载NULL和第12行 load&myvar,第15行 可以加载NULL,导致故障。8 |
| 1 int*gp; 2 3 void t0(void)4{ 7 10p1 = gp; 13如果(p2){ 15 p3 = * gp; 16} 17} |
请注意,中间的READ_ONCE()不会阻止另外两个加载融合,尽管这三个加载都是从同一个变量加载。

存储融合可能发生在编译器注意到对某个变量的一对连续存储操作而没有来自该变量的加载操作时。在这种情况下,编译器有权省略第一个存储操作。这在单线程代码中从来不是问题,事实上,在正确编写的并发代码中通常也不是问题。毕竟,如果两个存储操作迅速连续执行,其他线程几乎不可能从第一个存储操作中加载值。
但是,也有例外,例如清单4 .19所示。 函数shut_ it_ down()在第3行将状态存储到共享变量中 和8, 因此,假设neither start_shutdown()nor finish_shutdown()访问状态,编译器可以合理地删除第3行上的store到状态。 不幸的是,这意味着work_until_shut_dow n()将永远无法退出跨越第14行的循环 和15, 因此,它永远不会设置other_task_ready,这反过来意味着shut_it_down()永远不会退出跨越第5行的循环 和6 ,即使编译器选择不合并第5行的连续加载fromother_task_ready。
| 1 a=1; | |
| 2如果 | |
| 3 | a =0; |
| 4 | do abunch_of_stuff(&a); |
| 5} | |
| 1 r1=p; | |
| 2如果(不太可能(r1)) | |
| 3 | |
| 4 | |
| 5 | |
死码消除可能发生在编译器发现加载的值从未被使用,或者变量被存储但从未被加载时。这当然可以消除对共享变量的访问,进而破坏内存排序原语,导致并发代码以令人惊讶的方式运行。迄今为止的经验表明,这样的意外很少会让人感到愉快。特别是当外部代码通过符号表定位变量时,仅存取变量的情况尤为危险:编译器必然不知道这些外部代码的访问,因此可能会消除外部代码所依赖的变量。
可靠的并发代码显然需要一种方法,使编译器保存对共享内存的重要访问的数量、顺序和类型,第4.3.4.2节讨论了这个主题 和4.3.4.3 ,接下来是这些。
4.3.4.2易挥发溶液
尽管现在备受诟病,在C11和C++11[ Bec11]问世之前,volatile关键字是并行编程者工具箱中不可或缺的工具。这引发了一个问题,即volatile究竟意味着什么,即使是最新的版本也未能给出精确的答案[Smi19]。 此版本保证了“通过易失性值的访问严格根据抽象机的规则进行评估”,易失性访问是副作用,它们是四个向前推进指标之一,其确切语义由实现定义。或许最清晰的指导来自这一非规范注释:
易失性是指实现中避免对对象进行激进优化的提示,因为对象的值可能通过实施者无法检测到的方式发生变化。此外,对于某些实现,易失性可能意味着访问对象需要特殊的硬件指令。详细语义参见6.8.1。一般来说,C++中易失性的语义与C中相同。
这段措辞或许会让编写低级代码的人感到安心,但编译器开发者可以完全忽略非规范注释。相比之下,程序员可能会更加确信编译器开发者会尽量避免破坏设备驱动程序(尽管这可能需要与设备驱动开发人员进行几次坦诚而开放的讨论),并且设备驱动程序至少施加了以下约束[M WPF18]:
1.当可用该访问大小和类型的机器指令时,禁止实现撕裂对齐的易失性访问。12 当前代码依赖于此约束以避免不必要的加载和存储撕裂。
| 1ptr =READ_ONCE(global_ptr); | |||||
| 2 | 如果 | (ptr | != NULL&& ptr | < | 高地址) |
| 3 | do_low(ptr); | ||||
| 1,同时(!READ_ ONCE(need_ to_ stop)) 2do_something_quickly(); |
| 清单4.27:取消邀请一个虚构的商店 | |
| 1如果(条件) | |
| 2 | WRITE_ONCE(a,1); |
| 否则 | |
| 4 | |
| 清单4.28:防止C编译器融合负载 | |
| 1小时 | |
| 2 | 屏障 |
| 3 | |
| 4 | 屏障 |
| 5} | |
但是,这并不能阻止代码的重新排序,这需要一些额外的技巧,这些技巧在第4.3.4.3节中进行了介绍。
最后,可以使用WRITE_ONCE()来防止清单4.20中所示的存储发明 ,结果代码如清单4.27所示。
总之,易失性关键字可以在加载和存储操作为机器大小且正确对齐的情况下防止加载撕裂和存储撕裂。它还可以防止加载融合、存储融合、虚拟加载和虚拟存储。然而,尽管它可以阻止编译器重新排序易失性访问,但无法阻止CPU重新排序这些访问。此外,它也无法阻止编译器或CPU重新排序非易失性访问与易失性访问之间的关系。要防止这类重排序,需要采用下一节中描述的技术。
4.3.4.3组装解决方案的其余部分
传统上,通过使用汇编语言来提供额外的排序,例如GCC的asm指令。奇怪的是,这些指令实际上并不需要包含汇编语言,如清单4.9中所示的barrier()宏。
在屏障()宏中,__ asm__引入了asm指令,__ volatile防止编译器优化掉asm,空字符串表示不生成实际指令,而最终的“内存”告诉编译器这个无操作的asm可以任意改变内存。作为回应,编译器会避免在屏障()宏中移动任何内存引用。这意味着实时销毁循环的展开如清单4.17所示。 可以通过添加barrie r()调用来防止,如第2行所示 和4 见清单4.28。 这两行代码防止编译器从任一方向将load from need_to_stop推入或越过do_something_quickly()。
然而,这并不能阻止CPU重新排序引用。在许多情况下,这不是问题,因为硬件只能进行一定量的重排序。然而,也有像清单4.19这样的情况 硬件必须受到限制。清单4.26 防止了存储器熔断和发明,以及清单4.29 通过在第4行添加smp_mb()进一步防止剩余的重新排序, 8 ,10 , 18 , 和21。 smp_ mb()宏与清单4.9中所示的屏障()类似, 但是,用一个包含完整内存屏障指令的字符串替换空字符串,例如,在x86上使用“mfence”或在Po werPC上使用“sync”。

一些读-改写原子操作也提供了排序,其中一些在第4.3.5节中介绍。 在一般情况下,内存排序可能相当微妙,如第15章所述。下一节介绍内存排序的替代方法,即限制甚至完全避免数据竞争。
4.3.4.4避免数据竞争
“医生,当我同时访问共享变量时,我的头很痛!”
“然后停止同时访问共享变量!!!”
医生的建议可能看似无济于事,但一种经过验证的方法是避免当前访问共享变量——即只有在持有特定锁时才能访问这些变量,这将在第七章中讨论。另一种方法是从特定的CPU或线程访问给定的“共享”变量,这将在第八章中讨论。 可以将这两种方法结合起来,例如,某个变量可能仅由特定的CPU或线程在持有某个锁的情况下修改,并且可以从同一CPU或线程读取,也可以从其他CPU或线程在持有同一锁的情况下读取。在所有这些情况下,对共享变量的所有访问都可能是普通的C语言访问。
以下是一些允许对给定变量进行普通加载和存储访问的情况,而对其他访问该变量则需要标记(例如READ_O NCE()andWRITE_ONCE()):
1.共享变量仅由指定的拥有CPU或线程修改,但会被其他CPU或线程读取。所有存储操作都必须使用WRITE_ONCE()。拥有CPU或线程可以使用普通加载。其他所有操作都必须使用READ_ONCE()进行加载。
2.共享变量仅在持有给定锁时被修改,但未持有该锁的代码可以读取。所有存储操作都必须使用WRITE_ONCE()。持有锁的CPU或线程可以使用普通的加载操作。其他所有操作都必须使用READ_ONCE()进行加载。
3.共享变量仅在持有特定锁的CPU或线程修改时才会被修改,但其他CPU或线程,或者不持有该锁的代码可以读取。所有存储操作都必须使用WRITE_ONCE()。持有锁的CPU或线程可以使用普通加载,任何持有锁的CPU或线程也可以这样做。其他所有操作都必须useREAD_ONCE()for loads。
共享变量仅由特定的CPU或线程以及该CPU或线程上下文中运行的信号或中断处理程序访问。处理程序可以使用普通的加载和存储操作,任何阻止了处理程序被调用的代码也可以这样做,即那些阻塞了信号和/或中断的代码。所有其他代码必须使用READ_ONCE()和WRITE_ONCE()。
5.共享变量仅由特定的CPU或线程访问,以及由该CPU或线程上下文中运行的信号或中断处理程序访问,且处理程序在返回前总是会恢复其写入的所有变量的值。处理程序可以使用普通的加载和存储操作,任何阻止处理程序被调用的代码也可以这样做,即那些阻止信号和/或中断的代码。所有其他代码可以使用普通的加载操作,但必须useWRITE_ONCE()以防止存储撕裂、存储融合和虚构的存储。

在大多数其他情况下,对共享变量的加载和存储必须分别使用useREAD_ONCE()和WRITE_ONCE()或更高级别的操作。但需要重申的是,neitherREAD_ONCE()和WRITE_ONCE()除了在编译器内部之外,不提供任何顺序保证。参见上述第4.3.4.3节。 或第15章,以了解有关此类担保的信息。
第5章介绍了许多避免数据竞争的模式。
Linux内核提供了多种原子操作,但type atomic_t上定义的原子操作是一个很好的起点。byatomic_read()和atomic_set()分别提供了普通的非撕裂读取和存储。bysmp_load_acquire()提供了获取加载,smp_store_release()提供了释放存储。
提供了一些非值返回的获取和添加操作,如byatomic_add()、atomic_sub()、atomic_inc()、andatomic_de c()等。bothatomic_dec_和_test()以及atomic_ sub_和_test()提供了返回零指示的原子递减操作。atomic_add_return()则提供了一个返回新值的原子加法操作。atomic_add_unless()和atomic_inc_not_zero()提供了条件性的原子操作,除非原子变量的原始值与指定值不同,否则不会发生任何操作(这些操作对于管理引用计数器非常有用)。
原子交换操作由atomic_xchg()提供,而受推崇的比较交换(CAS)操作则由atomic_cmpxchg()提供。这两种操作都会返回旧值。Linux内核中还有许多其他原子RMW原语,详见Linux内核源代码树中的Documentation/ atomic_t. txt文件。14 本书的CodeSamples API与Linux内核的API非常相似。
| DEFINE_PER_THREAD(类型,名称)DECLARE_PER_THREAD(类型,名称)per_thread(名称,线程) __get_thread_var(姓名)init_per_thread(姓名,v) |
| Linux内核中的usesDEFINE_PER_CPU()用于定义一个非CPU变量,this_cpu_ptr()用于引用此CPU的给定per- CPU变量实例,per_cpu()用于访问指定CPU的给定per- CPU变量实例,以及其他许多专用的per- CPU操作。 清单4.30 显示了此书的每线程变量API,该API以Linux内核的每CPU变量API为模型。此API提供了每线程等效于全局变量的功能。虽然严格来说,此API不是必需的,15 它可以为Linux内核代码提供一个很好的用户空间类比。 |
| 4.3.6.1 API成员 定义per_thread() TheDEFINE_PER_THREAD()原语定义了一个不带参数的变量。不幸的是,无法按照Linux内核sDEFINE_PER_CPU()原语允许的方式提供初始化器,但是有一个aninit_per_thread()原语允许轻松地在运行时进行初始化。 声明每个线程() DECLARE_PER_THREAD()原语是C语言中的声明,而不是定义。因此,可以使用DECLARE_PER_THREAD()原语访问在其他文件中定义的每个线程变量。 每线程() per_thread()原语访问指定线程的变量。 get_thread_var() __ get_ thread_ var()原语访问当前线程的变量。 init_per_thread() Theinit_per_thread()原始集合将指定变量的实例转换为指定值。Linux内核通过常规的C初始化来实现这一点,它巧妙地利用了链接程序脚本和CPU联机过程中执行的代码。 假设我们有一个计数器,它经常增加,但很少读取。如第5.2节将要说明的那样,使用线程变量来实现这样的计数器是有帮助的。这样的变量可以定义如下: |
| DEFINE_PER_THREAD(计数器); |
必须按照以下方式初始化计数器:
| init_per_thread(计数器,0); |
可以按如下方式递增此计数器的实例:
| p_counter=&__get_thread_var(计数器);WRITE_ ONCE(*p_计数器,*p_计数器+ 1); |
计数器的值是其实例的总和。因此,可以按如下方式收集计数器值的快照:
| for_each_thread(t) sum+=READ_ONCE(per_thread(counter,t)); |
同样,也可以使用其他机制获得类似的效果,但每线程变量结合了方便性和高性能,将在第5.2节中详细说明。
![]()
如果你陷入困境,改变你的工具;它可能会解放你的思维。
保罗·阿登,缩写
作为一个粗略的经验法则,使用最简单的工具来完成任务。如果可以的话,直接按顺序编程。如果这还不够,尝试使用shell脚本来协调并行性。如果生成的shell脚本fork()/ exec()开销(对于英特尔酷睿双核笔记本电脑上的最小C程序大约为480微秒)过大,可以尝试使用C语言中的fork()和wait()原语。如果这些原语的开销(对于最小子进程大约为80微秒)仍然过大,则可能需要使用POSIX线程原语,并选择合适的锁和/或原子操作原语。如果POSIX线程原语的开销(通常小于微秒级)过大,则可能需要使用第9章介绍的原语。当然,实际的开销不仅取决于你的硬件,更重要的是你如何使用这些原语。此外,始终记住,进程间通信和消息传递可以是共享内存多线程执行的良好替代方案,尤其是在你的代码充分利用了第6章中提到的设计原则时。
![]() 由于并发是在C语言首次用于构建并发系统后的几十年才被添加到C语言中的,因此存在多种并发方式
由于并发是在C语言首次用于构建并发系统后的几十年才被添加到C语言中的,因此存在多种并发方式
访问共享变量。在其他条件相同的情况下,第4.2.6节中描述的C11标准操作 应该是你的第一站。如果你需要以普通访问和原子访问两种方式访问某个共享变量,那么现代GCC原子性操作如第4.2.7节所述可能对你很有用。如果你正在处理使用经典的GCC同步API的旧代码库,那么你应该查看第4.2.5节 以及相关的GCC文档。如果您正在处理Linux内核或类似的代码库,该代码库结合使用volatile关键字和内联汇编,或者您需要依赖项来提供排序,请参阅第4.3.4节中介绍的材料 以及第15章中的内容。
无论你采取何种方法,请记住,随意破解多线程代码是一个极其糟糕的主意,特别是考虑到共享内存并行系统会利用你的智慧来对付你:你越聪明,就越容易为自己挖一个更深的坑,直到意识到自己陷入了困境[Pok16]。因此,有必要做出正确的设计选择以及正确的个体原语选择,这将在后续章节中详细讨论。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









