










目录
Shape Robust Text Detection with Progressive Scale Expansion Network
这篇文章是利用分割方法来做文字检测,主要克服了弯曲的文字区域检测问题。所以这篇文章叫做形状鲁棒性的文字检测。
主要有以下几个重点思想:
- 利用分割方法来做检测,提高了对非矩形文字区域检测的鲁棒性;
- 利用Progressive Scale Expansion方法实现了instance segment(实例分割);
- 多尺度分割。
当然这篇文章的方法对于矩形区域的文字检测也是相当准确的。
1 网络
首先来看一下这篇文章使用的网络结构,如下图所示。

作者是将这个网络分成两个部分来讲述,左边是一个FPN结构,右边是一个特征融合部分和progressive scale expansion部分。
其实我个人是把这个网络看做分割网络和后处理两个部分。
首先从网络输入到mask预测输出看做分割部分,后面将多个分割结果整合成一个最终的结果看做是progressive scale expansion后处理部分。
1.1 分割网络
分割网络由FPN, 特征融合,加上一个预测组成。
首先分割网络采用了几个技术:
- FPN: FPN是一个解决多尺度的常用的解决方案,上采样的不同层的feature map大小不一样,从大到小,这样在小的featuremap上检测相对大的目标,在大的featuremap上可以检测相对小的目标(因为分辨率更高),实现了一个多尺度检测;
- concat:concat在图像处理中也经常遇到,经常用来融合不同尺度或不同层级特征的信息,在这里就是将各个不同尺度的特征图(feature map)的特征进行融合,实现一个多尺度的识别。
- concat后面的卷积:concat只是简单的将特征堆叠起来,后面一般会接一个conv层来融合特征。
- concat后的卷积还用了一次upsample,即上采样,这是因为FPN最后一层的数据是原图的一半,所以这里特征融合一个又进行了一次上采样来让预测结果和原图一样大小。
- sigmoid来预测n个mask。
1.2 后处理
后处理采用的是一个简单的像素点划分,有点类似区域生长,只是说在一个范围内进行区域生长。
mask最小的预测结果实现了instance分割,即每个文字块是相互分离的。最大的mask就是最终的分割结果(但是没有进行instance分割),但有时候文字块区域是相互黏连的,所以需要通过最小的mask的信息来讲这些黏连的区域分离。
具体过程就如下所示:

扩展基于广度优先搜索算法,该算法从多个内核的像素开始,迭代地合并相邻的文本像素。对于冲突的像素,只能被一个kernel合并,通过先到先得的规则合并。由于是这种根据下一个mask的边界来扩展区域的,所以不会影响最后的结果。
2 构建数据集

需要创建多个不同目标大小(经过不同尺度的缩小)的mask。文章中是使用图形学的方法来进行创建的。但是我决定也可以使用形态学腐蚀的方法创建。
文章使用Vatti clipping algorithm方法来进行mask的腐蚀。
腐蚀的边界距离是通过这个公式计算得到的:
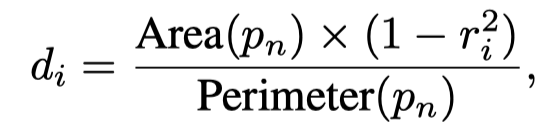
并且缩小的倍数是计算得到的,其实就是一个插值得到中间的倍数,例如从0.4-1倍,总共5个mask,那么就不是完整的从0.4,0.5,0.6,…这样下去,所以还是要计算一下的。公式如下:
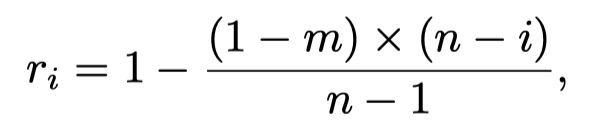
m表示最低是多少倍,n表示有几个mask,r就是倍数,d是边界到腐蚀以后边界的距离,p表示mask区域。
代码:
import pyclipper
import Polygon as plg
def get_bboxes(img, gt_path):
h, w = img.shape[0:2]
lines = util.io.read_lines(gt_path)
bboxes = []
tags = []
for line in lines:
line = util.str.remove_all(line, '\xef\xbb\xbf')
gt = util.str.split(line, ',')
x1 = np.int(gt[0])
y1 = np.int(gt[1])
bbox = [np.int(gt[i]) for i in range(4, 32)]
bbox = np.asarray(bbox) + ([x1 * 1.0, y1 * 1.0] * 14)
bbox = np.asarray(bbox) / ([w * 1.0, h * 1.0] * 14)
bboxes.append(bbox)
tags.append(True)
return np.array(bboxes), tags
def dist(a, b):
return np.sqrt(np.sum((a - b) ** 2))
def perimeter(bbox):
peri = 0.0
for i in range(bbox.shape[0]):
peri += dist(bbox[i], bbox[(i + 1) % bbox.shape[0]])
return peri
def shrink(bboxes, rate, max_shr=20):
rate = rate * rate
shrinked_bboxes = []
for bbox in bboxes:
area = plg.Polygon(bbox).area()
peri = perimeter(bbox)
pco = pyclipper.PyclipperOffset()
pco.AddPath(bbox, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON)
offset = min((int)(area * (1 - rate) / (peri + 0.001) + 0.5), max_shr)
shrinked_bbox = pco.Execute(-offset)
if len(shrinked_bbox) == 0:
shrinked_bboxes.append(bbox)
continue
shrinked_bbox = np.array(shrinked_bbox[0])
if shrinked_bbox.shape[0] <= 2:
shrinked_bboxes.append(bbox)
continue
shrinked_bboxes.append(shrinked_bbox)
return np.array(shrinked_bboxes)
3 损失函数 LOSS
损失由完整的mask的loss加上腐蚀以后mask的loss,其中两项是加权相加:
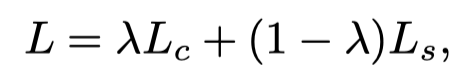
c表示完整的(complete),s表示(腐蚀后的,shrunk),Ls是所以腐蚀后的mask loss相加得到的。
使用1-dice coefficient作为loss,来避免样本不平衡(前景和背景)的影响。dice coefficient计算如下:
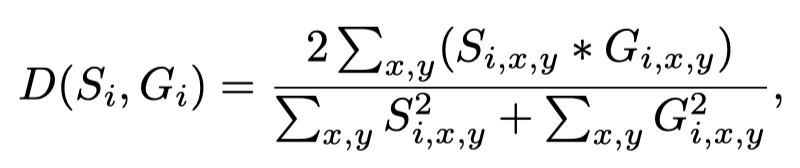
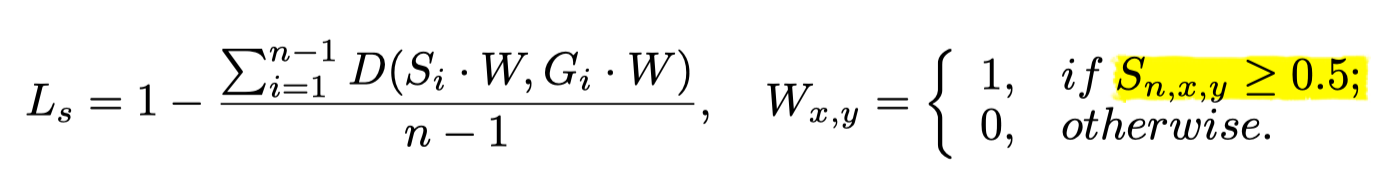
并且腐蚀后的mask的loss是在预测区域(注意不是标注区域内)内计算的,这个和之前我其他任务中在G里面计算loss不一样,这个是在预测的区域内计算loss,这样的一个好处可能是假阳会少,因为如果在G里面计算,那么G外面预测的假阳就没用计算在loss里面。
最后还使用了在线难例挖掘。
4 augment
数据增强使用了,水平翻转,随机旋转,随机缩放,随机剪裁640x640大小。
代码:
import pyclipper
import Polygon as plg
def random_horizontal_flip(imgs):
if random.random() < 0.5:
for i in range(len(imgs)):
imgs[i] = np.flip(imgs[i], axis=1).copy()
return imgs
def random_rotate(imgs):
max_angle = 10
angle = random.random() * 2 * max_angle - max_angle
for i in range(len(imgs)):
img = imgs[i]
w, h = img.shape[:2]
rotation_matrix = cv2.getRotationMatrix2D((h / 2, w / 2), angle, 1)
img_rotation = cv2.warpAffine(img, rotation_matrix, (h, w))
imgs[i] = img_rotation
return imgs
def scale(img, long_size=2240):
h, w = img.shape[0:2]
scale = long_size * 1.0 / max(h, w)
img = cv2.resize(img, dsize=None, fx=scale, fy=scale)
return img
def random_scale(img, min_size):
h, w = img.shape[0:2]
if max(h, w) > 1280:
scale = 1280.0 / max(h, w)
img = cv2.resize(img, dsize=None, fx=scale, fy=scale)
h, w = img.shape[0:2]
random_scale = np.array([0.5, 1.0, 2.0, 3.0])
scale = np.random.choice(random_scale)
if min(h, w) * scale <= min_size:
scale = (min_size + 10) * 1.0 / min(h, w)
img = cv2.resize(img, dsize=None, fx=scale, fy=scale)
return img
def random_crop(imgs, img_size):
h, w = imgs[0].shape[0:2]
th, tw = img_size
if w == tw and h == th:
return imgs
if random.random() > 3.0 / 8.0 and np.max(imgs[1]) > 0:
tl = np.min(np.where(imgs[1] > 0), axis = 1) - img_size
tl[tl < 0] = 0
br = np.max(np.where(imgs[1] > 0), axis = 1) - img_size
br[br < 0] = 0
br[0] = min(br[0], h - th)
br[1] = min(br[1], w - tw)
i = random.randint(tl[0], br[0])
j = random.randint(tl[1], br[1])
else:
i = random.randint(0, h - th)
j = random.randint(0, w - tw)
# return i, j, th, tw
for idx in range(len(imgs)):
if len(imgs[idx].shape) == 3:
imgs[idx] = imgs[idx][i:i + th, j:j + tw, :]
else:
imgs[idx] = imgs[idx][i:i + th, j:j + tw]
return imgs
5 最后
细节可看论文,这里只介绍了文章的主要思想和内容。
6 引用
- Shape Robust Text Detection with Progressive Scale Expansion Network
- https://github.com/whai362/PSENet
- https://github.com/whai362/PSENet/blob/master/dataset/ctw1500_loader.py#L40















 562
562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









