







- 找对方法理解不难,还是需要好的教程。
- 这里的状态价值、行为价值我觉得都像是神经网络里面的损失函数(loss),用来优化模型参数。价值函数和价值的区别就像损失函数和损失的区别。
- 马尔可夫性质:下一个状态只取决于当前状态;
- 概率论的研究对象是静态的随机现象,而随机过程的研究对象是随时间演变的随机现象(例如天气随时间的变化、城市交通随时间的变化),随机现象便是状态的变化过程。
- 给定一个马尔可夫过程,我们就可以从某个状态出发,根据它的状态转移矩阵生成一个状态序列(episode),这个步骤也被叫做采样(sampling);
- 在马尔可夫过程的基础上加入奖励函数(也就是reward) 和折扣因子(gamma),就可以得到马尔可夫奖励过程(Markov reward process, MRP),其实就是一个trajectory,叫什么并不重要,主要包含状态-奖励-状态,然后reward加起来可以得到一个return,如果乘以衰减系数(折扣因子)就是discounted return。
- 价值函数的输入为某个状态,输出为这个状态的价值。也就是在某个state的return。
- 奖励(reward,R)和回报(return, G)的关系:多个奖励组合成一个回报(为了好记忆总结的)。
- Gt = Rt + gamma * G(t+1), 也就是把下面公式 后面的gamma提出来。
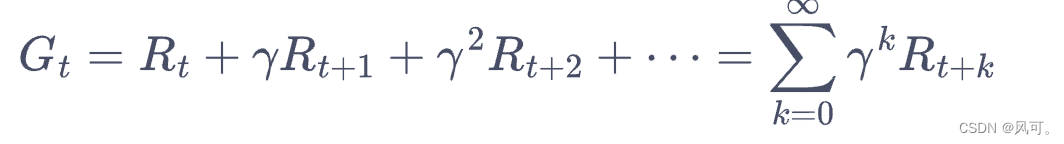
- 贝尔曼方程:当前state的价值(state value)等于当前的reward,加上折扣因子乘以状态转移概率乘以下一个state的价值,简单说就是当前的价值是和当前的价值 还有 后面每个可以遍历的路径有关。
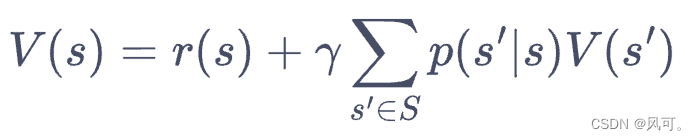
- n个变量 n个方程,就可以解出n个变量的值,这就是贝尔曼方程的解析解(线性代数)。
- 求解较大规模的马尔可夫奖励过程中的价值函数时,可以使用动态规划(dynamic programming)算法、蒙特卡洛方法(Monte-Carlo method)和时序差分(temporal difference)
- 马尔可夫决策过程(Markov decision process,MDP);在马尔可夫奖励过程(MRP)的基础上加入动作,就得到了马尔可夫决策过程(MDP),其实不用太纠结这两个,反正有动作的就是决策过程。奖励过程就是只根据状态转移的概率计算return。
- 连续状态的 MDP 环境,那时状态集合都不是有限的(游戏)。现在我们主要关注于离散状态的 MDP 环境(走格子),此时状态集合是有限的。
- 智能体就是做动作的那个人。策略就是一个动作的集合,哪个state做那个动作。比如走格子这个游戏,走格子的人就是智能体,棋盘就是环境。所以就有了不同的策略得到的return就不一样。虽然说可能环境p(s'| s, a)是一样的但是策略p(a | s)不一样结果也不一样。就像下棋,那么p(s'| s, a)就表示你向前走一步那他肯定是会走一步,但是p(a | s)就是不同的人在同一s他的action a是不一样的。
- 策略(Policy):π,都是p开头的读音。
- 确定性策略(deterministic policy)时,它在每个状态时只输出一个确定性的动作,即只有该动作的概率为 1;
- 随机性策略(stochastic policy)时,它在每个状态时输出的是关于动作的概率分布,然后根据该分布进行采样就可以得到一个动作;
- 从trajectory的return理解,state value(状态价值,V)和action value(动作价值, Q)的关系,既然是value(价值),其实就是return,在某个state的价值就是从这个state出发所有可能的trajectory(轨迹)的return的加权和,也就是下一个所有可能的state value的加权和。某个action的价值就是做了这个action以后所有可能的trajectory(轨迹)的return的加权和。这样理解的话:
- state value 就等于所有可能的action value的加权和,因为都是trajectory的return。
- 状态价值是针对某个状态。当前状态的价值就取决于后面可能的动作的收益。

-
- 动作价值是针对某个动作。
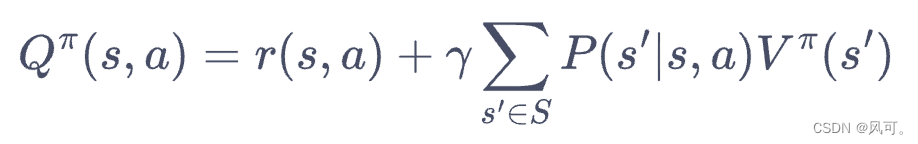
- 贝尔曼期望方差:就去把上面的公式相互带入:
- 价值函数和贝尔曼方程是强化学习非常重要的组成部分,之后的一些强化学习算法都是据此推导出来的,读者需要明确掌握!

- policy π(a | s) 条件概率和做了某个状态后状态转移条件概率p(s' | s, a)的区别, π是选择哪个动作的概率(而且这个动作不一定是说走到那个state,也可以是一些制定的其他的动作,比如摇色子,还是走一步),p是到下一个状态s'的概率,不一定说是做了这个动作,一定可以到达。
- 上面这两个相乘才是状态转移的概率
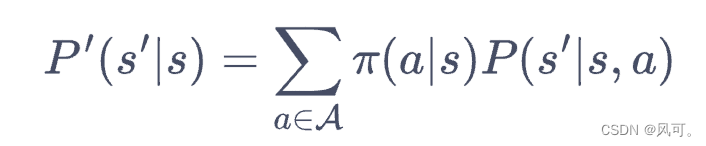
- (注:这些都是用来估计一个确定的策略的“价值”,类似于计算一个loss,然后才能根据loss来收敛)用蒙特卡洛方法来估计一个策略在一个马尔可夫决策过程中的状态价值函数,用蒙特卡洛方法的好处在于我们不需要知道 MDP 的状态转移函数和奖励函数,它可以得到一个近似值,并且采样数越多越准确。
- 蒙特卡洛方法(Monte-Carlo methods)也被称为统计模拟方法,是一种基于概率统计的数值计算方法。其实就是采样很多条可能的路径,然后算一个return。
- 占用度量:“动作-状态” 配对 被访问到的概率,也就是一种state和一种action同时出现的概率。
- 可以统计计算,就是所有情况除以所以可能的配对的次数
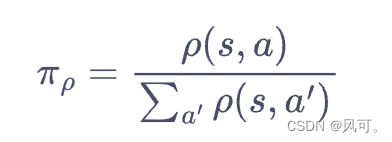
- 最优策略(optimal policy) 就是最好的策略,就是价值最大的策略。不同太过于纠结,比如就是下好一盘棋的最好策略。
- 最优动作就当前最好的动作。也就当前最好的action value,所以要当前的reward加上后续最好的state value。
- 反正一句话:最优就是 state value要最好,action value才能能最好。其实公式都是一样的。
- 带星的表示最优;
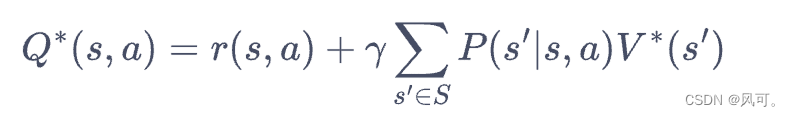
- 资料:
- 动手学强化学习:马尔可夫决策过程
- 强化学习的数学原来:第5课-蒙特卡洛方法(Part5-MC Epsilon-Greedy算法介绍)【强化学习的数学原理】_哔哩哔哩_bilibili















08-03
 644
644
644
07-23
1180
1180
04-26
1万+
1万+
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









