







Gym实现了经典的”agent-environment“(智能体-环境)的循环。
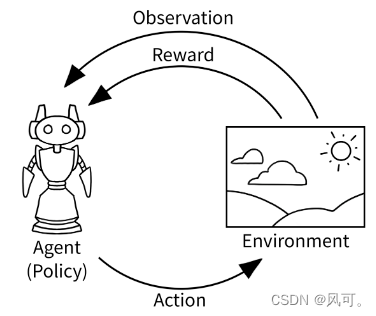
智能体会执行动作(action),然后观察(observes)到环境状态(state)的变化,并且会收到奖励(reward),这样的一次“动作-观察”循环叫做timestep。
强化学习的目的就是为了最大化总体的奖励。
经过一些时间步骤后,环境可能进入结束状态。例如,机器人可能已经崩溃了!在这种情况下,我们希望将环境重置为新的初始状态。
hello gym
下面是一个gym的案例,每次的action是随机采样的。
import gym
# env = gym.make("LunarLander-v2", render_mode="human")
env = gym.make("FrozenLake-v1", render_mode="human")
env.action_space.seed(42)
observation, info = env.reset(seed=42)
print(env.action_space)
for i in range(1000):
# print(env.action_space)
print(env.action_space.sample())
observation, reward, terminated, truncated, info = env.step(env.action_space.sample())
if terminated or truncated:
observation, info = env.reset()
print("done")
env.close()Playing within an environment
在环境里面打游戏。
mapping用来映射键盘到action。
callback用来记录玩游戏过程中的reward。
import gym
import pygame
from gym.utils.play import play, PlayPlot
mapping = {(ord('w'),): 1, (ord('e'),): 2, (ord('r'),): 3}
mapping = {(pygame.K_LEFT,): 3, (pygame.K_RIGHT,): 1, (pygame.K_DOWN,): 2,(pygame.K_UP,): 0, } ## 键盘映射到action
def callback(obs_t, obs_tp1, action, reward, terminated, truncated, info):
## 记录玩游戏过程中的信息
return [reward,]
plotter = PlayPlot(callback, 30 * 5, ["reward"])
play(gym.make("LunarLander-v2",render_mode='rgb_array'), keys_to_action=mapping, callback=plotter.callback)















 440
440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









