






 本文介绍了如何在gym库的FrozenLake-v1环境中使用Q-learning算法进行训练,通过调整参数如环境大小、滑动特性以及探索策略,优化了训练过程,使学习速度加快,便于理解和学习。
本文介绍了如何在gym库的FrozenLake-v1环境中使用Q-learning算法进行训练,通过调整参数如环境大小、滑动特性以及探索策略,优化了训练过程,使学习速度加快,便于理解和学习。
在学习Q-learning算法时,想利用python的gym库中的FrozenLake-v1,找了半天,要么就是FrozenLake-v0版本问题,要么就是step()函数传参时由于版本问题,或者在游戏开始后小人在运动时出现了一系列问题。本文在参考另一篇的文章的基础上做了一些改进,适当加快运行速度,能够在短时间内看到Q表的更新,避免在学习初期学习速度太慢,毕竟我们只是学习原理。
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。原文链接:https://blog.csdn.net/phmatthaus/article/details/131722365
目录
一、导入库
import random
import gym
import numpy as np二、初始化
1、环境说明
(参考内置文档frozen_lake.py)
- action的0、1、2、3分别代表左、下、右、上
- gym.make传参时,建议:
env = gym.make('FrozenLake-v1', desc=None, map_name="4x4", is_slippery=False, render_mode = "human")这样一来,首先地图只有4*4,训练比价快,学会之后再用8*8的。is_slippery=False,小机器人就可以完全按照action行动,加快训练速度,结果也比较清晰,便于初学者学习。至于is_slippery=True之后具体运作原理见原文档。render_mode改变视图,需要pygame库(报错没什么库就在Pycharm终端处直接pip install pygame -i https://pypi.tuna.tsinghua.edu.cn/simple)
-
原frozen_lake.py文档部分内容如下
gym.envs.toy_text.frozen_lake
class FrozenLakeEnv(Env)
Frozen lake involves crossing a frozen lake from Start(S) to Goal(G) without falling into any Holes(H) by walking over the Frozen(F) lake. The agent may not always move in the intended direction due to the slippery nature of the frozen lake.
### Action Space The agent takes a 1-element vector for actions. The action space is (dir), where dir decides direction to move in which can be:
0: LEFT
1: DOWN
2: RIGHT
3: UP
### Observation Space The observation is a value representing the agent's current position as current_row * nrows + current_col (where both the row and col start at 0). For example, the goal position in the 4x4 map can be calculated as follows: 3 * 4 + 3 = 15. The number of possible observations is dependent on the size of the map. For example, the 4x4 map has 16 possible observations.
### Rewards
Reward schedule: - Reach goal(G): +1 - Reach hole(H): 0 - Reach frozen(F): 0
### Arguments
` gym.make('FrozenLake-v1', desc=None, map_name="4x4", is_slippery=True) `
desc: Used to specify custom map for frozen lake. For example,
desc=["SFFF", "FHFH", "FFFH", "HFFG"].
A random generated map can be specified by calling the function generate_random_map. For example,
``` from gym.envs.toy_text.frozen_lake import generate_random_map
gym.make('FrozenLake-v1', desc=generate_random_map(size=8)) ```
map_name: ID to use any of the preloaded maps.
"4x4":[
"SFFF", "FHFH", "FFFH", "HFFG" ]
"8x8": [
"SFFFFFFF", "FFFFFFFF", "FFFHFFFF", "FFFFFHFF", "FFFHFFFF", "FHHFFFHF", "FHFFHFHF", "FFFHFFFG",
]
is_slippery: True/False. If True will move in intended direction with probability of 1/3 else will move in either perpendicular direction with equal probability of 1/3 in both directions.
For example, if action is left and is_slippery is True, then: - P(move left)=1/3 - P(move up)=1/3 - P(move down)=1/3
### Version History * v1: Bug fixes to rewards * v0: Initial versions release (1.0.0)2、q-learning超参数定义
代码如下:
env = gym.make("FrozenLake-v1", render_mode = "human", is_slippery = False)
observation_space_size = env.observation_space.n
print(observation_space_size)
action_space_size = env.action_space.n
print(action_space_size)
q_table = np.zeros((observation_space_size, action_space_size))
print(q_table)
total_episodes = 10000 # Total episodes 训练次数
learning_rate = 0.8 # Learning rate 学习率
max_steps = 50 # Max steps per episode 一次训练中最多决策次数
gamma = 0.95 # Discounting rate 折扣率,对未来收益的折扣
# Exploration parameters
epsilon = 0.7q表初始如下,16个位置代表了16个状态,上下左右四个动作,所以Q表就是16*4.

三、训练(Q表更新)
1、循环探索
所有的改动都在注释里了
# For life or until learning is stopped
for episode in range(total_episodes):
# Reset the environment
state = env.reset()
state = state[0] # 我们需要第一个位置的参数state,prob暂时不用
step = 0
done = False
for step in range(max_steps):
# Choose an action a in the current world state (s)
# First we randomize a number
# 大概率根据Q表行动,也有一定概率随机行动
if random.uniform(0, 1) < epsilon:
# 根据Q值最大原则选取action,如果有多个action的Q相同且最大,则随机选取一个
state_all = q_table[state, :]
max_indices = np.argwhere(state_all == np.max(state_all)).flatten()
action = np.random.choice(max_indices)
else:
# 随机选取一个行动
action = env.action_space.sample()
# 利用step函数求新状态、奖励、结果等,这里需要5个参数,可以看看源文档
new_state, reward, done, truncated, info = env.step(action)
# Q表更新,也就是Q-learning的核心,具体原理不再赘述,在别的博客有很多
q_table[state, action] = q_table[state, action] + learning_rate * (
reward + gamma * np.max(q_table[new_state, :]) - q_table[state, action])
# 这里自行修改Q值,加快运行速度,这里看似“作弊”,但是不影响Q-learning的原理
# 比如靠左墙还左转,那么将Q值减为负值,下次直接跳过这个选择
if state == new_state:
q_table[state, action] = -1
# 掉进河里也将Q值减为负值
if done:
if reward == 0:
q_table[state, action] = -1
break
# Our new state is state
state = new_state
# Reduce epsilon (because we need less and less exploration) 随着智能体对环境熟悉程度增加,可以减少对环境的探索
if epsilon < 0.95:
epsilon = epsilon + 0.0012、训练结果
![]()
3、最终Q表

四、完整代码
import random
import gym
import numpy as np
env = gym.make('FrozenLake-v1', desc=None, map_name="4x4", is_slippery=False, render_mode = "human")
observation_space_size = env.observation_space.n
print(observation_space_size)
action_space_size = env.action_space.n
print(action_space_size)
q_table = np.zeros((observation_space_size, action_space_size))
print(q_table)
total_episodes = 10000 # Total episodes 训练次数
learning_rate = 0.8 # Learning rate 学习率
max_steps = 50 # Max steps per episode 一次训练中最多决策次数
gamma = 0.95 # Discounting rate 折扣率,对未来收益的折扣
# Exploration parameters
epsilon = 0.7
# For life or until learning is stopped
for episode in range(total_episodes):
# Reset the environment
state = env.reset()
state = state[0] # 我们需要第一个未知的参数state,prob暂时不用
step = 0
done = False
for step in range(max_steps):
# Choose an action a in the current world state (s)
# First we randomize a number
# 大概率根据Q表行动,也有一定概率随机行动
if random.uniform(0, 1) < epsilon:
# 根据Q值最大原则选取action,如果有多个action的Q相同且最大,则随机选取一个
state_all = q_table[state, :]
max_indices = np.argwhere(state_all == np.max(state_all)).flatten()
action = np.random.choice(max_indices)
else:
# 随机选取一个行动
action = env.action_space.sample()
# 利用step函数求新状态、奖励、结果等,这里需要5个参数,可以看看源文档
new_state, reward, done, truncated, info = env.step(action)
# Q表更新,也就是Q-learning的核心,具体原理不再赘述,在别的博客有很多
q_table[state, action] = q_table[state, action] + learning_rate * (
reward + gamma * np.max(q_table[new_state, :]) - q_table[state, action])
# 这里自行修改Q值,加快运行速度,这里看似“作弊”,但是不影响Q-learning的原理
# 比如靠左墙还左转,那么将Q值减为负值,下次直接跳过这个选择
if state == new_state:
q_table[state, action] = -1
# 掉进河里也将Q值减为负值
if done:
if reward == 0:
q_table[state, action] = -1
break
# Our new state is state
state = new_state
# Reduce epsilon (because we need less and less exploration) 随着智能体对环境熟悉程度增加,可以减少对环境的探索
if epsilon < 0.95:
epsilon = epsilon + 0.001
补充
经过上述操作后,已经能够以较快速度训练出Q表,那么接下来,将再做一些细小的优化
1、
- 将观察模式改为ansi
- 将epsilon初始化为1.0,if语句中改为>号,然后在每一个episode结束后乘0.995衰减因子,直到衰减为0.05,这样一来,在初期基本上都是采取随机动作,在大约600个回合之后以95%的概率按照q表进行行动。
- 将自行修改的state值注释掉,即完全按照标准的Q-learning算法运行
env = gym.make('FrozenLake-v1', desc = None, map_name = "4x4", is_slippery = False, render_mode = "ansi")
epsilon = 1.0
if random.uniform(0, 1) > epsilon:
...
else:
...
# 这里自行修改Q值,加快运行速度,这里看似“作弊”,但是不影响Q-learning的原理
# 比如靠左墙还左转,那么将Q值减为负值,下次直接跳过这个选择
# if state == new_state:
# q_table[state, action] = -1
# 掉进河里也将Q值减为负值
if done:
# if reward == 0:
# q_table[state, action] = -1
break
# Our new state is state
state = new_state
if epsilon > 0.05:
epsilon = 0.995 * epsilon
由于将观察模式改为了ansi,大大加快了运行速度,Q表结果如下:
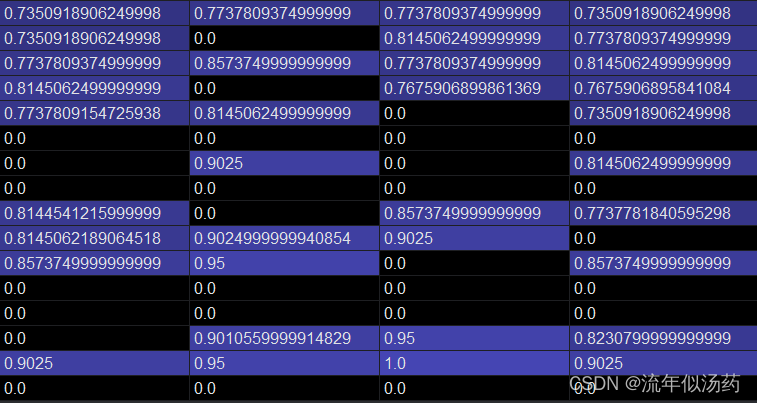
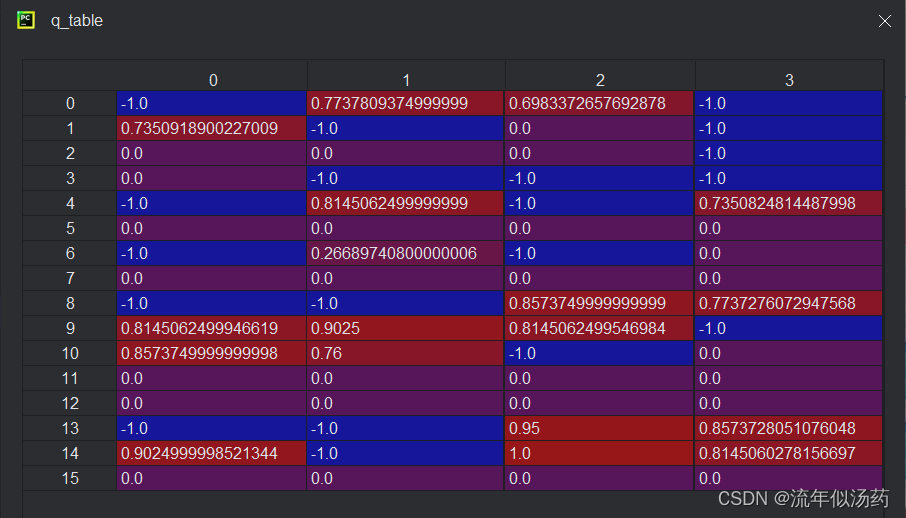
2、
- 设置is_slippery = True,再次运行,q表如下。但是由于加入了滑行,所以每次运行之后Q表不太一样


3、试试8*8的,关掉is_slippery,数据太长(64*4),只放一部分

测试一下:

效果不错















 921
921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









