







LLM的各类评估
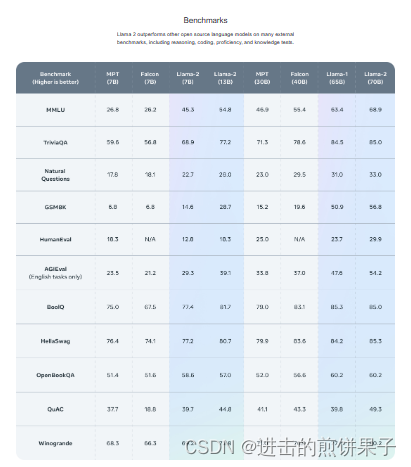
MMLU
2020年提出,衡量文本模型的多任务准确性。该测试涵盖了57个任务,包括基本数学、美国历史、计算机科学、法律等多个领域。为了在这个测试中获得高准确性,模型必须具备广泛的世界知识和问题解决能力。
更类似于我们评估人类的方式。该基准涵盖了57个科目,包括STEM(科学、技术、工程、数学)、人文科学、社会科学等领域。它的难度从初级水平到高级专业水平不等,测试的内容既涵盖世界知识,又涉及问题解决能力。科目涵盖传统领域(如数学和历史)以及更专业的领域,如法律和伦理学。基准的细粒度和广度使其能够发现模型的盲点。
MMLU的leaderboard连接
随机base25% llama 7B top5 35% 65B 63%
GPT-4 86%
mmlu-zs和mmlu-fs测试是MMLU基准中的重要组成部分,用于衡量模型在零样本和少样本学习中的能力。
zero-shot \ finetuned shot
TriviaQA
TriviaQA是一个阅读理解数据集,其中包含超过 65W 个问题 - 答案 - 证据三元组。TriviaQA包括由爱好者撰写的95K个问题 - 答案对和独立收集的证据文件,平均每个问题6个证据,包括不限于wiki页面 网络搜索结果等,为回答问题提供高质量的远程监督(2017)















 2851
2851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









