







ALBEF BLIP BLIP2 InstructBLIP 前世今生
ALBEF
在此之前,各类多模态,都是朴素的 目标检测框+后处理
目标检测提取出图片中的目标等,不够端到端
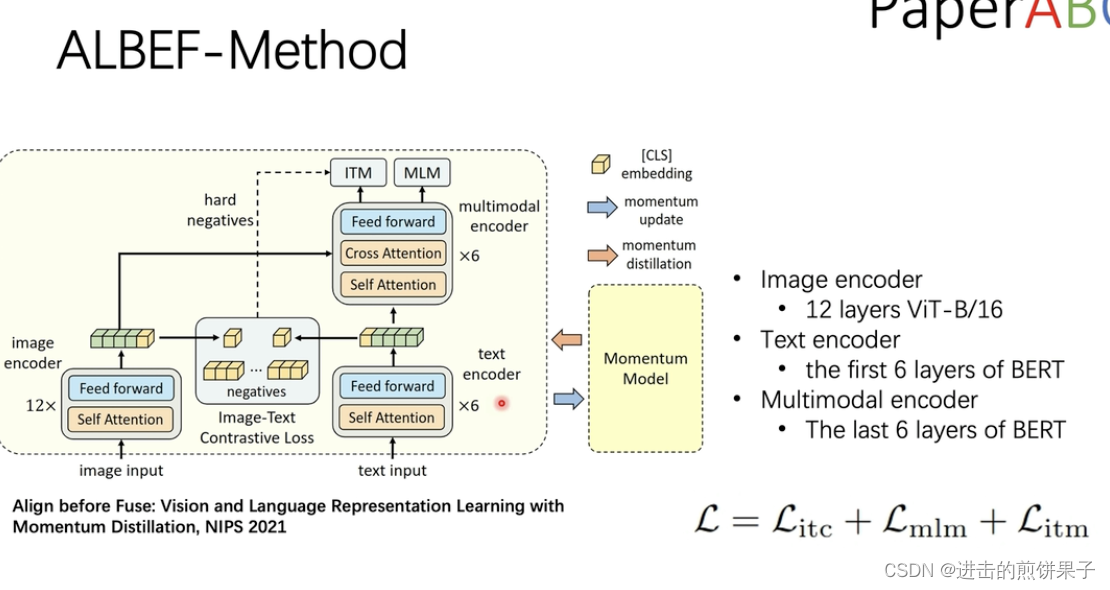
右边文本Bert 前6层是文本编码,后6层变为 特征融合
ITC 用 图像和文本的cls 的全局类别 做loss,Image-Text Contrastive Learning,目的是在融合前学习到更好的单模态表征。受MoCo的启发,作者维护了两个队列来存储最近的M个图像-文本表示。 减少 文本到图片, 图片到文本 的图片特征的差别、
对比学习的精髓。 次相关的样本可作为 itm 的负样本对做难样例分类。
ITM 图像文本是否匹配的二分类任务,Image-Text Matching
MLM Masked Language Modeling,利用给定图像和上下文文本来预测mask词,完形填空loss
动量模型 momentum distillation
来源于Moco
原始encoder 复制一份为 momentum encoder,
用EMA 指数移动方式更新,作为teacher 模型,生成soft target
BLIP
motivation
encoder难以做生成任务,
encoder-decoder难以做检索任务
大规模图像文本对噪音太大

1234 四个模块
1 图像编码器
2 文本编码器
3 ITM匹配任务
4 LM是新增的decoder模块做生成任务
双向自注意力 LM 续写后半句(不是完形填空)
causal 把后面部分masked掉
从Bert形式换为GPT形式
数据去噪
BLIP2
BLIP
YOLOX
1 预测分支解耦,性能提高。而不是直接85个channel直接80个类,4个xywh,1个obj
2 添加Mosaic和MixUp,但在最后15epochs时关闭
3 Anchor-free
4 正样本分配方法
Multi positives。将中心3*3区域都认为是正样本,即从上述策略每个gt有1个正样本增长到9个正样本
SimOTA 不单看一个anchor和GT,而是找全局最优。全局计算cost后排序分配正样本。
5 端到端无NMS。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









