







1.5 Decision Theory
在我们计算出所需要的概率之后,该如何决策,如何做出准确合理的预测,这便是这一小节主要讨论的内容。书上举了一个诊断癌症病人的例子,辅助接下来的探讨。
1.5.1 Minimizing the misclassification rate
拿诊断癌症病人的例子来讲,我们的目标就是要降低病人的误诊率。误诊有两种情况,第一种是把本无癌症的病人诊断为了癌症患者,第二种则是与上述情况刚好相反。
所以可以定义误诊率为:
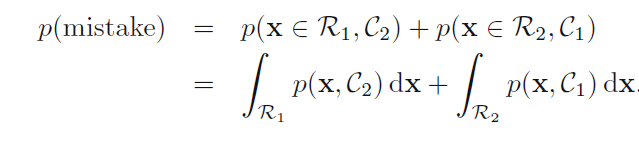
这个误诊率,或者把它简称为"错误率"的大致含义是,P(x落在R1区域,x属于C2类)与P(x落在R2区域,x属于C1类),即x落在了A区域中,却属于B类的概率。书上说我们根据p(x,c1)和p(x,c2)的相对大小关系,选择大的一个作预测,可以减小”错误率“。但是根据下面的图,”错误率“似乎又和你选择哪个p没有关系。
先看这幅图:
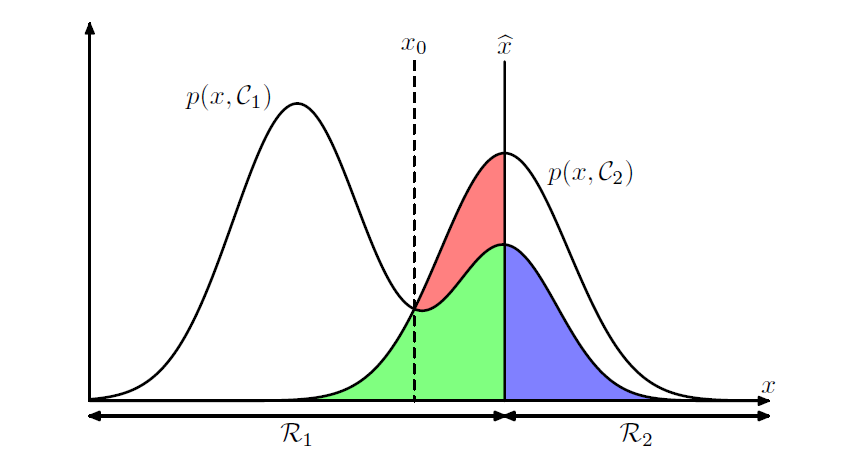
书上讲到,当我们改变x(hat)的时候,红色区域的面积也会改变,而绿色和蓝色区域的面积不变。当x(hat)平移到x0的时候,红色区域消失。关于这个图,要理解绿色区域和蓝色区域的面积之和不变,那么只要关注落在Rj区域内,又在p(x,Ck)(k!=j)下的所有面积均视为”错误率“。但是,这幅图我有点不理解:x的boundry和p是什么关系,当x的boundry改变的时候p(x,c)不应该变化么,而且从这幅图看,"错误率"的大小似乎和我们做预测时怎么选择p(x|c)是没有关系的?
接下来,作者题出了"正确率"的概念:
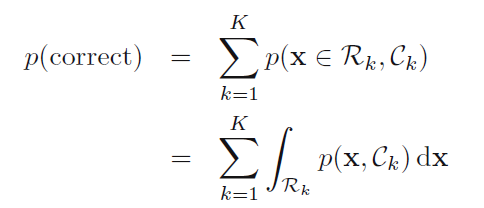
根据公式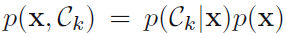
总之,根据"错误率"或"正确率"得出要选择最大的p(ck|x)的结论我没有看懂,希望有大神能做一点指点。
1.5.2 Minimizing the expected loss
有时候在实际问题中,我们会为"错误"赋予一些权值,例如我们宁可将一个没有病的病人误诊为癌症,也不愿漏诊一个癌症病人,一个是会遭受痛苦,后者最会丢掉生命。所以作者引出了Lkj的真实分类是k,我们将它划归到了j类中,k和j可等可不等)。我们定义一个loss matrix,而其元素便是Lkj。
于是我们把”错误率“的概念扩展到了”average loss“,定义入下:
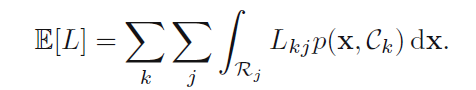
同样的,我们也可以根据公式和p(x)不变的原因,将联合概率改变为条件概率p(ck|x)。
1.5.3 The reject option
有一种方法可以减小我们的"错误率"或者是average loss,对于那些所有p(ck|x)都小于我们预置阈值theta的x,我们均不做预测。
1.5.4 Inference and decision
那么现在,我们有三种方法可以进行Inference和decision。
第一种:
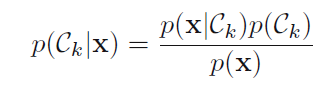
我们分别对p(x|ck)和p(ck)建模,因为p(x)可以做如下计算:
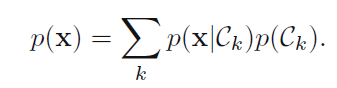
进而我们得到了后验概率。或者我们直接对联合概率建模也可以。最后再用决策理论,就完成了Inference和decision。这便是生成模型。
第二种:
我们直接对后验概率建模,再用决策理论,即判别模型。
第三种:
我们用一个判别函数,直接将输入x映射到一个分类中,这就将Inference和dicision两个步骤合二为一,同时也使我们不用对后验概率进行建模了。
这里既然提到了判别模型和生成模型,那就大致讨论一下我对两个模型异同的浅见:
假设样本为(xi,yi),是我们的目标变量。
判别模型:
我们更多只关注对于输入x,我们要输出什么样的y时,我们可以省去对联合概率的建模,直接对后验概率建模,即在p(y|x,theta)=p(x|y)p(y)/p(x)中,我们直接对p(y|x;theta)建模,这样相对于生成模型,我们简化了一些问题,只关注x的分类面。在p(theta|y)=p(y|theta,x)p(theta)/p(y)中,上节我们讨论过,当我们在考虑最大化目标时,不仅考虑p(y|theta,x),也考虑p(theta),这时,就会给我们的cost function加入正则化项。这是我的理解,有不对的希望大家指出来。
生成模型:
生成模型指的是我们要对联合概率,即p(x,y),或p(x|y)p(y)。联合概率密度建模相对复杂,但它不仅可以告诉你对于输入x应该输出什么样的y,还可以还原出p(x,y)的分布,包含的信息量更大。另外书上讲了,因为可以通过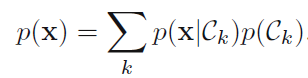
接下来,作者探讨了我们有很强大的理由去计算后验概率,而不是用一个判别函数草草了事,大致讲了四点,很清楚,这里就不多说了。
1.5.5 Loss functions for regression
这一节从概率的角度讲了回归问题的loss函数,并利用当loss函数是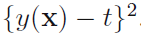
有两个公式没太搞清楚,贴在下面,希望大家能帮忙解答。
这个式子是怎么由书上是怎么由书上1.86推导而来的?
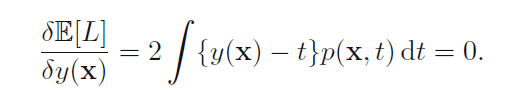
如书上对(y(x)-t)的平方展开后,代入1.87,对t积分交叉项是如何消失,然后变为下面式子的?
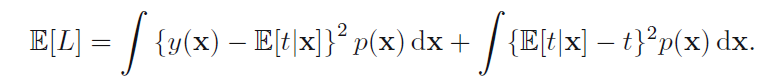















 789
789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









