







本系列是经典书籍《Pattern Recognition and Machine Learning》的读书笔记,正在研读中,欢迎交流讨论。
基本概念
1.
模式识别(Pattern Recognition):是指通过算法自动发现数据的规律,并进行数据分类等任务。
2. 泛化(generalization):是指对与训练集数据不同的新样本进行正确分类的能力。(模式识别的主要目标)
3.
分类(classification):将输入数据分到有限个数的类别中。
4.
回归(regression):预测输入数据对应的输出值,该输出值由一个或多个连续变量的值组成。
5.
强化学习(reinforcement learning):在给定的环境或条件下,找到合理的步骤或操作使奖赏最大化。
其特点之一是:在发现新的操作(exploration)和利用现有操作(exploitation)之间进行权衡
。
6.线性模型(linear models):只包含线性的未知参数的模型,例如多项式就是线性模型。
7.
RMSE(Root-Mean-Square Error,均方根误差):观测值与真实值的偏差的平方和与观测次数之比的平方根。
(可以反映预测的准确性)
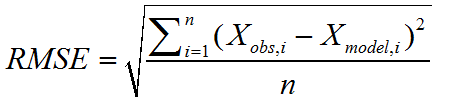
8. 在多项式曲线拟合中,多项式的阶数越高,参数的值也会越高。
当阶数过大时,将导致过拟合,此时参数的值非常大(正值)或非常小(负值),使拟合曲线出现很大的振荡。
解决过拟合的方法之一是:正则化,避免参数值过大或过小。
正则化参数(惩罚项)越大,参数值越小。
正则化参数过小,不能解决过拟合问题;正则化参数过大,将导致欠拟合。
9. 优化模型复杂度:使用验证集,交叉验证等等。
概率理论
模式识别中的不确定性(
uncertainty)一方面由于数据集的大小有限,另一方面是由于噪音。
概率规则:
加法规则(sum rule):
(marginal probability,边缘概率)
乘法规则(product rule):
(joint probability,联合概率)
1 贝叶斯理论(Bayes's theorem):

边缘概率可用加法规则计算:
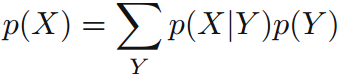
先验概率(prior probability):某个类发生的概率(主观)。
后验概率(posterior probability):给定输入数据,其被分到某一类的概率。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2145
2145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









