







之前为了搞清楚这块问题,看了很多文章都写的迷迷糊糊的,我尽量写的简单明了一点,包看懂就好。
先来思考索引的几个问题?
1. 为什么要给表加上主键?
2. 为什么加索引后会使查询变快?
3. 为什么加索引后会使写入、修改、删除变慢?
4. 什么情况下要同时在两个字段上建索引?
带着问题我们接下来看,索引是什么?它的底层是如何的相信你会有个不一样的体会。
1、索引
是帮助Mysql高效获取数据的排好序的数据结构。
核心在于:排好序、数据结构。既然是数据结构我们肯定是要探讨下它的原理。
下面举个例子:来看看索引的好处。下面有张表t,又图是以col2作为索引的二叉树数据结构,为什么这里用二叉树建立索引,你可以理解为这个是mysql索引初期的样子。
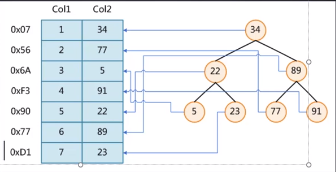
现在我们要对表t,查找col2=89的数据,sql语句为:select * from t where t.col2=89 limit 1
如果不加索引的话从表里面一条条往下查,需要查询6次才可以找到。经过了6次磁盘I/O,效率不高。
如果对col2建立了索引了之后,索引的数据结构如上面二叉树的结构。第一次跟根节点34比较,比它大继续向右查找,查询89只需要两次。查找次数相比之前减少了很多。效率也就提高了。以上的这种问题加索引后会使查询变快的例子。
接下来我们讨论下索引的数据结构演变过程。
2、索引数据结构
- 二叉树
- 红黑树
- Hash表
- B-Tree
1、先来说下二叉树作为索引会怎么样?可以理解为初期的索引结构
假如我们要对上图col1做为索引字段。会怎么样?
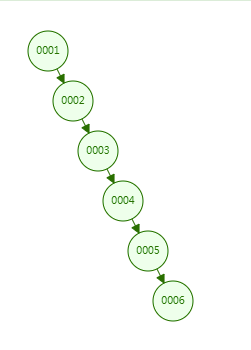
如果是此类数据的话,二叉树形成了一个线程结构,类似成一个单向的链表了,查询效率O(n)。查询叶子节点居然需要6次I/O,仅仅6行数据就要6次,如果上百万数据那这种结构肯定是不合理的。
2、为了优化二叉树的这种情况,优化之后使用红黑树(一种平衡的二叉树,为何叫平衡的二叉树,因为再往里面加元素的时候,二叉树多了一个自旋的过程,避免出现二叉树里面的单向结构。)
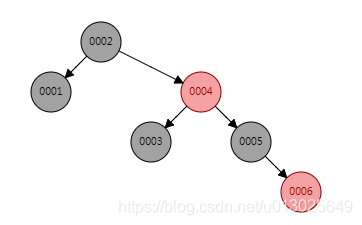
相比于二叉树,多了一步自旋平衡的一个过程。但是索引并没有选择这种机构,为什么?
6行数据,要经过4次的磁盘I/O。如果几百万数据,深度如何?所以后面的优化应该降低这个树的高度,减少磁盘I/O的次数。
下图举个例子,100w数据如果插进去,高度差不多20。
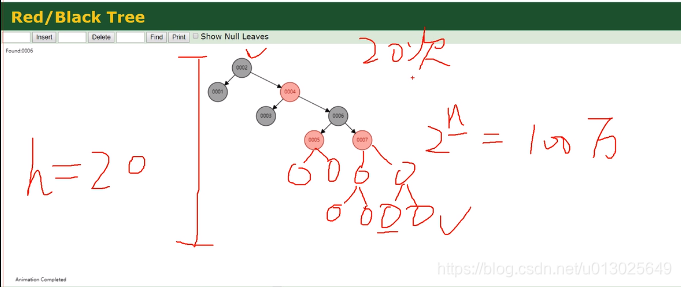
红黑树作为索引数据结构的问题:数据量太大,高度就太深,如果查找叶子节点的数据,查找磁盘索引I/O非常慢。
3、Hash表
对索引字段做hash计算,经过一次磁盘I/O就可以查到数据。
hash表相当是一个数组,索引字段做hash计算时相当与拿到数据的下标位置,然后根据这个位置直接找到元素,数据快时间复杂度O(1),效率很高。但是哈希索引不支持范围查找和排序的功能。
4、B+树(索引的底层数据结构)
在介绍B+树之前,先看下B树,B+树是B树的一个演变。
B树:
- 根节点至少包括2个孩子
- 每个节点最多含m个子节点
-
- 非根节点和叶节点外,每个节点至少含有ceil(m/2)个孩子【ceil上限】
-
- 叶子节点都位于同一层
-
- 每个非终端节点含有N个关键字信息
-
- Ki为关键字,升序排列
-
- 关键字个数n:[ceil(m/2)-1] <= n <= m-1 【比孩子节点少一个】
-
- 非叶子节点指针:P[1]指向关键字小于K[1]的子树;P[M]指向关键字大于K[M-1]的子树,其他P[i]指向关键字属于(K[i-k],k[i])的子树
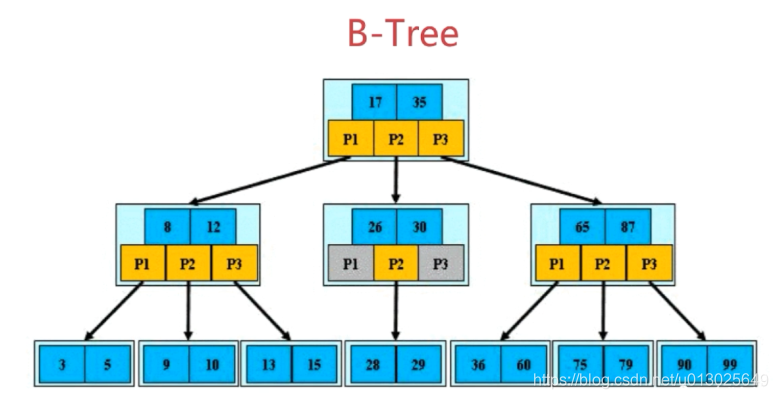
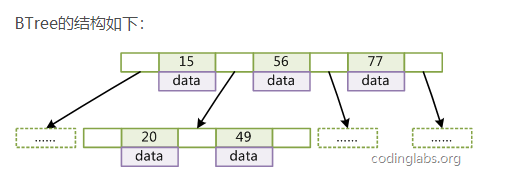
在BTree的机构下,就可以使用二分查找的查找方式,查找复杂度为h*log(n),一般来说树的高度是很小的,一般为3左右,因此BTree是一个非常高效的查找结构。那么思考下,这里树已经满足了我们索引的要求(少的I/O次数,查询效率也高)为何不用它?
我们可以在细节图中看到B树里面的元素节点信息包含了索引和Data数据的,这是不是可以便向的理解为每次磁盘I/O加载时节点读取是有限的,特别是在data对象数据量比较大的时候。
知道问题了之后我们猜测,那么B+树就是对B树这个地方的一个优化。每次磁盘I/O尽可能多的加载节点,那么如何才能更多呢?我们上面说过节点信息是包含了索引和Data数据,那么我们能不能只加载索引呢?这样就能解决我们的需求,但是Data怎么存放呢?
在回头看下,我们要干什么?
1、磁盘I/O的时候尽可能多加载节点(索引)
2、我们要根据索引速度找打我们的data
目的知道了,首先我们确定了节点中只保留索引key,data我们要找个地方。不仅支持排序,加快查找速度,还要解决hash索引不具备的范为查找。那么我们能不能把data放在叶子节点里面,然后用指针串起来。上层索引用指针找到叶子节点拿数据。这是我们根据需求想到的方法,那来看下B+树的结构,是不是跟我们思考的一致?
- 非叶子节点指针:P[1]指向关键字小于K[1]的子树;P[M]指向关键字大于K[M-1]的子树,其他P[i]指向关键字属于(K[i-k],k[i])的子树
B+树:(B树的变种)
1. 非叶子节点不存储data,只存储索引,可以放更多的索引
2. 叶子节点不存储指针
3. 顺序访问指针,提高区间访问的性能
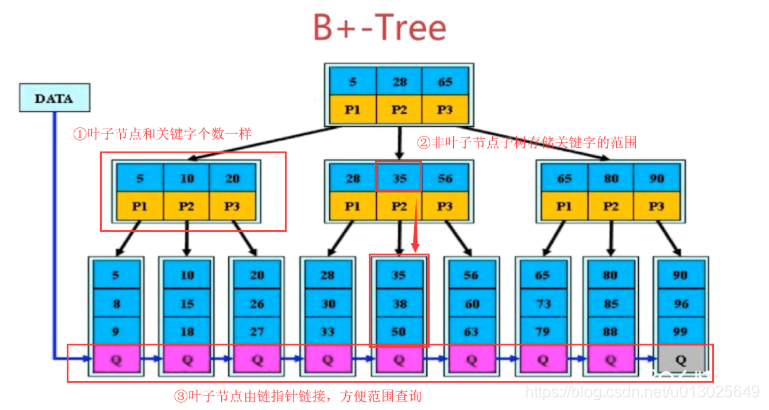
根据结构来对比下,B+Tree对比BTree的优点:
1、磁盘读写代价更低
一般来说B+Tree比BTree更适合实现外存的索引结构,因为存储引擎的设计专家巧妙的利用了外存(磁盘)的存储结构,即磁盘的最小存储单位是扇区(sector),而操作系统的块(block)通常是整数倍的sector,操作系统以页(page)为单位管理内存,一页(page)通常默认为4K,数据库的页通常设置为操作系统页的整数倍。
我们看下mysql默认设置的索引节点的大小:(Innodb数据页大小)
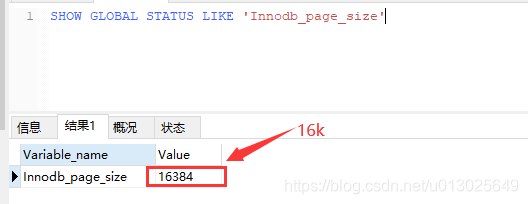

mysql默认的索引节点大小16k,因为mysql默认引擎innodb,所以这里展示的是innodb默认的索引节点的大小。举个例子存一个bigint字段,字段占8字节(8b),加个指针(6b),那么一个索引节点可以存储16k/(14b)~=1170个元素节点。树的高度为3,以为着可能存储1170个元素节点,再加入我们的叶子节点+索引大小为1k。那么可以存储1170117016个元素节点,相当与2000万数据。支撑千万级存储
那么可以知道,每个节点中的key个数越多,那么树的高度越小,需要I/O的次数越少,因此一般来说B+Tree比BTree更快,因为B+Tree的非叶节点中不存储data,就可以存储更多的key。
mysql设置16k的大小,data元素。设置16k大小?希望这个树可以存储更多的元素。
2、查询速度更稳定
由于B+Tree非叶子节点不存储数据(data),因此所有的数据都要查询至叶子节点,而叶子节点的高度都是相同的,因此所有数据的查询速度都是一样的。
相信经过上面的介绍应该知道原理了,那么我们在回头看看之前的4个问题。
- 为什么要给表加上主键?
- 为什么加索引后会使查询变快?
- 为什么加索引后会使写入、修改、删除变慢?
- 什么情况下要同时在两个字段上建索引?
是不是隐隐约约知道了一点原理?心里有点想法的话,应该是这样的
1、这里主键可能就是索引
2、加了索引对数据进行了排序,肯定要比没排序的要快
3、加索引新增数据的时候,怎么保持树的平衡结构,左节点<根节点<右节点。既然要保持这种结构数据增删改肯定需要花费代价去维护索引的关系
4、可能还没想法,没事我们看下一章














 129
129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









