







前言:
好久没更新博客了,添加一篇旧文。该文内容实际有点过时了,DGL最近把data pipeline重构了一下(https://github.com/dmlc/dgl/pull/3665),应该比文中内容更丰富一些了。
导言:
最近工作需要调研一下DGL社区的一些动态,发现了这篇针对GNN训练的论文: Large Graph Convolutional Network Training with GPU-Oriented Data Communication Architecture,这里对此做一下简单的笔记。
Motivation:
GNN的主要场景是依据Node的邻居信息来计算得到Node的Embedding。目前GNN模型中常见的mini-batch训练方式主要可以分为两部分:a)当前batch的子图准备,主要包括采样得到子图的结构以及对应子图的特征获取。b)根据得到的子图完成GNN模型的计算。
通常来讲,完整的Graph(全图)和初始feature(所有结点的特征)是放在主存中的【主要是因为通常显存无法放下全图和对应的所有feature】,由CPU来完成子图采样和对应的特征准备工作,然后将子图和特征传输至GPU中完成GNN模型的计算。在这个过程中,CPU需要收集每个batch所需的sparse feature,会给主机的内存带宽和CPU带来很大的压力。
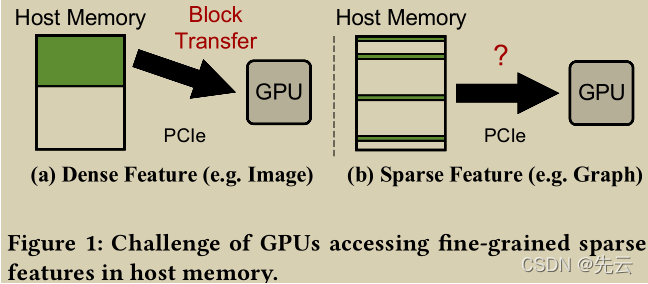
本文通过zero-copy技术,使用GPU的线程直接获取host memory中的稀疏特征,从而减轻CPU的负担,并且减少了CPU的feather gather阶段。可以加速GNN训练,减少host资源的消耗。为了提高数据传输的效率,还提出了1)自动的地址对齐来最大化PCIe的packet efficiency。2)异步的零拷贝访问和内核执行来overlap数据传输和训练(pipeline)。
感觉论文思路还是蛮容易理解的,估计难度主要是在工程上。
主要内容:
-
地址对齐
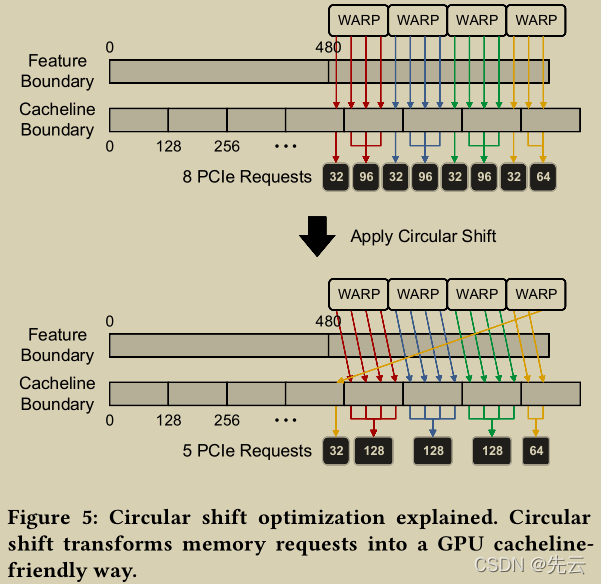
-
利用GPU thread来帮助传输feature,CPU不需要再进行feature gather工作,只需将需要的node idx传入gpu即可。这里作者经过实验,在其环境下需要10%左右的GPU资源用于数据传输,剩下的90%用于train。这里需要解决资源分配和同步问题,资源分配用的是MPS(CUDA multiprocessing service),看文中应该是没有那么好用的样子。同步问题主要是避免data transfer阻塞了train(这部分是不是已经有prefetch的意思了?即GPU部分thread来负责数据搬运,同时还不阻塞train的那部分)。这部分论文3.2节有介绍。然后还有pingpong buffer等。没有很理解。估计要结合实现来看一看(ping pong buffer应该是让一个buffer处理的同时准备另一个buffer)。
-
总流程
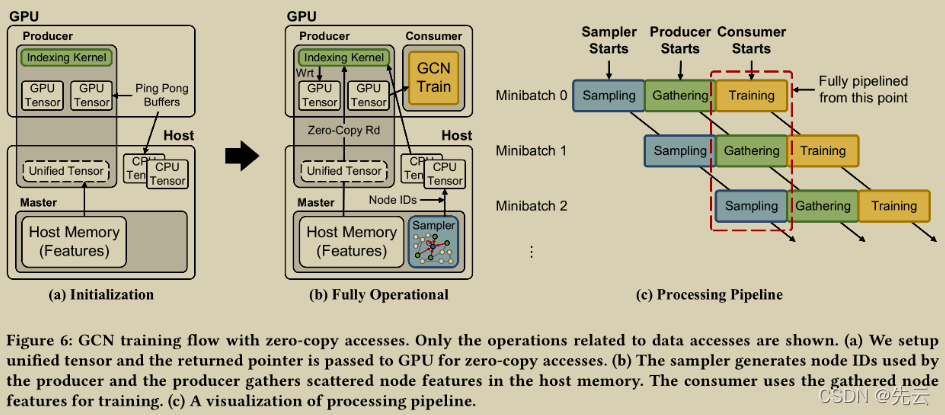
-
多卡训练
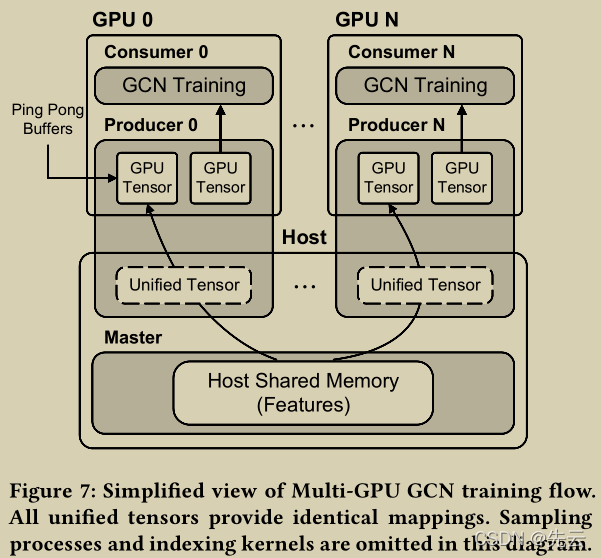
实现
-
官方repo:https://github.com/K-Wu/pytorch-direct_dgl
-
另外好像已经(部分)合入了DGL-UnifiedTensor,是不是把非修改Pytorch的部分合入了?有时间跑跑这个commit之后的example,看看效果。
在公司怎么都编译不成功,最后在家里来弄了。
家里环境是CPU是AMD3700X,B450的板子,3200频率的内存条16G*2,显卡是2060Super。
编译了dgl的这个版本:git clone --recurse-submodules https://github.com/davidmin7/dgl.git
跑了examples/pytorch/graphsage/train_sampling_unified_tensor.py 和train_sampling.py进行对比。结果如下:
- 特征在CPU上,原始方式。显存使用大概4G(nvidia-smi)。
(work) maqy@ubuntu:~/work/gnn/dglUnifiedTensor/davidfork/dgl/examples/pytorch/graphsage$ python train_sampling.py --num-epochs 10 --data-cpu
Epoch 00000 | Step 00000 | Loss 6.1428 | Train Acc 0.0300 | Speed (samples/sec) nan | GPU 265.5 MB
...
Eval Acc 0.9465
Test Acc: 0.9468
...
Epoch 00009 | Step 00140 | Loss 0.3134 | Train Acc 0.9180 | Speed (samples/sec) 15294.2769 | GPU 514.7 MB
Epoch Time(s): 10.4865
Avg epoch time: 10.435481643676757
- 特征在CPU上,zero-copy(论文)方式,感觉这里显存打印应该是不准的,实际需要显存2.7G左右(nvidia-smi命令),为啥会比上一种需要的显存还好呢?是因为手动分配了部分没检测到的显存使用?TODO:需要注意一下。
(work) maqy@ubuntu:~/work/gnn/dglUnifiedTensor/davidfork/dgl/examples/pytorch/graphsage$ python train_sampling_unified_tensor.py --num-epochs 10 --data-cpu
Epoch 00000 | Step 00000 | Loss 6.0242 | Train Acc 0.0280 | Speed (samples/sec) nan | GPU 11.1 MB
Eval Acc 0.9467
Test Acc: 0.9458
...
Epoch 00005 | Step 00140 | Loss 0.3690 | Train Acc 0.9130 | Speed (samples/sec) 29736.9992 | GPU 11.6 MB
Epoch Time(s): 5.5860
Avg epoch time: 5.597336053848267
- 特征在GPU中,理论速度最快的方式。显存使用4.3G。
(work) maqy@ubuntu:~/work/gnn/dglUnifiedTensor/davidfork/dgl/examples/pytorch/graphsage$ python train_sampling.py --num-epochs 10
Epoch 00000 | Step 00000 | Loss 5.9498 | Train Acc 0.0160 | Speed (samples/sec) nan | GPU 829.8 MB
Eval Acc 0.9452
Test Acc: 0.9470
...
Epoch 00009 | Step 00140 | Loss 0.3385 | Train Acc 0.9270 | Speed (samples/sec) 70266.2194 | GPU 1080.4 MB
Epoch Time(s): 2.6766
Avg epoch time: 2.6224377155303955
dgl master(2022.02.16)分支
新分支中重写了example,将UnifiedTensor也可以用于Graph了,因此在服务器上编译了一下想测试性能。目前DGL的采样模式是多种的,具体见下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2TqYptJf-1650020589965)(5DB5CB9422924AA1AC759DE6BB7544E8)]
后续对这块可能会进行简化成:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0sKc8pvI-1650020589966)(23EE0B74652845A1BFE36C28413F11CA)]
测试平台:
- Intel® Xeon Gold CPU 2.10GHz 16核心 x 2
- Nvidia Tesla T4 x 6 | pcie3.0 x 8
- 内存376G DDR4 2400 MT/s
测试代码:
- 单卡graphsage reddit(only train, not used inference, 因为现在master分支代码有点问题)
| graph device | feature device | sampling | subgraph construction | Host <=> device | epoch Time | GPU memory(print/nvidia-smi) |
|---|---|---|---|---|---|---|
| gpu | gpu | gpu | gpu | NO | 3.5s | 1079MB/5080MB |
| uva | gpu | gpu | gpu | graph zero-copy host->device | 3.9s | 1079MB/3090MB |
| cpu | gpu | cpu | cpu | graph host->device | 4.3s | 1079MB/3570MB |
| uva | uva | gpu | gpu | graph&feature zero-copy host->device | 11s | 12.8MB/2050MB |
| cpu | uva | cpu | cpu | graph/feature zc host->device | 11.4s | 12.5MB/1807MB |
| cpu | cpu | cpu | cpu | graph/feature host->device | 14.1 | 515MB/2550MB |
- 单机6卡
| graph device | feature device | sampling | subgraph construction | Host <=> device | epoch Time | GPU memory(print/nvidia-smi) |
|---|---|---|---|---|---|---|
| uva | uva | gpu | gpu | graph&feature zero-copy host->device | 2.54s | 13.8MB/1860MB |
- 单机 Unsupervised train TODO(很可能不会再测试了)

















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









