









看这篇文章之前需要知道一个概念
虚拟内存系统通过将虚拟内存分割为称作虚拟页(Virtual Page,VP)大小固定的块,一般情况下,每个虚拟页的大小默认是4096字节。同样的,物理内存也被分割为物理页(Physical Page,PP),也为4096字节。
一、mmap基本原理和分类
在LINUX中我们可以使用mmap用来在进程虚拟内存地址空间中分配地址空间,创建和物理内存的映射关系。
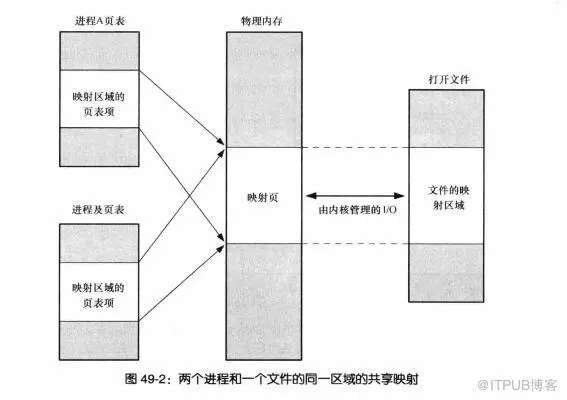
映射关系
映射关系可以分为两种
1、文件映射
磁盘文件映射进程的虚拟地址空间,使用文件内容初始化物理内存。
2、匿名映射
初始化全为0的内存空间。
而对于映射关系是否共享又分为
1、私有映射(MAP_PRIVATE)
多进程间数据共享,修改不反应到磁盘实际文件,是一个copy-on-write(写时复制)的映射方式。
2、共享映射(MAP_SHARED)
多进程间数据共享,修改反应到磁盘实际文件中。
因此总结起来有4种组合
1、私有文件映射
多个进程使用同样的物理内存页进行初始化,但是各个进程对内存文件的修改不会共享,也不会反应到物理文件中
2、私有匿名映射
mmap会创建一个新的映射,各个进程不共享,这种使用主要用于分配内存(malloc分配大内存会调用mmap)。
例如开辟新进程时,会为每个进程分配虚拟的地址空间,这些虚拟地址映射的物理内存空间各个进程间读的时候共享,写的时候会copy-on-write。
3、共享文件映射
多个进程通过虚拟内存技术共享同样的物理内存空间,对内存文件 的修改会反应到实际物理文件中,他也是进程间通信(IPC)的一种机制。
4、共享匿名映射
这种机制在进行fork的时候不会采用写时复制,父子进程完全共享同样的物理内存页,这也就实现了父子进程通信(IPC).
这里值得注意的是,mmap只是在虚拟内存分配了地址空间,只有在第一次访问虚拟内存的时候才分配物理内存。
在mmap之后,并没有在将文件内容加载到物理页上,只上在虚拟内存中分配了地址空间。当进程在访问这段地址时,通过查找页表,发现虚拟内存对应的页没有在物理内存中缓存,则产生"缺页",由内核的缺页异常处理程序处理,将文件对应内容,以页为单位(4096)加载到物理内存,注意是只加载缺页,但也会受操作系统一些调度策略影响,加载的比所需的多。
二.mmap在write和read时会发生什么
1.write
- 1.进程(用户态)将需要写入的数据直接copy到对应的mmap地址(内存copy)
- 2.若mmap地址未对应物理内存,则产生缺页异常,由内核处理
- 3.若已对应,则直接copy到对应的物理内存
- 4.由操作系统调用,将脏页回写到磁盘(通常是异步的)
因为物理内存是有限的,mmap在写入数据超过物理内存时,操作系统会进行页置换,根据淘汰算法,将需要淘汰的页置换成所需的新页,所以mmap对应的内存是可以被淘汰的(若内存页是"脏"的,则操作系统会先将数据回写磁盘再淘汰)。这样,就算mmap的数据远大于物理内存,操作系统也能很好地处理,不会产生功能上的问题。
2.read
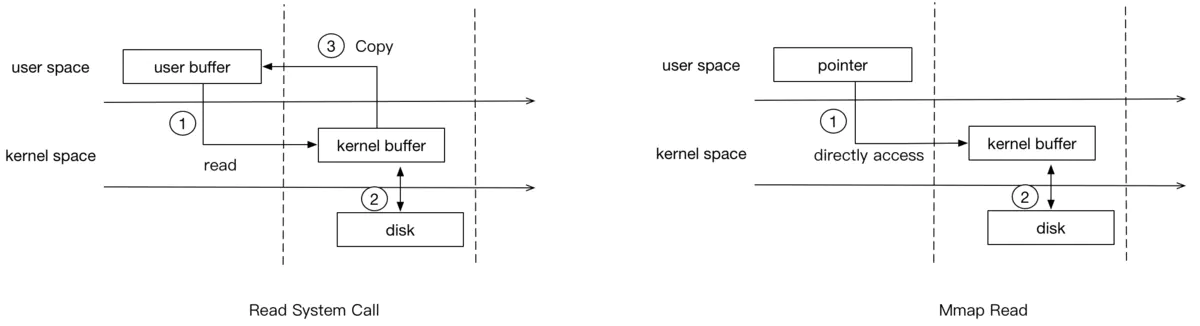
读的过程对比
从图中可以看出,mmap要比普通的read系统调用少了一次copy的过程。因为read调用,进程是无法直接访问kernel space的,所以在read系统调用返回前,内核需要将数据从内核复制到进程指定的buffer。但mmap之后,进程可以直接访问mmap的数据(page cache)。
三.性能分析
测试结果来源于:深入剖析mmap-从三个关键问题说起
1.读性能分析
场景:对2G的文件进行顺序写入
| 每次写入大小 | mmap 耗时 | write 耗时 |
|---|---|---|
| 100 bytes | 2.84s | 22.86s |
| 512 bytes | 2.51s | 5.43s |
| 1024 bytes | 2.48s | 3.48s |
| 2048 bytes | 2.47s | 2.34s |
| 4096 bytes | 2.48s | 1.74s |
| 8192 bytes | 2.45s | 1.67s |
| 10240 bytes | 2.49s | 1.65s |
可以看到mmap在100byte写入时已经基本达到最大写入性能,而write调用需要在4096(也就是一个page size)时,才能达到最大写入性能。
从测试结果可以看出,在写小数据时,mmap会比write调用快,但在写大数据时,反而没那么快。
2.写性能分析
场景:对2G的文件进行顺序读取(为了避免磁盘对测试的影响,2G文件都缓存在pagecache中)
| 每次读取大小 | mmap 耗时 | read 耗时 |
|---|---|---|
| 100 bytes | 86.4ms | 8100.9ms |
| 512 bytes | 16.14ms | 1851.45ms |
| 1024 bytes | 8.11ms | 992.71ms |
| 2048 bytes | 4.09ms | 636.85ms |
| 4096 bytes | 2.07ms | 558.10ms |
| 8192 bytes | 1.06ms | 444.83ms |
| 10240 bytes | 867.88µs | 475.28ms |
由上可以看出,在read上面,mmap的性能还是非常好的。
四.总结
优点如下:
1、对文件的读取操作跨过了页缓存,减少了数据的拷贝次数,用内存读写取代I/O读写,提高了文件读取效率。
2、实现了用户空间和内核空间的高效交互方式。两空间的各自修改操作可以直接反映在映射的区域内,从而被对方空间及时捕捉。
3、提供进程间共享内存及相互通信的方式。不管是父子进程还是无亲缘关系的进程,都可以将自身用户空间映射到同一个文件或匿名映射到同一片区域。从而通过各自对映射区域的改动,达到进程间通信和进程间共享的目的。同时,如果进程A和进程B都映射了区域C,当A第一次读取C时通过缺页从磁盘复制文件页到内存中;但当B再读C的相同页面时,虽然也会产生缺页异常,但是不再需要从磁盘中复制文件过来,而可直接使用已经保存在内存中的文件数据。
4、可用于实现高效的大规模数据传输。内存空间不足,是制约大数据操作的一个方面,解决方案往往是借助硬盘空间协助操作,补充内存的不足。但是进一步会造成大量的文件I/O操作,极大影响效率。这个问题可以通过mmap映射很好的解决。换句话说,但凡是需要用磁盘空间代替内存的时候,mmap都可以发挥其功效。
缺点如下:
1.文件如果很小,是小于4096字节的,比如10字节,由于内存的最小粒度是页,而进程虚拟地址空间和内存的映射也是以页为单位。虽然被映射的文件只有10字节,但是对应到进程虚拟地址区域的大小需要满足整页大小,因此mmap函数执行后,实际映射到虚拟内存区域的是4096个字节,11~4096的字节部分用零填充。因此如果连续mmap小文件,会浪费内存空间。
- 对变长文件不适合,文件无法完成拓展,因为mmap到内存的时候,你所能够操作的范围就确定了。
3.如果更新文件的操作很多,会触发大量的脏页回写及由此引发的随机IO上。所以在随机写很多的情况下,mmap方式在效率上不一定会比带缓冲区的一般写快















 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









