







1、为什么要使用激活函数
激活函数是为了进行特征选择和学到非线性特征。没有激活函数,网络层之间的传递只是简单的线性变换。gelu激活函数为了提高模型泛化能力,加入随机正则,是 dropout、zoneout、Relus的综合。
https://blog.csdn.net/dss_dssssd/article/details/83927312
2、常见激活函数的表达式及优缺点
-
Sigmoid
- Tanh
- ReLU
- Leaky ReLU
- gelu
2.1、sigmoid函数
2.1.1、sigmoid函数表示

函数表示:
Sigmoid(x)=σ(x)=1/(1+exp(−x))
梯度表示:
dσ(x)/dx=σ(x)(1-σ(x))
2.1.2、sigmoid函数优缺点
优点:
-
是便于求导的平滑函数;
-
能压缩数据,经sigmoid后,数据范围为[0,1];保证数据幅度不会趋于+ ∞ 或 − ∞
缺点:
-
容易出现梯度消失(gradient vanishing)的现象:当激活函数接近饱和区时,变化太缓慢,导数接近0,根据后向传递的数学依据是微积分求导的链式法则,当前导数需要之前各层导数的乘积,几个比较小的数相乘,导数结果很接近0,从而无法完成深层网络的训练。
-
Sigmoid的输出均值不是0(zero-centered)的:这会导致后层的神经元的输入是非0均值的信号,这会对梯度产生影响。以 f=sigmoid(wx+b)为例, 假设输入均为正数(或负数),那么对w的导数总是正数(或负数),这样在反向传播过程中要么都往正方向更新,要么都往负方向更新,使得收敛缓慢。
-
指数运算相对耗时
2.2、Tanh
2.2.1、tanh函数表示
tanh实质上就是sigmoid函数的一个变形:tanh(x)=2sigmoid(2x)-1

2.2.2、tanh函数优缺点
改善的一点就是tanh函数将输出值映射到了-1到1之间,因此它是0均值的了。
但是它也同样存在梯度消失和幂运算的问题
2.3、ReLu函数
2.3.1、ReLu函数表示
ReLU(x)=(x)+=max(0,x)
2.3.2、ReLu函数优缺点
优点:
(1)收敛速度比 sigmoid 和 tanh 快;(梯度不会饱和,解决了梯度消失问题)
(2)计算复杂度低,不需要进行指数运算
缺点:
(1)ReLu的输出不是zero-centered;
(2)Dead ReLU Problem(神经元坏死现象):某些神经元可能永远不会被激活,导致相应参数不会被更新(在负数部分,梯度为0)。产生这种现象的两个原因:参数初始化问题;learning rate太高导致在训练过程中参数更新太大。解决办法:采用Xavier初始化方法;以及避免将learning rate设置太大或使用adagrad等自动调节learning rate的算法。
(3)ReLu不会对数据做幅度压缩,所以数据的幅度会随着模型层数的增加不断扩张。
2.4、Leaky ReLU (PReLU)
2.4.1、Leaky ReLU函数表示
f(x)=max(0.01x,x)

2.4.2、PRelu函数优缺点
此激活函数的提出是用来解决ReLU带来的神经元坏死的问题,可以将0.01设置成一个变量a,其中a可以由后向传播学习。但是其表现并不一定比ReLU好
以上上述四种激活函数基本是常用的激活函数,现在最常用的激活函数是Relu
具有收敛速度快的优点,但必须要设置较低的学习率和好的参数初始化
2.5、ELU (Exponential Linear Units) 函数
2.5.1、ELU函数表示
ELUs是对ReLU激活函数的一种演变,将激活函数更能够保持一个noise-robust状态。所以提出一个具有负值的激活函数,这可以使得平均激活接近于零,但它会以更小的参数饱和为负值的激活函数ELUs。ELUs激活函数的公式The exponential linear unit (ELU) with 0 <α如下展示

2.5.2、ELU函数优缺点
优点
不会有Dead ReLU问题 输出的均值接近0,zero-centered
缺点
它的一个小问题在于计算量稍大。类似于Leaky ReLU,理论上虽然好于ReLU,但在实际使用中目前并没有好的证据ELU总是优于ReLU。
2.6、gelu
2.6.1、gelu函数表达
最近在看bert源码,发现里边的激活函数不是Relu等常见的函数,是一个新的激活函数GELUs, 这里记录分析一下该激活函数的特点。
在激活函数领域,大家公式的鄙视链应该是:Elus > Relu > Sigmoid ,这些激活函数都有自身的缺陷, sigmoid容易饱和,Elus与Relu缺乏随机因素。
在神经网络的建模过程中,模型很重要的性质就是非线性,同时为了模型泛化能力,需要加入随机正则,例如dropout(随机置一些输出为0,其实也是一种变相的随机非线性激活), 而随机正则与非线性激活是分开的两个事情, 而其实模型的输入是由非线性激活与随机正则两者共同决定的。
GELUs正是在激活中引入了随机正则的思想,是一种对神经元输入的概率描述,直观上更符合自然的认识,同时实验效果要比Relus与ELUs都要好。
GELUs其实是 dropout、zoneout、Relus的综合,GELUs对于输入乘以一个0,1组成的mask,而该mask的生成则是依概率随机的依赖于输入。假设输入为X, mask为m,则m服从一个伯努利分布Φ(x)=P(X<=x),X服从标准正太分布),这么选择是因为神经元的输入趋向于正太分布,这么设定使得当输入x减小的时候,输入会有一个更高的概率被dropout掉,这样的激活变换就会随机依赖于输入了。
数学表达如下:
GELU(x)= xP(X<=x) = xΦ(x)
这里Φ(x)是正太分布的概率函数,可以简单采用正太分布N(0,1), 可以使用参数化的正太分布N(μ,σ), 然后通过训练得到μ,σ。在源码中给出了近似正态分布的数据计算公式如下所示:
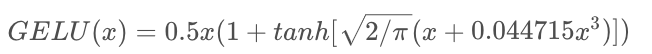
tensorflow 版bert中gelu的源代码
def gelu(input_tensor):
cdf = 0.5 * (1.0 + tf.erf(input_tensor / tf.sqrt(2.0)))
return input_tesnsor*cdf3、如何选择合适的激活函数
1)深度学习往往需要大量时间来处理大量数据,模型的收敛速度是尤为重要的。所以,总体上来讲,训练深度学习网络尽量使用zero-centered数据 (可以经过数据预处理实现) 和zero-centered输出。所以要尽量选择输出具有zero-centered特点的激活函数以加快模型的收敛速度。
2)如果使用 ReLU,那么一定要小心设置 learning rate,而且要注意不要让网络出现很多 “dead” 神经元,如果这个问题不好解决,那么可以试试 Leaky ReLU、PReLU .
3)最好不要用 sigmoid,你可以试试 tanh,不过可以预期它的效果会比不上 ReLU .
4)Tanh 和 sigmoid 函数会引起巨大的梯度消失问题,因此一般不推荐使用。
5)神经网络中一开始尝试引入 ReLU 函数。如上文所述,在权重层(诸如 CNN、RNN、LSTM 或线性感知层)之后添加激活层。如果你认为模型已经停止学习,那么可以用 Leaky ReLU 替换它,以避免「Dying ReLU」问题。但 Leaky ReLU 会稍微增加计算时间。
6)如果你的网络中也有 Batch-Norm 层(批规范层),则需要在激活函数之前添加,即顺序是先是 CNN-Batch(卷积神经网络批处理),再是 Norm-Act(规范化)。虽然 Batch-Norm(批处理规范化)和激活函数的顺序是一个备受争议的话题,也有人说顺序其实无关紧要,为了与最初的 Batch-Norm 论文保持一致,作者使用的是以上提到的这种顺序。
7)激活函数的默认超参数如果是在著名的框架(如 Tensorflow 和 Pytorch)中所使用的,则效果最好。然而,你可以调整 Leaky ReLU 中的负斜率并将其设置为 0.02 以加快学习。
参考文章
https://blog.csdn.net/dss_dssssd/article/details/83927312(激活函数)
https://zhuanlan.zhihu.com/p/88429934 (pytorch激活函数介绍)
https://blog.csdn.net/tyhj_sf/article/details/79932893 (激活函数的比较,这篇展开了在讨论)
https://www.leiphone.com/news/202001/JqKtvu3P8WQyC1So.html (对于激活函数使用介绍较为详细)
https://blog.csdn.net/tyhj_sf/article/details/79932893(介绍较为详细的激活函数)
https://blog.csdn.net/liruihongbob/article/details/86510622(gelu激活函数介绍)















 1978
1978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









