







#博学谷IT学习技术支持#
第一章 RDD详解
1.1 为什么需要RDD?
没有RDD之前:
1.MR:只提供了map和reduce的API,而且编写麻烦,运行效率低!
2.使用Python/Scala/Java的本地集合:但是只能完成本地单机版的,如果要实现分布式的,---很困难!
所以需要有一个分布式的数据抽象,也就是用该抽象,可以表示分布式的集合,
那么基于这个分布式集合进行操作,就可以很方便的完成分布式的WordCount!
(该分布式集合底层应该将实现的细节封装好,提供简单易用的API!)
在此背景之下,RDD就诞生了!
MR中的迭代:
MR的这种方式对数据领域两种常见的操作不是很高效。第一种是迭代式的算法。比如机器学习中ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据反复查询反复操作。MR这种模式不太合适,即使多MR串行处理,性能和时间也是一个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR显然不擅长。

Spark中的迭代:
我们需要一个效率非常快,且能够支持迭代计算和有效数据共享的模型,Spark应运而生。RDD是基于工作集的工作模式,更多的是面向工作流。
但是无论是MR还是RDD都应该具有类似位置感知、容错和负载均衡等特性

总结
RDD提供了一个抽象的数据模型,让我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换操作(函数),不同RDD之间的转换操作之间还可以形成依赖关系,进而实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销,并且还提供了更多的API(map/reduec/filter/groupBy...)
RDD将Spark的底层的细节都隐藏起来了(自动容错、位置感知、任务调度执行,失败重试…)
让开发者可以像操作本地集合一样以函数式编程的方式操作RDD这个分布式数据集进行各种并行计算
1.2 什么是RDD?
在Spark开山之作Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing这篇paper中(以下简称 RDD Paper),Matei等人提出了RDD这种数据结构,文中开头对RDD的定义是:

RDD设计的核心点为
RDD提供了一个抽象的数据模型,不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换操作(函数),不同RDD之间的转换操作之间还可以形成依赖关系,进而实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销,并且还提供了更多的API(map/reduec/filter/groupBy...)。

1.3 RDD 定义
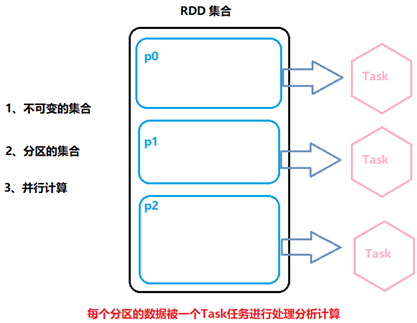
RDD(Resilient Distributed Dataset)弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
所有的运算以及操作都建立在 RDD 数据结构的基础之上。
可以认为RDD是分布式的列表List或数组Array,抽象的数据结构,RDD是一个抽象类Abstract Class和泛型Generic Type:

1.4 RDD的5大特性
RDD 数据结构内部有五个特性(摘录RDD 源码):
前三个特征每个RDD都具备的,后两个特征可选的。

1.5 RDD特点
特点1:分区-RDD逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个compute函数得到每个分区的数据。
特点2:只读-RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD。
特点3:依赖-RDDs之间维护着这种血缘关系,也称之为依赖
特点4:缓存-如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据
特点5:checkpoint-随着迭代的进行,RDDs之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。为此,RDD支持checkpoint将数据保存到持久化的存储中,这样就可以切断之前的血缘关系



1.6 WordCount中RDD
在内部,每个RDD都有五个主要特性:
1.-分区列表:每个RDD都有会分区的概念,类似于HDFS的分块, 分区的目的:提高并行度!
2.-用于计算每个分区的函数:用函数来操作各个分区中的数据
3.-对其他RDD的依赖列表:后面的RDD需要依赖前面的RDD
4.-可选地,键值RDDs的分区器(例如,reduceByKey中的默认的Hash分区器)
5.-可选地,计算每个分区的首选位置列表/最佳位置(例如HDFS文件)--移动计算比移动数据更划算!
第二章 RDD的创建
2.1 PySpark中RDD的创建两种方式
官方文档:
http://spark.apache.org/docs/latest/rdd-programming-guide.html#resilient-distributed-datasets-rdds
如何将数据封装到RDD集合中,主要有两种方式:
并行化本地集合(Driver Program中)和引用加载外部存储系统(如HDFS、Hive、HBase、Kafka、Elasticsearch等)数据集。

(1)第一步 创建sparkContext
SparkContext, Spark程序的入口. SparkContext代表了和Spark集群的链接, 在Spark集群中通过SparkContext来创建RDD
SparkConf 创建SparkContext的时候需要一个SparkConf, 用来传递Spark应用的基本信息。
conf = SparkConf().setAppName(appName).setMaster(master)
sc = SparkContext(conf=conf)在pyspark shell中 已经为我们创建好了 SparkContext 通过sc直接使用
可以在spark UI中看到当前的Spark作业 在浏览器访问当前centos的4040端口 192.168.88.161:4040

2.2 并行化方式创建RDD
首先Spark官网针对创建方式的说明:

调用`SparkContext`的 `parallelize` 方法并且传入已有的可迭代对象或者集合:
>>> data = [1, 2, 3, 4, 5]
>>> distData = sc.parallelize(data)
>>> data [1, 2, 3, 4, 5]也可以在spark ui中观察执行情况
在通过parallelize方法创建RDD 的时候可以指定分区数量
>>> distData = sc.parallelize(data,5)
>>> distData.reduce(lambda a, b: a + b)
15
from pyspark import SparkContext, SparkConf
import os
os.environ['SPARK_HOME'] = '/export/servers/spark'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
print('PySpark First Program')
# 输入数据
data = ["hello", "world", "hello", "world"]
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
# sc = SparkContext.getOrCreate(conf)
sc = SparkContext(conf=conf)
# 将collection的data转为spark中的rdd并进行操作
rdd = sc.parallelize(data)
# 执行map转化操作以及reduceByKey的聚合操作
res_rdd = rdd.map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
# 将rdd转为collection并打印
res_rdd_coll = res_rdd.collect()
for line in res_rdd_coll:
print(line)
print('停止 PySpark SparkSession 对象')
sc.stop()
2.3 小文件读取
在实际项目中,有时往往处理的数据文件属于小文件(每个文件数据数据量很小,比如KB,几十MB等),文件数量又很大,如果一个个文件读取为RDD的一个个分区,计算数据时很耗时性能低下,使用SparkContext中提供:wholeTextFiles类,专门读取小文件数据。
范例演示:读取100个小文件rating数据,每个文件大小小于1MB,查看默认情况下分区个数情况
# -*- coding: utf-8 -*-
from pyspark import SparkContext, SparkConf
import os
os.environ['SPARK_HOME'] = '/export/servers/spark'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
print('PySpark WholeTextFile Program')
# TODO:1、创建应用程序入口SparkContext实例对象
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
# TODO: 2、从文件系统加载数据,调用textFile
resultRDD1 = sc.textFile("file:///export/pyfolder1/pyspark-chapter02_3.8/data/ratings100/")
# TODO: 3、调用集合RDD中函数处理分析数据,调用wholeTextFiles
resultRDD2 = sc.wholeTextFiles("file:///export/pyfolder1/pyspark-chapter02_3.8/data/ratings100/")
# TODO: 4、获取分区数
print("textFile numpartitions:", resultRDD1.getNumPartitions())
print("whole textFile numpartitions:", resultRDD2.getNumPartitions())
# print(resultRDD2.take(2))
print('停止 PySpark SparkSession 对象')
# 关闭SparkContext
sc.stop()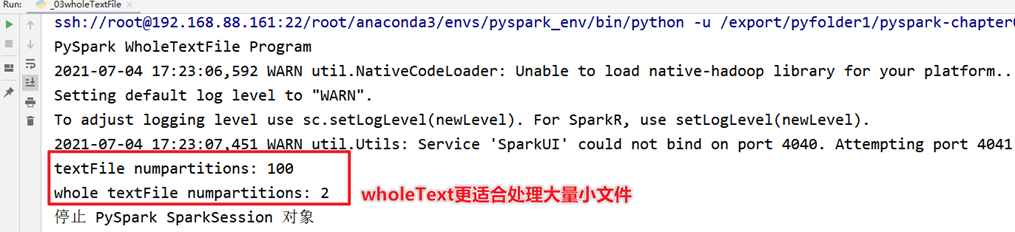
2.4 通过外部数据创建RDD
PySpark可以从Hadoop支持的任何存储源创建RDD,包括本地文件系统,HDFS,Cassandra,HBase,Amazon S3等。
支持整个目录、多文件、通配符
支持压缩文件
如下为Spark官网描述的支持文件信息:

>>> rdd1 = sc.textFile('file:///root/tmp/word.txt')
>>> rdd1.collect()
['foo foo quux labs foo bar quux abc bar see you by test welcome test', 'abc labs foo me python hadoop ab ac bc bec python']
from pyspark import SparkContext, SparkConf
import os
import re
os.environ['SPARK_HOME'] = '/export/servers/spark'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
print('PySpark RDD Program')
data = ["hello", "world", "hello", "world"]
# TODO:1、创建应用程序入口SparkContext实例对象
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
# TODO: 2、从文件系统加载数据,创建RDD数据集
# TODO: 3、调用集合RDD中函数处理分析数据
resultRDD2 = sc.textFile("file:///export/pyfolder1/pyspark-chapter02_3.8/data/word.txt") \
.flatMap(lambda line: re.split("\s+", line)) \
.map(lambda x: (x, 1)) \
.reduceByKey(lambda a, b: a + b)
# TODO: 4、保存结果RDD到外部存储系统(HDFS、MySQL、HBase。。。。)
res_rdd_coll = resultRDD2.collect()
for line in res_rdd_coll:
print(line)
print('停止 PySpark SparkSession 对象')
# 关闭SparkContext
sc.stop()2.5 扩展阅读:RDD分区数
在讲解 RDD 属性时,多次提到了分区(partition)的概念。分区是一个偏物理层的概念,也是 RDD 并行计算的单位。
l数据在 RDD 内部被切分为多个子集合,每个子集合可以被认为是一个分区,运算逻辑最小会被应用在每一个分区上,每个分区是由一个单独的任务(task)来运行的,所以分区数越多,整个应用的并行度也会越高。
l获取RDD分区数目方式,如下:
http://spark.apache.org/docs/latest/api/python/reference/api/pyspark.RDD.getNumPartitions.html#pyspark.RDD.getNumPartitions
bin/pyspark --master local[2]
>>> data = [1, 2, 3, 4, 5]
>>> distData = sc.parallelize(data)
>>> distData.getNumPartitions() #2RDD分区的数据取决于哪些因素?
第一点:RDD分区的原则是使得分区的个数尽量等于集群中的CPU核心(core)数目,这样可以充分利用CPU的计算资源;
第二点:在实际中为了更加充分的压榨CPU的计算资源,会把并行度设置为cpu核数的2~3倍;
第三点:RDD分区数和启动时指定的核数、调用方法时指定的分区数、如文件本身分区数有关系,具体如下说明:
1)、启动的时候指定的CPU核数确定了一个参数值:
spark.default.parallelism=指定的CPU核数(集群模式最小2)
思考:尝试spark.default.parallelism设置小一些,查看分区数
2)、对于Scala集合调用parallelize(集合,分区数)方法
如果没有指定分区数,就使用spark.default.parallelism
如果指定了就使用指定的分区数(建议不要指定大于spark.default.parallelism)
3)、对于textFile(文件, 分区数)
defaultMinPartitions
如果没有指定分区数sc.defaultMinPartitions=min(defaultParallelism,2)
如果指定了就使用指定的分区数sc.defaultMinPartitions=指定的分区数rdd的分区数
rdd的分区数
对于本地文件
rdd的分区数 = max(本地file的分片数, sc.defaultMinPartitions)
注意:这里即便自定义设置分区个数也不行,如sc.textFile(“”,3)
对于HDFS文件
rdd的分区数 = max(hdfs文件的block数目, sc.defaultMinPartitions)
所以如果分配的核数为多个,且从文件中读取数据创建RDD,即使hdfs文件只有1个切片,最后的Spark的RDD的partition数也有可能是2
第三章 RDD的操作
3.1 函数分类
对于 Spark 处理的大量数据而言,会将数据切分后放入RDD作为Spark 的基本数据结构,开发者可以在 RDD 上进行丰富的操作,之后 Spark 会根据操作调度集群资源进行计算。总结起来,RDD 的操作主要可以分为 Transformation 和 Action 两种。

官方文档:http://spark.apache.org/docs/latest/rdd-programming-guide.html#rdd-operations
RDD中操作(函数、算子)分为两类:
1)、Transformation转换操作:返回一个新的RDD
which create a new dataset from an existing one
所有Transformation函数都是Lazy,不会立即执行,需要Action函数触发
2)、Action动作操作:返回值不是RDD(无返回值或返回其他的)
which return a value to the driver program after running a computation on the datase
所有Action函数立即执行(Eager),比如count、first、collect、take等

此外注意RDD中函数细节:
第一点:RDD不实际存储真正要计算的数据,而是记录了数据的位置在哪里,数据的转换关系(调用了什么方法,传入什么函数);
第二点:RDD中的所有转换都是惰性求值/延迟执行的,也就是说并不会直接计算。只有当发生一个要求返回结果给Driver的Action动作时,这些转换才会真正运行。之所以使用惰性求值/延迟执行,是因为这样可以在Action时对RDD操作形成DAG有向无环图进行Stage的划分和并行优化,这种设计让Spark更加有效率地运行。
3.2 Transformation函数
在Spark中Transformation操作表示将一个RDD通过一系列操作变为另一个RDD的过程,这个操作可能是简单的加减操作,也可能是某个函数或某一系列函数。值得注意的是Transformation操作并不会触发真正的计算,只会建立RDD间的关系图。
如下图所示,RDD内部每个方框是一个分区。假设需要采样50%的数据,通过sample函数,从 V1、V2、U1、U2、U3、U4 采样出数据 V1、U1 和 U4,形成新的RDD。





3.3 Action函数
不同于Transformation操作,Action操作代表一次计算的结束,不再产生新的 RDD,将结果返回到Driver程序或者输出到外部。所以Transformation操作只是建立计算关系,而Action 操作才是实际的执行者。每个Action操作都会调用SparkContext的runJob 方法向集群正式提交请求,所以每个Action操作对应一个Job。
常用Action执行函数。



3.5 Transformer算子
值类型valueType
map: map(func):

将func函数作用到数据集的每一个元素上,生成一个新的RDD返回。
>>> rdd1 = sc.parallelize([1,2,3,4,5,6,7,8,9],3)
>>> rdd2 = rdd1.map(lambda x: x+1)
>>> rdd2.collect()
[2, 3, 4, 5, 6, 7, 8, 9, 10]
map: map(func):
自定义Python函数:
>>>rdd1 = sc.parallelize([1,2,3,4,5,6,7,8,9],3)
>>>def add(x):
... return x+1
>>>rdd2 = rdd1.map(add)
>>>rdd2.collect()
[2, 3, 4, 5, 6, 7, 8, 9, 10]
上述代码类似于:
>>> rdd1.map(lambda x:x+1).collect()

groupBy
>>> x = sc.parallelize([1,2,3])
>>> y = x.groupBy(lambda x: 'A' if (x%2 == 1) else 'B' )
>>> print(y.mapValues(list).collect())
[('A', [1, 3]), ('B', [2])]
Filter:
filter(func) 选出所有func返回值为true的元素,生成一个新的RDD返回
>>>rdd1 = sc.parallelize([1,2,3,4,5,6,7,8,9],3)
>>>rdd2 = rdd1.map(lambda x:x*2)
>>>rdd3 = rdd2.filter(lambda x:x>4)
>>>rdd3.collect()
[6, 8, 10, 12, 14, 16, 18]
Flatmap:
flatMap会先执行map的操作,再将所有对象合并为一个对象
>>>rdd1 = sc.parallelize(["a b c","d e f","h i j"])
>>>rdd2 = rdd1.flatMap(lambda x:x.split(" "))
>>>rdd2.collect()
['a', 'b', 'c', 'd', 'e', 'f', 'h', 'i', 'j']
flatMap和map的区别:
flatMap在map的基础上将结果合并到一个list中
>>> rdd1 = sc.parallelize(["a b c","d e f","h i j"])
>>> rdd2 = rdd1.map(lambda x:x.split(" "))
>>> rdd2.collect()
[['a', 'b', 'c'], ['d', 'e', 'f'], ['h', 'i', 'j']]双值类型DoubleValueType
Union:对两个RDD求并集
>>> rdd1 = sc.parallelize([("a",1),("b",2)])
>>> rdd2 = sc.parallelize([("c",1),("b",3)])
>>> rdd3 = rdd1.union(rdd2)
>>> rdd3.collect()
[('a', 1), ('b', 2), ('c', 1), ('b', 3)]
Intersection:对两个RDD求交集
>>> rdd1 = sc.parallelize([("a",1),("b",2)])
>>> rdd2 = sc.parallelize([("c",1),("b",3)])
>>> rdd3 = rdd1.union(rdd2)
>>> rdd4 = rdd3.intersection(rdd2)
>>> rdd4.collect()
[('c', 1), ('b', 3)]Key-Value值类型
groupByKey:
以元组中的第0个元素作为key,进行分组,返回一个新的RDD
>>>rdd1 = sc.parallelize([("a",1),("b",2)])
>>>rdd2 = sc.parallelize([("c",1),("b",3)])
>>>rdd3 = rdd1.union(rdd2)
>>>rdd4 = rdd3.groupByKey()
>>>rdd4.collect()
[('a', <pyspark.resultiterable.ResultIterable object at 0x7fba6a5e5898>), ('c', <pyspark.resultiterable.ResultIterable object at 0x7fba6a5e5518>), ('b', <pyspark.resultiterable.ResultIterable object at 0x7fba6a5e5f28>)]
groupByKey之后的结果中 value是一个Iterable
>>>result[2]
('b', <pyspark.resultiterable.ResultIterable object at 0x7fba6c18e518>)
>>>result[2][1]
<pyspark.resultiterable.ResultIterable object at 0x7fba6c18e518>
>>>list(result[2][1])
[2, 3]reduceByKey:将key相同的键值对,按照Function进行计算
>>>rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
>>>rdd.reduceByKey(lambda x,y:x+y).collect()
[('b', 1), ('a', 2)]sortByKey:根据key进行排序
`sortByKey`(ascending=True, numPartitions=None, keyfunc=<function RDD.<lambda>>)
>>>tmp = [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
>>>sc.parallelize(tmp).sortByKey().first()
('1', 3)
>>>sc.parallelize(tmp).sortByKey(True, 1).collect()
[('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)]
>>>sc.parallelize(tmp).sortByKey(True, 2).collect()
[('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)]
>>>tmp2 = [('Mary', 1), ('had', 2), ('a', 3), ('little', 4), ('lamb', 5)]
>>>tmp2.extend([('whose', 6), ('fleece', 7), ('was', 8), ('white', 9)])
>>>sc.parallelize(tmp2).sortByKey(True, 3, keyfunc=lambda k: k.lower()).collect()
[('a', 3), ('fleece', 7), ('had', 2), ('lamb', 5),...('white', 9), ('whose', 6)]
countByValue
>>> x = sc.parallelize([1,3,1,2,3])
>>> y = x.countByValue()
>>> print(x.collect())
[1, 3, 1, 2, 3]
>>> print(y)
defaultdict(<class 'int'>, {1: 2, 3: 2, 2: 1})
>>> 3.6 Action算子
collect
返回一个list,list中包含 RDD中的所有元素
只有当数据量较小的时候使用Collect 因为所有的结果都会加载到内存中
>>>rdd1 = sc.parallelize([1,2,3,4,5,6,7,8,9],3)
>>>rdd2 = rdd1.map(lambda x: x+1)
>>>rdd2.collect()
[2, 3, 4, 5, 6, 7, 8, 9, 10] reduce
reduce将RDD中元素两两传递给输入函数,同时产生一个新的值,新产生的值与RDD中下一个元素再被传递给输入函数直到最后只有一个值为止。
>>>rdd1 = sc.parallelize([1,2,3,4,5])
>>>rdd1.reduce(lambda x,y : x+y)
15 first
返回RDD的第一个元素
>>>sc.parallelize([2, 3, 4]).first()
2 reduce
reduce将RDD中元素两两传递给输入函数,同时产生一个新的值,新产生的值与RDD中下一个元素再被传递给输入函数直到最后只有一个值为止。
>>>rdd1 = sc.parallelize([1,2,3,4,5])
>>>rdd1.reduce(lambda x,y : x+y)
15first
返回RDD的第一个元素
>>>sc.parallelize([2, 3, 4]).first()
2 take
返回RDD的前N个元素,`take`(*num*)
>>>sc.parallelize([2, 3, 4, 5, 6]).take(2)
[2, 3]
>>>sc.parallelize([2, 3, 4, 5, 6]).take(10)
[2, 3, 4, 5, 6]
>>>sc.parallelize(range(100), 100).filter(lambda x: x > 90).take(3)
[91, 92, 93] Top:排序取前几个从大到小
>>> x = sc.parallelize([1,3,1,2,3])
>>> y = x.top(num = 3)
>>> print(x.collect())
[1, 3, 1, 2, 3]
>>> print(y)
[3, 3, 2]Count:返回RDD中元素的个数
>>>sc.parallelize([2, 3, 4]).count()
3takeSample
>>> rdd = sc.parallelize(range(0, 10))
>>> rdd.takeSample(True, 20, 1)
[0, 6, 3, 4, 3, 1, 3, 7, 3, 5, 3, 0, 0, 9, 6, 5, 7, 9, 4, 7]
>>> rdd.takeSample(True, 5, 1)
[8, 8, 0, 3, 6]
>>> rdd.takeSample(True, 5, 1)
[8, 8, 0, 3, 6]
>>> rdd.takeSample(False, 5, 2)
[5, 9, 3, 4, 6]
>>> rdd.takeSample(False, 5, 2)
[5, 9, 3, 4, 6]
foreach
仅返回满足foreach内函数条件元素。在下面的示例中,我们在foreach中调用print函数,它打印RDD中的所有元素。
>>> words = sc.parallelize (
... ["scala",
... "java",
... "hadoop",
... "spark",
... "akka",
... "spark vs hadoop",
... "pyspark",
... "pyspark and spark"]
... )
>>> def f(x): print(x)
>>> fore = words.foreach(f)
3.7 重要函数
RDD中包含很多函数,主要可以分为两类:Transformation转换函数和Action函数。


RDD中map、filter、flatMap及foreach等函数为最基本函数,都是都RDD中每个元素进行操作,将元素传递到函数中进行转换。
map 函数:
map(f:T=>U) : RDD[T]=>RDD[U],表示将 RDD 经由某一函数 f 后,转变为另一个RDD。
flatMap 函数:
flatMap(f:T=>Seq[U]) : RDD[T]=>RDD[U]),表示将 RDD 经由某一函数 f 后,转变为一个新的 RDD,但是与 map 不同,RDD 中的每一个元素会被映射成新的 0 到多个元素(f 函数返回的是一个序列 Seq)。
filter 函数:
filter(f:T=>Bool) : RDD[T]=>RDD[T],表示将 RDD 经由某一函数 f 后,只保留 f 返回为 true 的数据,组成新的 RDD。
foreach 函数:
foreach(func),将函数 func 应用在数据集的每一个元素上,通常用于更新一个累加器,或者和外部存储系统进行交互,例如 Redis。关于 foreach,在后续章节中还会使用,到时会详细介绍它的使用方法及注意事项。
saveAsTextFile 函数:
saveAsTextFile(path:String),数据集内部的元素会调用其 toString 方法,转换为字符串形式,然后根据传入的路径保存成文本文件,既可以是本地文件系统,也可以是HDFS 等。
分区操作函数
每个RDD由多分区组成的,实际开发建议对每个分区数据的进行操作,map函数使用mapPartitions代替、foreache函数使用foreachPartition代替。

foreachPartition代码实战:
>>>def f(iterator):
>>> for x in iterator:
>>> print(x)
>>>sc.parallelize([1, 2, 3, 4, 5]).foreachPartition(f)
MapPartition代码实战:
>>> rdd = sc.parallelize([1, 2, 3, 4], 2)
>>> def f(iterator): yield sum(iterator)
...
>>> rdd.mapPartitions(f).collect()
[3, 7]
为什么要对分区操作,而不是对每个数据操作,好处在哪里呢???
应用场景:处理网站日志数据,数据量为10GB,统计各个省份PV和UV。
假设10GB日志数据,从HDFS上读取的,此时RDD的分区数目:80 分区;
但是分析PV和UV有多少条数据:34,存储在80个分区中,实际项目中降低分区数目,比如设置为2个分区。

重分区函数
如何对RDD中分区数目进行调整(增加分区或减少分区),在RDD函数中主要有如下三个函数。1)、增加分区函数函数名称:repartition,此函数使用的谨慎,会产生Shuffle。

>>> rdd = sc.parallelize([1,2,3,4,5,6,7], 4)
>>> sorted(rdd.glom().collect())
[[1], [2, 3], [4, 5], [6, 7]]
>>> len(rdd.repartition(2).glom().collect())
2
>>> len(rdd.repartition(10).glom().collect())
10
>>> rdd.glom().collect()
[[1], [2, 3], [4, 5], [6, 7]]
2)、减少分区函数
函数名称:coalesce,此函数不会产生Shuffle,当且仅当降低RDD分区数目。
比如RDD的分区数目为10个分区,此时调用rdd.coalesce(12),不会对RDD进行任何操作。

>>> sc.parallelize([1, 2, 3, 4, 5], 3).glom().collect()
[[1], [2, 3], [4, 5]]
>>> sc.parallelize([1, 2, 3, 4, 5], 3).coalesce(1).glom().collect()
[[1, 2, 3, 4, 5]]
>>> sc.parallelize([1, 2, 3, 4, 5], 3).coalesce(4).glom().collect()
[[1], [2, 3], [4, 5]]
>>> sc.parallelize([1, 2, 3, 4, 5], 3).coalesce(4,True).glom().collect()
[[4, 5], [2, 3], [], [1]]
3)、调整分区函数
在PairRDDFunctions(此类专门针对RDD中数据类型为KeyValue对提供函数)工具类中partitionBy函数:

>>> pairs = sc.parallelize([1, 2, 3, 4, 2, 4, 1]).map(lambda x: (x, x))
>>> pairs.getNumPartitions()
>>> pairs.partitionBy(3).glom().collect()
[[(3, 3)], [(1, 1), (4, 4), (4, 4), (1, 1)], [(2, 2), (2, 2)]]
>>> len(pairs.partitionBy(3).glom().collect()) 
# -*- coding: utf-8 -*-
# Program function:从外部文件系统读取数据转换为RDD
from pyspark import SparkContext, SparkConf
import os
import re
os.environ['SPARK_HOME'] = '/export/servers/spark'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
print('PySpark RDD Program')
# TODO:1、创建应用程序入口SparkContext实例对象
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
# TODO: 2、从文件系统加载数据,创建RDD数据集
# TODO: 3、调用集合RDD中函数处理分析数据
fileRDD = sc.textFile("file:///export/pyfolder1/pyspark-chapter02_3.8/data/word.txt", 2)
# 对fileRDD进行重分区
fileRDD.repartition(3)
resultRDD2 = fileRDD \
.flatMap(lambda line: re.split("\s+", line)) \
.map(lambda x: (x, 1)) \
.reduceByKey(lambda a, b: a + b)
# TODO: 4、通过ForeachPartition展示结果
def f(iterator):
for x in iterator:
print(x)
resultRDD2.foreachPartition(f)
print('停止 PySpark SparkSession 对象')
# 关闭SparkContext
sc.stop()在实际开发中,什么时候适当调整RDD的分区数目呢?让程序性能更好好呢?
第一点:增加分区数目:n当处理的数据很多的时候,可以考虑增加RDD的分区数目

第二点:减少分区数目:
其一:当对RDD数据进行过滤操作(filter函数)后,考虑是否降低RDD分区数目

其二:当对结果RDD存储到外部系统

聚合函数
集合中聚合函数
在数据分析领域中,对数据聚合操作是最为关键的,在Spark框架中各个模块使用时,主要就是其中聚合函数的使用。
回顾Python列表中reduce聚合函数核心概念:聚合的时候,往往需要聚合中间临时变量。查看列表List中聚合函数reduce和fold源码如下:
reduce(function, iterable[, initializer])
·function -- 函数,有两个参数
·iterable -- 可迭代对象
·initializer -- 可选,初始参数
返回函数计算结果。
#!/usr/bin/python
from functools import reduce
def add(x, y) : # 两数相加
return x + y
sum1 = reduce(add, [1,2,3,4,5]) # 计算列表和:1+2+3+4+5
sum2 = reduce(lambda x, y: x+y, [1,2,3,4,5]) # 使用 lambda 匿名函数
print(sum1)
print(sum2)RDD 中聚合函数
在RDD中提供类似列表List中聚合函数reduce和fold,查看如下:

案例演示:求列表List中元素之和,RDD中分区数目为2,核心业务代码如下:
>>> from operator import add
>>> sc.parallelize([1, 2, 3, 4, 5]).reduce(add)
15
>>> sc.parallelize((2 for _ in range(10))).map(lambda x: 1).cache().reduce(add)
10
>>> sc.parallelize([]).reduce(add)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/export/servers/spark/python/pyspark/rdd.py", line 1000, in reduce
raise ValueError("Can not reduce() empty RDD")
ValueError: Can not reduce() empty RDD
>>> 
使用RDD中fold聚合函数:

>>> from operator import add
>>> sc.parallelize([1, 2, 3, 4, 5]).fold(0, add)
15
查看RDD中高级聚合函数aggregate,函数声明如下:

>>> seqOp = (lambda x, y: (x[0] + y, x[1] + 1))
>>> combOp = (lambda x, y: (x[0] + y[0], x[1] + y[1]))
>>> sc.parallelize([1, 2, 3, 4]).aggregate((0, 0), seqOp, combOp)
(10, 4)
在Spark中有一个object对象PairRDDFunctions,主要针对RDD的数据类型是Key/Value对的数据提供函数,方便数据分析处理。比如使用过的函数:reduceByKey、groupByKey等。*ByKey函数:将相同Key的Value进行聚合操作的,省去先分组再聚合。
l第一类:分组函数groupByKey

l第二类:分组聚合函数reduceByKey和foldByKey

l第三类:分组聚合函数aggregateByKey

在企业中如果对数据聚合使用,不能使用reduceByKey完成时,考虑使用aggregateByKey函数,基本上都能完成任意聚合功能。
PairRDDFunctions 聚合函数
演示范例代码如下:
# -*- coding: utf-8 -*-
# Program function:从外部文件系统读取数据转换为RDD
if __name__ == '__main__':
print('PySpark agg Function Program')
# TODO:1、创建应用程序入口SparkContext实例对象
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
# TODO: 2、从本地文件系统创建RDD数据集
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
# TODO: 3、调用集合RDD中函数处理分析数据
# TODO: 4、通过ForeachPartition展示结果
print("==================groupByKey=======================")
print(sorted(rdd.groupByKey().mapValues(len).collect()))
# [('a', 2), ('b', 1)]
print(sorted(rdd.groupByKey().mapValues(list).collect()))
# [('a', [1, 1]), ('b', [1])]
print("==================reduceByKey=======================")
print(sorted(rdd.reduceByKey(add).collect()))
# [('a', 2), ('b', 1)]
print("==================foldByKey=======================")
print(sorted(rdd.foldByKey(0, add).collect()))
# [('a', 2), ('b', 1)]
print("===================aggregateByKey======================")
print(rdd.aggregateByKey(0, add, add).collect())
# [('b', 1), ('a', 2)]
print(sorted(rdd.aggregateByKey(0, add, add).collect()))
# [('a', 2), ('b', 1)]
print("==================groupByKey实现wordcount=======================")
lineseq = ["hadoop scala hive spark scala sql sql",
"hadoop scala spark hdfs hive spark",
"spark hdfs spark hdfs scala hive spark"]
inputRDD = sc.parallelize(lineseq, 2)
wordsRDD = inputRDD.flatMap(lambda line: re.split("\\s+", line)).map(lambda word: (word, 1))
wordsGroupRDD = wordsRDD.groupByKey()
# 仅仅对value进行sum加和
print(wordsGroupRDD.mapValues(sum).collectAsMap())#mapValues(list)
print("==方法2实现wordcount==")
print(wordsRDD.foldByKey(0,add).collect())
# [('hadoop', 2), ('scala', 4), ('hive', 3), ('hdfs', 3), ('spark', 6), ('sql', 2)]
print("==方法3实现wordcount==")
print(wordsRDD.aggregateByKey(0,add,add).collect())
# [('hadoop', 2), ('scala', 4), ('hive', 3), ('hdfs', 3), ('spark', 6), ('sql', 2)]
# 关闭SparkContext
print('停止 PySpark SparkContext对象')
sc.stop()
面试题
RDD中groupByKey和reduceByKey区别???
reduceByKey函数:在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置。

groupByKey函数:在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的函数,将相同key的值聚合到一起,与reduceByKey的区别是只生成一个sequence。

关联函数
当两个RDD的数据类型为二元组Key/Value对时,可以依据Key进行关联Join。

首先回顾一下SQL JOIN,用Venn图表示如下:

具体看一下join(等值连接)函数说明:
if __name__ == '__main__':
print('PySpark join Function Program')
# TODO:1、创建应用程序入口SparkContext实例对象
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
# TODO: 2、从本地文件系统创建RDD数据集
x = sc.parallelize([(1001, "zhangsan"), (1002, "lisi"), (1003, "wangwu"), (1004, "zhangliu")])
y = sc.parallelize([(1001, "sales"), (1002, "tech")])
# TODO: 3、调用集合RDD中函数处理分析数据
# TODO: 4、通过ForeachPartition展示结果
print("==================join=======================")
joined = x.join(y)
final = joined.collect()
print("join result is:",final)
print("==================leftOuterJoin=======================")
leftOuterjoined = x.leftOuterJoin(y)
print("leftOuterjoined result is:",leftOuterjoined.collectAsMap())
print("==================rightOuterJoin=======================")
rightOuterjoined = x.rightOuterJoin(y)
print("rightOuterjoined result is:",rightOuterjoined.collectAsMap())
# 关闭SparkContext
print('停止 PySpark SparkContext对象')
sc.stop()















 323
323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









