







#博学谷IT学习技术支持#
DataFrame进阶
3.1 DataFrame的组成
DataFrame是一个二维表结构, 那么表格结构就有无法绕开的三个点:
行
列
表结构描述
比如,在MySQL中的一张表:
由许多行组成
数据也被分成多个列
表也有表结构信息(列、列名、列类型、列约束等)
基于这个前提,DataFrame的组成如下:
在结构层面:
StructType对象描述整个DataFrame的表结构
StructField对象描述一个列的信息
在数据层面
Row对象记录一行数据
Column对象记录一列数据并包含列的信息
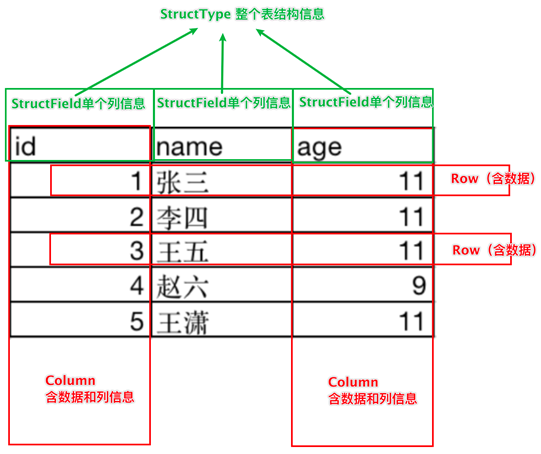
如图, 在表结构层面,DataFrame的表结构由:
StructType描述,如下图

一个StructField记录:列名、列类型、列是否运行为空
多个StructField组成一个StructType对象。
一个StructType对象可以描述一个DataFrame:有几个列、每个列的名字和类型、每个列是否为空
同时,一行数据描述为Row对象,如Row(1, 张三, 11)
一列数据描述为Column对象,Column对象包含一列数据和列的信息
Row、Column、StructType、StructField的编程我们在后面编码阶段会接触
3.2 DataFrame的代码构建
RDD转换DataFrame:
实际项目开发中,往往需要将RDD数据集转换为DataFrame,本质上就是给RDD加上Schema信息,官方提供两种方式:
(1)类型推断和(2)自定义Schema。

Spark官网提供了两种方法来实现从RDD转换得到DataFrame,
第一种方法是利用反射机制,推导包含某种类型的RDD,通过反射将其转换为指定类型的DataFrame,适用于提前知道RDD的schema。
第二种方法通过编程接口与RDD进行交互获取schema,并动态创建DataFrame,在运行时决定列及其类型。
DataFrame的代码构建 - 基于RDD方式1
这种方法为使用反射方法Schema模式,Spark SQL 可以将 Row 对象的 RDD 转换为 DataFrame,从而推断数据类型。
if __name__ == '__main__':
spark = SparkSession.builder \
.appName('test') \
.getOrCreate()
sc = spark.sparkContext
通过SparkSession对象的createDataFrame方法来将RDD转换为DataFrame
这里只传入列名称,类型从RDD中进行推断
# Load a text file and convert each line to a Row.
# 读取一个文件转化每一行为Row对象
lines = sc.textFile("file:///export/pyfolder1/pyspark-chapter03_3.8/data/sql/people.txt")
parts = lines.map(lambda l: l.split(","))
people = parts.map(lambda p: Row(name=p[0], age=int(p[1])))
# Infer the schema, and register the DataFrame as a table.
# 推断Schema,并且将DataFrame注册为Table
schemaPeople = spark.createDataFrame(people)
schemaPeople.createOrReplaceTempView("people")
# SQL can be run over DataFrames that have been registered as a table.
# SQL 可以在已注册为表的 DataFrame 上运行。
teenagers = spark.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")
# The results of SQL queries are Dataframe objects.
# rdd returns the content as an :class:`pyspark.RDD` of :class:`Row`.
# SQL查询的结果是Dataframe对象。
# rdd 返回内容作为 :class:`pyspark.RDD` 的 :class:`Row`。
teenNames = teenagers.rdd.map(lambda p: "Name: " + p.name).collect()
for name in teenNames:
print(name)
# Name: Justin
spark.stop()DataFrame的代码构建 - 基于RDD方式2
将RDD转换为DataFrame方式2:
通过StructType对象来定义DataFrame的“表结构”转换RDD
1.从原始 RDD 创建元组或列表的 RDD;
2.StructType在步骤 1 中创建的 RDD 中创建由匹配的元组或列表结构表示的模式。
3.通过createDataFrame提供的方法将模式应用到 RDD SparkSession。
# Load a text file and convert each line to a Row.
# 1-读取数据,转换每一行数据为Row
lines = sc.textFile("file:///export/pyfolder1/pyspark-chapter03_3.8/data/sql/people.txt")
parts = lines.map(lambda l: l.split(","))
# 2-每一行数据转化为tuple
# Each line is converted to a tuple.
people = parts.map(lambda p: (p[0], p[1].strip()))
# 3-scheme
# The schema is encoded in a string.
schemaString = "name age"
fields = [StructField(field_name, StringType(), True) for field_name in schemaString.split()]
schema = StructType(fields)
# 4-应用Schemea于RDD
# Apply the schema to the RDD.
schemaPeople = spark.createDataFrame(people, schema)
# 5-创建临时试图
# Creates a temporary view using the DataFrame
schemaPeople.createOrReplaceTempView("people")
# 6-执行SQL
# SQL can be run over DataFrames that have been registered as a table.
results = spark.sql("SELECT name FROM people")
# 7-展示结果
results.show()DataFrame的代码构建 - 基于RDD方式3
将RDD转换为DataFrame方式3:
使用RDD的toDF方法转换RDD
# Load a text file and convert each line to a Row.
from pyspark.sql import SparkSession
from pyspark.sql import Row
spark = SparkSession.builder.appName('test').getOrCreate()
sc = spark.sparkContext
l = [('Ankit', 25), ('Jalfaizy', 22), ('saurabh', 20), ('Bala', 26)]
rdd = sc.parallelize(l)
# 为数据添加列名
df = rdd.toDF(["name", "age"])
df.show()
df.printSchema()
spark.stop()
--------------------------------------------------------------
spark = SparkSession.builder.appName('test').getOrCreate()
sc = spark.sparkContext
# 读取一个文件转化每一行为Row对象
lines = sc.textFile("file:///export/pyfolder1/pyspark-chapter03_3.8/data/sql/people.txt")
parts = lines.map(lambda l: l.split(","))
# people = parts.map(lambda p: Row(name=p[0], age=int(p[1])))
peopleDF = parts.toDF(["name", "age"])
# 创建试图
peopleDF.createOrReplaceTempView("people")
# SQL can be run over DataFrames that have been registered as a table.
# SQL 可以在已注册为表的 DataFrame 上运行。
teenagers = spark.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")
# The results of SQL queries are Dataframe objects.
# rdd returns the content as an :class:`pyspark.RDD` of :class:`Row`.
# SQL查询的结果是Dataframe对象。
# rdd 返回内容作为 :class:`pyspark.RDD` 的 :class:`Row`。
teenNames = teenagers.rdd.map(lambda p: "Name: " + p.name).collect()
for name in teenNames:
print(name)
# Name: Justin
spark.stop()DataFrame的代码构建 - 基于Pandas的DataFrame
将Pandas的DataFrame对象,转变为分布式的SparkSQL DataFrame对象
# 构建Pandas的DF
pdf = pd.DataFrame({
"id": [1, 2, 3],
"name": ["张大仙", '王晓晓', '王大锤'],
"age": [11, 11, 11]
})
# 将Pandas的DF对象转换成Spark的DF
df = spark.createDataFrame(pdf)
# coding:utf8
# 演示将Panda的DataFrame转换成Spark的DataFrame
from pyspark.sql import SparkSession
# 导入StructType对象
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pd
if __name__ == '__main__':
spark = SparkSession.builder.\
appName("create df").\
master("local[*]").\
getOrCreate()
sc = spark.sparkContext
# 构建Pandas的DF
pdf = pd.DataFrame({
"id": [1, 2, 3],
"name": ["张大仙", '王晓晓', '王大锤'],
"age": [11, 11, 11]
})
# 将Pandas的DF对象转换成Spark的DF
df = spark.createDataFrame(pdf)
df.printSchema()
df.show()DataFrame的代码构建 - 读取外部数据
读取text数据源
使用format(“text”)读取文本数据
读取到的DataFrame只会有一个列,列名默认称之为:value
示例代码:
schema = StructType().add("data", StringType(), nullable=True)
df = spark.read.format("text")\
.schema(schema)\
.load("../data/sql/people.txt")通过SparkSQL的统一API进行数据读取构建DataFrame
统一API示例代码:
sparksession.read.format("text|csv|json|parquet|orc|avro|jdbc|......")
.option("K", "V") # option可选
.schema(StructType | String) # STRING的语法如.schema("name STRING", "age INT")
.load("被读取文件的路径, 支持本地文件系统和HDFS")读取text数据源
使用format(“text”)读取文本数据
读取到的DataFrame只会有一个列,列名默认称之为:value
示例代码:
schema = StructType().add("data", StringType(), nullable=True)
df = spark.read.format("text")\
.schema(schema)\
.load("../data/sql/people.txt")读取json数据源
使用format(“json”)读取json数据
示例代码:
df = spark.read.format("json").\
load("../data/sql/people.json")
# JSON 类型 一般不用写.schema, json自带, json带有列名 和列类型(字符串和数字)
df.printSchema()
df.show()读取csv数据源
使用format(“csv”)读取csv数据
示例代码:
df = spark.read.format("csv")\
.option("sep", ";")\ # 列分隔符
.option("header", False)\ # 是否有CSV标头
.option("encoding", "utf-8")\ # 编码
.schema("name STRING, age INT, job STRING")\ # 指定列名和类型
.load("../data/sql/people.csv") # 路径
df.printSchema()
df.show()3.3 DataFrame的入门操作
DataFrame支持两种风格进行编程,分别是:
•DSL风格
•SQL风格
DSL语法风格
DSL称之为:领域特定语言。
其实就是指DataFrame的特有API
DSL风格意思就是以调用API的方式来处理Data
比如:df.where().limit()
SQL语法风格
SQL风格就是使用SQL语句处理DataFrame的数据
比如:spark.sql(“SELECT * FROM xxx)
- show 方法
展示DataFrame中的数据, 默认展示20条
df.show(参数1, 参数2)
- 参数1: 默认是20, 控制展示多少条
- 参数2: 是否阶段列, 默认只输出20个字符的长度, 过长不显示, 要显示的话 请填入 truncate = TrueDSL - printSchema方法
功能:打印输出df的schema信息
语法:df.printSchema()
DSL - select
功能:选择DataFrame中的指定列(通过传入参数进行指定)
可传递:
可变参数的cols对象,cols对象可以是Column对象来指定列或者字符串列名来指定列
List[Column]对象或者List[str]对象, 用来选择多个列

DSL - filter和where
功能:过滤DataFrame内的数据,返回一个过滤后的DataFrame
语法:
df.filter()
df.where()
where和filter功能上是等价的

DSL - groupBy 分组
功能:按照指定的列进行数据的分组, 返回值是GroupedData对象
语法:
df.groupBy()

传入参数和select一样,支持多种形式,不管怎么传意思就是告诉spark
按照哪个列分组
GroupedData对象
GroupedData对象是一个特殊的DataFrame数据集
其类全名:<class 'pyspark.sql.group.GroupedData'>
这个对象是经过groupBy后得到的返回值, 内部记录了 以分组形式存储的数据
GroupedData对象其实也有很多API,比如前面的count方法就是这个对象的内置方法
除此之外,像:min、max、avg、sum、等等许多方法都存在
后续会再次使用它
SQL风格语法 - 注册DataFrame成为表
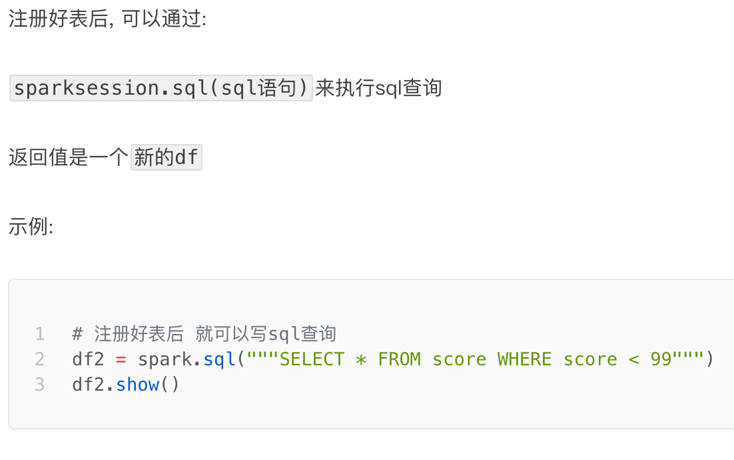
DataFrame的一个强大之处就是我们可以将它看作是一个关系型数据表,然后可以通过在程序中使用spark.sql() 来执行SQL语句查询,结果返回一个DataFrame。
如果想使用SQL风格的语法,需要将DataFrame注册成表,采用如下的方式:

lpyspark.sql.functions 包
PySpark提供了一个包: pyspark.sql.functions
这个包里面提供了 一系列的计算函数供SparkSQL使用
from pyspark.sql import functions as F
这些功能函数, 返回值多数都是Column对象.

if __name__ == '__main__':
spark = SparkSession.builder.appName('test').getOrCreate()
sc = spark.sparkContext
# Load a text file and convert each line to a Row.
spark = SparkSession.builder.appName('test').getOrCreate()
sc = spark.sparkContext
# 读取一个文件转化每一行为Row对象
lines = sc.textFile("file:///export/pyfolder1/pyspark-chapter03_3.8/data/sql/people.txt")
parts = lines.map(lambda l: l.split(","))
# people = parts.map(lambda p: Row(name=p[0], age=int(p[1])))
personDF = parts.toDF(["name", "age"])
# DSL操作
# 4.1.1 查看DataFrame中的内容,通过调用show方法
personDF.show
# 4.1.2 查看DataFrame的Scheme信息
personDF.printSchema()
# 4.1.3.1 第一种方式查看name字段数据
personDF.select("name").show()
# 4.1.3.2 第二种方式查看name字段数据
personDF.select(personDF['name'], personDF['age'] + 1).show()
# 4.1.3.3 第三种方式查看name和age字段数据-此方法不可行
# personDF.select(personDF.col("name"), personDF.col("age")).show
# 4.1.3.4 第四种方式查看name和age字段数据-此方法不可行
# personDF.select(personDF.columns["name"], personDF.columns["age"]).show
# 4.1.3.5 过滤操作
personDF.filter(personDF['age'] > 21).show()
# 4.1.3.6 统计操作
personDF.groupBy("age").count().show()
# 5-SQL操作 创建临时试图
# Creates a temporary view using the DataFrame
personDF.createOrReplaceTempView("people")
# 5.1.1 查看DataFrame中的内容
spark.sql("SELECT * FROM people").show()
# 5.1.2 查看DataFrame的Scheme信息
spark.sql("desc people").show()
# 5.1.3 查看name字段数据
spark.sql("SELECT name FROM people").show()
# 5.1.3 根据age排序的前两个人员信息
spark.sql("select * from people order by age desc limit 2 ").show()
# 5.1.4 查询年龄大于30的人的信息
spark.sql("select * from people where age > 15").show()3.4 词频统计案例
3.5 电影数据分析
3.6 SparkSQL Shuffle 分区数目


# TODO: 设置shuffle时分区数目
spark = SparkSession.builder \
.appName('test') \
.master("local[4]") \
.config("spark.sql.shuffle.partitions", "4") \
.getOrCreate()
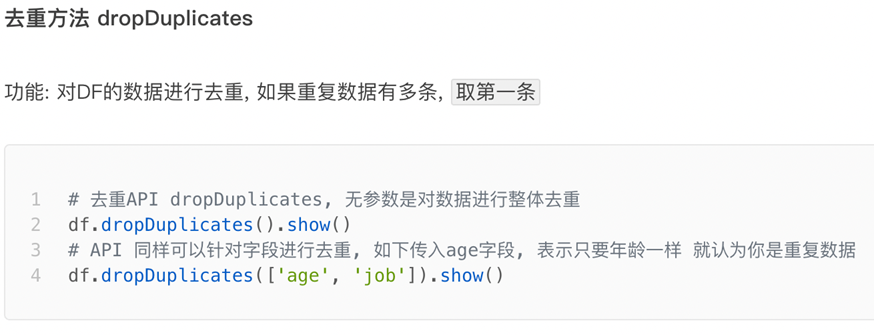
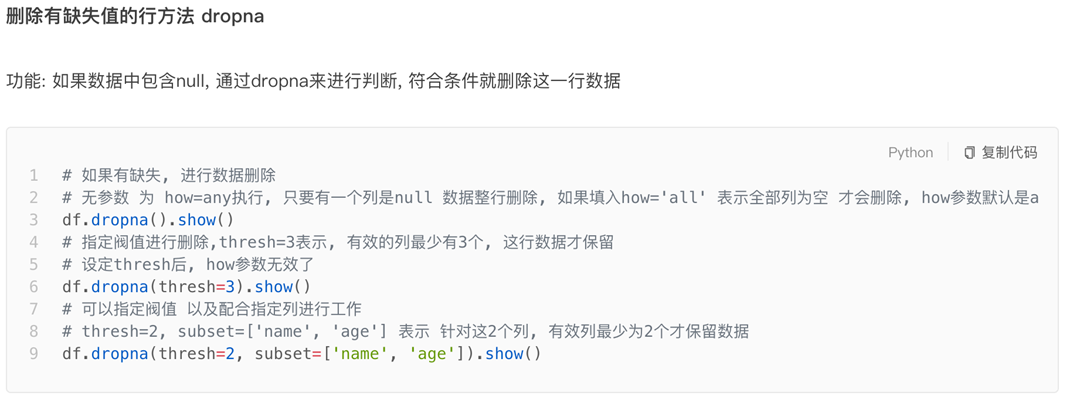
sc = spark.sparkContext3.7 SparkSQL 数据清洗API


3.8 DataFrame数据写出

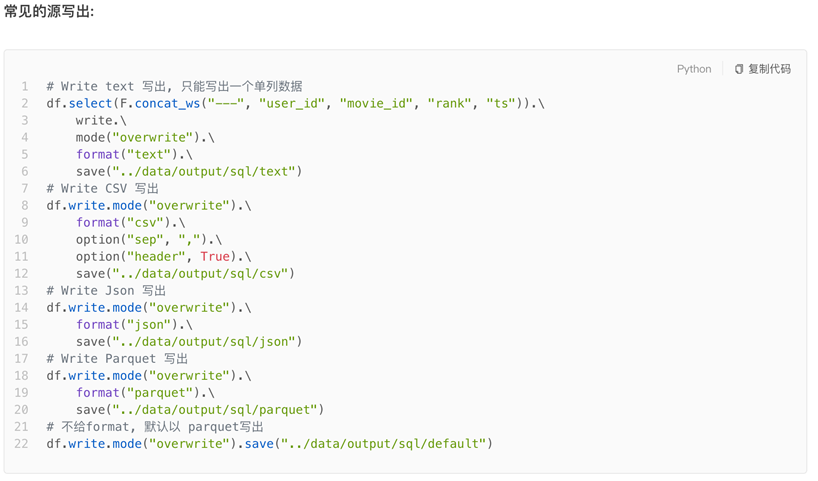
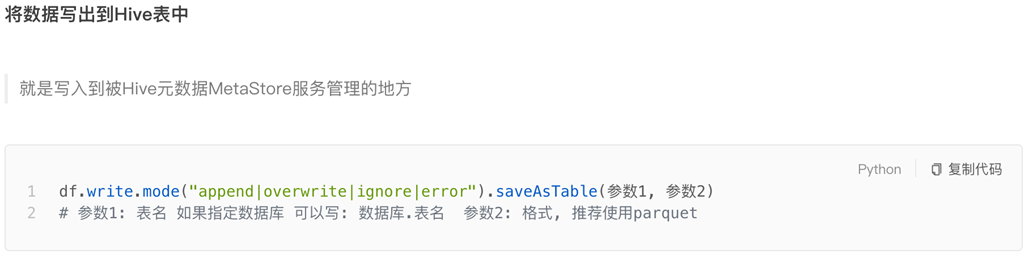
注意写出Hive表需要配置好Hive和Spark的集成。
SparkSQL函数定义
4.1 SparkSQL 使用窗口函数
开窗函数的引入是为了既显示聚集前的数据,又显示聚集后的数据。即在每一行的最后一列添加聚合函数的结果。
开窗用于为行定义一个窗口(这里的窗口是指运算将要操作的行的集合),它对一组值进行操作,不需要使用 GROUP BY 子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。
●聚合函数和开窗函数
聚合函数是将多行变成一行,count,avg....
开窗函数是将一行变成多行;
聚合函数如果要显示其他的列必须将列加入到group by中
开窗函数可以不使用group by,直接将所有信息显示出来
●开窗函数分类
1.聚合开窗函数
聚合函数(列) OVER(选项),这里的选项可以是PARTITION BY 子句,但不可以是 ORDER BY 子句。
2.排序开窗函数
排序函数(列) OVER(选项),这里的选项可以是ORDER BY 子句,也可以是 OVER(PARTITION BY 子句 ORDER BY 子句),但不可以是 PARTITION BY 子句。
# 聚合类型 SUM\MIN\MAX\AVG\COUNT
sum() OVER([PARTITION BY XXX][ORDER BY XXX [DESC]])
# 排序类型: ROW NUMBERIRANKIDENSE RANK
ROW_NUMBER() OVER([PARTITION BY XXX][ORDER BY XXX [DESC]])
# 分区类型: NTILE
NTILE(number) OVER([PARTITION BY XXX][ORDER BY XXX[DESC]])
scoreDF = spark.sparkContext.parallelize([
("a1", 1, 80),
("a2", 1, 78),
("a3", 1, 95),
("a4", 2, 74),
("a5", 2, 92),
("a6", 3, 99),
("a7", 3, 99),
("a8", 3, 45),
("a9", 3, 55),
("a10", 3, 78),
("a11", 3, 100)]
).toDF(["name", "class", "score"])
scoreDF.createOrReplaceTempView("scores")
scoreDF.show()●示例1
OVER 关键字表示把聚合函数当成聚合开窗函数而不是聚合函数。
SQL标准允许将所有聚合函数用做聚合开窗函数
spark.sql("select count(name) from scores").show()
spark.sql("select name, class, score, count(name) over() name_count from scores").show()
+----+-----+-----+
|name|class|score|
+----+-----+-----+
| a1| 1| 80|
| a2| 1| 78|
| a3| 1| 95|
| a4| 2| 74|
| a5| 2| 92|
| a6| 3| 99|
| a7| 3| 99|
| a8| 3| 45|
| a9| 3| 55|
| a10| 3| 78|
| a11| 3| 100|
+----+-----+-----+●示例2
OVER 关键字后的括号中还可以添加选项用以改变进行聚合运算的窗口范围。
如果 OVER 关键字后的括号中的选项为空,则开窗函数会对结果集中的所有行进行聚合运算。
开窗函数的 OVER 关键字后括号中的可以使用 PARTITION BY 子句来定义行的分区来供进行聚合计算。
注意:与 GROUP BY 子句不同,PARTITION BY 子句创建的分区是独立于结果集的,创建的分区只是供进行聚合计算的,而且不同的开窗函数所创建的分区也不互相影响。
spark.sql("select name, class, score, count(name) over(partition by class) name_count from scores").show()
+----+-----+-----+----------+
|name|class|score|name_count|
+----+-----+-----+----------+
| a1| 1| 80| 3|
| a2| 1| 78| 3|
| a3| 1| 95| 3|
| a6| 3| 99| 6|
| a7| 3| 99| 6|
| a8| 3| 45| 6|
| a9| 3| 55| 6|
| a10| 3| 78| 6|
| a11| 3| 100| 6|
| a4| 2| 74| 2|
| a5| 2| 92| 2|
+----+-----+-----+----------+ROW_NUMBER顺序排序
# row_number() over(order by score) as rownum 表示按score 升序的方式来排序,并得出排序结果的序号
spark.sql("select name, class, score, row_number() over(order by score) rank from scores").show()
# PartitionBy分组
spark.sql("select name, class, score, row_number() over(partition by class order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a2| 1| 78| 1|
| a1| 1| 80| 2|
| a3| 1| 95| 3|
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a10| 3| 78| 3|
| a6| 3| 99| 4|
| a7| 3| 99| 5|
| a11| 3| 100| 6|
| a4| 2| 74| 1|
| a5| 2| 92| 2|
+----+-----+-----+----+RANK跳跃排序
rank() over(order by score) as rank表示按 score升序的方式来排序,并得出排序结果的排名号。
这个函数求出来的排名结果可以并列,并列排名之后的排名将是并列的排名加上并列数
简单说每个人只有一种排名,然后出现两个并列第一名的情况,这时候排在两个第一名后面的人将是第三名,也就是没有了第二名,但是有两个第一名
spark.sql("select name, class, score, rank() over(order by score) rank from scores").show()
rank() over(order by score) as rank表示按 score升序的方式来排序,并得出排序结果的排名号。
这个函数求出来的排名结果可以并列,并列排名之后的排名将是并列的排名加上并列数
简单说每个人只有一种排名,然后出现两个并列第一名的情况,这时候排在两个第一名后面的人将是第三名,也就是没有了第二名,但是有两个第一名
spark.sql("select name, class, score, rank() over(partition by class order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a2| 1| 78| 1|
| a1| 1| 80| 2|
| a3| 1| 95| 3|
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a10| 3| 78| 3|
| a6| 3| 99| 4|
| a7| 3| 99| 4|
| a11| 3| 100| 6|
| a4| 2| 74| 1|
| a5| 2| 92| 2|
+----+-----+-----+----+DENSE_RANK连续排序
dense_rank() over(order by score) as dense_rank 表示按score 升序的方式来排序,并得出排序结果的排名号。
这个函数并列排名之后的排名只是并列排名加1
简单说每个人只有一种排名,然后出现两个并列第一名的情况,这时候排在两个第一名后面的人将是第二名,也就是两个第一名,一个第二名spark.sql("select name, class, score, dense_rank() over(order by score) rank from scores").show()
spark.sql("select name, class, score, dense_rank() over(partition by class order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a2| 1| 78| 1|
| a1| 1| 80| 2|
| a3| 1| 95| 3|
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a10| 3| 78| 3|
| a6| 3| 99| 4|
| a7| 3| 99| 4|
| a11| 3| 100| 5|
| a4| 2| 74| 1|
| a5| 2| 92| 2|
+----+-----+-----+----+NTILE分组排名[了解]
# ntile(6) over(order by score)as ntile表示按 score 升序的方式来排序,然后 6 等分成 6 个组,并显示所在组的序号。
spark.sql("select name, class, score, ntile(6) over(order by score) rank from scores").show()
# partition by
spark.sql("select name, class, score, ntile(6) over(partition by class order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a2| 1| 78| 1|
| a1| 1| 80| 2|
| a3| 1| 95| 3|
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a10| 3| 78| 3|
| a6| 3| 99| 4|
| a7| 3| 99| 5|
| a11| 3| 100| 6|
| a4| 2| 74| 1|
| a5| 2| 92| 2|
+----+-----+-----+----+4.2 SparkSQL 定义UDF函数
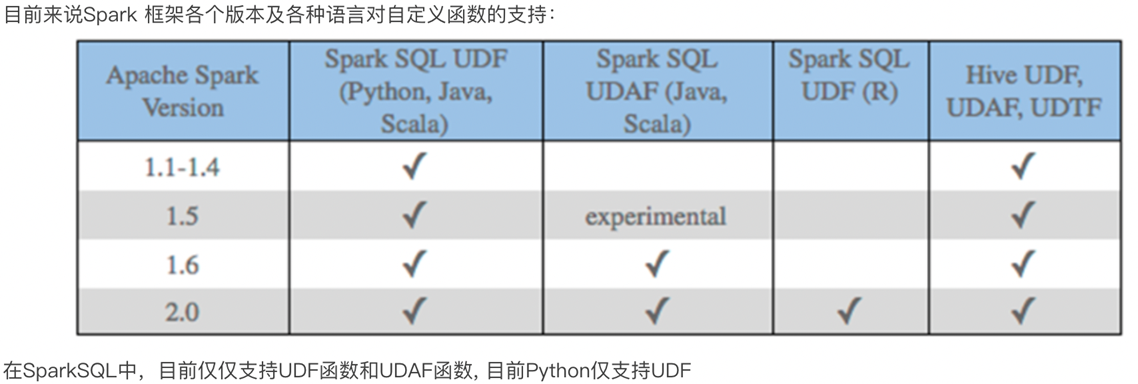
无论Hive还是SparkSQL分析处理数据时,往往需要使用函数,SparkSQL模块本身自带很多实现公共功能的函数,在pyspark.sql.functions中。SparkSQL与Hive一样支持定义函数:UDF和UDAF,尤其是UDF函数在实际项目中使用最为广泛。
回顾Hive中自定义函数有三种类型:
第一种:UDF(User-Defined-Function) 函数
一对一的关系,输入一个值经过函数以后输出一个值;
在Hive中继承UDF类,方法名称为evaluate,返回值不能为void,其实就是实现一个方法;
第二种:UDAF(User-Defined Aggregation Function) 聚合函数
多对一的关系,输入多个值输出一个值,通常与groupBy联合使用;
第三种:UDTF(User-Defined Table-Generating Functions) 函数
一对多的关系,输入一个值输出多个值(一行变为多行);
用户自定义生成函数,有点像flatMap;
问题出现:
Spark 在 0.7 版中添加了 Python API,并支持user-defined functions。这些用户定义的函数一次只能操作一行,因此会遭遇高序列化和调用开销。因此,许多数据管道在 Java 和 Scala 中定义 UDF,然后从 Python 中调用它们。
基于注解方式Pandas UDF
在Arrow之前,如果要对不同语言数据进行传输需要使用过序列化和反序列化,耗费了大量的开销,而Arrow 借由其简单高效的内存结构,支持不同语言间的相互转换,实现了不同语言之间的高效数据传输。基于 Apache Arrow 构建的 Pandas UDF 为您提供了两全其美的功能 - 完全用 Python 定义低开销,高性能 UDF的能力。
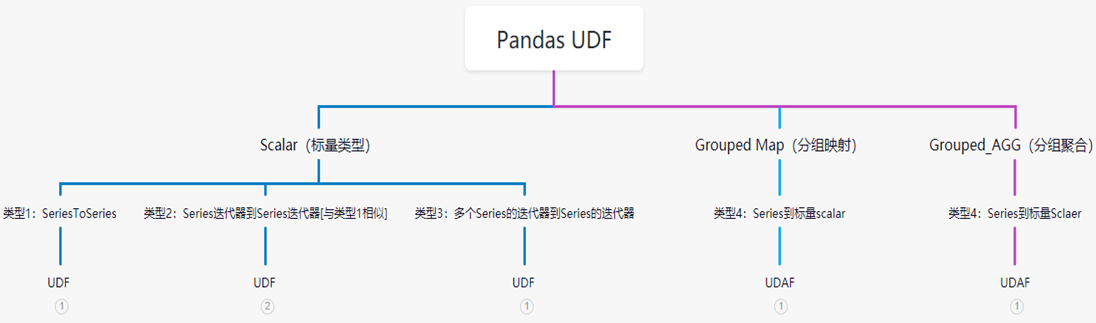
在 Spark 2.3 中,将会有两种类型的 Pandas UDF: 标量(scalar)和分组映射(grouped map)。Spark2.4新支持Grouped Aggregate


方式1语法:
udf对象 = sparksession.udf.register(参数1,参数2,参数3)
参数1:UDF名称,可用于SQL风格
参数2:被注册成UDF的方法名
参数3:声明UDF的返回值类型
udf对象: 返回值对象,是一个UDF对象,可用于DSL风格
方式2语法:
udf对象 = F.udf(参数1, 参数2)
参数1:被注册成UDF的方法名
参数2:声明UDF的返回值类型
udf对象: 返回值对象,是一个UDF对象,可用于DSL风格
其中F是:
from pyspark.sql import functions as F
其中,被注册成UDF的方法名是指具体的计算方法,如:
def add(x, y): x + y
add就是将要被注册成UDF的方法名
需求1:我们想将一个求平方和的python函数注册成一个Spark UDF函数,UDF返回值注册为整形
# 需求:我们想将一个求平方和的python函数注册成一个Spark UDF函数
def square(x):
return x ** 2
from pyspark.sql.functions import udf
from pyspark.sql.types import IntegerType
udf_integger = udf(square, returnType=IntegerType())
# DSL
df.select("integers", udf_integger("integers")).show()
# SQL
df.createOrReplaceTempView("table")
# 如果使用SQL需要注册时临时函数
spark.udf.register("udf_integger", udf_integger)
spark.sql("select integers,udf_integger(integers) as integerX from table").show()
需求2:我们想将一个求平方和的python函数注册成一个Spark UDF函数,UDF返回值注册为Float类型
# 需求:我们想将一个求平方和的python函数注册成一个Spark UDF函数
def square(x):
return x ** 2
from pyspark.sql.functions import udf
from pyspark.sql.types import IntegerType,FloatType
# 现象:如果类型和udf的返回类型不一致的化,导致null的出现
# 如何解决?基于列表方式解决
udf_integger = udf(square, returnType=FloatType())
# DSL
df.select("integers", udf_integger("integers").alias("int"),udf_integger("floats").alias("flat")).show()
# 下面演示转化为lambda表达式场景
udf_integger_lambda = udf(lambda x:x**2, returnType=IntegerType())
df.select("integers", udf_integger_lambda("integers").alias("int")).show()
需求4:我们想将一个求平方和的python函数注册成一个Spark UDF函数,使用Python注解方式
from pyspark.sql.types import IntegerType, FloatType
# 需求:我们想将一个求平方和的python函数注册成一个Spark UDF函数
@udf(returnType=IntegerType())
def square(x):
return x ** 2
df.select("integers", square("integers").alias("int")).show()
# 需求:我们想将一个求平方和的python函数注册成一个Spark UDF函数
def squareTest(x):
return x ** 2
udf_int = udf(squareTest, returnType=IntegerType())
df.select("integers", udf_int("integers").alias("int")).show()
有一个函数,输入一个数字,返回数字以及该数字对应字母表中的字母。UDF返回值注册为字典类型
# 4-对于返回类型是tuple或者是混合类型的函数,我们可以定义一个相关的StructType(),
# 里面的字段可以定义为StructField()。
import string
from pyspark.sql.types import StructField, StructType, IntegerType, StringType
def convert_ascii(number):
return [number, string.ascii_letters[number]]
array_schema = StructType([
StructField('number', IntegerType(), nullable=False),
StructField('letters', StringType(), nullable=False)
])
spark_convert_ascii = udf(lambda z: convert_ascii(z), array_schema)
df_ascii = df.select('integers', spark_convert_ascii('integers').alias('ascii_map'))
df_ascii.show()
Ø注意:
Ø使用UDF两种方式均可
Ø
Ø唯一需要注意的就是:返回值类型一定要有合适的类型声明
Ø
Ø返回值int 可以用IntegerType
Ø返回值小数,可以用FloatType或者DoubleType
Ø返回值list可以用ArrayType描述
Ø返回值字典,可以用StructType描述
Ø.....
Ø
Ø这些内置的Spark数据类型均存储在
Øpyspark.sql.types中需求:模拟数据集实现用户名字长度,用户名字转为大写,以及age年龄字段增加1岁
import os
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf
if __name__ == '__main__':
spark = SparkSession.builder \
.appName('test') \
.master("local[*]") \
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
from pyspark.sql.types import IntegerType
slen = udf(lambda s: len(s), IntegerType())
@udf
def to_upper(s):
if s is not None:
return s.upper()
@udf(returnType=IntegerType())
def add_one(x):
if x is not None:
return x + 1
df = spark.createDataFrame([(1, "John Doe", 21)], ("id", "name", "age"))
result = df.select(slen("name").alias("slen(name)"), to_upper("name"), add_one("age"))
result.show()
spark.stop()4.3 pandasUDF
Apache Arrow 是一种内存中的列式数据格式,用于 Spark 中以在 JVM 和 Python 进程之间有效地传输数据。下面学习从Pandas转化到Spark的DF以及Spark的DF通过toPandas转化为Pandas的DataFrame。
Apache Arrow高性能数据传输框架
Apache Arrow 是 Apache 基金会全新孵化的一个顶级项目。一个跨平台的在内存中以列式存储的数据层,它设计的目的在于作为一个跨平台的数据层,来加快大数据分析项目的运行速度。 Pandas 建立在ApacheArrow 之上,带来了低开销,高性能的udf。
Apache Arrow 是一种内存中的列式数据格式,用于 Spark 中以在 JVM 和 Python 进程之间有效地传输数据。目前这对使用 Pandas/NumPy 数据的 Python 用户最有益。它的使用不是自动的,可能需要对配置或代码进行一些小的更改才能充分利用并确保兼容性。
如何安装呢?
pip install pyspark[sql]
在代码中添加启动arrow:
spark.conf.set("spark.sql.execution.arrow.enabled", "true")
启用与pandas的转换:
在使用调用将 Spark DataFrame 转换为 Pandas DataFrame 以及使用DataFrame.toPandas().pandas DataFrame 从 Pandas DataFrame 创建 Spark DataFrame 时, Arrow 可用作优化SparkSession.createDataFrame()。要在执行这些调用时使用 Arrow,用户需要首先将 Spark 配置设置spark.sql.execution.arrow.pyspark.enabled为true. 默认情况下禁用此功能。
此外,spark.sql.execution.arrow.pyspark.enabled如果在 Spark 中的实际计算之前发生错误,则启用的优化可以自动回退到非 Arrow 优化实现。这可以通过下面命令来控制:
spark.sql.execution.arrow.pyspark.fallback.enabled。
Apache Arrow高性能数据传输框架
if __name__ == '__main__':
spark = SparkSession.builder \
.appName('test') \
.getOrCreate()
sc = spark.sparkContext
import numpy as np
import pandas as pd
# Enable Arrow-based columnar data transfers
# 基于Arrow-Based的列数据传输
spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true")
# Generate a Pandas DataFrame
# 生成 Pandas的数据框
pdf = pd.DataFrame(np.random.rand(100, 3))
# Create a Spark DataFrame from a Pandas DataFrame using Arrow
df = spark.createDataFrame(pdf)
# Convert the Spark DataFrame back to a Pandas DataFrame using Arrow
# 使用 Arrow 从 Pandas DataFrame 创建 Spark DataFrame
result_pdf = df.select("*").toPandas()
print(result_pdf)
print(type(result_pdf))
spark.stop()对 Arrow 使用上述优化将产生与未启用 Arrow 时相同的结果,但是效率提升很多。
请注意,即使使用 Arrow,也会DataFrame.toPandas()导致将 DataFrame 中的所有记录收集到驱动Driver程序中。当前并非所有 Spark 数据类型都受支持,如果列具有不受支持的类型,则会引发错误。如果在运行期间发生错误SparkSession.createDataFrame(),Spark 将会退以创建没有 Arrow 的 DataFrame。
pandas UDF
Pandas UDF 是用户定义的函数,由 Spark 执行,使用 Arrow 传输数据,Pandas函数处理数据(写的是Py函数),允许向量化操作。Pandas UDF 是使用pandas_udf()作为装饰器或包装函数来定义的,不需要额外的配置。Pandas UDF 通常表现为常规的PySpark函数API。
注意:在 Spark 3.0 之前,Pandas UDF 过去使用pyspark.sql.functions.PandasUDFType. 从 Spark 3.0 和 Python 3.6+ 开始,还可以使用Python 类型提示。首选使用 Python 类型提示,并且pyspark.sql.functions.PandasUDFType将在未来版本中弃用。
类型1: seriesToSeries
类型提示可以表示为pandas.Series, ... -> pandas.Series。
通过pandas_udf()与具有上述类型提示的函数一起使用,它会创建一个 Pandas UDF,其中给定的函数采用一个或多个pandas.Series并输出一个pandas.Series。函数的输出应始终与输入的长度相同。在内部,PySpark将通过将列拆分为批次并作为数据的子集调用每个批次的函数,然后将结果连接在一起来执行 Pandas UDF。
以下示例演示如何创建此 Pandas UDF 来计算 2 列的乘积:

if __name__ == '__main__':
spark = SparkSession.builder \
.appName('test') \
.getOrCreate()
sc = spark.sparkContext
x = pd.Series([1, 2, 3])
# 方式1:普通方式创建pandas_func
def multiply_func(a: pd.Series, b: pd.Series) -> pd.Series:
return a * b
print(multiply_func(x, x))
# 0 1
# 1 4
# 2 9
# pandas_udf方法
multiply = pandas_udf(multiply_func, returnType=LongType())
df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
df.select(multiply(col("x"), col("x"))).show()
# +-------------------+
# |multiply_func(x, x)|
# +-------------------+
# | 1|
# | 4|
# | 9|
# +-------------------+
# 方式2:装饰器方法
@pandas_udf(LongType())
def multiply_func1(a: pd.Series, b: pd.Series) -> pd.Series:
return a * b
df.select(multiply_func1(col("x"), col("x")))\
.withColumnRenamed("multiply_func1(x, x)","xxx").show()
spark.stop()类型2: series到标量sclaer(Grouped Agg)
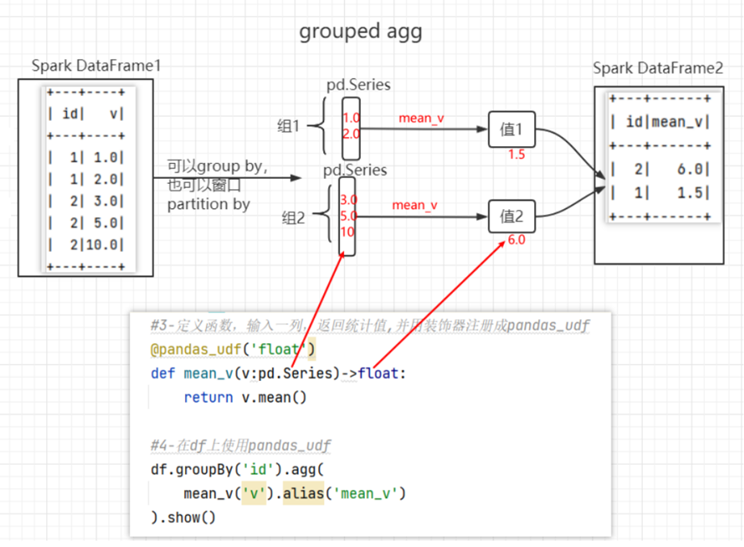
import pandas as pd
from pyspark.sql.functions import pandas_udf
from pyspark.sql import Window
df = spark.createDataFrame([(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)], ("id", "v"))
# Declare the function and create the UDF
@pandas_udf("double")
def mean_udf(v: pd.Series) -> float:
return v.mean()
df.select(mean_udf(df['v'])).show()
# +-----------+
# |mean_udf(v)|
# +-----------+
# | 4.2|
# +-----------+
df.groupby("id").agg(mean_udf(df['v'])).show()
# +---+-----------+
# | id|mean_udf(v)|
# +---+-----------+
# | 1| 1.5|
# | 2| 6.0|
# +---+-----------+
w = Window \
.partitionBy('id') \
.rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing)
df.withColumn('mean_v', mean_udf(df['v']).over(w)).show()
# +---+----+------+
# | id| v|mean_v|
# +---+----+------+
# | 1| 1.0| 1.5|
# | 1| 2.0| 1.5|
# | 2| 3.0| 6.0|
# | 2| 5.0| 6.0|
# | 2|10.0| 6.0|
# +---+----+------+ pandasUDF案例实战
pyspark.sql.functions.pandas_udf(f=None, returnType=None, functionType=None)
pandas_udf是用户定义的函数,由Spark使用Arrow来传输数据,并使用Pandas来处理数据,从而实现矢量化操作。使用pandas_udf,可以方便的在PySpark和Pandas之间进行互操作,并且保证性能;其核心思想是将Apache Arrow作为序列化格式。
Pandas UDF通常表现为常规的PySpark函数API。
f: 用户定义的函数;
returnType: 用户自定义函数的返回值类型,该值可以是pyspark.sql.types.DataType对象或DDL格式的类型字符串
functionType: pyspark.sql.functions.PandasUDFType中的枚举值。 默认值:SCALAR.存在此参数是为了兼容性。 鼓励使用Python类型。















 1082
1082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









