







一、概述
按照惯例,先看一下源码里的第一段注释:
Hash table and linked list implementation of the Map interface, with predictable iteration order. This implementation differs from HashMap in that it maintains a doubly-linked list running through all of its entries. This linked list defines the iteration ordering, which is normally the order in which keys were inserted into the map (insertion-order). Note that insertion order is not affected if a key is re-inserted into the map. (A key k is reinserted into a map m if m.put(k, v) is invoked when m.containsKey(k) would return true immediately prior to the invocation.)
从注释中,我们可以先了解到LinkedHashMap是通过哈希表和链表实现的,它通过维护一个链表来保证对哈希表迭代时的有序性,而这个有序是指键值对插入的顺序。另外,当向哈希表中重复插入某个键的时候,不会影响到原来的有序性。也就是说,假设你插入的键的顺序为1、2、3、4,后来再次插入2,迭代时的顺序还是1、2、3、4,而不会因为后来插入的2变成1、3、4、2。(但其实我们可以改变它的规则,使它变成1、3、4、2)
LinkedHashMap的实现主要分两部分,一部分是哈希表,另外一部分是链表。哈希表部分继承了HashMap,拥有了HashMap那一套高效的操作,所以我们要看的就是LinkedHashMap中链表的部分,了解它是如何来维护有序性的。
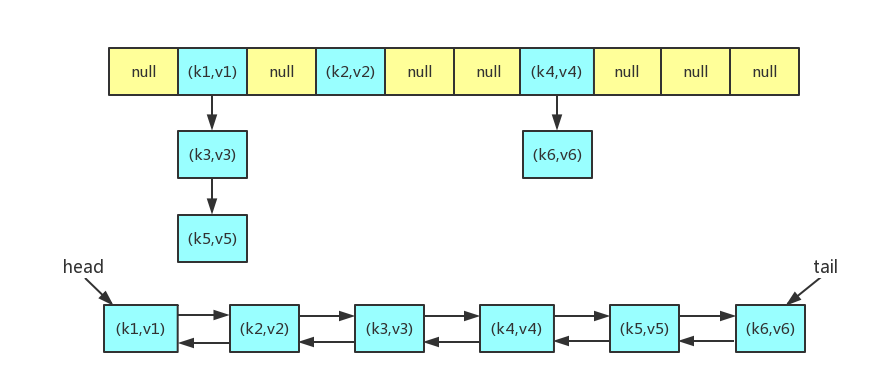
LinkedHashMap 的大致实现如下图所示,当然链表和哈希表中相同的键值对都是指向同一个对象,这里把它们分开来画只是为了呈现出比较清晰的结构。
二、属性
在看属性之前,我们先来看一下 LinkedHashMap 的声明:
public class LinkedHashMap<K,V> extends  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1909
1909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









