









一、引言
生成式 AI 模型在自然语言处理领域中取得了显著进展,其核心在于生成符合人类语言习惯的文本。Temperature(温度) 作为关键超参数,直接影响文本的随机性与多样性。从问答系统到创意写作,Temperature 的调节能力使其成为 AI 文本生成的重要工具。本文将从原理、数学基础、应用场景及调优策略等方面,全面解析 Temperature 采样的作用与价值。
二、Temperature 采样的背景与发展
Temperature 采样作为生成式 AI 模型中的核心技术之一,其发展历程与自然语言处理(NLP)领域的进步密切相关。从早期的统计模型到现代深度学习框架,Temperature 的引入与优化不仅提升了文本生成的多样性,也为随机性控制提供了理论和实践基础。
1. 历史背景
Temperature 采样的概念最早可以追溯到统计力学中的玻尔兹曼分布(Boltzmann Distribution)。在物理学中,玻尔兹曼分布描述了系统中粒子在不同能量状态下的概率分布,其数学形式为:
P ( E i ) = e − E i k T ∑ j e − E j k T P(E_i) = \frac{e^{-\frac{E_i}{kT}}}{\sum_{j} e^{-\frac{E_j}{kT}}} P(Ei)=∑je−kTEje−kTEi
其中, E i E_i Ei 表示第 i i i 个状态的能量, k k k 为玻尔兹曼常数, T T T 为温度。温度 T T T 在此起到调节作用:当 T T T 较高时,概率分布趋于均匀;当 T T T 较低时,高能量状态的概率显著降低。这种分布的特性启发了机器学习领域对概率分布的操控。

在 NLP 的早期,文本生成主要依赖统计语言模型,如 n-gram 模型。这些模型通过统计词频生成文本,但缺乏上下文理解能力,且生成的文本单一、呆板。随着神经网络的兴起,尤其是循环神经网络(RNN)和长短期记忆网络(LSTM)的应用,语言模型开始能够捕捉更长的依赖关系。然而,当时的解码策略多采用贪心解码(Greedy Decoding),即在每一步选择概率最高的词。这种方法虽然高效,但生成的文本往往过于保守,缺乏多样性。
2010 年代,随着 Transformer 架构的出现(如 BERT、GPT),生成式模型的能力显著提升。Transformer 的自注意力机制使其能够处理大规模语料并生成更连贯的文本。然而,贪心解码的局限性愈发明显,研究者开始探索更灵活的采样方法。Temperature 采样正是在这一背景下被引入,它借鉴了玻尔兹曼分布的思想,通过调节“温度”参数 T T T,实现了对概率分布的动态控制。
2. 技术演进
Temperature 采样的技术演进与生成式模型的优化密切相关。最初,Temperature 被作为 Softmax 函数的简单扩展,用于调整 logits 的缩放。其基本公式为:
P ′ ( i ) = e l o g i t ( i ) T ∑ j = 1 n e l o g i t ( j ) T P'(i) = \frac{e^{\frac{logit(i)}{T}}}{\sum_{j=1}^{n} e^{\frac{logit(j)}{T}}} P′(i)=∑j=1neTlogit(j)eTlogit(i)
这种形式直接继承了玻尔兹曼分布的指数特性,通过 T T T 的变化影响概率分布的平滑度。例如,当 T = 1 T = 1 T=1 时,输出等同于标准 Softmax;当 T < 1 T < 1 T<1 时,分布更尖锐;当 T > 1 T > 1 T>1 时,分布更平坦。
早期应用
在 RNN 和 LSTM 模型中,Temperature 采样被用于提升文本生成的多样性。例如,2015 年左右的字符级 RNN 模型中,研究者发现通过设置 T = 1.2 T = 1.2 T=1.2,模型可以生成更具创意性的句子,尽管偶尔会牺牲连贯性。这一时期的 Temperature 应用较为粗糙,通常作为固定参数手动调节,缺乏系统性优化。
Transformer 时代的突破
2017 年 Transformer 的提出标志着 NLP 的新纪元,Temperature 采样也在此阶段得到广泛应用。以 GPT-1 为例,其文本生成任务中引入了 Temperature 作为超参数,结合 Softmax 实现动态采样。研究者发现,通过将 T T T 设置在 0.7 至 1.5 之间,模型能在逻辑性和创造性之间取得较好平衡。例如,在对话生成中, T = 0.9 T = 0.9 T=0.9 的设置使回答既自然又不失灵活性。
数学推导与优化
Temperature 的数学基础在于其对 logits 缩放的影响。假设原始 logits 为
[
l
1
,
l
2
,
.
.
.
,
l
n
]
[l_1, l_2, ..., l_n]
[l1,l2,...,ln],引入
T
T
T 后,指数项变为
l
i
T
\frac{l_i}{T}
Tli。当
T
→
0
T \to 0
T→0 时:
lim
T
→
0
P
′
(
i
)
=
{
1
,
if
i
=
arg
max
(
l
j
)
0
,
otherwise
\lim_{T \to 0} P'(i) = \begin{cases} 1, & \text{if } i = \arg\max(l_j) \\ 0, & \text{otherwise} \end{cases}
T→0limP′(i)={1,0,if i=argmax(lj)otherwise
这等效于贪心解码;当
T
→
∞
T \to \infty
T→∞ 时,所有
P
′
(
i
)
P'(i)
P′(i) 趋于
1
n
\frac{1}{n}
n1,即均匀分布。这种极限行为为 Temperature 的调节范围提供了理论依据。
现代优化中,Temperature 常与其他超参数(如 Top-k、Top-p)结合使用。例如,OpenAI 在 GPT-2 和 GPT-3 中通过实验验证, T = 1 T = 1 T=1 配合 Top-p = 0.9 能显著提升生成文本的质量。这一时期的 Temperature 采样不再是单一参数,而是融入复杂的解码策略体系。
3. 与其他采样方法的对比
Temperature 采样的独特之处在于其灵活性和可控性,但与其他采样方法相比,各有优劣。
贪心解码
贪心解码始终选择概率最高的词,计算复杂度低,但生成的文本重复性高。例如,输入“天气很好”,可能反复输出“很好很好”。Temperature 采样通过调节 T T T(如 T = 1.2 T = 1.2 T=1.2)引入随机性,避免这种单调性。
束搜索(Beam Search)
束搜索通过保留多个候选路径优化全局序列,广泛用于机器翻译。但其计算成本高,且在开放性任务中可能生成过于“安全”的文本。相比之下,Temperature 采样更轻量,适合实时生成任务。例如,在诗歌创作中,束搜索可能生成规整但缺乏新意的诗句,而 T = 1.5 T = 1.5 T=1.5 的 Temperature 采样可能带来意外的意象。
随机采样
纯随机采样(均匀分布)生成的文本完全不可控,缺乏语义连贯性。Temperature 采样通过 T T T 的调节,既能引入随机性,又能保留模型的语言能力。例如, T = 2 T = 2 T=2 时虽增加多样性,但仍基于模型预测,而非完全随机。
Top-k 和 Top-p 采样
Top-k 采样保留前 k k k 个高概率词,Top-p 采样基于累积概率阈值 p p p。这两种方法与 Temperature 互补:Top-k/p 限制候选范围,Temperature 调整分布形状。例如, T = 0.8 T = 0.8 T=0.8 结合 k = 50 k = 50 k=50 可生成既准确又有一定多样性的文本,而单独使用任一方法可能过于受限或随机。
对比分析
从数学角度看,Temperature 通过指数缩放直接作用于 logits,而 Top-k/p 通过截断候选集间接调整分布。束搜索则关注序列级优化,三者目标不同但可协同工作。例如,在新闻生成中, T = 0.7 T = 0.7 T=0.7 + Top-p = 0.9 + 束搜索宽度 5 的组合,能生成逻辑清晰且多样化的报道。
三、从 Softmax 到 Temperature
在生成式 AI 模型中,Softmax 函数和 Temperature(温度) 是文本生成的核心组件。Softmax 将模型输出的原始分数(logits)转化为概率分布,而 Temperature 则通过调节这些概率的形状,控制生成的随机性与多样性。本节将深入探讨 Softmax 的数学基础、Temperature 的介入机制及其在实际应用中的作用。

1. Softmax 函数基础
Softmax 函数是机器学习中多分类任务的常用工具,尤其在语言模型中用于将神经网络的输出转化为可解释的概率分布。其核心功能是将一组实数值(logits)映射到 (0, 1) 区间,并确保所有概率之和为 1。
1.1 计算公式
Softmax 的数学表达式为:
P ( i ) = e l o g i t ( i ) ∑ j = 1 n e l o g i t ( j ) P(i) = \frac{e^{logit(i)}}{\sum_{j=1}^{n} e^{logit(j)}} P(i)=∑j=1nelogit(j)elogit(i)
- l o g i t ( i ) logit(i) logit(i):第 i i i 个类别的原始分数,通常由模型最后一层输出。
- n n n:类别总数(如词汇表大小)。
- e l o g i t ( i ) e^{logit(i)} elogit(i):指数运算,将实数映射为正值。
- 分母:归一化项,确保 ∑ i = 1 n P ( i ) = 1 \sum_{i=1}^{n} P(i) = 1 ∑i=1nP(i)=1。
1.2 工作原理
Softmax 的指数特性使其对高分值更敏感。例如,若 l o g i t ( i ) > l o g i t ( j ) logit(i) > logit(j) logit(i)>logit(j),则 e l o g i t ( i ) ≫ e l o g i t ( j ) e^{logit(i)} \gg e^{logit(j)} elogit(i)≫elogit(j),放大原始分数间的差距。这种特性在文本生成中尤为重要,因为它决定了模型对下一个词的“信心”分布。
以一个简单例子说明:假设词汇表有三个词,logits 为
[
2.0
,
1.0
,
0.1
]
[2.0, 1.0, 0.1]
[2.0,1.0,0.1]:
P
(
1
)
=
e
2.0
e
2.0
+
e
1.0
+
e
0.1
≈
0.659
P(1) =\frac{e^{2.0}}{e^{2.0} + e^{1.0} + e^{0.1}} \approx 0.659
P(1)=e2.0+e1.0+e0.1e2.0≈0.659
P
(
2
)
=
e
1.0
e
2.0
+
e
1.0
+
e
0.1
≈
0.242
P(2) = \frac{e^{1.0}}{e^{2.0} + e^{1.0} + e^{0.1}} \approx 0.242
P(2)=e2.0+e1.0+e0.1e1.0≈0.242
P
(
3
)
=
e
0.1
e
2.0
+
e
1.0
+
e
0.1
≈
0.099
P(3) = \frac{e^{0.1}}{e^{2.0} + e^{1.0} + e^{0.1}} \approx 0.099
P(3)=e2.0+e1.0+e0.1e0.1≈0.099
结果显示, P ( 1 ) P(1) P(1) 远高于其他选项,反映了 Softmax 对高分值的偏好。这种分布为后续采样提供了基础。
1.3 数学特性分析
Softmax 的指数运算具有放大效应。若两 logits 相差
Δ
=
l
o
g
i
t
(
i
)
−
l
o
g
i
t
(
j
)
\Delta = logit(i) - logit(j)
Δ=logit(i)−logit(j),则概率比为:
P
(
i
)
P
(
j
)
=
e
l
o
g
i
t
(
i
)
e
l
o
g
i
t
(
j
)
=
e
Δ
\frac{P(i)}{P(j)} = \frac{e^{logit(i)}}{e^{logit(j)}} = e^\Delta
P(j)P(i)=elogit(j)elogit(i)=eΔ
当
Δ
=
1
\Delta = 1
Δ=1 时,
P
(
i
)
P
(
j
)
≈
2.718
\frac{P(i)}{P(j)} \approx 2.718
P(j)P(i)≈2.718;当
Δ
=
2
\Delta = 2
Δ=2 时,
P
(
i
)
P
(
j
)
≈
7.389
\frac{P(i)}{P(j)} \approx 7.389
P(j)P(i)≈7.389。这表明 logits 间的微小差异可能导致概率的显著变化。
此外,Softmax 的输出是对数空间中的线性变换与归一化的结合。若定义
Z
=
∑
j
=
1
n
e
l
o
g
i
t
(
j
)
Z = \sum_{j=1}^{n} e^{logit(j)}
Z=∑j=1nelogit(j) 为配分函数,则:
log
P
(
i
)
=
l
o
g
i
t
(
i
)
−
log
Z
\log P(i) = logit(i) - \log Z
logP(i)=logit(i)−logZ
这揭示了 Softmax 与统计力学中配分函数的联系,为 Temperature 的引入埋下伏笔。
1.4 应用场景
在文本生成中,Softmax 通常作用于词汇表大小的 logits。例如,GPT 模型在预测下一个词时,输出维度可能为 50,000(词汇表大小),Softmax 将其转化为概率分布。若不加干预,模型可能倾向于选择概率最高的词(如贪心解码),但这限制了多样性。
2. Temperature 的引入
Temperature 是一个超参数,通过缩放 logits 修改 Softmax 的输出分布,从而控制生成的随机性。其公式为:
P ′ ( i ) = e l o g i t ( i ) T ∑ j = 1 n e l o g i t ( j ) T P'(i) = \frac{e^{\frac{logit(i)}{T}}}{\sum_{j=1}^{n} e^{\frac{logit(j)}{T}}} P′(i)=∑j=1neTlogit(j)eTlogit(i)
其中 T > 0 T > 0 T>0,称为温度参数。
2.1 作用机制
Temperature 通过改变 logits 的相对大小,调整概率分布的平滑度:
- T = 1 T = 1 T=1:标准 Softmax,保持原始分布。例如,上例中 P ( 1 ) = 0.659 P(1) = 0.659 P(1)=0.659, P ( 2 ) = 0.242 P(2) = 0.242 P(2)=0.242, P ( 3 ) = 0.099 P(3) = 0.099 P(3)=0.099。
-
T
<
1
T < 1
T<1:缩小 logits 差异,分布更尖锐,高概率选项被放大。例如,
T
=
0.5
T = 0.5
T=0.5:
P ′ ( 1 ) = e 2.0 0.5 e 2.0 0.5 + e 1.0 0.5 + e 0.1 0.5 ≈ 0.999 P'(1) = \frac{e^{\frac{2.0}{0.5}}}{e^{\frac{2.0}{0.5}} + e^{\frac{1.0}{0.5}} + e^{\frac{0.1}{0.5}}} \approx 0.999 P′(1)=e0.52.0+e0.51.0+e0.50.1e0.52.0≈0.999
P ′ ( 2 ) ≈ 0.001 , P ′ ( 3 ) ≈ 0.000 P'(2) \approx 0.001, \quad P'(3) \approx 0.000 P′(2)≈0.001,P′(3)≈0.000 -
T
>
1
T > 1
T>1:放大 logits 差异,分布更平滑,低概率选项机会增加。例如,
T
=
2
T = 2
T=2:
P ′ ( 1 ) = e 2.0 2 e 2.0 2 + e 1.0 2 + e 0.1 2 ≈ 0.442 P'(1) = \frac{e^{\frac{2.0}{2}}}{e^{\frac{2.0}{2}} + e^{\frac{1.0}{2}} + e^{\frac{0.1}{2}}} \approx 0.442 P′(1)=e22.0+e21.0+e20.1e22.0≈0.442
P ′ ( 2 ) ≈ 0.302 , P ′ ( 3 ) ≈ 0.256 P'(2) \approx 0.302, \quad P'(3) \approx 0.256 P′(2)≈0.302,P′(3)≈0.256
2.2 数学推导
Temperature 的作用可通过指数项的缩放分析。若原始 logits 差异为
Δ
\Delta
Δ,则引入
T
T
T 后:
P
′
(
i
)
P
′
(
j
)
=
e
l
o
g
i
t
(
i
)
−
l
o
g
i
t
(
j
)
T
=
e
Δ
T
\frac{P'(i)}{P'(j)} = e^{\frac{logit(i) - logit(j)}{T}} = e^{\frac{\Delta}{T}}
P′(j)P′(i)=eTlogit(i)−logit(j)=eTΔ
- 当 T T T 减小(如 T = 0.5 T = 0.5 T=0.5), Δ T \frac{\Delta}{T} TΔ 增大,概率比迅速放大。
- 当 T T T 增大(如 T = 2 T = 2 T=2), Δ T \frac{\Delta}{T} TΔ 减小,概率比趋于平缓。
极限情况下:
- T → 0 T \to 0 T→0: l o g i t ( i ) T → ∞ \frac{logit(i)}{T} \to \infty Tlogit(i)→∞(若 l o g i t ( i ) = max logit(i) = \max logit(i)=max)或 0 0 0(其他),分布退化为独热向量,等效于贪心解码。
- T → ∞ T \to \infty T→∞: l o g i t ( i ) T → 0 \frac{logit(i)}{T} \to 0 Tlogit(i)→0, P ′ ( i ) → 1 n P'(i) \to \frac{1}{n} P′(i)→n1,即均匀分布。
这种数学特性使 Temperature 成为调节随机性的强大工具。
2.3 应用示例
- 低 Temperature( T = 0.5 T = 0.5 T=0.5):在问答系统中,输入“1+1等于多少?”,输出“1+1等于2”,确保准确性。
- 默认 Temperature( T = 1 T = 1 T=1):在对话中,输入“今天天气如何?”,输出“我无法查天气,但这个季节可能温暖,建议查看预报”,自然且合理。
- 高 Temperature( T = 1.5 T = 1.5 T=1.5):在诗歌生成中,输入“写一首关于月亮的诗”,输出“月亮悬在云端,洒下银辉,夜风低语它的秘密”,富有创意。
2.4 与其他方法的关联
Temperature 与 Top-k、Top-p 采样结合时效果更佳。例如:
- Top-k:保留前 k k k 个高概率词, T = 0.7 T = 0.7 T=0.7 可进一步聚焦高置信选项。
- Top-p:基于累积概率 p p p 截断, T = 1.2 T = 1.2 T=1.2 可增加多样性而不失相关性。
3. Softmax 与 Temperature 的协同作用
Softmax 提供概率基础,Temperature 赋予其动态调整能力。二者结合使模型能在不同任务间切换:
- 高确定性任务(如代码生成): T = 0.3 T = 0.3 T=0.3,输出规范代码片段。
- 创意任务(如故事创作): T = 1.3 T = 1.3 T=1.3,生成新颖情节。
- 平衡任务(如新闻报道): T = 1 T = 1 T=1,兼顾准确性与可读性。
3.1 实际案例
在 GPT-3 中,生成新闻标题时, T = 0.9 T = 0.9 T=0.9 可能输出“当地发生交通事故”,而 T = 1.5 T = 1.5 T=1.5 可能输出“车流中突现意外奇闻”,风格迥异但各有适用场景。
3.2 局限性与改进
- 局限性: T T T 过低导致重复,过高导致无序。
- 改进:引入自适应 T T T,根据上下文动态调整。
Softmax 与 Temperature 的结合为文本生成提供了从确定性到随机性的光谱控制,其数学优雅性和实用性使其成为生成式 AI 的基石。
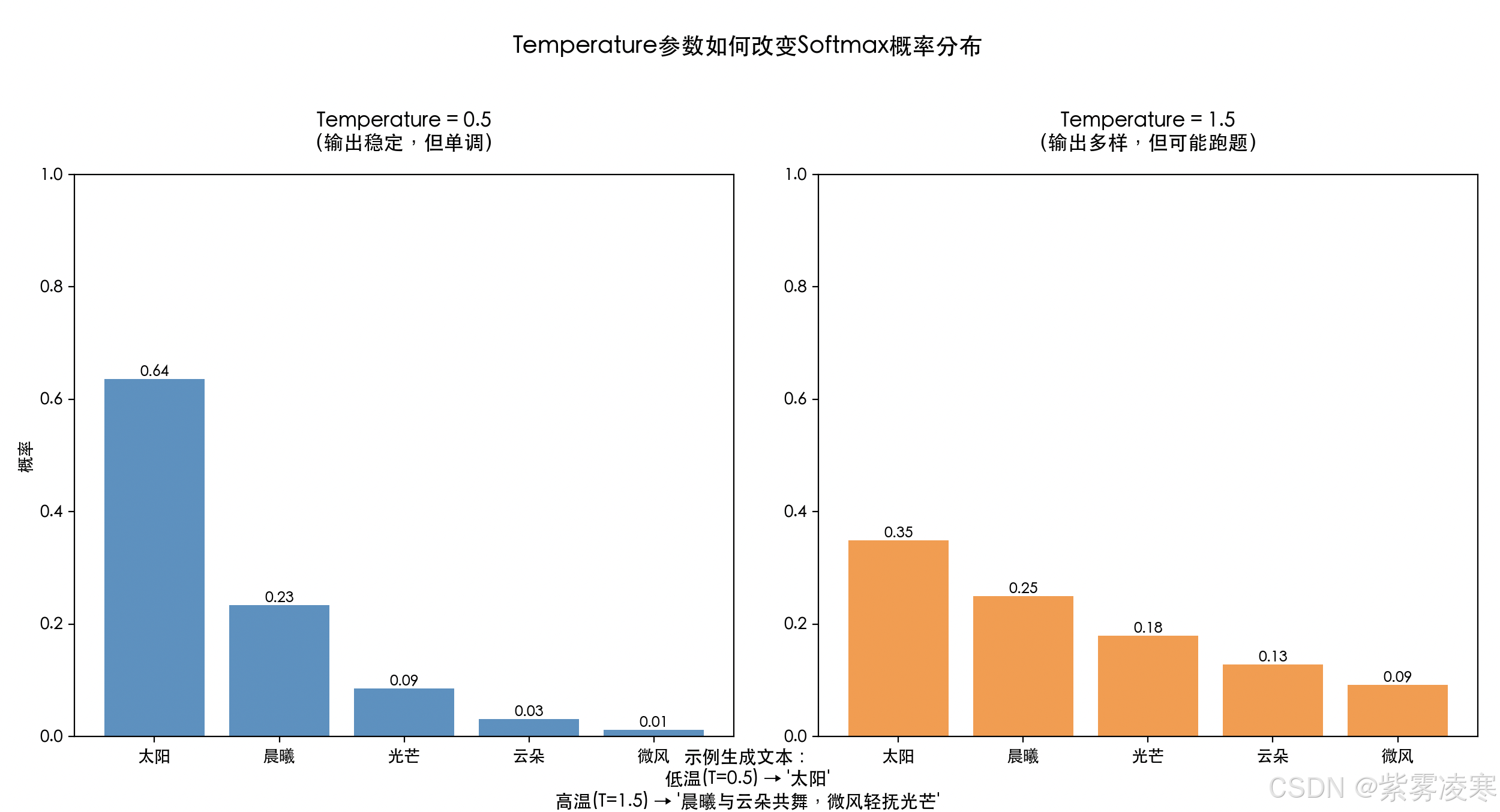
四、Temperature 值的效果
1. 趋近于 0:高度确定性
当 T T T 接近 0,模型几乎只选择概率最高的词,生成文本高度一致。例如:
- 输入:“一年有几个季节?”
- 输出:“一年有四个季节。”
这种稳定性适合需要精确输出的场景,如数学计算或事实性问答。但多样性不足,难以应对开放性任务。
应用案例
在法律文档生成中, T = 0.2 T = 0.2 T=0.2 可确保条款表述规范,避免歧义。
2. 默认值 1:平衡输出
T = 1 T = 1 T=1 是默认设置,生成文本兼具逻辑性与自然性。例如:
- 输入:“今天天气如何?”
- 输出:“我无法查看实时天气,但这个季节通常温暖,可能有微风,建议查阅天气预报。”
适用于对话系统、新闻撰写等场景。
应用案例
在产品描述生成中, T = 1 T = 1 T=1 可生成既有信息量又自然的文本。
3. 大于 1:创意提升
T > 1 T > 1 T>1 增加低概率词的机会,激发创造性。例如, T = 1.5 T = 1.5 T=1.5 生成的诗歌:
- 输入:“写一首关于秋天的诗。”
- 输出:“秋天染红枫叶,金色稻田铺展,风声诉说丰收。”
适合创意任务,但需注意逻辑性可能下降。
应用案例
在广告文案中, T = 1.2 T = 1.2 T=1.2 可生成独特且吸引人的标语。
4. 过高值:随机性过强
T T T 过高(如 2.0)时,文本可能失去连贯性。例如:
- 输入:“描述自然风光。”
- 输出:“太阳跳跃,河流画彩虹,山峰融化。”
这种输出在艺术实验中或有价值,但在实用场景中效果不佳。
五、与其他采样策略的结合
1. 与 Top-p(核采样)结合
Top-p 采样基于累积概率阈值 p p p 选择词集,与 Temperature 结合可优化生成质量。例如, T = 1.0 T = 1.0 T=1.0, p = 0.9 p = 0.9 p=0.9:
- 输入:“神秘森林里住着……”
- 输出:“神秘森林里住着一只会讲故事的松鼠,述说古老传说。”
兼顾创意与相关性。
2. 与 Top-k 结合
Top-k 采样保留前 k k k 个高概率词。例如, T = 0.7 T = 0.7 T=0.7, k = 20 k = 20 k=20:
- 输入:“某地区发生了一起……”
- 输出:“某地区发生了一起交通事故,轿车与卡车相撞,造成拥堵。”
适合需逻辑严谨的场景。
六、应用场景与调优策略
1. 应用场景
在实际应用中,Temperature 的取值需依不同场景和任务灵活调整。
- 代码生成:场景中准确性和规范性重要,Temperature 常设 0.2 − 0.5 0.2 - 0.5 0.2−0.5,可使模型生成常见、符合语法规范代码,降低错误,如生成 Python 函数。过高则易生成不符实际需求代码,增加调试成本。
- 对话系统:自然流畅和相关性是关键,Temperature 一般设 0.7 − 1.0 0.7 - 1.0 0.7−1.0,保证对话自然且回复与提问紧密相关,如智能客服场景。
- 诗歌创作:追求独特创意和丰富想象力,Temperature 设 1.0 − 1.5 1.0 - 1.5 1.0−1.5,激发模型创造力,创作出富有意境和艺术感的诗歌。
- 故事创作:希望故事有趣味、创新且具逻辑性和连贯性,Temperature 通常设 0.8 − 1.2 0.8 - 1.2 0.8−1.2,能创造新奇情节等,又保证故事逻辑清晰 。
2. 调优策略
为更好发挥 Temperature 的作用,可采用以下调优策略:
- 分阶段调参:新任务开始先用默认值(通常为 T = 1 T = 1 T=1)生成文本,观察结果。若文本保守缺创意,每次提高 0.1 − 0.2 0.1 - 0.2 0.1−0.2;若过于随机缺逻辑,每次降低 0.1 − 0.2 0.1 - 0.2 0.1−0.2 ,以此找到合适值。
- 动态自适应:实时应用场景,如对话系统或交互式写作工具,根据用户输入和上下文动态调温 T T T。提问模糊开放时提高,提问具体明确时降低,以适应不同需求和场景。
- 结合评估指标:调温时结合连贯性、相关性、多样性等评估指标衡量文本质量。可人工评估,也可用 BLEU、ROUGE 等自动评估工具。根据结果针对性调温,如连贯性差就降低,多样性不足就提高,以此优化生成效果。
七、Temperature 的局限性与改进
1. 局限性
- 高 T T T 下逻辑性下降。
- 低 T T T 缺乏多样性。
2. 改进方向
- 结合上下文自适应 T T T。
- 引入多层次采样策略。
八、总结与展望
Temperature 采样原理是生成式 AI 模型核心技术,能通过调节 Temperature 值把控文本随机性与多样性,在不同场景展现优势。实际应用时,要依任务需求和文本特性选值,结合其他采样策略,还可采用多种调优策略优化模型。未来,它有望在智能教育、智能客服、艺术创作等领域广泛应用,但也面临提升文本逻辑性连贯性、保障数据隐私安全等挑战。Temperature 采样原理潜力巨大,随着技术进步,将在各领域发挥关键作用,为生活工作带来便利惊喜。
延伸阅读




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











