










一、技术亮点:构建代码智能的基石
1.1 模型架构创新
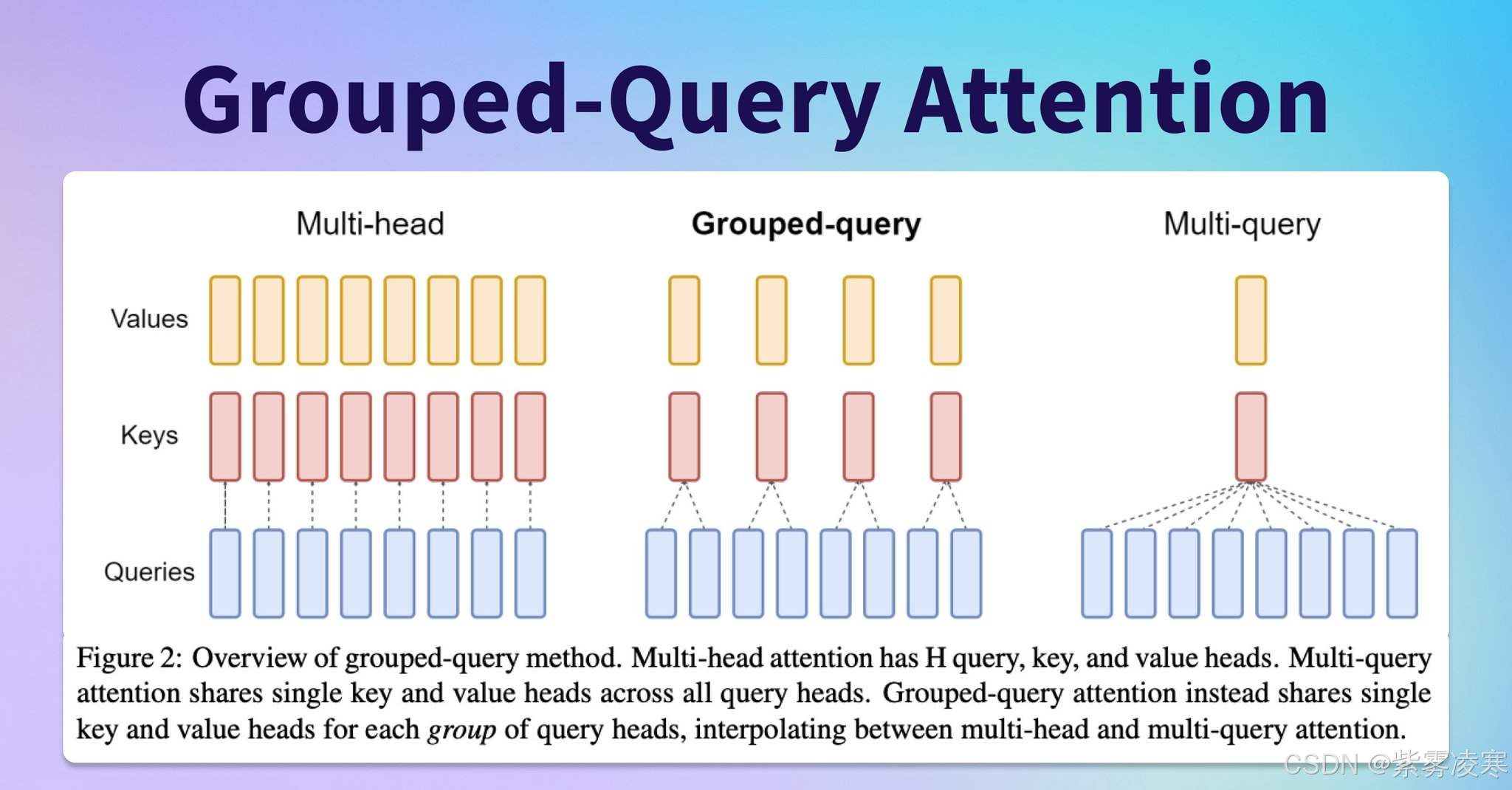
StarCoder2 在模型架构上的创新是其成为代码生成领域佼佼者的关键。它采用了 Grouped Query Attention 机制,通过将注意力查询分组,有效降低了计算复杂度 O ( n 2 ) O(n^2) O(n2),使得模型在处理长序列代码时能够高效分配资源,同时保持对长序列的处理能力。这种机制极大地提升了处理长代码段的 准确性与效率。
此外,StarCoder2 结合了 16,384 个 token 的超长上下文窗口 和 4 , 096 4,096 4,096 个 token 的滑动窗口注意力,突破了传统模型的上下文限制。这使得模型在生成代码时能更好地理解前文语境,生成逻辑更连贯的代码。基于 Transformer 架构的改进设计,不仅继承了其在自然语言处理中的优势,还针对代码特点进行了优化,支持 600+ 编程语言 的多模态训练,赋予模型跨语言生成能力。
1.2 训练数据与能力突破
StarCoder2 在训练数据上投入巨大,使用 Stack v2 数据集 完成了 3.3 × 1 0 12 3.3 \times 10^{12} 3.3×1012 至 4.3 × 1 0 12 4.3 \times 10^{12} 4.3×1012 个 token 的训练,涵盖 GitHub、Stack Overflow 等平台的代码和问答数据。这些多样化数据赋予模型丰富的编程风格与问题解决能力。
通过 Fill-in-the-Middle 训练目标,StarCoder2 提升了代码生成的逻辑连贯性。这种方法让模型专注于预测未完成代码行,增强了对代码结构的理解。在 HumanEval 基准测试中,StarCoder2 取得了 40.8% 的 Pass@1 准确率,超越开源模型 CodeGen-16B-Mono,显著提高了开发效率。
二、核心功能:开发者的全能助手
2.1 代码生成与补全
StarCoder 的代码生成与补全功能是其核心亮点。开发者只需输入自然语言描述,例如 “创建一个 Flask 框架的登录 API,连接 MySQL”,即可快速生成相应的 Python 代码框架。在集成开发环境(如 VS Code)中,StarCoder 的 实时补全功能 可根据上下文提供智能建议,提升编码速度约 30%。
2.2 多语言代码翻译
StarCoder 支持 619 种编程语言 的跨语言转换。例如,将 Python 数据处理脚本转换为 Java,或将 C++ 高性能模块转为 Go 语言,模型都能保持代码逻辑一致。在 MultiPL-E 评测中,其性能优于 OpenAI 的 code-cushman-001。
2.3 代码优化与调试
StarCoder 可优化代码性能,例如通过分析 DS-1000 数据科学基准,找出循环冗余等问题,优化后的代码响应时间提升 50%。在调试中,它还能根据错误信息提供解决方案建议。
三、应用场景:重塑开发流程
3.1 企业级开发提效
某金融企业在微服务开发中引入 StarCoder,生成 70% 的基础架构代码,项目周期缩短 30%,显著提升了效率与代码一致性。
3.2 编程教育革新
StarCoder 为初学者提供实时代码解释与错误诊断,结合 Stack Exchange 数据实现交互式辅导,生成的代码注释率达 85%,降低学习难度。
3.3 开源生态构建
通过 BigCode Open RAIL-M 许可证,StarCoder 支持商业应用,并与 Hugging Face、GitHub 深度集成,推动开源社区发展。
四、竞争优势与发展展望
4.1 对比优势分析
StarCoder2-15B( 15 × 1 0 9 15 \times 10^9 15×109 参数)在语言支持(600+)与上下文窗口( 16 , 384 16,384 16,384 tokens)上优于 CodeGeeX2-6B(6 种语言, 8 , 192 8,192 8,192 tokens),HumanEval 得分达 40.8%,远超 CodeLlama-13b-Python 的 30.5%。
4.2 未来演进方向
未来,StarCoder 计划新增 200+ 小众语言支持,通过 StarPii 技术实现 PII 检测率 99.9%,并推出量化版本适配边缘计算。
五、开发者指南:快速上手实践
5.1 安装与配置
使用 StarCoder,首先需要进行安装和配置。以在 Python 环境中使用为例,安装过程较为简便,只需通过 pip 安装相关依赖包。
pip install -r requirements.txt
对于不同的运行环境,如 CPU、GPU,有不同的配置要点。若使用 GPU 加速,需要确保 CUDA 和 cuDNN 等相关驱动和库已正确安装,并且版本与所使用的深度学习框架兼容。在代码中,可以通过如下方式指定设备:
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
这样,模型在运行时会自动选择可用的 GPU 设备,以提高运行效率。同时,还需要根据实际的硬件资源,如内存大小,合理调整模型的参数设置,以避免因资源不足导致运行失败 。
5.2 代码生成示例
在实际使用中,通过 Python 代码调用 StarCoder 进行代码生成的过程并不复杂。以下是一个简单的示例,展示如何使用它生成 Python 代码:
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "bigcode/starcoder"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)
# 输入提示
input_prompt = "def calculate_sum(a, b):"
inputs = tokenizer.encode(input_prompt, return_tensors="pt").to(device)
# 生成代码
outputs = model.generate(inputs)
generated_code = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_code)
在这个示例中,首先从 transformers 库中导入必要的类,然后加载 StarCoder 模型和对应的分词器。通过定义一个输入提示input_prompt,描述要生成的代码功能,这里是定义一个计算两个数之和的函数。使用 tokenizer.encode 将输入提示编码为模型可接受的格式,再通过 model.generate 生成代码。最后,使用 tokenizer.decode 将生成的代码解码并打印出来 。
5.3 常见问题与解决
在使用过程中,可能会遇到一些常见问题。比如,模型生成的代码不符合预期,这可能是由于输入提示不够清晰准确导致的。在这种情况下,需要优化输入提示,提供更多的上下文信息和明确的要求,以引导模型生成更符合需求的代码 。
如果遇到运行时错误,如内存不足或依赖包版本不兼容,需要检查硬件资源和依赖包的版本。可以通过升级或降级相关依赖包来解决版本兼容性问题,对于内存不足的情况,可以尝试减小模型的批量大小,或者使用分布式计算来分摊负载。此外,还可以参考官方文档和社区论坛,获取更多的解决方案和经验分享,以快速解决遇到的问题,确保开发工作的顺利进行 。
六、总结
StarCoder 凭借 150 亿参数的超大规模、多语言支持和企业级优化,已成为代码生成领域的标杆模型。随着 DS-1000 等垂直领域优化和边缘部署能力的提升,其在金融、教育、开源社区等场景的应用将持续深化。开发者可通过 GitHub 获取完整工具链,共同推动代码智能的革新进程。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











