







一.基本正则表达式
re模块
导入re模块:
import repython通过re模块提供对正则表达式的支持。
(1)常用方法:findall,search,sub
findall: 匹配所有符合规律的内容,返回包含结果的列表
Search:匹配并提取第一个符合规律的内容,返回一个正则表达式对象(object)
Sub:替换符合规律的内容,返回替换后的值
(2)常用符号:点号,星号,问号与括号
. : 匹配任意字符,换行符\n除外
* :匹配前一个字符0次或无限次
? :匹配前一个字符0次或1次
.*:贪心算法
.*?:非贪心算法
():括号内的数据作为结果返回
(3)常用情况
使用findall与search从大量文本中匹配感兴趣的内容
使用sub实现换页功能
二.Http网络请求
requests模块
Requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。
导入requests模块:
import requests基本Get请求:
#-*- coding:utf-8 -*- //定义编码为utf-8,避免显示乱码
import requests
url = 'http://www.baidu.com'
r = requests.get(url) //使用requests模块的get方法获取百度首页的源代码
print r.text这里只举例了我们要使用的基本的get请求,如果需要了解更多的requests模块的方法请自行百度。
三.实例代码
目的:爬取湖南农业大学官网中心位置的三张图片,并且下载下来
1.获取图片的源代码
使用chrome打开农大官网,右键审查元素,然后点击左上角的放大镜,点击图片就会定位到图片的源代码位置,如图所示:
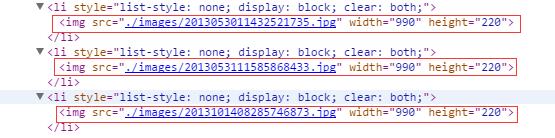
2.分析源代码,写出正则表达式
分析上图可知,我们需要的部分为src=”“中引号里面的url,而三张图片都是相同的格式,所以我们使用re模块的findall方法,将src的中间部分获取到即可:
re.findall(‘img src=”(.*?)” width=”990”’,html.text,re.S)
(1)findall即匹配所有符合正则表达式规则的内容
(2)(.*?)用作获取src=”“的双引号中间的url并返回
(3)re.S的作用是使.的作用范围包括换行符,即可以换行匹配
3.根据获取到的url下载图片
因为我们获取到的url并不是完整的网址,所以右键上图的链接选择Open link in new tab来查看完整的网址,如下图,因此我们在下载图片时需要在url前加上http://www.hunau.edu.cn/。

代码如下:
import re //导入正则表达式的库
import requests //导入第三方http库
html = requests.get("http://www.hunau.edu.cn/") //通过get方法获取农大官网的网页源代码
html.encoding = 'utf-8' //设定编码方式,使能够正常显示中文
# print(html.text) //也可以把网页源代码输出来看一下
homedir = os.getcwd() //获取项目当前路径
os.mkdir(homedir+'\pic') //创建pic文件夹,用于保存图片
pic_url = re.findall('img src="(.*?)" width="990"',html.text,re.S) //设定正则表达式,爬取图片的url
i = 0
for each in pic_url: //遍历pic_url
print 'now downloading:' + each
pic = requests.get("http://www.hunau.edu.cn/"+each) //补充完整的网址,通过get方法获取图片
fp = open('pic\\' + str(i) + '.jpg','wb') //在pic文件夹下创建jpg格式的文件
fp.write(pic.content) //将图片写入到工程文件夹下的pic文件夹中
fp.close()
i += 1文本爬虫,效果如下:
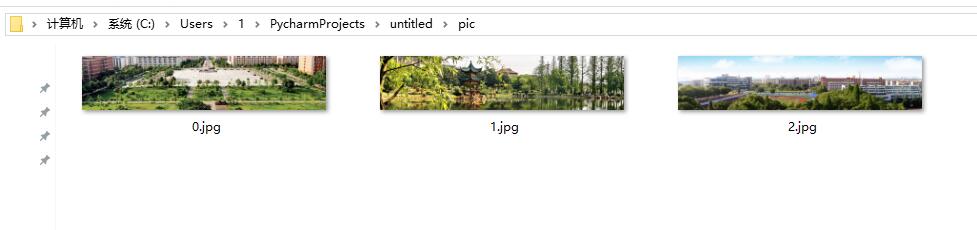
我们在这里只是爬取了三张图片,但是使用python来做网页爬虫真的功能很强大,大家可以试一试修改代码去爬取更多的图片。















 573
573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









