







三文带你轻松上手鸿蒙的AI语音01-实时语音识别
前言
HarmonyOSNext中集成了强大的AI功能。Core Speech Kit(基础语音服务)是它提供的众多AI功能中的一种。
Core Speech Kit(基础语音服务)集成了语音类基础AI能力,包括文本转语音(TextToSpeech)及语音识别(SpeechRecognizer)能
力,便于用户与设备进行互动,实现将实时输入的语音与文本之间相互转换。
简单来讲Core Speech Kit主要提供了两大语音AI功能:
- 语音识别
- 文本转语音
语音识别介绍
语音识别功能可以将一段音频信息(短语音模式不超过60s,长语音模式不超过8h)转换为文本。
其中语音识别又可以实现:
- 实时语音转文本
- 声音文件转文本
实时语音转文本
实现流程
先介绍语音识别的流程,后面的文字转语音大同小异
- 申请权限
- 创建AI语音引擎
- 设置监听回调
- 开始监听
tips: 完整代码在每一个功能的末尾,可以结合封装后的代码来阅读
申请权限

因为在开发功能过程中,需要调用手机的麦克风功能。所以需要主动申请权限。

申请权限分成3个步骤
- 声明权限
- 检查是否拥有权限
- 申请权限
声明权限
-
在
\entry\src\main\module.json5中添加以下配置代码 requestPermissions{ "module": { ... "requestPermissions": [ { "name": "ohos.permission.MICROPHONE", "reason": "$string:voice_reason", "usedScene": { "abilities": [ "FormAbility" ], "when": "always" } } ], } } -
在
\entry\src\main\resources\base\element\string.json添加 申请原因voice_reason{ "string": [ { "name": "module_desc", "value": "module description" }, { "name": "EntryAbility_desc", "value": "description" }, { "name": "EntryAbility_label", "value": "label" }, { "name": "voice_reason", "value": "用于获取用户的录音" } ] }
检查权限
实际开发中,我们在申请权限之前可以先调用接口checkAccessTokenSync,检查下是否已经拥有权限。如果没有,则主动申请权限
申请权限
当我们需要申请某个功能的权限时,可以通过调用 requestPermissionsFromUser 来实现
封装好的权限代码
因为HarmonyOSNext中关于权限的代码,都是没有经过封装的,难以使用。所以这里提供了封装好的版本。
没有封装过的示例代码:
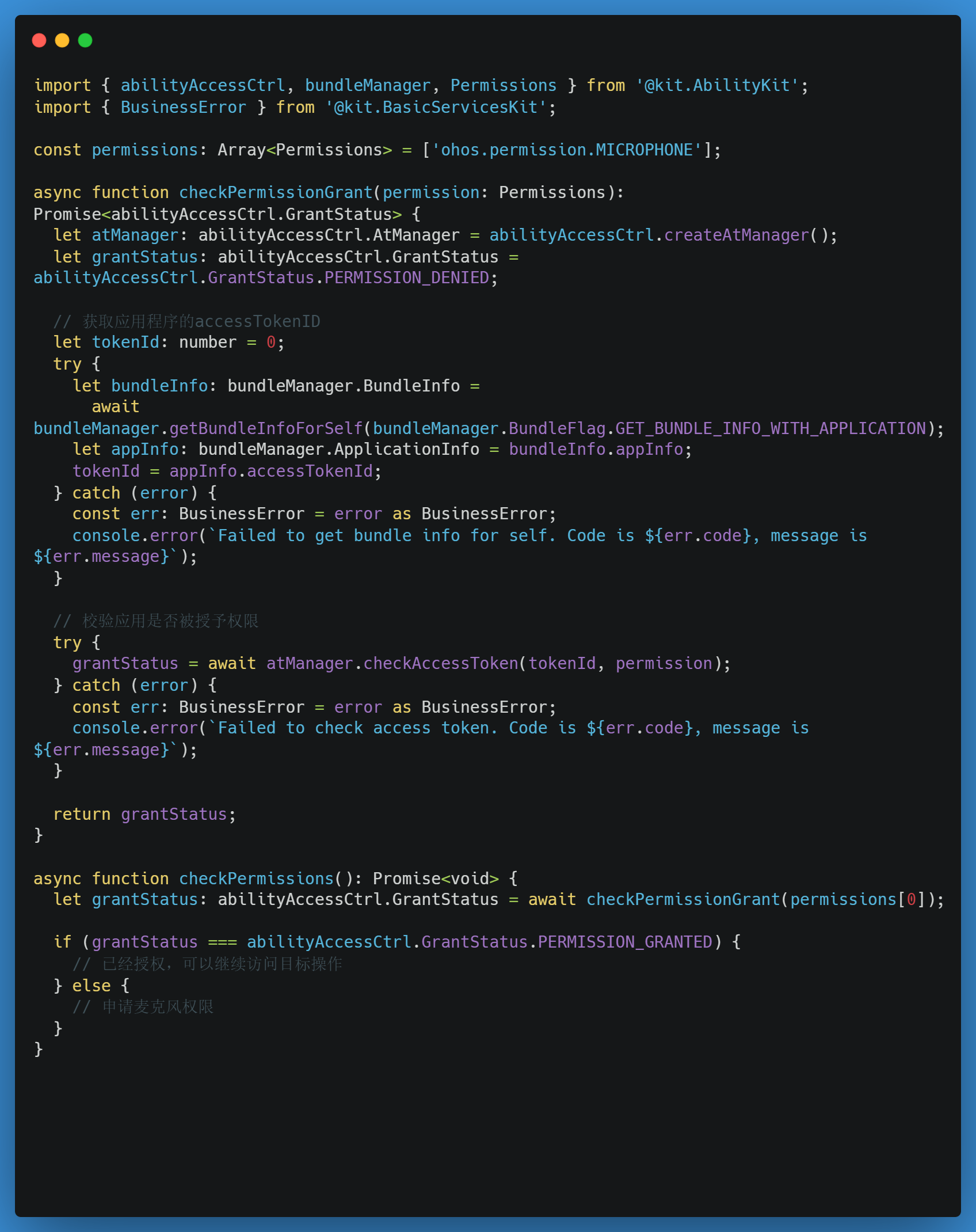
封装好的代码
entry\src\main\ets\utils\permissionMananger.ets
// 导入必要的模块,包括权限管理相关的功能
import { abilityAccessCtrl, bundleManager, common, Permissions } from '@kit.AbilityKit';
export class PermissionManager {
// 静态方法用于检查给定的权限是否已经被授予
static checkPermission(permissions: Permissions[]): boolean {
// 创建一个访问令牌管理器实例
let atManager: abilityAccessCtrl.AtManager = abilityAccessCtrl.createAtManager();
// 初始化tokenID为0,稍后将获取真实的tokenID
let tokenID: number = 0;
// 获取本应用的包信息
const bundleInfo =
bundleManager.getBundleInfoForSelfSync(bundleManager.BundleFlag.GET_BUNDLE_INFO_WITH_APPLICATION);
// 设置tokenID为应用的访问令牌ID
tokenID = bundleInfo.appInfo.accessTokenId;
// 如果没有传入任何权限,则返回false表示没有权限
if (permissions.length === 0) {
return false;
} else {
// 检查所有请求的权限是否都被授予
return permissions.every(permission =>
abilityAccessCtrl.GrantStatus.PERMISSION_GRANTED ===
atManager.checkAccessTokenSync(tokenID, permission)
);
}
}
// 异步静态方法用于请求用户授权指定的权限
static async requestPermission(permissions: Permissions[]): Promise<boolean> {
// 创建一个访问令牌管理器实例
let atManager: abilityAccessCtrl.AtManager = abilityAccessCtrl.createAtManager();
// 获取上下文(这里假设getContext是一个可以获取到UI能力上下文的方法)
let context: Context = getContext() as common.UIAbilityContext;
// 请求用户授权指定的权限
const result = await atManager.requestPermissionsFromUser(context, permissions);
// 检查请求结果是否成功(authResults数组中每个元素都应该是0,表示成功)
return !!result.authResults.length && result.authResults.every(authResults => authResults === 0);
}
}
页面中使用权限代码
Index.ets
import { PermissionManager } from '../utils/permissionMananger'
import { Permissions } from '@kit.AbilityKit'
@Entry
@Component
struct Index {
// 1 申请权限
fn1 = async () => {
// 准备好需要申请的权限 麦克风权限
const permissions: Permissions[] = ["ohos.permission.MICROPHONE"]
// 检查是否拥有权限
const isPermission = await PermissionManager.checkPermission(permissions)
if (!isPermission) {
// 如果没权限,就主动申请
PermissionManager.requestPermission(permissions)
}
}
build() {
Column() {
Button("申请权限")
.onClick(this.fn1)
}
.width("100%")
.height("100%")
.justifyContent(FlexAlign.Center)
}
}

实时语音识别相关步骤
以下主要实现实时语音识别
创建AI语音引擎
创建AI语音引擎主要有以下几个步骤
-
声明AI语音引擎配置参数,主要有语种、区域信息等
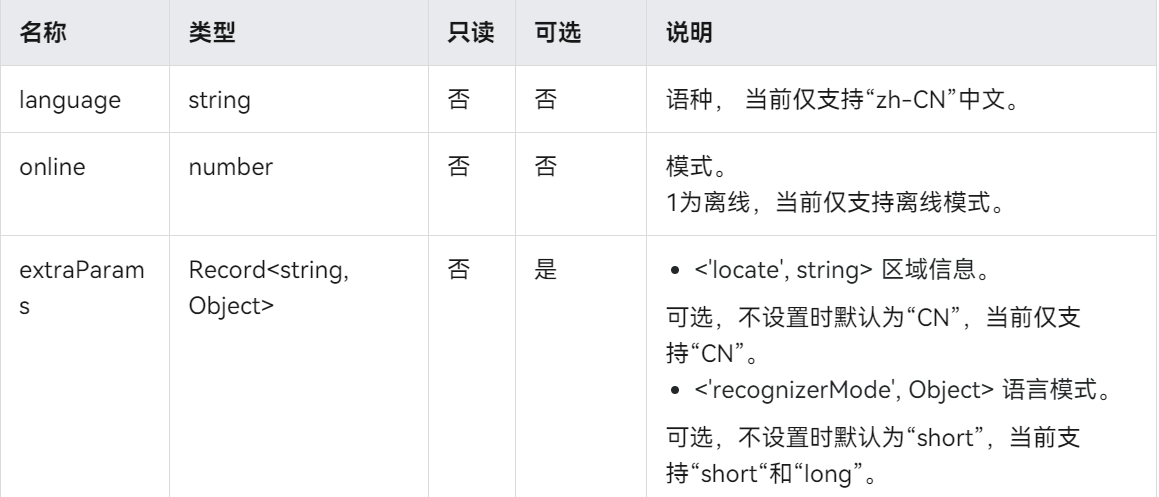
-
调用开始创建
createEngine方法开始创建,并且返回 AI语音实例引擎
设置AI语音监听回调
在开始语音识别之前,需要先设置语音识别回调 setListener 。它主要有以下几个分类
- 开始识别回调
- 事件回调
- 识别结果回调
- 识别完成回调
- 识别错误回调
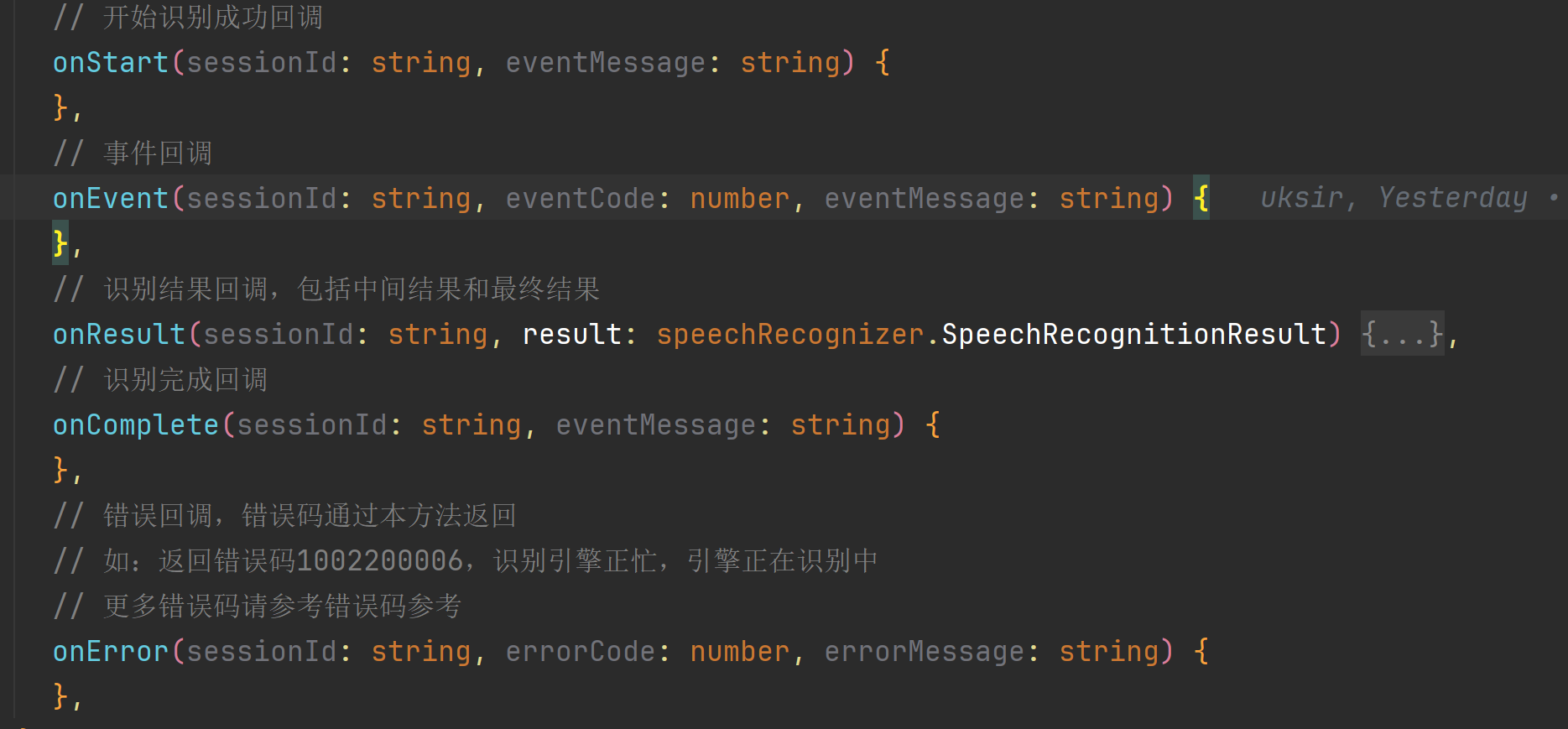
开始监听实时语音
需要先配置监听的参数,便可以调用startListening实现语音识别了
参数配置 其中,实时语音识别和语音文件识别的主要配置在 recognitionMode 字段, 0 表示实时语音识别
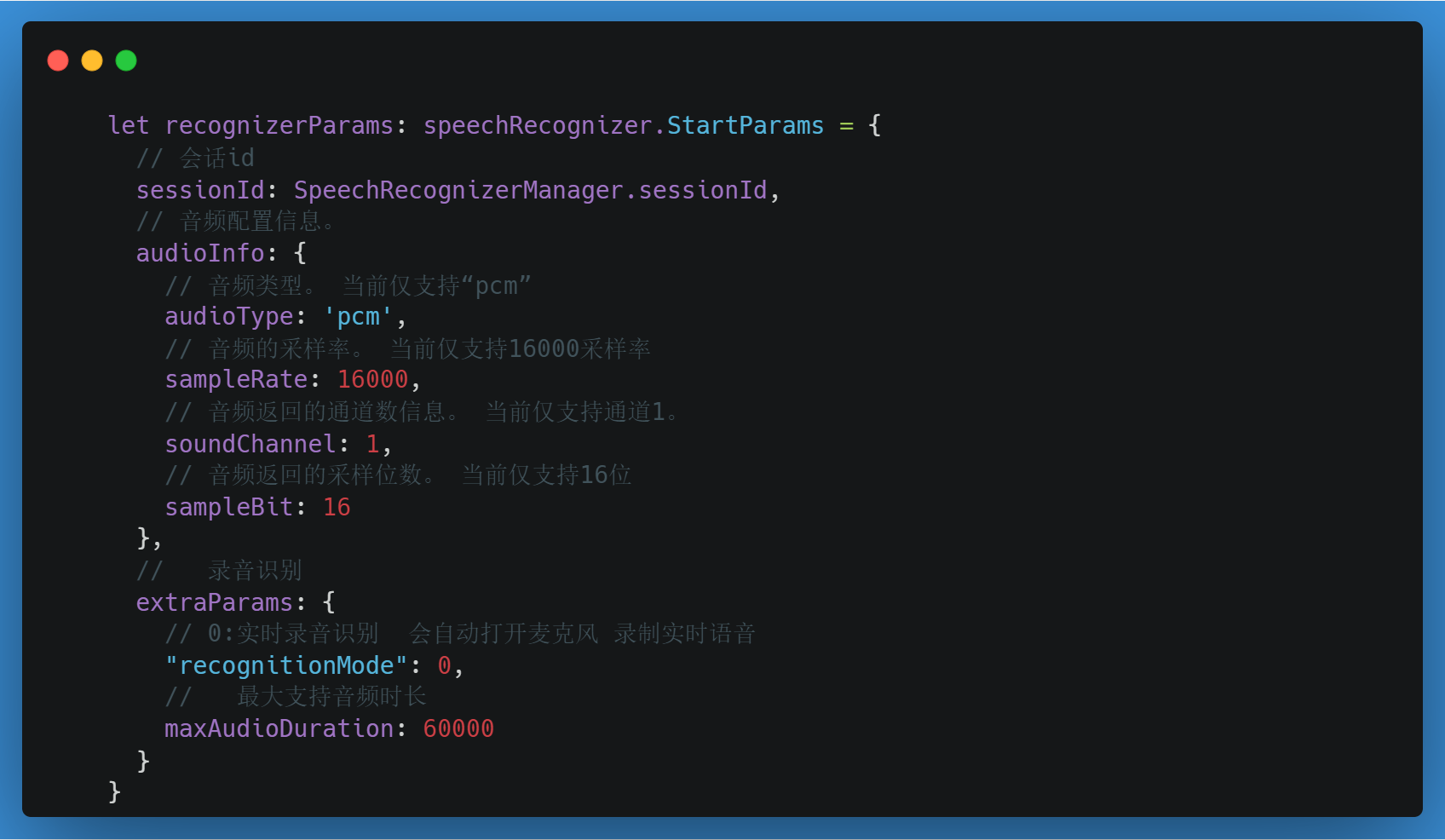
封装好的语音识别代码
\entry\src\main\ets\utils\SpeechRecognizerManager.ets
import { speechRecognizer } from '@kit.CoreSpeechKit';
class SpeechRecognizerManager {
/**
* 语种信息
* 语音模式:长
*/
private static extraParam: Record<string, Object> = { "locate": "CN", "recognizerMode": "long" };
private static initParamsInfo: speechRecognizer.CreateEngineParams = {
/**
* 地区信息
* */
language: 'zh-CN',
/**
* 离线模式:1
*/
online: 1,
extraParams: this.extraParam
};
/**
* 引擎
*/
private static asrEngine: speechRecognizer.SpeechRecognitionEngine | null = null
/**
* 录音结果
*/
static speechResult: speechRecognizer.SpeechRecognitionResult | null = null
/**
* 会话ID
*/
private static sessionId: string = "asr" + Date.now()
/**
* 创建引擎
*/
private static async createEngine() {
// 设置创建引擎参数
SpeechRecognizerManager.asrEngine = await speechRecognizer.createEngine(SpeechRecognizerManager.initParamsInfo)
}
/**
* 设置回调
*/
private static setListener(callback: (srr: speechRecognizer.SpeechRecognitionResult) => void = () => {
}) {
// 创建回调对象
let setListener: speechRecognizer.RecognitionListener = {
// 开始识别成功回调
onStart(sessionId: string, eventMessage: string) {
},
// 事件回调
onEvent(sessionId: string, eventCode: number, eventMessage: string) {
},
// 识别结果回调,包括中间结果和最终结果
onResult(sessionId: string, result: speechRecognizer.SpeechRecognitionResult) {
SpeechRecognizerManager.speechResult = result
callback && callback(result)
},
// 识别完成回调
onComplete(sessionId: string, eventMessage: string) {
},
// 错误回调,错误码通过本方法返回
// 如:返回错误码1002200006,识别引擎正忙,引擎正在识别中
// 更多错误码请参考错误码参考
onError(sessionId: string, errorCode: number, errorMessage: string) {
},
}
// 设置回调
SpeechRecognizerManager.asrEngine?.setListener(setListener);
}
/**
* 开始监听
* */
static startListening() {
// 设置开始识别的相关参数
let recognizerParams: speechRecognizer.StartParams = {
// 会话id
sessionId: SpeechRecognizerManager.sessionId,
// 音频配置信息。
audioInfo: {
// 音频类型。 当前仅支持“pcm”
audioType: 'pcm',
// 音频的采样率。 当前仅支持16000采样率
sampleRate: 16000,
// 音频返回的通道数信息。 当前仅支持通道1。
soundChannel: 1,
// 音频返回的采样位数。 当前仅支持16位
sampleBit: 16
},
// 录音识别
extraParams: {
// 0:实时录音识别 会自动打开麦克风 录制实时语音
"recognitionMode": 0,
// 最大支持音频时长
maxAudioDuration: 60000
}
}
// 调用开始识别方法
SpeechRecognizerManager.asrEngine?.startListening(recognizerParams);
};
/**
* 取消识别
*/
static cancel() {
SpeechRecognizerManager.asrEngine?.cancel(SpeechRecognizerManager.sessionId)
}
/**
* 释放ai语音转文字引擎
*/
static shutDown() {
SpeechRecognizerManager.asrEngine?.shutdown()
}
/**
* 停止并且释放资源
*/
static async release() {
SpeechRecognizerManager.cancel()
SpeechRecognizerManager.shutDown()
}
/**
* 初始化ai语音转文字引擎
*/
static async init(callback: (srr: speechRecognizer.SpeechRecognitionResult) => void = () => {
}) {
await SpeechRecognizerManager.createEngine()
SpeechRecognizerManager.setListener(callback)
SpeechRecognizerManager.startListening()
}
}
export default SpeechRecognizerManager
页面中调用语音识别代码
import { PermissionManager } from '../utils/permissionMananger'
import { Permissions } from '@kit.AbilityKit'
import SpeechRecognizerManager from '../utils/SpeechRecognizerManager'
@Entry
@Component
struct Index {
@State
text: string = ""
// 1 申请权限
fn1 = async () => {
// 准备好需要申请的权限 麦克风权限
const permissions: Permissions[] = ["ohos.permission.MICROPHONE"]
// 检查是否拥有权限
const isPermission = await PermissionManager.checkPermission(permissions)
if (!isPermission) {
// 如果没权限,就主动申请
PermissionManager.requestPermission(permissions)
}
}
// 2 实时语音识别
fn2 = () => {
SpeechRecognizerManager.init(res => {
console.log("实时语音识别", JSON.stringify(res))
this.text = res.result
})
}
build() {
Column({ space: 10 }) {
Text(this.text)
Button("申请权限")
.onClick(this.fn1)
Button("实时语音识别")
.onClick(this.fn2)
}
.width("100%")
.height("100%")
.justifyContent(FlexAlign.Center)
}
}

语音识别结果分析
语音识别成功后的数据格式如下
实时语音识别 {"isFinal":false,"isLast":false,"result":"是"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的太"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的太多"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的太多"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的太多"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的太多"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的太多"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的太多"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的太多"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的太多"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的太多"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的太多"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的太多"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的太多"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":"是否给你承诺的太多"}
I 实时语音识别 {"isFinal":true,"isLast":false,"result":"是否给你承诺的太多?"}
I 实时语音识别 {"isFinal":false,"isLast":false,"result":""}
其中需要关注的是:
-
识别功能是持续触发的,当收集到声音时持续触发
-
isFinal 表示一个句子是否结束

-
isLast 表示这一次语音识别是否结束
总结
HarmonyOSNext中集成了强大的AI功能。Core Speech Kit(基础语音服务)是它提供的众多AI功能中的一种。
Core Speech Kit(基础语音服务)集成了语音类基础AI能力,包括文本转语音(TextToSpeech)及语音识别(SpeechRecognizer)能
力,便于用户与设备进行互动,实现将实时输入的语音与文本之间相互转换。
简单来讲Core Speech Kit主要提供了两大语音AI功能:
- 语音识别
- 文本转语音
其中语音识别又可以实现:
- 实时语音转文本
- 声音文件转文本
本文主要实现了 实时语音转文本 , 声音文件转文本 将会在下文讲解。



















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











