






编译参数优化
编译参数优化(Compiler Parameter Optimization)是指在编译器将源代码转化为可执行代码的过程中,通过对程序的分析和优化,使得生成的目标代码在执行速度、占用内存等方面都能够达到更好的效果。
以Intel编译器的编译流程为例,在完成前方词法分析、语法分析后,编译器将进行过程间分析优化(主要为对函数调用等过程进行优化)、循环优化(如预取、向量化、循环展开等)、全局标量优化(入冗余消除、死代码消除等)和代码生成(向量化、流水线、全局调度等)。
本文主要介绍Intel编译器所提供的部分常见的编译优化选项。
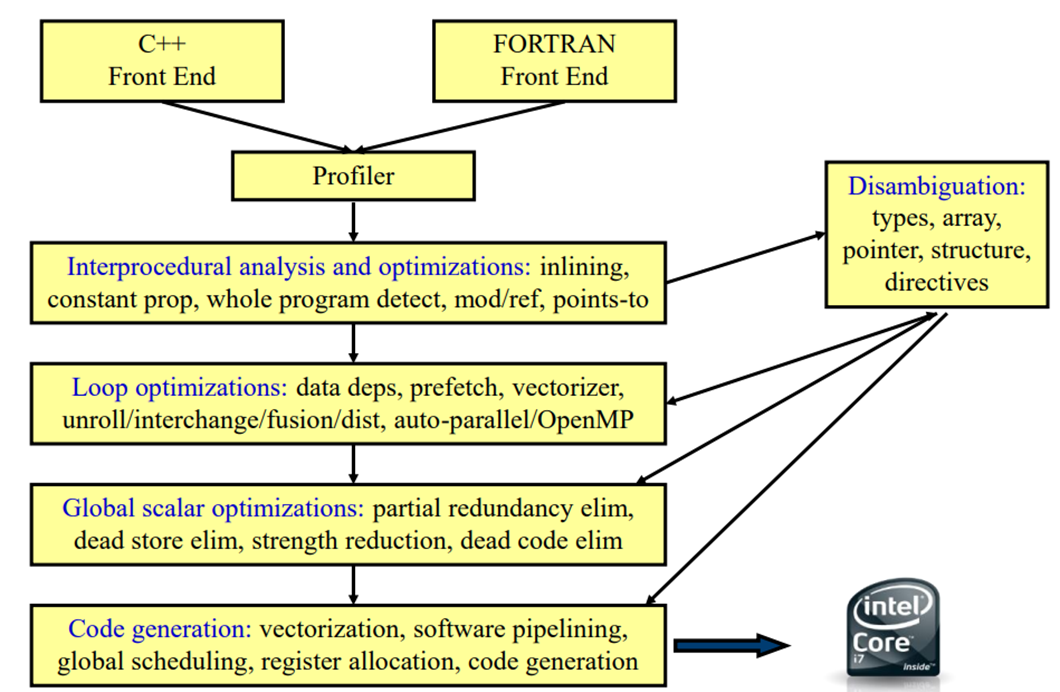
添加图片注释,不超过 140 字(可选)
主要的优化方向

添加图片注释,不超过 140 字(可选)
优化参数选项
编译器会提供一些优化选项,并根据优化选项自动进行大部分的优化。这些选项允许用户控制编译器对代码执行优化以提高其性能。
-fno-alias:该选项用于禁用别名分析,这是一个允许编译器假设在函数调用过程中的参数与被调用函数中的指针没有别名的功能。通过禁用别名分析,编译器可以通过避免不必要的内存访问和减少对数组和其他数据结构执行操作所需的指令数量来生成更高效的代码。如果指定-falias,在函数调用中会假定存在别名,这可能会影响性能。
-foptimize-sibling-calls:该选项会针对性地优化尾递归,默认开启。尾递归是指,在函数返回的时候,调用自身本身,并且,return 语句不能包含表达式。尾递归所占用的栈空间可能快速增长,因为尾递归调用也会创建新的栈帧。但是可以通过优化使得尾递归每次调用只占用一个栈帧,不会出现栈溢出的情况。下面的代码即为一个尾递归,在尾部调用的是函数自身,且return语句不包含运算。
int fact(int n) {
return fact_iter(n, 1);
}
int fact_iter(int int, int product) {
if (num == 1)
return productl
return fact_iter(num - 1, num * product);
}在尾递归优化中,递归调用被转换为GOTO语句,该语句返回到函数的开头。在这种情况下,递归调用的返回值仅用于返回。它不用于其他表达式。递归函数被转换为循环,从而防止修改所使用的堆栈空间。
-fprotect-parens:此选项确定优化器在确定浮点表达式求值的顺序时是否使用括号。当指定选项-fprotect-parens时,优化器将按照代码中括号所施加的求值顺序进行运算。当指定选项-fno-protect-parens时,如果生成的浮点表达式更快,优化器可能会重新排序浮点表达式,而不考虑括号。该选项的默认值为-fno-protect-parens,可能会改变程序编写者的意图,影响浮点运算的结果。如果程序是浮点敏感的,则应该使用选项-fp-model precise。
-nolib-inline:该选项禁止把库中的代码进行内联操作,默认关闭该选项,即编译器会将大量适合内联的库函数进行内联。只有在程序运行异常时才可设置该选项。
-O[n]:该选项针对代码速度进行优化,默认值一般为2,但可能会根据指定的其他编译器选项而更改,用户可以手动设置为0,1,2,3。增加图表。
代码生成选项
本部分所涉及的代码生成一般是基于某些指令集的,如Intel AVX512,Intel AVX2等。
-arch code:告诉编译器可能生成哪些指令集下的代码。参数code向编译器指示它可能生成的指令集。Code可以取SKYLAKE、CORE-AVX512、CORE-AVX2等.
-axcode:告诉编译器为英特尔处理器生成多个基于特定指令集的自动调度代码路径(如果有性能优势)。它还生成基线代码路径,基线代码路径取决于由-m或-x指定的架构。
code可能的值与-arch code的参数相同。可以指定多个code值。指定多个code值时,每个值必须用逗号分隔。例如:
ifort -axSKYLAKE file.cpp
ifort -axSKYLAKE,BROADWELL file.cpp
ifort -axAVX,CORE-AVX2 file.cpp-march:告诉编译器为支持某些功能的处理器生成代码。语法为“-march=processor”,processor的取值与code取值类似,但需要改为小写。,针对非Intel处理器,可以设置-march=haswell以使Intel处理器生成更高效的代码。如果同时指定-ax和-march选项,编译器将不会生成Intel特定的指令。选项-x和-march是互斥的。如果两者都指定,编译器将使用最后一个指定的,并生成警告。
-mtune:对特定处理器执行优化,但不会导致使用扩展指令集(与-march不同)。语法为“-mtune=processor”,取值同上。该选项生成的可执行文件向后兼容,生成的代码针对特定处理器进行了优化。例如,使用-mtune=core2生成的代码在第4代英特尔处理器上正确运行,但它的运行速度可能不如使用-mtune=haswell生成的代码快。使用-mtune=haswell或-mtune=core-avx2生成的代码也将在英特尔Core2处理器上正确运行,但它的运行速度可能不如使用-mtune=core2生成的代码快。这与使用-march=core-avx2生成的代码不同,后者无法在较旧的处理器上正确运行。
-xHost:告诉编译器为编译主机处理器上可用的最高指令集生成指令。此编译器选项生成的指令因处理器而异。
过程间优化选项
过程间优化(interprocedural optimization,IPO)是指在编译器优化过程中,对整个程序不同函数或模块进行全局性的优化。这种优化技术不仅关注单个函数或代码段的性能,而且还考虑了函数之间的相互作用和依赖关系,以实现对整个程序的更全面和有效的优化。
-ffat-lto-objects:该选项确定在过程间优化编译期间是否生成包含中间语言和目标代码的链接时间优化(LTO)对象文件.
-ip:确定是否为单个文件编译启用其他过程间优化。该选项默认是关闭状态(OFF).
-ipo[n]:该选项开启文件间的过程间优化。n是一个可选整数,指定编译器应创建的目标文件数,n必须大于或等于0。指定此选项时,编译器对在单独的文件中定义的函数的调用执行内联函数扩展。
-ipo-c:该选项告知编译器对多个文件进行过程间优化并生成一个单独的目标文件(ipo_out.o)。默认关闭。
高级优化选项
这里的选项包括使用更高级的库和指令集,更激进的预取与优化措施等。在用户优化过程中可以尝试如下的编译选项,编译器可能会编译出更高性能的代码,但也要注意由此带来的正确性和性能损失。
-ansi-alias:它告诉编译器假设程序遵循Fortran标准的以下规则:不可在声明的数组边界之外访问数组;形式参数所代表的对象只能通过该形式参数更改其定义状态,除非它具有TARGET属性。
-qmkl[=lib]:告诉编译器链接到oneMKL中的某些库。lib指示应链接的oneMKL库文件。lib可能的值为:
-
parallel:告诉编译器使用oneMKL中线程并行的库进行链接。如果在没有指定lib的情况下指定该选项,则这是默认设置。
-
sequential:告诉编译器使用oneMKL中的串行库进行链接。
-
cluster:告诉编译器使用集群特定的库和oneMKL中的串行库进行链接。
在Linux下,默认为动态链接,如果在C++程序中需要静态链接Intel MKL库,需要使用如下方式:
-qmkl -static-intel-qopt-zmm-usage=keyword:定义zmm寄存器使用的级别。对于Intel处理器,此选项可以提供更好的代码优化。
当指定-xCORE-AVX512时,默认值为low;当指定-xCOMMON-AVX512时,默认值为high。
-simd:启用或禁用SIMD指令的编译器导语。要禁用SIMD指令的解释,请指定-no-simd。请注意,即使未指定-simd,编译器仍然可以对循环进行向量化并生成SIMD指令。
-scalar-rep:启用或禁用编译器作为循环转换的一部分完成的标量替换优化。
-unroll[=n]和-unroll-aggressive:告诉编译器展开循环的最大次数,以及确定编译器是否对某些循环使用更积极的展开。
-vec和-vec-threshold[n]:启用或禁用向量化,以及设置循环的向量化阈值。n是循环的向量化阈值,即加速的百分比概率
-fauto-profile=path:启用基于采样的反馈导向优化,path是包含AutoFDO配置文件信息的文件的名称。
-fbranch-probabilities:在运行使用-fprofile-arcs编译的程序后,它会为每个源文件的程序流及执行计数保存到一个名为sourcename.gcda的文件中。可以使用-fbranch-probabilities对其进行第二次编译,以根据每个分支的执行次数改进优化。
-frename-registers:尝试通过使用寄存器分配后剩余的寄存器来避免代码中的错误依赖关系。
-funroll-loops、-fpeel-loops、-fsplit-loops:展开循环,循环剥离和循环分割
优化报告选项
编译器在编译时输出的优化报告会包含其在分析代码实现时阻碍优化的语句,用户可以根据优化报告中提示的信息有针对性地进行优化。
-guide[=n]:该选项设置自动向量化、自动并行和数据转换的指导信息级别,它使编译器生成一些优化指导信息消息。
-guide-file[=filename]:将自动优化的指导信息输出到filename文件中,如果filename已经存在,该文件将被覆写。
-qopt-report[=n]和-qopt-report-phase[=list]:该选项告诉编译器生成优化报告文件的级别,每个对象文件(.o文件)一个。n指示报告中的详细级别,可以指定值0到5;指定要生成优化报告的一个或多个阶段。例如cg(代码生成阶段)、ipo(过程间优化阶段)、loop(循环嵌套优化阶段)、par(自动并行阶段)、vec(向量化阶段)等。
并行处理及OpenMP选项
该部分优化选项主要为OpenMP线程级并行。在使用该部分优化选项时,用户也需要在代码中进行设计,避免开启线程级并行时导致结果错误。
以下为Intel编译器的并行选项。
-parallel:告诉自动并行化器为可以安全并行执行的循环生成多线程代码。要使用此选项,还必须指定选项O2或O3。
-qopenmp:支持识别OpenMP*功能,并告诉并行优化器根据OpenMP*指令生成多线程代码。
-qopenmp-simd:启用或禁用OpenMP*SIMD编译。如果要在不影响其他OpenMP功能的情况下启用或禁用SIMD支持,则可以使用此选项。在这种情况下,不需要链接OpenMP运行时库,编译器也不需要生成OpenMP运行库初始化代码。
浮点优化选项
浮点优化选项用于控制编译器对浮点运算的处理方式,包括舍入规则、精度要求、对特殊值的处理等.
-fast-transcendentals:使编译器能够用更快但不太精确的实现替换对某些函数的调用。它允许编译器对某些函数执行优化,例如使用不太精确的向量化正弦库来替换循环中对正弦函数的单个调用。
-fimf-use-svml=value[:funclist]:指示编译器使用Short Vector Math Library(SVML)而不是Intel Fortran Compiler Math Library(LIBM)实现数学函数。funclist是将调用SVML库对应函数的函数列表,该列表指定的是实际的数学库名称,如果指定了多个函数,则它们必须用逗号分隔。例如,sin和sinf等特定于精度的函数会被认为是不同的函数,因此需要使用-fimf-use-svml=true:sin,sinf来指定单精度和双精度正弦函数都应该使用SVML。
-fma:确定如果目标处理器上存在融合乘法加法(FMA)指令,编译器是否生成此类指令。
-fp-model=keyword:控制浮点计算的语义。keyword指定要使用的语义。
-
precise:告诉编译器在实现浮点计算时严格遵守值安全优化,禁用可以更改浮点计算结果的优化
-
fast[=1|2]:告诉编译器在实现浮点计算时使用更积极的优化。这些优化提高了速度,但可能会影响浮点计算的准确性和可重现性。
-
consistent:编译器生成的代码将在不同优化级别或相同体系结构的不同处理器之间保持结果一致性。
-
strict:启用precise和except,告诉编译器在实现浮点计算时严格遵守值安全优化,并启用浮点异常语义。
-
source:将中间结果舍入到源定义的精度。
-
[no-]except:确定是否遵循严格浮点异常语义。
内联选项
内联函数(或编译时期展开函数)用来建议编译器对一些特殊函数进行内联扩展,即建议编译器将指定的函数体插入并取代每一处调用该函数的地方,从而节省每次调用函数带来的额外时间开支。但在选择使用内联函数时,必须在程序占用空间和程序执行效率之间进行权衡,因为过多的复杂函数进行内联扩展将带来很大的存储资源开支,甚至造成代码膨胀。
-finline:告知编译器将! DIR$ ATTRIBUTES FORCEINLINE.声明的函数内联。
-finline-limit=n:用于指定要内联的函数的最大大小,n是函数内联时可以考虑的最大行数。
-inline-forceinline:指示编译器在编译器有能力的时候强制内联建议的函数。此功能仅适用于ifort。如果没有此选项,编译器将使用INLINE属性声明的函数视为仅推荐用于内联。使用此选项与!DIR$ATTRIBUTES-FORCEINLINE相同。
-inline-level=n:指定内联函数扩展的级别,n是内联函数扩展级别,可能的值为0、1和2。n为0时禁用用户定义函数的内联(单语句函数总是内联的);n为1时在指定内联关键字或内联指令时启用内联;n为2时启用编译器自行决定的任何函数的内联。
语言选项
本部分语言选项指对编程语言中的实现进行假定或检查。该部分同样会影响程序性能。
-assume keyword[, keyword...]:编译器在代码中加入执行期检查语句。keyword指定要检查的条件。
-
[no]buffered_io 确定数据是立即从磁盘读取、写入磁盘还是在缓冲区中累积。
-
[no]buffered_stdout 确定数据是立即写入标准输出设备还是累积在缓冲区中。
-
[no]byterecl 确定未格式化文件中OPEN语句RECL说明符(记录长度)值的单位是字节还是长字(四字节单位)。
-
[no]contiguous_assumed_shape 确定是否为指定大小的形式参数假定相邻性。
-
[no]ieee_compares 确定浮点比较操作是否作为IEEE信号操作执行。
-
[no]ieee_fpe_flags 确定浮点异常和状态标志是否保存在例程入口,并在例程出口时恢复。
-
[no]nan_compares 确定是否生成涉及NaN的浮点比较操作的代码,编译器假定不会遇到NaN时可以生成更快的代码序列。
本部分的语言选项指对编程语言中的实现进行假定或检查。该部分同样会影响程序性能。
-check [keyword[, keyword...]]:keyword指定要检查的条件。可能的值为:
-
编译器在代码中加入执行期检查语句。keyword指定要检查的条件。
-
[no]arg_temp_created 确定是否在例程调用之前检查复制到临时存储器中的实际参数。
-
[no]assume 确定是否进行检查以测试ASSUME指令中的标量布尔表达式是否为true,或者ASSUME_ALIGNED指令中的地址是否在指定的字节边界上对齐。
-
[no]bounds 确定是否对数组下标和字符子字符串表达式进行检查。
-
[no]contiguous 确定编译器是否在指针分配时检查指针的相邻性。
-
[no]format 确定是否对要格式化以进行输出的项的数据类型进行检查。
-
[no]shape 确定是否执行数组维度大小一致性检查。
-
[no]stack 确定是否对堆栈帧进行检查。此选项还强制执行局部变量初始化和堆栈指针验证。
数据选项
本部分的选项主要控制数据的对齐、分配布局等。
-align [keyword[, keyword...]]:告诉编译器如何对齐某些数据项。对于对齐的数据,系统在运行时能够更高效地进行存取。
-auto:使所有非SAVE类型的本地变量分配在运行时栈上。
-falign-functions[=n]和-falign-loops[=n]:告诉编译器在最佳字节边界上对齐函数或循环。
-init=keyword:用于将一类变量初始化为零或各种数值异常值.
-mcmodel=mem_model:告诉编译器使用特定的内存模型来生成代码和存储数据,它会影响代码大小和性能。mem_model是要使用的内存模型,例如small、medium和large。
部分参数因篇幅限制,不再详细列出,具体可参考以下链接
引用:
-
https://www.intel.com/content/www/us/en/docs/fortran-compiler/developer-guide-reference/2023-0/overview.html
-
https://www.intel.com/content/www/us/en/developer/articles/technical/intel-fortran-and-c-compiler-documentation.html
-
https://www.physics.udel.edu/~bnikolic/QTTG/shared/docs/intel_fortran_user_reference_guide.pdf


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









