







 本文介绍了如何使用爬虫抓取糯米网上的商家数据,包括分析请求过程、处理请求限制、解析页面等内容。虽然不提供源代码,但强调了理解思路的重要性。文章详细讲解了如何通过城市、分类、地区和商圈的层级结构来遍历数据,并揭示了部分数据通过AJAX加载的事实。
本文介绍了如何使用爬虫抓取糯米网上的商家数据,包括分析请求过程、处理请求限制、解析页面等内容。虽然不提供源代码,但强调了理解思路的重要性。文章详细讲解了如何通过城市、分类、地区和商圈的层级结构来遍历数据,并揭示了部分数据通过AJAX加载的事实。
前段时间写了 爬取美团商家信息的博客 爬虫抓取美团网上所有商家信息 ,这次说说爬取糯米网,由于某些原因无法提供源代码,但是,代码不是关键,最关键的是思想,懂了思想,代码是很容易写的.
爬虫最重要的是分析请求过程,按照实际请求过程去请求数据.
分析是否需要处理cookie,有些网站比较严格请求某些接口的数据时是需要cookie,获取cookie的链接一般是首页,一般的系统会有一个JsessionId 来保持会话.从你访问一个页面开始服务器就会返回这个JsessionId给你,但是访问某些接口,没有带这个cookie,服务器就不会返回数据给你, 这个可以看看我之前写的 使用python爬取12306上面所有车次数据 ,在爬取12306时就需要处理cookie.
分析网站的请求限制,由于爬虫会增加他们服务器压力,流量浪费,数据损失.所以很多网站都会有请求次数的限制.但是他们数据既然是开放的,就一定可以爬取到.只是付出的代价大小的问题.一般会根据ip来限制请求,请求到一定次数时会有验证码. 比如在爬天眼查的数据时,就遇到这个问题.可以使用代理.现在获取代理很容易,也很便宜.
分析网站的数据是否是通过ajax加载的,返回的数据是否有加密.一般这种情况可以使用无界面的浏览器来请求,浏览器中会自己处理好这些事情.
抓取页面,解析想要数据,这个就比较简单了.页面已经抓取下来了,可以使用一些开源的框架解析页面中数据,也可以使用正则.
下面分析如何抓取糯米网上的数据.
经过分析发现糯米 不需要处理cookie,没有ajax加载的情况,有请求的限制,所以就只需要使用代理就可以了.
我们现在分析要如何才能爬取全部数据.
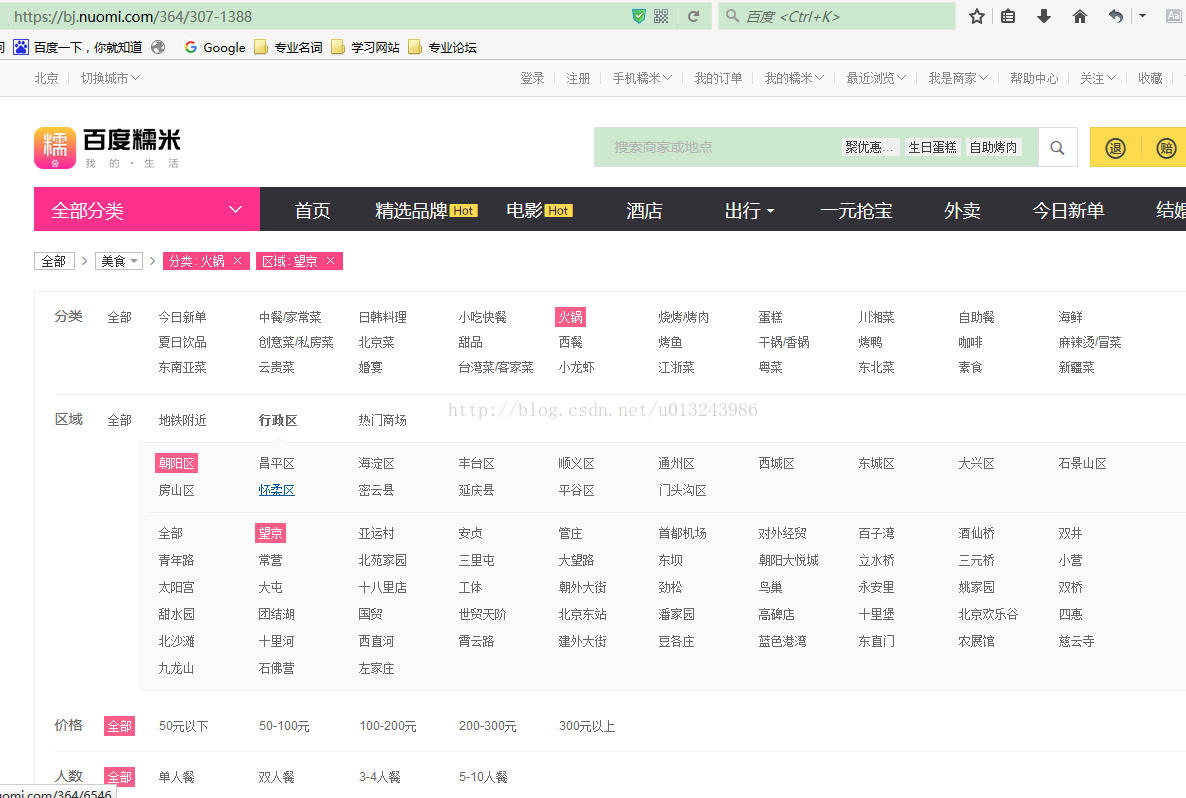
从链接https://bj.nuomi.com/364/3
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 591
591

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









