






TextBoxes A Fast Text Detector with a Single Deep Neural Network
相比于ssd,创新点如下:
1.改变生成的prior boxes的aspect ratios,改为1,2,3,5,7和10。并且设置了vertical offsets
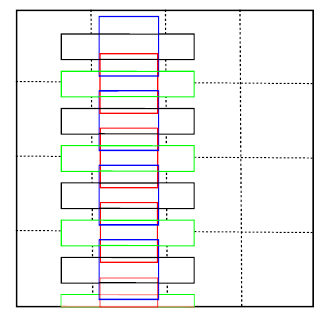
2.将3×3的卷积核改为1×5,改善了特征提取效果。
3.测试阶段:将输入的image重新变形为5种大小,300×300,700×700,300×700,500×700,1600×1600,进行测试。
训练阶段:只使用300×300大小的图像进行训练。
4.提出利用识别(recognition)来提高检测(detection)的精度。利用识别模型来计算loss,提高检测精度。
代码地址:https://github.com/MhLiao/TextBoxes/
上述创新点在代码中的具体表现为:
1.sample比例改变
'min_scale': 0.3,
'max_scale': 1.0,
'min_aspect_ratio': 0.3,
'max_aspect_ratio': 2.0,
2.prior box 的ratio比例改变
min_ratio = 20
max_ratio = 95
aspect_ratios = [[2,3,5,7,10], [2,3,5,7,10], [2,3,5,7,10], [2,3,5,7,10], [2,3,5,7,10], [2,3,5,7,10]]
3.计算loss的时候,使用长方形的卷积核
mbox_layers = CreateMultiBoxHead(net, data_layer='data', from_layers=mbox_source_layers,
use_batchnorm=use_batchnorm, min_sizes=min_sizes, max_sizes=max_sizes,
aspect_ratios=aspect_ratios, normalizations=normalizations,
num_classes=num_classes, share_location=share_location, flip=flip, clip=clip,
prior_variance=prior_variance, kernel_size=[1,5], pad=[0,2])
4.改变priorbox的生成方式
在priorbox的垂直方向设置偏移量,生成原来两倍的priorboxes.
// xmin
top_data[idx++] = (center_x - box_width / 2.) / img_width;
// ymin
top_data[idx++] = (center_y - box_height / 2.) / img_height;
// xmax
top_data[idx++] = (center_x + box_width / 2.) / img_width;
// ymax
top_data[idx++] = (center_y + box_height / 2.) / img_height;
// xmin
top_data[idx++] = (center_x - box_width / 2.) / img_width;
// ymin
top_data[idx++] = (center_y_offset_1 - box_height / 2.) / img_height;
// xmax
top_data[idx++] = (center_x + box_width / 2.) / img_width;
// ymax
top_data[idx++] = (center_y_offset_1 + box_height / 2.) / img_height;















 1108
1108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









