







 本文深入探讨Adaboost元算法,从概述、原理到特点进行详细阐述。关注Adaboost的权重调整策略、弱分类器的选择及其影响,以及如何应对多分类问题。核心在于权重更新和错误率计算,通过组合多个弱分类器形成强分类器,以提高整体分类性能。
本文深入探讨Adaboost元算法,从概述、原理到特点进行详细阐述。关注Adaboost的权重调整策略、弱分类器的选择及其影响,以及如何应对多分类问题。核心在于权重更新和错误率计算,通过组合多个弱分类器形成强分类器,以提高整体分类性能。
一、 Adaboost概述
1、过程描述:
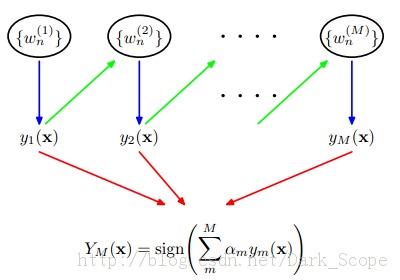
如上图所示,Adaboost的训练过程有如一个学生学习的过程:我们把每个训练样例看做一道练习题,所有的训练样本看做一本习题集。第一次做题的时候,由于每道题都没有做过,不知道哪些难哪些简单,所以一视同仁,做完了对照答案,可能会有很多题目做的不对,那么对于做错的题目,我们就重点标记,给予更高的重视程度,这个用权重w来标示,到第二轮做题的时候就重视这些没做对的“难题”,对于第一次就做对的题目,可以认为是比较简单的,那么第二次的时候稍微看下就可以了,可以降低他的权重。并且,对于第一轮做完以后的效果给一个整体的评分,评价这轮做题的能力,这个就是alpha。在第二轮做题的时候,就按照上一轮调整过的权重对不同的题目给予不同的重视程度和时间分配。如此不断练习,几轮下来,难题就逐渐被攻克了。每轮做题都是有收获的,只不过每次收获的知识权重不同(alpha),这样,我们最后就得到m个分类器,综合每个分类器的权重,我们就能得到一个“学习成绩很好”的分类器了。
2、 算法实现
1) 初始化所有训练样本的权重为1/N, N为训练样本的总数。
2) for m = 1, ..., M
a) 训练一个弱分类器ym,使得他能最小化权重误差函数
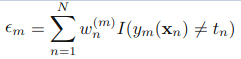
b) 接下来计算该分类器的话语权
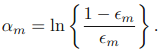
c) 按照分类器的话语权,调整分类器分对和分错的样本的权重
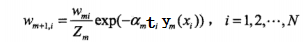
其中Zm为,
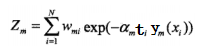
3) 最后综合所有的分类器,得到一个强分类器
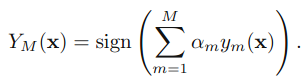
3、 一些思考
1) 对于不同的训练样本开始给予同样的权重,按照上面权重调整的公式,正类和负类的调整步调分别是一致的,有没有可能到第二轮的时候,选取的分类器还是一样的,导致最后结果不收敛?
2) 如果对于每个分类的结果都能有一个概率描述,那么可以参考概率大小来对不同样本调整权重,不需要步调一致地调整权重,这样也许更精细一些。
3) 对于最终结果是否会收敛,每次调整权重之后重新选择的分类器就一定会比之前的分类器更好吗?如果所有的分类器都很弱,最后的结果综合在一起,岂不是更弱吗?
4) 对于参数M的设置和训练过程终止点的设定,有什么科学的方法?
5) 如果对于每次训练,选取不同的分类器,结果会怎么样呢?
6) 如何扩展到多分类问题?
二、 原理
总体的思想如开始的那张图,表达的已经很清楚,问题就在于,权重更新的方法,错误率的计算方法是怎么来的?为什么要这样更新权重,为什么要这么来计算错误率?
直接用前项分布加法模型:
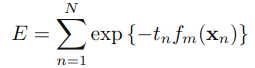
其中fm是前m个弱分类器的组合,
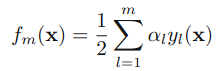
假设前面m-1个y和aloha都已经固定了,那么我们要找到ym和alpha_m,使得E最小化,将E变形得到:
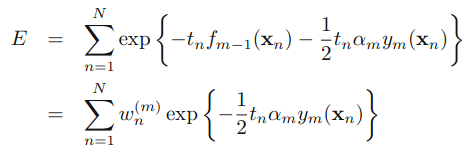
其中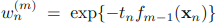
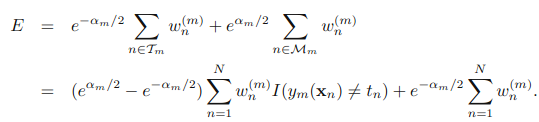
最小化E的过程其实也是寻找ym最小化弱分类器

我们构造弱分类器的时候已经保证了这个条件,因为,我们再根据上式就可以求出a的表达式为:
继而就能找到更新W的公式
其中,
三、特点
1、 Adaboost是存在过拟合的,只不过没有决策树那么明显,但是其泛化性能远没有SVM那么好;
2、 Adaboost的根本就在于其权重更新和弱分类器加权组合:权重更新的过程保证了前面的弱分类器重点处理普遍问题,后面的弱分类器重点处理疑难问题,最终所有的分类器加权组合就构成一个强分类器。
3、 优点:
泛化错误率低, 易编码, 可以应用在大部分的分类器上, 无参数调整;
4、 缺点:
对离群点敏感。
5、 Adaboost每次迭代改变的都是样本的分布,而不是重复采样,不用做特征筛选,也不易overfitting。
6、
一是训练的错误率上界,随着迭代次数的增加,会逐渐下降,这个可以证明;二是adaboost算法即使训练次数很多,也不会出现过拟合的问题。

















 1171
1171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









