






以数据分类任务为例,在分类任务之前,我们需要探索数据,通过数据可视化掌握数据概况,并对数据的完整性和数据质量逆行评估。随后我们围绕分类任务的两大核心问题展开工作。
数据挖掘中分类任务面临两个核心问题:
1,分类器包含SVM,KNN,决策树,朴素贝叶斯分类器等,在做模型训练时,我们到底如何选择分类器?
2,如何优化分类器的参数,提高分类准确率。
文中完整代码详见https://github.com/ccmather/py_workspace
在同一数据中,同时构造svm,KNN,决策树,随机森林分类器,引入pipeline流水线作业模块,对每一个分类器均进行训练,这里,我们需要先对数据进行标准化处理,每一步均采用(名称,步骤)的方式进行。
如

在训练模型时,事实上,每个模型的参数都很多,取值范围也比较广,如何高效调优呢,我们引入gridsearchcv工具,这是python的参数自动搜索模块,输入想要调整的参数以及参数的取值范围即可,gridsearchcv会将每种情况都处理一遍,输出处理就够,通常,只要输出最优结果即可。
gridsearchcv模块包引入
from sklearn.model_selection import GridSearchCV
涉及到的参数如下:
#@estimator:想要采用的分类器
#@param_grid:想要优化的参数及取值,
#@cv:交叉验证的折数,默认三折交叉验证
#@scoring:准确度的评价标准,
使用示例如下:
def GridSearchCV_work(pipe, train_x, train_y, test_x, test_y, param_grid, score = 'accuracy'):
response = {}
gridsearch = GridSearchCV(estimator=pipe, param_grid= param_grid, scoring=score)
#寻找最优的参数和最优的准确率分数
search = gridsearch.fit(train_x, train_y)
print("gridsearch最优参数:", search.best_params_)
print("gridsearch最优分数:", search.best_score_)
predict_y = gridsearch.predict(test_x)
print("accuracy:", accuracy_score(test_y, predict_y))
response['predict_y'] = predict_y
response['accuracy_score'] = accuracy_score(test_y, predict_y)
return response我们同时采用svm,knn,决策树,随机森林分类器,引入pipeline模块和gridsearchcv模块,对wanwna某银行的信用卡违约数据进行训练,并预测信用卡位于率,主要分为一下三步,
#step1 加载数据
#step2 数据特征处理阶段:采用可视化方式对数据做简单处理,把握数据概况
#step3 分类模型训练阶段:采用pipeine方式,第一步:数据规范化,
第二步:采用SVC,KNN,决策树,RF模型 都训练数据集,
用gridsearchCV工具,找到每个分类器的最优参数和最优分数,
最终找到最适合的分类器和分类器的参数。
#数据加载,查看数据集大小,数据概况,做特征工程
data = pd.read_csv('/UCI_Credit_Card.csv')
print(data.shape)
print(data.describe())
#查看下雨个月违规率的情况, value_counts()查看某列有多少不同值,并计算每个不同值在该列中有多少重复值
next_month = data['default.payment.next.month'].value_counts()
print(next_month)
df = pd.DataFrame({'default.payment.next.month':next_month.index, 'values': next_month.values})
plt.figure(figsize=(6,6))
plt.title('信用卡违约率客户\n (违约:1,守约:0')
sns.set_color_codes('pastel')
sns.barplot(x = 'default.payment.next.month', y='values', data = df)
locs, labels = plt.xticks()
plt.show()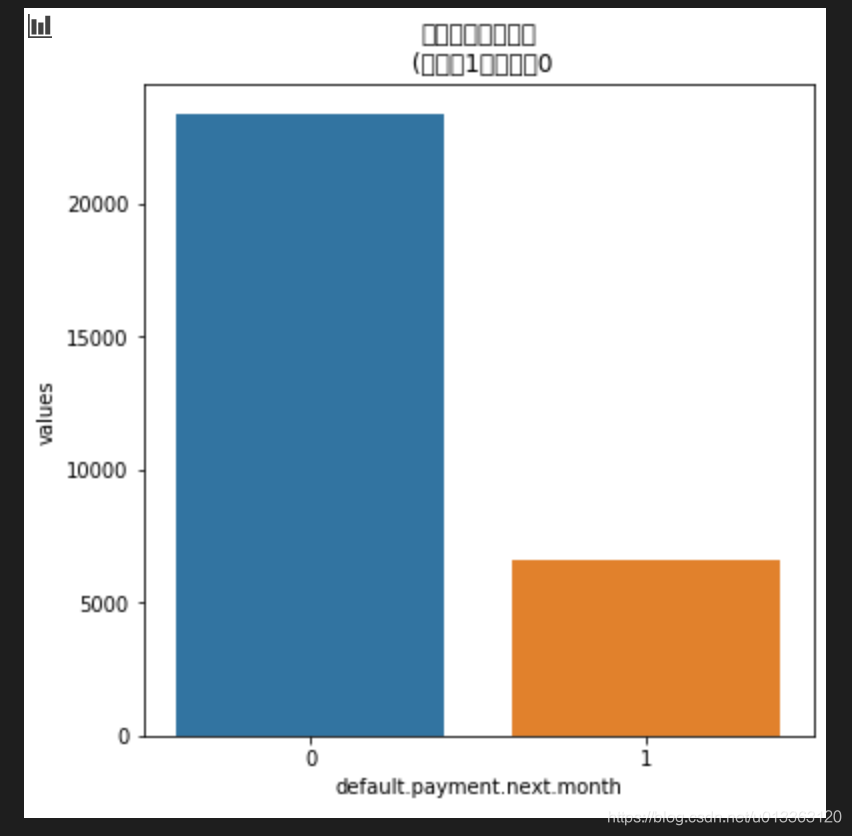
#pipeline 构造svm,DecisionTree,RF,KNeighbors分类器,
classifiers = [
SVC(random_state = 1, kernel='rbf'),
DecisionTreeClassifier(random_state = 1, criterion='gini'),
RandomForestClassifier(random_state=1, criterion='gini'),
KNeighborsClassifier(metric='minkowski'),
]
#分类器名称
classifier_names = [
'svc',
'decisiontreeclassifier',
'randomforestclassifier',
'kneighborclassifier',
]
#分类器参数
classifier_param_grid = [
{'svc__C':[1], 'svc__gamma':[0.01]},
{'decisiontreeclassifier__max_depth': [6,9,11]},
{'randomforestclassifier__n_estimators': [3,5,6]},
{'kneighborclassifier__n_neighbors': [4,6,8]},
]最后采用pipeline和gridsearchcv构造分类器训练模型,训练结果如下:

有问题请与我联系














 1020
1020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









