







最小二乘法的误差符合正态分布,而逻辑回归的误差符合的是二项分布,所以不能用最小二乘法来作为损失函数,那么能够用最大似然预计来做。
从求最优解的角度来解释:
如果用最小二乘法,目标函数就是  ,是非凸的,不容易求解,会得到局部最优。
,是非凸的,不容易求解,会得到局部最优。
如果用最大似然估计,目标函数就是对数似然函数:  ,是关于
,是关于  的高阶连续可导凸函数,可以方便通过一些凸优化算法求解,比如梯度下降法、牛顿法等。
的高阶连续可导凸函数,可以方便通过一些凸优化算法求解,比如梯度下降法、牛顿法等。
最小二乘作为损失函数的函数曲线:

图1 最小二乘作为逻辑回归模型的损失函数,theta为待优化参数
以及最大似然作为损失函数的函数曲线(最大似然损失函数后面给出):
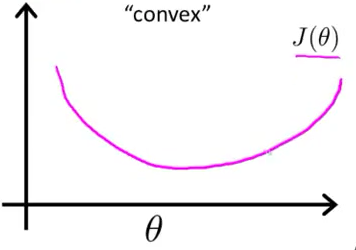
图2 最大似然作为逻辑回归模型的损失函数,theta为待优化参数
很显然了,图2比图1展现的函数要简单多了,很容易求到参数的最优解(凸函数),而图1很容易陷入局部最优解(非凸函数)。这就是前面说的选取的标准要容易测量,这就是逻辑回归损失函数为什么使用最大似然而不用最小二乘的原因了。
既然是最大似然,我们的目标当然是要最大化似然概率了:

对于二分类问题有:


用一个式子表示上面这个分段的函数为:(记得写成相乘的形式)

代入目标函数中,再对目标函数取对数,则目标函数变为:

如果用  来表示
来表示  ,则可用
,则可用  来表示
来表示  ,再将目标函数max换成min,则目标函数变为:
,再将目标函数max换成min,则目标函数变为:

这样就得到最终的形式了!
参考文献

















 7134
7134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









