






基本概念
Snapshot
快照捕获表在某个时间点的状态。用户可以通过最新的快照来访问表的最新数据。通过时间旅行,用户还可以通过较早的快照访问表的先前状态。
Partition
Paimon 采用与 Apache Hive 相同的分区概念来分离数据。
分区是一种可选方法,可根据日期、城市和部门等特定列的值将表划分为相关部分。每个表可以有一个或多个分区键来标识特定分区。
通过分区,用户可以高效地操作表中的一片记录。
如果定义了主键,则分区键必须是主键的子集。
Bucket
未分区表或分区表中的分区被细分为存储桶,以便为可用于更有效查询的数据提供额外的结构。
桶的范围由记录中的一列或多列的哈希值确定。用户可以通过提供bucket-key选项来指定分桶列。如果未指定bucket-key选项,则主键(如果已定义)或完整记录将用作存储桶键。
桶是读写的最小存储单元,因此桶的数量限制了最大处理并行度。不过这个数字不应该太大,因为它会导致大量小文件和低读取性能。一般来说,建议每个桶的数据大小为1GB左右。
Consistency Guarantees一致性保证
Paimon writer使用两阶段提交协议以原子方式将一批记录提交到表中。每次提交在提交时最多生成两个快照。
对于任意两个同时修改表的writer,只要他们不修改同一个存储桶,他们的提交都是可序列化的。如果他们修改同一个存储桶,则仅保证快照隔离。也就是说,最终表状态可能是两次提交的混合,但不会丢失任何更改。
文件布局
一张表的所有文件都存储在一个基本目录下。Paimon 文件以分层方式组织。下图说明了文件布局。从快照文件开始,Paimon 读者可以递归地访问表中的所有记录。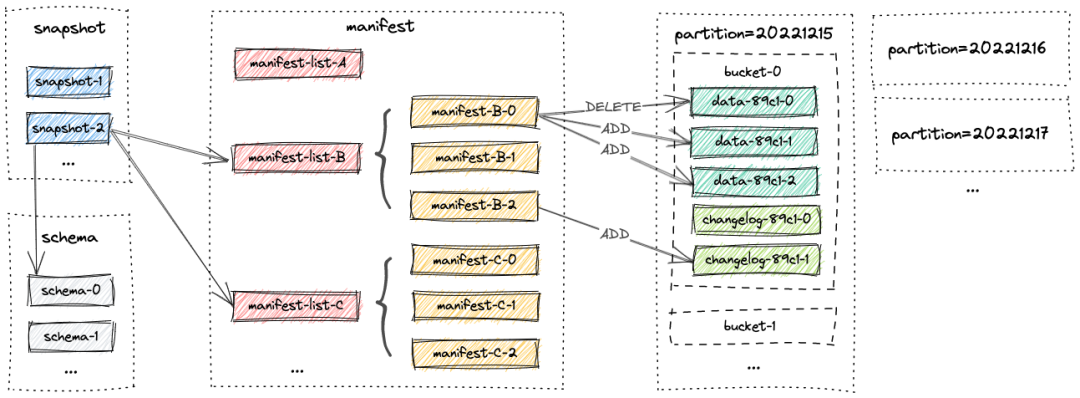
Snapshot Files
所有快照文件都存储在快照目录中。
快照文件是一个 JSON 文件,包含有关此快照的信息,包括:
正在使用的Schema文件
包含此快照的所有更改的清单列表(manifest list)
Manifest Files
所有清单列表(manifest list)和清单文件(manifest file)都存储在清单(manifest)目录中。
清单列表(manifest list)是清单文件名(manifest file)的列表。
清单文件(manifest file)是包含有关 LSM 数据文件和更改日志文件的文件信息。例如对应快照中创建了哪个LSM数据文件、删除了哪个文件。
Data Files
数据文件按分区和存储桶分组。每个存储桶目录都包含一个 LSM 树及其变更日志文件。
目前,Paimon 支持使用 orc(默认)、parquet 和 avro 作为数据文件格式。
LSM Trees
Paimon 采用 LSM 树(日志结构合并树)作为文件存储的数据结构。
Sorted Runs
LSM 树将文件组织成多个Sorted Run。Sorted Run由一个或多个数据文件组成,并且每个数据文件恰好属于一个Sorted Run。
数据文件中的记录按其主键排序。在Sorted Run中,数据文件的主键范围永远不会重叠。
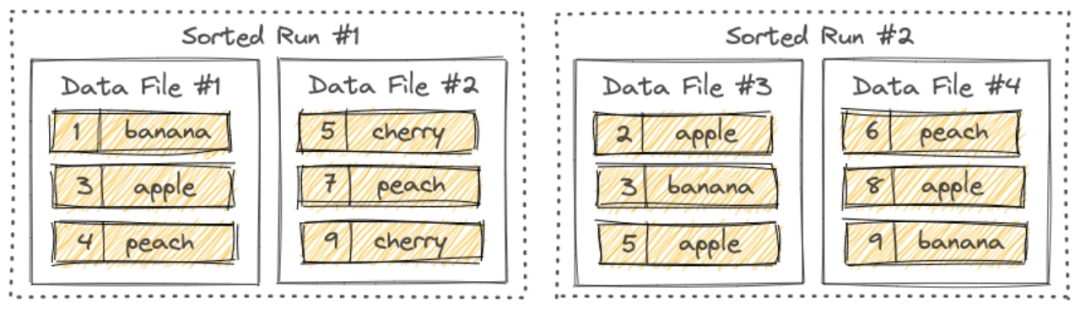
正如您所看到的,不同的Sorted Run可能具有重叠的主键范围,甚至可能包含相同的主键。查询LSM树时,必须合并所有Sorted Run,并且必须根据用户指定的合并引擎和每条记录的时间戳来合并具有相同主键的所有记录。
写入LSM树的新记录:将首先缓存在内存中。当内存缓冲区满时,内存中的所有记录将被排序并刷新到磁盘。
Compaction
当越来越多的记录写入LSM树时,Sorted Run的数量将会增加。由于查询LSM树需要将所有Sorted Run合并起来,太多Sorted Run将导致查询性能较差,甚至内存不足。
为了限制Sorted Run的数量,我们必须偶尔将多个Sorted Run合并为一个大的Sorted Run。这个过程称为Compaction。
然而,Compaction是一个资源密集型过程,会消耗一定的CPU时间和磁盘IO,因此过于频繁的Compaction可能会导致写入速度变慢。这是查询和写入性能之间的权衡。Paimon 目前采用了类似于 Rocksdb 通用压缩的Compaction策略。
默认情况下,当Paimon将记录追加到LSM树时,它也会根据需要执行Compaction。用户还可以选择在“专用Compaction作业”中独立执行所有Compaction。
表管理
管理快照
1)快照过期
Paimon Writer每次提交都会生成一个或两个快照。每个快照可能会添加一些新的数据文件或将一些旧的数据文件标记为已删除。然而,标记的数据文件并没有真正被删除,因为Paimon还支持时间旅行到更早的快照。它们仅在快照过期时被删除。
目前,Paimon Writer在提交新更改时会自动执行过期操作。通过使旧快照过期,可以删除不再使用的旧数据文件和元数据文件,以释放磁盘空间。
设置以下表属性:
注意,保留时间太短或保留数量太少可能会导致如下问题:
批量查询找不到该文件。例如,表比较大,批量查询需要10分钟才能读取,但是10分钟前的快照过期了,此时批量查询会读取到已删除的快照。
表文件上的流式读取作业(没有外部日志系统)无法重新启动。当作业重新启动时,它记录的快照可能已过期。(可以使用Consumer Id来保护快照过期的小保留时间内的流式读取)。
2)快照回滚
<FLINK_HOME>/bin/flink run \
/path/to/paimon-flink-action-0.5-SNAPSHOT.jar \
rollback-to \
–warehouse \
–database \
–table \
–snapshot \
[–catalog-conf [–catalog-conf …]]管理分区
创建分区表时可以设置partition.expiration-time。Paimon会定期检查分区的状态,并根据时间删除过期的分区。
判断分区是否过期:将分区中提取的时间与当前时间进行比较,看生存时间是否超过partition.expiration-time。比如:
CREATE TABLE T (…) PARTITIONED BY (dt) WITH (
'partition.expiration-time' = '7 d',
'partition.expiration-check-interval' = '1 d',
'partition.timestamp-formatter' = 'yyyyMMdd'
);
管理小文件
小文件可能会导致:
稳定性问题:HDFS中小文件过多,NameNode会承受过大的压力。
成本问题:HDFS中的小文件会暂时使用最小1个Block的大小,例如128MB。
查询效率:小文件过多查询效率会受到影响。
1)Flink Checkpoint的影响
使用Flink Writer,每个checkpoint会生成 1-2 个快照,并且checkpoint会强制在 DFS 上生成文件,因此checkpoint间隔越小,会生成越多的小文件。
默认情况下,不仅checkpoint会导致文件生成,writer的内存(write-buffer-size)耗尽也会将数据flush到DFS并生成相应的文件。可以启用 write-buffer-spillable 在 writer 中生成溢出文件,从而在 DFS 中生成更大的文件。
所以,可以设置如下:
增大checkpoint间隔
增加 write-buffer-size 或启用 write-buffer-spillable2)快照的影响
Paimon维护文件的多个版本,文件的Compaction和删除是逻辑上的,并没有真正删除文件。文件只有在 Snapshot 过期后才会被真正删除,因此减少文件的第一个方法就是减少 Snapshot 过期的时间。Flink writer 会自动使快照过期。
分区和分桶的影响
表数据会被物理分片到不同的分区,里面有不同的桶,所以如果整体数据量太小,单个桶中至少有一个文件,建议你配置较少的桶数,否则会出现也有很多小文件。
3)主键表LSM的影响
LSM 树将文件组织成Sorted Runs的运行。Sorted Runs由一个或多个数据文件组成,并且每个数据文件恰好属于一个Sorted Runs。
默认情况下,Sorted Runs数取决于 num-sorted-run.compaction-trigger,这意味着一个桶中至少有 5 个文件。如果要减少此数量,可以保留更少的文件,但写入性能可能会受到影响。
4)仅追加表的文件的影响
默认情况下,Append-Only 还会进行自动Compaction以减少小文件的数量
对于分桶的 Append-only 表,为了排序会对bucket内的文件行Compaction,可能会保留更多的小文件。
5)Full-Compaction的影响
主键表是5个文件,但是Append-Only表(桶)可能单个桶里有50个小文件,这是很难接受的。更糟糕的是,不再活动的分区还保留了如此多的小文件。
建议配置Full-Compaction,在Flink写入时配置full-compaction.delta-commits定期进行full-compaction。并且可以确保在写入结束之前分区被full-compaction。

如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!

Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点















 951
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









