







一、需求分析
输入旺旺号,获取淘宝卖家的信用分
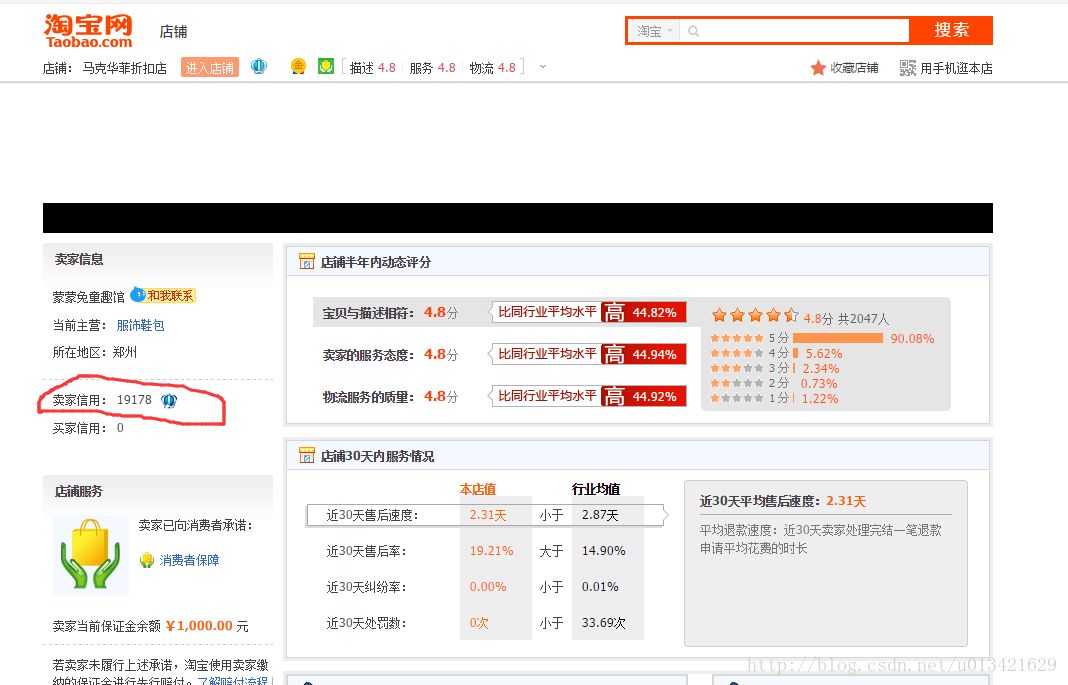
二、思路
淘宝需要模拟登陆,我们这里抓不到,因此为了绕过登陆,发现了淘一兔,我们可以通过这里,得到淘宝卖家的信用分,结果是一样的。
http://www.taoyizhu.com/
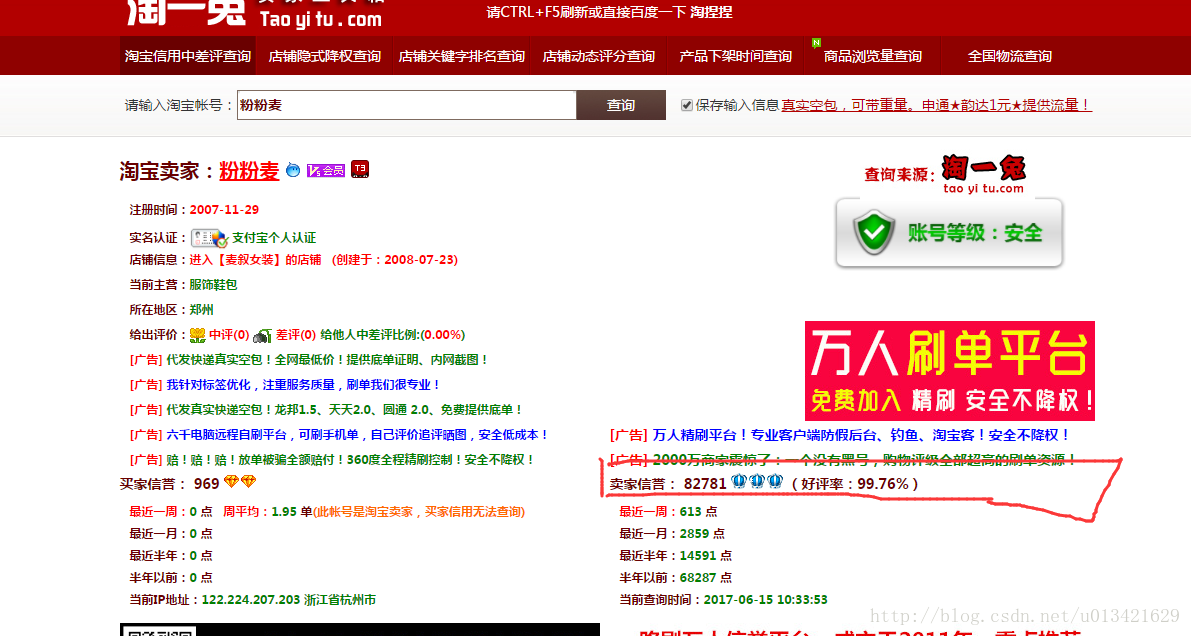
输入旺旺号,需要点击查询,等待几秒,得到查询结果,这里我们用selienum 来做
三、实现源代码(抓取不能太快,否则抓不到)
# encoding: utf-8
from selenium import webdriver
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import pandas as pd
import time
import re
time1=time.time()
driver=webdriver.PhantomJS(executable_path='D:\\Program Files\\Python27\\Scripts\\phantomjs.exe')
driver.set_window_size(800, 600)
########################读取数据############################
data1=pd.read_excel(r'C:/taobao/taobao1.xlsx')
print data1
#######################查询店铺信誉分#############################
seller_credit=[]
for i in range(0,len(data1)):
key=str(data1.iloc[i,0])
key1=key.decode("utf-8")
driver.get("http://www.taoyizhu.com/")
time.sleep(5)
driver.find_element_by_id("txt_name").clear()
driver.find_element_by_id("txt_name").send_keys(key1)
driver.find_element_by_id('search_btn').click()
time.sleep(3)
html2 = driver.page_source
seller_credit1 = re.findall('<span id="spanUserSellerCount">(.*?)</span>', html2, re.S)
for each in seller_credit1:
print key,each
seller_credit.append(each)
#######################################增加店铺信誉分这一列#############################
data1['店铺信誉分']=seller_credit
print data1
# 写出excel
writer = pd.ExcelWriter(r'C:\\taobao\\taobao1_all.xlsx', engine='xlsxwriter', options={'strings_to_urls': False})
data1.to_excel(writer, index=False)
writer.close()
time2 = time.time()
print u'ok,爬虫结束!'
print u'总共耗时:' + str(time2 - time1) + 's'


















 2739
2739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











