







二叉堆的定义
二叉堆是完全二叉树或者是近似完全二叉树。
二叉堆满足二个特性:
1.父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
2.每个结点的左子树和右子树都是一个二叉堆(都是最大堆或最小堆)。
当父结点的键值总是大于或等于任何一个子节点的键值时为最大堆。当父结点的键值总是小于或等于任何一个子节点的键值时为最小堆。下图展示一个最小堆:

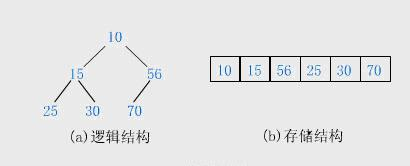
堆的存储
一般都用数组来表示堆,i结点的父结点下标就为(i – 1) / 2。它的左右子结点下标分别为2 * i + 1和2 * i + 2。如第0个结点左右子结点下标分别为1和2。
如何建堆
与堆相关的一个很重要的操作就是堆的建立,即如何将原始数组调整为一个堆。下面是一个最大堆的调整过程:
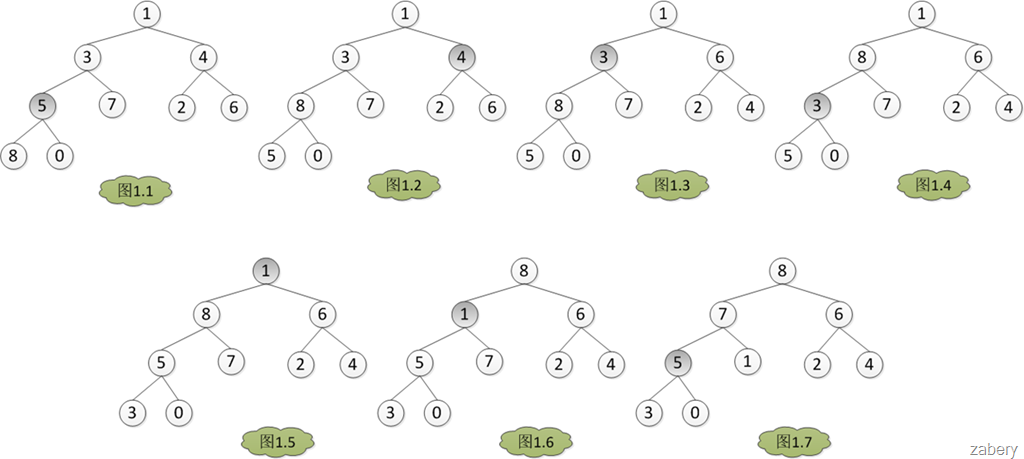
概括起来就是从length/2一直到根节点进行maxHeapify调整。java实现如下:
private void swap(int[] a,int i, int j){
int tmp = a[i];
a[i] = a[j];
a[j] = tmp;
}
public void buildHead(int[] arr){ //建成一个堆,自下而上
for(int i=arr.length/2-1;i>=0;i--){
int largest = i;
while(true){
int left = 2*i+1;
int right = 2*i+2;
if(left<arr.length&&arr[left]>arr[i])
largest = left;
if(right<arr.length&&arr[right]>arr[largest])
largest = right;
if(i!=largest)
swap(arr,i,largest);
else
break;
i = largest;
}
}
}
可以看到,初始堆的建立是自下而上的。
堆排序
建立好初始堆后堆排序就简单了,以非递减排序为例,思路为:设置一个下标len表示堆的最后一个元素的下标,初始值为A.length-1,然后执行如下步骤:
1)将A[0]和A[len]交换
2)自上而下调整下标为0到len-1的元素,使其成为堆
3)--len,如果len>1转步骤1,否则交换A[0]和A[1],结束。
上面的建堆过程加上下面的代码就是堆排序的完整实现:
public void HeapAdjust(int[] arr, int len){
int i=0;
int largest = i;
while(true){
int left = 2*i+1;
int right = 2*i+2;
if(left<len&&arr[left]>arr[i])
largest = left;
if(right<len&&arr[right]>arr[largest])
largest = right;
if(i!=largest)
swap(arr,i,largest);
else
break;
i = largest;
}
}
public void HeadSort(int[] arr){
buildHead(arr);
printArray(arr);
System.out.println();
for(int len=arr.length-1;len>1;len--){
swap(arr,0,len);
HeapAdjust(arr, len);
}
swap(arr,0,1);
}
总结
堆排序的主要耗时操作在初始堆的建立和调整新堆的反复“筛选”,在建立堆时,总共的关键字比较次数不超过4n,调整堆时,最坏情况下时间复杂度为nlogn(实际上要小于这个值)。堆排序在待排序元素较少时不值得提倡,但是当n较大时,堆排序的性能还是有优势的。















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









