







一个数,求其二进制中1的个数,这个我以为很简单的问题,没想到再看了一些大神的博客和一些专门的算法之后,才感觉越是看似简单的问题越是博大精深,简直是佩服的五体投地,一个简单的问题,原来还有这么多可研究的地方,而且这么深奥
本文借鉴于zdd大神的博客 算法-求二进制数中1的个数
一. 最简单,朴实的代码
照例 上代码
int BitCount1(unsigned int n)
{
int count=0;
while(n)
{
count+=n&1;
n>>=1;
}
return count;
}
这段代码就不用解释了吧,一位一位的比较,在c语言里,位运算比常规运算要快 这样 int 型的数最多执行32次运算,
时间复杂度为o(N) 差不多是 对于整体int来说 差不多是 32n吧
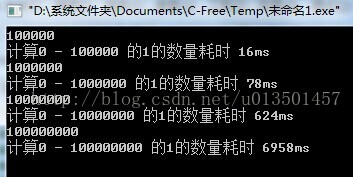
这是测试之下的结果 1亿的数据需要7秒完成运算
二.简单的快速法
这个代码比较朴实 简单易懂,并且很快
int BitCount2(unsigned int n)
{
int count = 0;
while(n)
{
count++;
n&=(n-1);
}
return count;
}
n&(n-1) 这个实际上是取的n的最后一个1,我们可以实际模拟一下,假设n=10 二进制为1010 n-1 = 9 1001 n&(n-1) 不就等于 1000 8吗 这样n&=(n-1) 就是去掉最后一个1 10 & 9 = 8 从1010 变为 1000 然后8 &(7) = (1000)&(0111) = 0 所以,每一次&运算,就加一个count,这样,不用运算所有位,有多少个1就运算多少次,比BitCount1 ()快上多少呢,我们测试一下
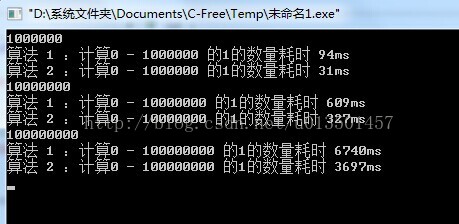
可以看出平均快了一倍 时间复杂度应该还是 o(n) n为1的个数 平均性能应该在 16n ;
三.打表查询 时间复杂度O(1) //下面开始就进入精华的地方了,逐步深入
打表有几种 对256内的数打表,然后借地址运算 静态打表(即表数据存好,之后读取就行)
int table[256]={
0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
4, 5, 5, 6, 5, 6, 6, 7, 5, 6, 6, 7, 6, 7, 7, 8,
};int BitCount3 (unsigned int n)
{
unsigned char * p = (unsigned char * ) &n;
return table[*p]+table[*(p+1)]+table[*(p+2)]+table[*(p+3)];
}
为什么一定要用unsigned char 呢,因为 这样p的范围 是0-255 不然char的范围是 -127到 128 这样的范围不满足,得不出正确答案,
还有一种打表方法,这个思路很巧妙,不是先建立好表,是自己算出table[],然后运算,但是计算table[256]的方法十分巧妙,值得研究;
unsigned char Table[256] = {0} ;
// 初始化表
for (i =0; i <256; i++) <span> //巧妙地就是这个地方怎么算出来的
{
Table[i] = (i & 1) + Table[i /2];
}
int BitCount4(unsigned int n)
{
int count = 0 ,i;
// 建表
// 查表
unsigned char* p = (unsigned char*) &n ;
count = Table[p[0]] + Table[p[1]] + Table[p[2]] + Table[p[3]];
return c ;
}
对于程序中的第一个for循环估计很多人会摸不着头脑,Table这个表究竟是怎么算出来的,这个地方本菜鸟研究了一下
先理解程序,table[i] = i的最后一位 + table[i/2];
i/2 的值我想是因为 比如说i=2,4,6,8 这样的偶数 i*2 = i<<1 即不会改变二进制中1的数量,2是1 4是1 6和3一样是2 10 和 5一样是2 所以,table[i]实际上等于 table[i/2];
问题是还有奇数呢,比如3 3就是2的最后一位+1 5就是4的最后一位加1 然后table [4] = table [2] 所以 5 = 1 + table[2] ;
这的确是一种很巧妙地算法,利用了奇偶数的不同性质,奇数就+1 偶数就等于table [i/2];
这两种打表 时间复杂度都是 o(1) 不过第一种多一个打表,当然,对于大量数据来说,打表时间可以忽略,重要的是这种思路,
下面是实际比较 因为Bitcount3和BitCount4是一样的,打表 就只按3的效率进行计算
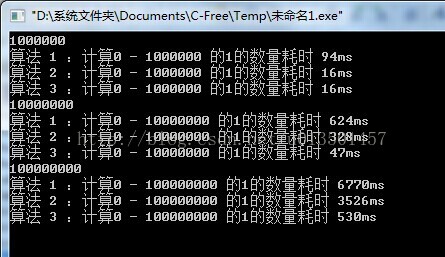
明显发现 打表的方法比快速和普通的快很多 ,1亿的数据量也只要500ms 就可以计算完毕,数据量越大越快的明显
当然,打表还有打table[16]和table[64]这样的的小表 速度可能稍慢一点,但是原理是一样的
四.平行算法
下面就是真正让本人佩服的东西了,虽然我没弄懂,但是不明觉厉啊,
int BitCount5(int n)
{
n = (n &0x55555555) + ((n >>1) &0x55555555) ;
n = (n &0x33333333) + ((n >>2) &0x33333333) ;
n = (n &0x0f0f0f0f) + ((n >>4) &0x0f0f0f0f) ;
n = (n &0x00ff00ff) + ((n >>8) &0x00ff00ff) ;
n = (n &0x0000ffff) + ((n >>16) &0x0000ffff) ;
return n ;
}
这段代码简直让人看的头晕目眩,不明觉厉,,,,一大串的16进制数据,一大堆的位运算,,情何以堪,,,
在网上找了很多解析,然后博主自己琢磨了很久,都没有想明白,这个思路虽然比较简单,但是实施过程如何推倒的,博主无力啊
思路和归并类似吧,看图,,以 217(11011001)为例
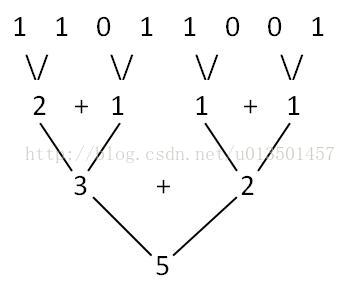
这样就出现5了,因为二进制只有1和0 所以整个2进制每个位加起来的和就是 1的数量 ,,(再次拜服大佬!!!)

然后把149经行下一次操作 得到 17 + 33 =50
50进入下一步 = 2 +3 = 5;
5进入下一步 = 5 + 0 =5;
5进入下一步 = 5 + 0 = 5;
哎,,可以知道结果是正确的,但是却始终不清楚这些16进制的数如何推导的
还有一个更完美的代码
int BitCount6(unsigned int n)
{
unsigned int tmp = n - ((n >>1) &033333333333) - ((n >>2) &011111111111);
return ((tmp + (tmp >>3)) &030707070707) %63;
}
这个就更琢磨不了了啊,,,,哎,,根骨有限,只能留着以后琢磨了,,
贴一下大神的解释
第一行代码的作用
先说明一点,以0开头的是8进制数,以0x开头的是十六进制数,上面代码中使用了三个8进制数。
将n的二进制表示写出来,然后每3bit分成一组,求出每一组中1的个数,再表示成二进制的形式。比如n = 50,其二进制表示为110010,分组后是110和010,这两组中1的个数本别是2和3。2对应010,3对应011,所以第一行代码结束后,tmp = 010011,具体是怎么实现的呢?由于每组3bit,所以这3bit对应的十进制数都能表示为2^2 * a + 2^1 * b + c的形式,也就是4a + 2b + c的形式,这里a,b,c的值为0或1,如果为0表示对应的二进制位上是0,如果为1表示对应的二进制位上是1,所以a + b + c的值也就是4a + 2b + c的二进制数中1的个数了。举个例子,十进制数6(0110)= 4 * 1 + 2 * 1 + 0,这里a = 1, b = 1, c = 0, a + b + c = 2,所以6的二进制表示中有两个1。现在的问题是,如何得到a + b + c呢?注意位运算中,右移一位相当于除2,就利用这个性质!
4a + 2b + c 右移一位等于2a + b
4a + 2b + c 右移量位等于a
然后做减法
4a + 2b + c –(2a + b) – a = a + b + c,这就是第一行代码所作的事,明白了吧。
第二行代码的作用
在第一行的基础上,将tmp中相邻的两组中1的个数累加,由于累加到过程中有些组被重复加了一次,所以要舍弃这些多加的部分,这就是&030707070707的作用,又由于最终结果可能大于63,所以要取模。
需要注意的是,经过第一行代码后,从右侧起,每相邻的3bit只有四种可能,即000, 001, 010, 011,为啥呢?因为每3bit中1的个数最多为3。所以下面的加法中不存在进位的问题,因为3 + 3 = 6,不足8,不会产生进位。
tmp + (tmp >> 3)-这句就是是相邻组相加,注意会产生重复相加的部分,比如tmp = 659 = 001 010 010 011时,tmp >> 3 = 000 001 010 010,相加得
001 010 010 011
000 001 010 010
---------------------
001 011 100 101
011 + 101 = 3 + 5 = 8。(感谢网友Di哈指正。)注意,659只是个中间变量,这个结果不代表659这个数的二进制形式中有8个1。
注意我们想要的只是第二组和最后一组(绿色部分),而第一组和第三组(红色部分)属于重复相加的部分,要消除掉,这就是&030707070707所完成的任务(每隔三位删除三位),最后为什么还要%63呢?因为上面相当于每次计算相连的6bit中1的个数,最多是111111 = 77(八进制)= 63(十进制),所以最后要对63取模。
最后还有一个思路
五.位标志法
struct _byte
{
unsigned a:1;
unsigned b:1;
unsigned c:1;
unsigned d:1;
unsigned e:1;
unsigned f:1;
unsigned g:1;
unsigned h:1;
};
long get_bit_count( unsigned char b )
{
struct _byte *by = (struct _byte*)&b;
return (by->a+by->b+by->c+by->d+by->e+by->f+by->g+by->h);
}
还有一个
六.指令法
这个也是很奇葩的,,反正本人看不懂
unsigned int n =127 ;
unsigned int bitCount = _mm_popcnt_u32(n) ;
使用微软提供的指令,首先要确保你的CPU支持SSE4指令,用Everest和CPU-Z可以查看是否支持。
哎,革命还未成功,同志们一起努力吧,,














 5663
5663











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









