






曹诗雯
1
{ }^{1}
1, 张昭兴
1
{ }^{1}
1, 姚俊明
1
{ }^{1}
1, 乔菊颖
1
{ }^{1}
1, 宋国文
1
{ }^{1}
1, 沈蓉
1
∗
{ }^{1 *}
1∗
1
{ }^{1}
1 理想汽车公司,北京,中国
摘要
即使在大模型快速发展的时代,视频理解,尤其是长视频理解,仍然极具挑战性。与文本或图像信息相比,视频通常包含更多带有冗余的信息,需要大模型在全球范围内战略性地分配注意力以准确理解内容。为了解决这一问题,我们提出了MCAF,这是一个基于代理、无需训练的框架,通过多模态粗到精注意力聚焦进行视频理解。其关键创新在于能够感知并优先处理与理解任务高度相关的视频片段。首先,MCAF通过多模态信息分层关注高度相关的关键帧,增强获取的情境信息与查询之间的相关性。其次,它采用一种时间膨胀扩展机制,以缓解从这些集中帧中提取信息时可能遗漏重要细节的风险。此外,我们的框架还结合了一种自我反思机制,利用模型响应的置信度作为反馈。通过迭代应用这两种创新的聚焦策略,它可以自适应地调整注意力,捕捉与查询高度相关的上下文,从而提高响应准确性。MCAF在平均表现上优于当前最先进的方法。在EgoSchema数据集上,它的表现比领先方法高出显著的 5 % \mathbf{5\%} 5%。同时,在Next-QA和IntentQA数据集上,它分别以 0.2 % \mathbf{0.2\%} 0.2%和 0.3 % \mathbf{0.3\%} 0.3%的优势超越了目前最先进的标准。在平均时长接近一小时的Video-MME数据集上,MCAF也优于其他基于代理的方法。
I. 引言
近年来,由于视频能够传达更广泛的信息,视频在各个领域得到了越来越多的应用。因此,视频理解任务逐渐成为多模态研究领域的热点。与文本和图像数据相比,视频数据在空间和时间上跨度更大,表现出更复杂的语义内容和多模态特征,并具有强因果关系和冗余性,所有这些都对视频分析方法提出了巨大挑战。
随着大型语言模型(LLMs)[1-8,70,71]在自然语言处理中的显著成功,基于LLMs的多模态大型语言模型(MLLMs)[9-21,74,75]已经在各种图像理解任务中展现出令人印象深刻的能力,包括识别[22]、目标检测[14,15]和视觉导航[23]。然而,将MLLM为中心的方法应用于视频理解任务仍然面临以下方面的困难[24,50,57,59]:
- 更大的数据量:随着视频质量的提高,更高的分辨率和帧率导致海量数据,这对MLLMs的处理能力提出了重大挑战。
-
- 更高的信息密度:长视频通常包含多个场景和丰富的语义表达。单纯的压缩或降采样往往无法保留细粒度信息,导致对细节导向问题的回答不准确。
-
- 更高的冗余性:视频通常表现出时间上的冗余。如果没有精确识别和适当选择关键帧,MLLMs的注意力可能会放在与查询不密切相关的部分,可能导致误解。
因此,需要一个视频理解框架,使MLLMs能够有选择地吸收多模态视频信息,并自适应地专注于视频的不同部分,像人类的思维过程一样逐步获得全面的答案。
- 更高的冗余性:视频通常表现出时间上的冗余。如果没有精确识别和适当选择关键帧,MLLMs的注意力可能会放在与查询不密切相关的部分,可能导致误解。
一些视频理解解决方案结合使用预训练的视频编码器和特定任务的基于Transformer的多模态融合操作。这些模块生成的空间-时间标记随后被输入到MLLMs中进行理解。这种基于MLLM的视频理解方法(video-MLLM)[25-42]在某些数据集上取得了良好的结果。然而,它们通常需要针对特定任务的监督微调,
:联系人: shenrong@lixiang.com
这限制了它们的泛化能力。此外,当面对包含多个场景和丰富细节的长视频时,全局叙事逻辑和细粒度但关键的信息在过量的数据中变得模糊不清,使得MLLMs难以感知。此外,由于上下文长度的限制,视觉标记的压缩不可避免,这进一步破坏了MLLMs的细粒度信息感知能力。
相比之下,基于代理的框架利用预训练语言模型的理解和决策能力来构建模拟人类认知机制的多代理协作系统。这些框架在动态任务分配和自动化工具使用能力方面表现出独特的优势[43]。如图1所示,当前主流的基于代理的视频理解方法采用系统化的回答-评估-改进架构。通过利用LLMs或MLLMs的自我反思推理能力,它们采用分而治之的方法进行视频理解,使得基于此类架构的解决方案[44-60]在核心模型大小相当的情况下表现出优越的泛化和适应能力。此外,这些框架的无需训练特性显著减少了对高质量标注数据的依赖。
因此,我们提出多模态粗到精注意力聚焦(MCAF)框架,这是一种模仿人类认知策略进行视频理解的基于代理的视频理解解决方案。MCAF能够根据前一次思考的反馈动态调整其注意力。继承上述提到的基于代理框架的优点,MCAF还具备整合各种主流LLMs和MLLMs的能力,以实现高效的视频理解。
我们的MCAF的核心创新工作在于其能够从大量视频数据中精确感知和优先处理与查询相关的片段(如图1中薰衣草色区域所示)。总之,这些关键贡献如下所述:
-
多模态层次相关性检索与时空增强:我们开发了一种新型的多模态层次相关性过滤模块,结合有效的语义提取策略,以检索最相关的上下文供LLM关注,从而增强长时间视频理解的有效性和全面性。
-
- 高效的自我反思机制:我们通过单一LLM实现了自适应自我反思机制。通过由响应置信度反馈引导的迭代注意力聚焦适应,系统自主获取高相关性的
-
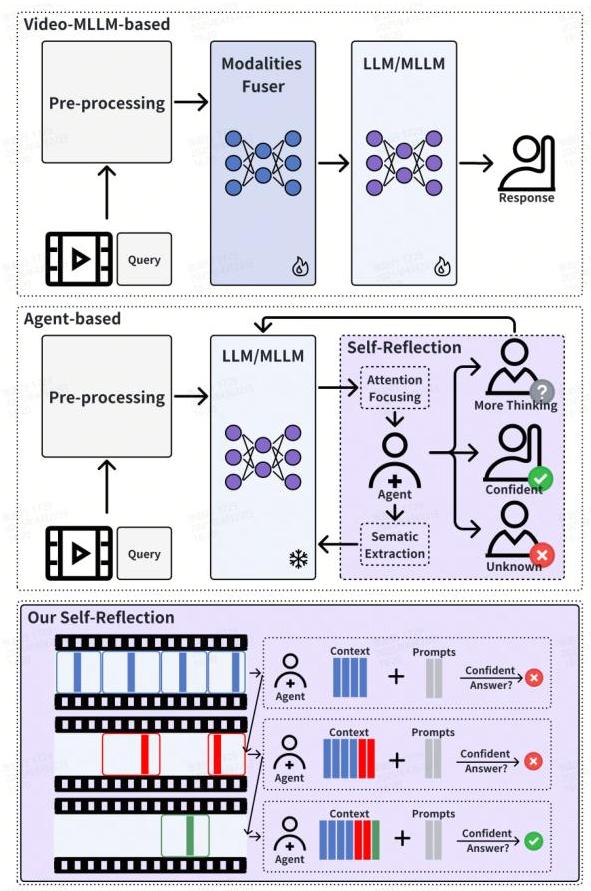
图1:两种主流基于MLLM的视频理解框架比较:基于Video-MLLM和基于Agent的方法。特别是,基于代理方法中紫色突出显示的部分表示我们在MCAF框架中的创新工作。
情境信息,实现可测量的准确度提升。主要视频问答基准上的对比实验展示了我们基于单个LLM的自我反思模块的优越性。 -
即插即用架构:MCAF兼容当前主流的LLMs和MLLMs。其架构确保我们的解决方案性能自动受益于这些LLMs和MLLMs未来的进步。
II. 相关工作
随着MLLM技术的快速发展,近年来,视频理解领域的先进(SOTA)框架普遍利用LLMs或MLLMs。这些大型模型可以大致分为以下两种方法:
- 基于Video-MLLM:这些解决方案通常利用来自MLLMs的标记化输出作为隐藏状态,从而将其预训练的通用多模态理解能力嵌入
- 特定任务的网络架构用于视频理解。通过对领域内视频数据集进行监督微调大型模型或适配器[25-42]的参数,这些框架能够对视频理解提供精确的响应。
- 然而,这些基于Video-MLLM的方法通常存在几个固有的局限性:首先,它们的整体架构往往复杂且需要大量的训练,代价是巨大的数据整理和标注。其次,监督微调过程通常会削弱模型的泛化能力。再次,不可或缺的数据压缩操作如标记压缩和时间滑动窗口经常因细节损失而降低理解准确性。最后,这些系统通常在自我导向探索方面表现不足,而这对于处理复杂的任务如视频理解至关重要[24,50,57,59]。
- 基于代理:这类方法[44-61]通常利用预训练LLMs或MLLMs的调度能力来帮助视频理解。通过高效集成自我反思闭环,基于代理框架可以在视频理解任务中最大化这些LLMs或MLLMs的一般理解能力,而不损害其一般理解能力。基于代理的方法还允许我们通过其他操作将选定的内容输入LLMs或MLLMs,以在相同核心模型配置下增强理解效率。
- 在其他主流SOTA框架中,DrVideo[49]采用迭代自我反思机制来定位相关视频段进行理解。然而,它完全依赖LLMs通过文本转换的图像模式来评估相关性,导致因未能充分利用丰富的视觉信息而产生理解错误。VideoTree[59]在其自我反思推理中吸收视觉特征,但仅形成部分注意力分配过程的闭环,缺乏基于最终答案质量的动态调整分配政策的能力。其自适应广度扩展机制也比我们的膨胀时间扩展(DTE)策略更复杂。VCA[50]引入额外的基于MLLM的评估模型,通过多模态信息自适应调整焦点剪辑,但由于过多的模型参与而导致性能下降,其核心注意力聚焦效果受到历史图像存储容量的限制。VideoAgent[57]和VideoINSTA[60]均利用辅助模型提取辅助信息(例如前景对象位置)以进行视频
- 理解。然而,这些辅助模型的引入带来了沉重的计算开销。它们也无法通过响应评估建立有效的闭环优化。
-
- 我们的解决方案:借鉴上述例子的灵感,我们提出了新颖的基于代理的框架MCAF。遵循人类的认知过程来理解视频,MCAF通过多模态层次注意力聚焦操作在空间和时间上显著提高了视频理解的准确性。与同期解决方案相比,MCAF首先引入了一种增强的上下文检索机制,确保获取的上下文既相关又完整。然后,它将这种创新的检索机制融入由单个LLM引导的自我反思推理机制中。这种高效实现无论是在长时间形式如Video-MME[67]还是中短时间形式如EgoSchema[64]、Next-QA[65]和IntentQA[66]视频问答基准上都表现出优越性能。
III. 方法论
我们提出的MCAF模仿人类通过视频问题进行推理的方式,其模块按以下方式排列:
- 对视频进行快速端到端扫描并将其分解为相对独立的语义段。
-
- 粗略预测哪些语义段很可能包含必要的信息。
-
- 在这些候选段落上进行更精细的关注,以获取包含详细信息的全面上下文。
-
- 动态评估收集的上下文是否足够,并在当前上下文信息不足以生成自信响应时重复最后两个步骤以调整重点。
- 在我们的管道中,MCAF首先对输入视频进行逐片聚类。通过多层次和多模态的相关性评估,MCAF识别出最相关的查询帧,并在这些帧上施加DTE以拓宽理解视野。随后,视觉语言模型(VLM)从这些高度相关的帧中提取语义信息,作为回答问题的聚焦上下文基础。该框架利用答案置信度分数作为反馈,迭代调整其多层次和多模态的相关性评估,直到获得足够自信的响应。图2展示了MCAF如何通过其多模态层次注意力聚焦机制动态平衡效率和精度。
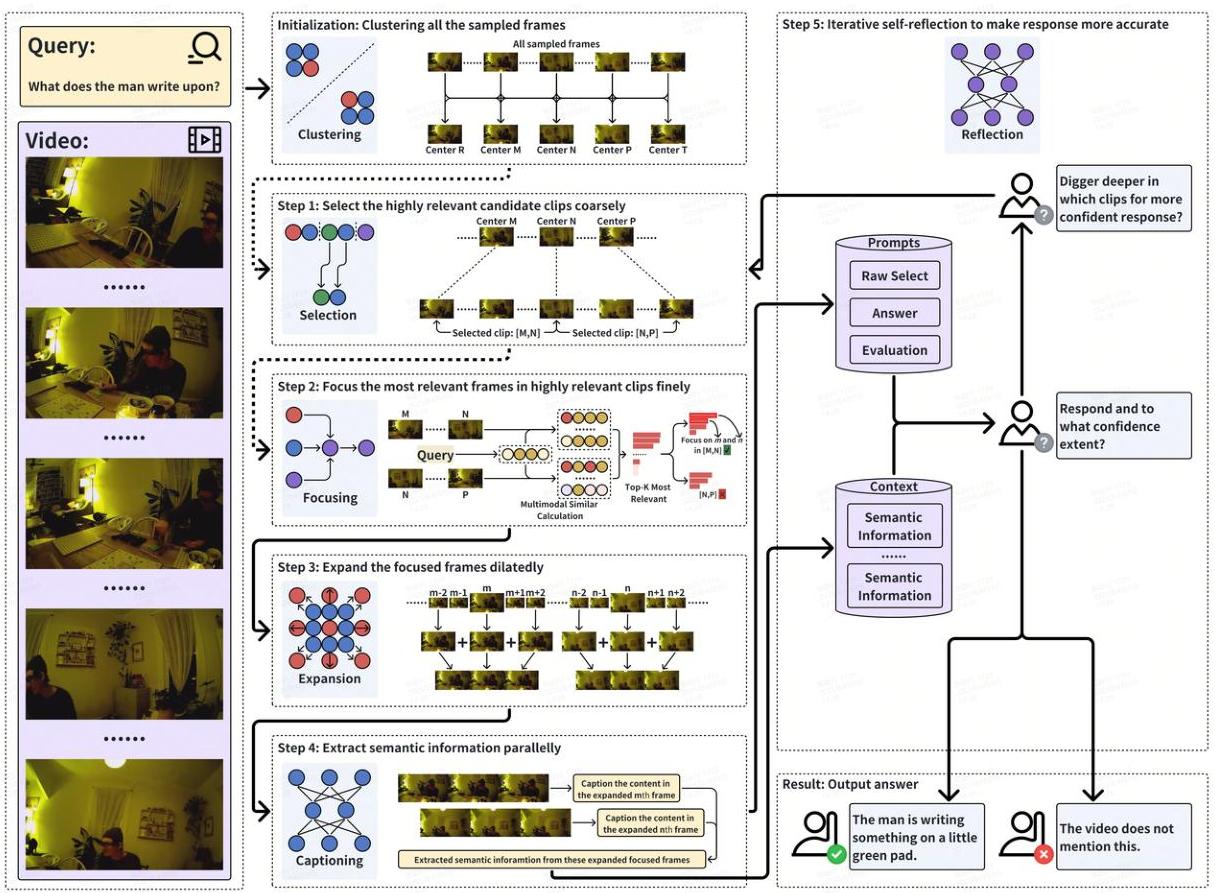
图2:完整的MCAF管道示意图,其中最左侧部分显示输入查询和所有视频帧,其他部分显示核心模块:第一步使用“选择”表示基于语义特征识别高度相关的片段候选人的粗略注意力聚焦过程;第二步使用“聚焦”表示通过语义-视觉特征相似性匹配精确定位高度相关帧的精细注意力聚焦过程;第三步对选定帧执行DTE;第四步通过VLM从扩展帧中提取语义特征作为问答的上下文信息;第五步生成响应,同时评估置信度分数以决定直接输出还是重新迭代聚焦-选择过程以补充缺失信息。值得注意的是,第五步中的单个LLM充当响应生成、置信度评估和第一步粗略注意力聚焦的反射器。由于初始粗略聚焦时上下文为空,在第一次自我反思轮次中,MCAF直接将初始化阶段获得的聚类中心帧作为高度相关帧输入到第三步。此过程在图中以虚线表示。
MCAF的注意力聚焦机制由以下关键组件组成:
- 初始化期间基于视觉特征的逐片视频聚类。
-
- 多模态粗到精相关感测(MCRS)能力,包括LLM辅助的语义高度查询相关的视频片段粗选与之前粗选相关片段范围内的多模态细粒度相关帧感测。
-
- 聚焦查询相关帧的DTE操作,以在保持关键信息的同时拓宽时间感受野。
-
- 利用单个LLM通过响应置信度自我反思,分级迭代调整注意力聚焦。
A. 视频逐片聚类
给定一个视频 V ∈ R C × H × W × T V \in R^{C \times H \times W \times T} V∈RC×H×W×T 包含 T T T 个图像帧和一个文本查询 Q Q Q,我们首先对视频进行帧采样(例如均匀采样)以获得采样帧集 s p l _ f r m s = s p l \_f r m s= spl_frms= { F t } t = 1 T / t \left\{F_{t}\right\}_{t=1}^{T / t} {Ft}t=1T/t,其中采样间隔 t t t 由总帧数 T T T 和图像分辨率决定,以确保选出足够的帧用于后续处理。然后对 s p l _ f r m s s p l \_f r m s spl_frms 进行基于视觉特征的聚类,生成 N N N 个聚类中心帧和由这些中心帧分割的 N + 1 N+1 N+1 个视频片段,如初始化阶段所示。
B. 多模态粗到精相关感测(MCRS)
粗选:由于初始化阶段聚类后对目标视频缺乏先验知识,MCAF中的LLM无法进行粗选,我们将所有聚类中心帧视为高度查询相关的帧以启动自我反思过程。随着后续自我反思轮次中上下文的更新,LLM获得了粗选能力,并给出原始选择结果,如图2中的第一步所示。
细聚焦:根据粗选策略,这些选定的视频片段候选者与查询的平均相关性得以保留。但在查询相关内容以视觉形式呈现(例如短时间内前景位置快速变化)的情况下,有可能错过关键细节。为此,我们的MCAF引入了一种基于视觉特征的相关性筛选机制,通过基于标记的相似性匹配将聚焦粒度细化到帧级别。
具体来说,我们首先使用图像编码器对更新后的候选视频片段集 s p l _ c l p s s p l \_c l p s spl_clps 中的 K v K_{v} Kv 帧进行编码。为简化起见,我们假设所有模态编码的特征都在同一维度 d d d,从而得到所有比较帧的视觉标记 T k v _ c f ∈ R N c f × d T k_{v \_c f} \in R^{N_{c f} \times d} Tkv_cf∈RNcf×d。这些视觉标记通过余弦相似性计算和排序 Sim v _ c f = \operatorname{Sim}_{v \_c f}= Simv_cf= sort ( T k v _ c f ⋅ ( T k t ) T ) ∈ R N c f \operatorname{sort}\left(T k_{v \_c f} \cdot\left(T k_{t}\right)^{T}\right) \in R^{N_{c f}} sort(Tkv_cf⋅(Tkt)T)∈RNcf 生成逐帧相似度分数。排名前 K v K_{v} Kv 的视觉标记被视为每个候选者中最相关的查询。然后我们统计每个候选片段中此类相关标记的数量,选择具有最大数量计数的前 K f K_{f} Kf 个片段,并检索其最查询相似的帧作为细聚焦相关帧至fcs_frms。整个过程简单地可视化在图2中的第二步,实施细节在图3中举例说明。
通过这些多模态粗选和细聚焦操作,MCAF使框架能够更有效地集中在与特定理解任务最相关的部分。
C. 膨胀时间扩展(DTE)
根据膨胀卷积网络中扩展感受野在视觉检测任务中的应用,我们对fcs_frms中的每个细聚焦帧的时间感受野进行时间膨胀以获得更广泛的理解视野。具体来说,基于1D卷积表达式
y
[
n
]
=
∑
k
=
0
K
−
1
x
[
n
+
k
]
⋅
z
[
k
]
y[n]=\sum_{k=0}^{K-1} x[n+k] \cdot z[k]
y[n]=∑k=0K−1x[n+k]⋅z[k],1D膨胀卷积可以建模为
y
[
n
]
=
∑
k
=
0
K
−
1
x
[
n
+
y[n]=\sum_{k=0}^{K-1} x[n+
y[n]=∑k=0K−1x[n+
r
⋅
k
]
⋅
z
[
k
]
r \cdot k] \cdot z[k]
r⋅k]⋅z[k]。通过引入膨胀
率
r
r
r,感受野相应地扩大
r
r
r 倍。我们的DTE以每个聚焦片段中心帧为锚点,并对称选择总共
w
n
w n
wn 个在
w
w
w 帧间隔内的膨胀扩展帧范围。在每个范围内,我们然后分别使用参数
s
s
s 和
r
r
r 选择每个中心帧的时间相邻帧。假设细聚焦帧索引为
n
n
n,其DTE过程可以表示为
D
T
E
e
d
_
F
r
a
m
e
[
n
]
=
D T E e d \_F r a m e[n]=
DTEed_Frame[n]=
∑
k
=
−
⌊
w
n
/
2
⌋
⌊
w
n
/
2
⌋
∑
i
=
−
⌊
s
/
2
⌋
⌊
s
/
2
⌋
f
c
s
_
f
r
m
s
[
n
+
k
⋅
w
+
i
⋅
r
]
\sum_{k=-\lfloor w n / 2\rfloor}^{\lfloor w n / 2\rfloor} \sum_{i=-\lfloor s / 2\rfloor}^{\lfloor s / 2\rfloor} f c s \_f r m s[n+k \cdot w+i \cdot r]
∑k=−⌊wn/2⌋⌊wn/2⌋∑i=−⌊s/2⌋⌊s/2⌋fcs_frms[n+k⋅w+i⋅r],其中
∑
\sum
∑ 操作符代表连接。预期DTE可以通过更广泛的时间感受野实现更好的视频理解,如图4所示。
D. 基于迭代响应置信度的自我反思
为了避免在注意力聚焦过程中陷入局部最优,MCAF评估每次响应的置信度水平,并将其作为反馈逐步引导框架的注意力焦点向与查询更一致的区域移动。
具体而言,MCAF中的LLM不仅基于获取的上下文生成响应,还通过置信度分数 C C C 评估提取信息的相关性。如果 C < = 2 C<=2 C<=2,MCAF通过重复步骤1-4迭代调整注意力聚焦,因为相关信息虽相关但不足。当 C = 3 C=3 C=3 时,MCAF直接作答,因为它认为上下文足以生成自信的响应。
与其他基于代理的SOTA解决方案如VideoAgent [57] 或 VCA [50] 不同,后者引入额外的奖励模型来评估每次响应的置信度分数并感知所需的补充信息,MCAF的自我反思循环使单个LLM能够在语义空间内同时执行三个紧密相关的认知过程:响应生成、评估和相关片段重新选择,因为在我们的架构中这些操作都在相同的语义空间内发生。我们的后续实验证实,这种高效的统一不会降低系统的理解能力。完整的MCAF工作流程伪代码如下:
IV. 实验
A. 数据集
我们在这些视频理解基准上进行了全面的实验,比较MCAF的表现与其他SOTA方法:
- EgoSchema [64]:它包含从第一视角视频中提取的5000个单选题,每个样本持续180秒。数据集仅包含测试集,
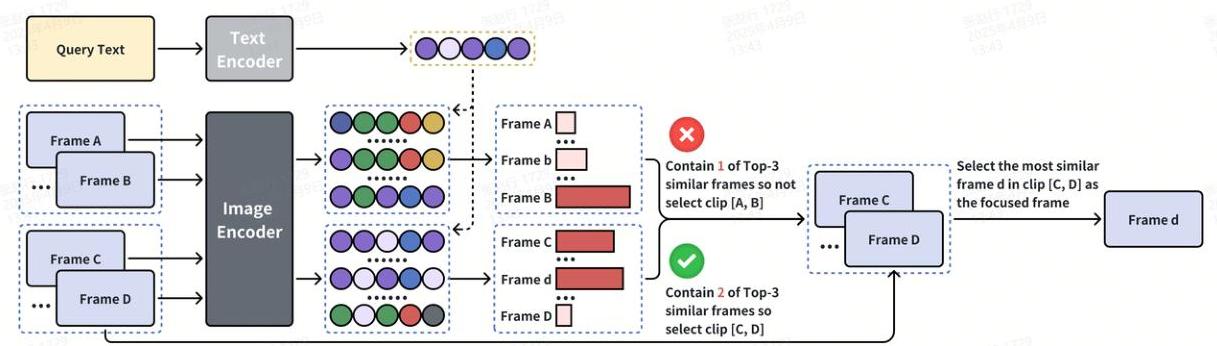
图3:细粒度相关感测过程实现示例。在两个粗选视频片段候选者 [ A , B ] [\mathrm{A}, \mathrm{B}] [A,B] 和 [ C , D ] [\mathrm{C}, \mathrm{D}] [C,D] 之间,我们的细聚焦算法确定后者与查询的相关性更高,因为它包含更多的相关视觉标记。因此,我们选择帧d,它在视频片段[C, D]中具有最高的相似度分数。
算法1 整个MCAF算法
输入:视频
V
V
V,查询
Q
Q
Q,上下文
P
−
c
t
x
P_{-} c t x
P−ctx,答案提示
P
−
a
s
w
P_{-} a s w
P−asw,选择提示
P
−
s
l
c
P_{-} s l c
P−slc,预训练视觉编码模型 video_2_token
(
θ
)
(\theta)
(θ),视频帧采样函数 frame_sampling
(
⋅
)
(\cdot)
(⋅),视频帧聚类函数 frame_clustering
(
⋅
)
(\cdot)
(⋅),视频帧膨胀扩展函数 frame_expansion
(
⋅
)
(\cdot)
(⋅),视频帧字幕模型 frame_captioning
(
θ
)
(\theta)
(θ),语义匹配模型 query_frame_matching
(
θ
)
(\theta)
(θ) 以获取候选重新聚焦片段中最相关的查询帧,视频片段选择模型 relevant_clip_selection
(
θ
)
(\theta)
(θ) 以获取用于自信响应的查询相关片段,视频问答模型 video_question_answer
(
θ
)
(\theta)
(θ),最大允许重复次数
N
N
N,顶级相关视觉标记候选数
K
v
K_{v}
Kv 和最大细聚焦帧数
K
f
K_{f}
Kf,膨胀扩展窗口数
w
n
w n
wn,窗口间隔
w
w
w,每窗口帧数
s
s
s 和每窗口帧间隔
r
r
r
输出:最终答案
A
A
A 和回答置信度
C
C
C
1: 初始化当前重复时间
n
←
0
n \leftarrow 0
n←0,当前回答置信度
C
←
0
C \leftarrow 0
C←0,当前所有中心帧的字幕
c
f
m
_
c
p
t
s
←
∅
c f m \_c p t s \leftarrow \emptyset
cfm_cpts←∅,当前聚焦视频片段
f
c
s
_
c
l
p
s
←
∅
f c s \_c l p s \leftarrow \emptyset
fcs_clps←∅ 及其中心帧
f
c
s
_
c
c
f
s
←
∅
f c s \_c c f s \leftarrow \emptyset
fcs_ccfs←∅
2: 获取采样帧
s
p
l
_
f
r
m
s
←
s p l \_f r m s \leftarrow
spl_frms← frame_sampling
(
V
)
(\mathbf{V})
(V)
3: 执行聚类以获取所有中心帧
f
c
s
_
c
c
f
s
,
f
c
s
_
c
l
p
s
←
f c s \_c c f s, f c s \_c l p s \leftarrow
fcs_ccfs,fcs_clps← frame_clustering(spl_frms)
4: 当
n
<
N
n<N
n<N 且
C
<
3
C<3
C<3 时执行以下操作
5:
e
p
d
_
f
r
m
s
←
e p d \_f r m s \leftarrow
epd_frms← frame_expansion(fcs_clps, fcs_ccfs, wn, w, s, r)
6:
c
f
m
_
c
p
t
s
←
c f m \_c p t s \leftarrow
cfm_cpts← frame_captioning(epd_frms)
7: 使用
c
f
m
_
c
p
t
s
c f m \_c p t s
cfm_cpts 更新
P
−
c
t
x
P_{-} c t x
P−ctx
8:
A
,
C
←
A, C \leftarrow
A,C← video_question_answer
(
Q
,
P
_
(\mathbf{Q}, \mathbf{P} \_
(Q,P_asw,
P
_
\mathbf{P} \_
P_ctx
)
)
)
9: 如果
C
=
=
3
C==3
C==3 则
10: 结束
11: 结束
12:
f
c
s
_
c
l
p
s
←
f c s \_c l p s \leftarrow
fcs_clps← relevant_clip_selection
(
Q
,
P
_
\left(\mathbf{Q}, \mathbf{P} \_\right.
(Q,P_slc,
P
_
\left.\mathbf{P} \_\right.
P_ctx,
K
c
)
\left.\mathbf{K}_{\mathbf{c}}\right)
Kc)
13:
f
c
s
_
c
l
p
s
,
f
c
s
_
c
c
f
s
←
f c s \_c l p s, f c s \_c c f s \leftarrow
fcs_clps,fcs_ccfs← query_clip_matching(video_2_token(fcs_clps),
K
f
)
\left.\mathbf{K}_{\mathbf{f}}\right)
Kf)
14:
n
=
n
+
1
n=n+1
n=n+1
15: 结束循环
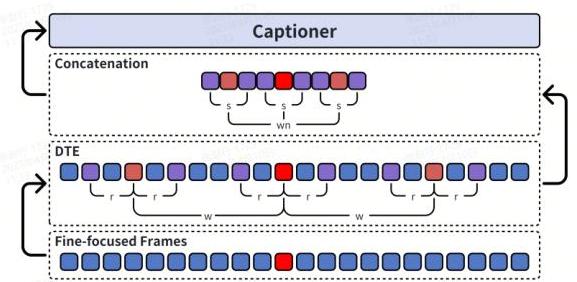
图4:第3步中DTE过程示例,参数
w
=
7
,
r
=
2
,
w
n
=
3
w=7, r=2, w n=3
w=7,r=2,wn=3 和
s
=
3
s=3
s=3 显示每个细聚焦帧通过DTE扩展总共9帧。这些参数可以自适应调整。
其中包含500个有注释标签的问题子集。
- NExT-QA [65]:它包含5440个描绘日常物体交互的自然主义视频,以及48000个多项选择题。每个视频平均长度为44秒。按照既定的评估协议,我们在构成验证集的570个视频上进行零样本评估,共计4,969项任务。
-
- Intent-QA [66]:该数据集旨在进行人类意图推理,包含4,303个视频和16000个问答对。我们在零样本条件下使用测试集进行评估,特别关注576个必要视频,总计2,134项任务。
-
- Video-MME [67]:该数据集包括多样化的超长视频(最长超过60分钟)。它利用多样化的真实世界视频和需要时空分析、情感识别和多事件理解的问题。
B. 实现细节
我们在所有上述提到的数据集上以多项选择题回答设置评估MCAF,采用标准准确率指标进行所有实验。
对于EgoSchema [64]、IntentQA [66] 和 NExTQA [65] 数据集,我们以1 FPS采样原始视频,而Video-MME数据集则以0.5 FPS采样。对于EgoSchema [64] 和 Video-MME [67],我们应用Qwen2-VL-7B [15]模型提取字幕。对于IntentQA [66] 和 NExT-QA [65],我们分别利用LLaVA-NeXT [11] 和 CogAgent [21] 模型生成帧级字幕。
在对比实验中,我们列出其他以ChatGPT-4 [7]为主要模型的解决方案以确保公平性。由于ChatGPT-4 [7]的上下文长度限制,我们为EgoSchema [64]、NExT-QA [65] 和 IntentQA [66] 数据集配置DTE参数为 w n = 3 , s = 3 , r = 2 w n=3, s=3, r=2 wn=3,s=3,r=2,和 w = 6 w=6 w=6。对于Video-MME [67] 的长片段部分,这些参数调整为 w n = 3 , s = 5 w n=3, s=5 wn=3,s=5, r = 1 r=1 r=1, 和 w = 6 w=6 w=6。
在推理过程中,我们实施并行处理策略以高效提取DTE后连接的聚焦帧的文本特征,这显著增强了推理效率。
C. 结果与分析
我们首先在上述四个主流视频数据集上测试MCAF的性能,这些视频数据集具有不同的视频长度:
根据表I汇总的比较结果,MCAF在三个数据集上平均优于所有其他SOTA方法(基于代理或基于视频-MLLM的方法,例如使用相关视频数据集预训练的LVNet [45])。我们还列出了这些方法所使用的基模型类型。在EgoSchema [64] 数据集上,它比之前的领先方法提高了显著的5%性能。而在NExT-QA [65] 数据集上,MCAF的整体性能比其他方法高出 0.2 % 0.2 \% 0.2%。在它的四个子类别中,MCAF在三个类别中排名第一,并在其余一个类别中获得第二名。对于Intent-QA [66] 数据集,MCAF比第二名方法高出 0.2 % 0.2 \% 0.2%。这些成就有力证明了我们提出的方法在处理视频理解任务方面的有效性。
为了进一步突出我们方法在处理长视频方面的优势,我们还在Video-MME [67]的长片段部分进行了具有挑战性的比较。如表I再次所示,我们的方法在响应准确性上达到 57.1 % 57.1 \% 57.1%,优于所有其他列出的SOTA基于代理的解决方案和一些需要微调的开源视频模型如InternVL2 [77]。值得注意的是,那些表现优于我们的解决方案利用了更新的大规模模型,其参数量更大且训练成本高于我们的核心模型。
我们还研究了自我反思机制对准确度的影响。图5显示了在不同自我反思轮次下,我们的MCAF与另外两个基于自我反思的代理解决方案在EgoSchema [64] 数据集上的比较。我们发现:
MCAF通过多轮自我反思显著提高了响应准确性,始终优于DrVideo [49] 和 VideoAgent [57]。尽管DrVideo [49] 在第二轮达到峰值,VideoAgent [57] 在第三轮达到峰值,
表I:在EgoSchema、IntentQA、NExT-QA和Video-MME数据集上的比较结果。
| 解决方案 | (M)LLMs | 数据集 | |||||
|---|---|---|---|---|---|---|---|
| EgoSchema | IntentQA | NExT-QA | |||||
| 时间 | 因果 | 描述性 | 平均 | ||||
| 基于专有MLLMs | |||||||
| LVNet [45] | ChatGPT-4o | 68.2 | - | 65.5 | 75.0 | 81.5 | 72.9 |
| VideoChat2 [32] | ChatGPT-4 | 54.4 | - | - | - | - | 61.7 |
| Vamos [73] | ChatGPT-4 | 51.2 | 68.5 | - | - | - | - |
| IG-VLM [26] | ChatGPT-4v | 59.8 | 64.2 | 63.6 | 69.8 | 74.7 | 68.6 |
| 基于开源MLLMs | |||||||
| MVU [51] | Mistral-13B | 60.3 | - | 55.4 | 48.1 | 64.1 | 55.2 |
| LangRepo [54] | Mirstral-8×7B | 66.2 | 59.1 | 51.4 | 64.4 | 69.1 | 60.9 |
| SeViLA [25] | BLIP-2 | - | 60.9 | - | - | - | - |
| LongVA [76] | Qwen2-7B-Instruct | - | - | - | - | - | - |
| InternVL2 [77] | LLaMa | - | - | - | - | - | - |
| LLaVa-OneVision-72B [78] | Qwen2 | - | - | - | - | - | - |
| Qwen2-VL-72B [15] | Qwen2-VL-72B | - | - | - | - | - | - |
| 基于无训练代理 | |||||||
| LLoVi [53] | ChatGPT-4 | 61.2 | 64.0 | 61.0 | 69.5 | 75.6 | 67.7 |
| VideoAgent [58] | ChatGPT-4 | 60.2 | - | 64.5 | 72.7 | 81.1 | 71.3 |
| VideoAgent [57] | ChatGPT-4v | 62.8 | - | 60.0 | 76.0 | 76.5 | 70.8 |
| GraphVideoAgent [68] | ChatGPT-4 | 62.7 | - | 74.6 | 65.2 | 83.5 | 73.3 |
| LifelongMemory [48] | ChatGPT-4 | 65.0 | - | - | - | - | 72.3 |
| VideoTree [59] | ChatGPT-4 | 66.2 | 66.9 | 70.6 | 76.5 | 83.9 | 75.6 |
| VideoINSTA [60] | ChatGPT-4 | 65.0 | 72.8 | - | - | - | 72.3 |
| DrVideo [49] | ChatGPT-4 | 61.0 | - | - | - | - | - |
| CLARF (Ours) | ChatGPT-4 | 73.4(+5.2) | 73.1(+0.3) | 70.8 | 77.2 | 84.1 | 75.8(+0.2) |
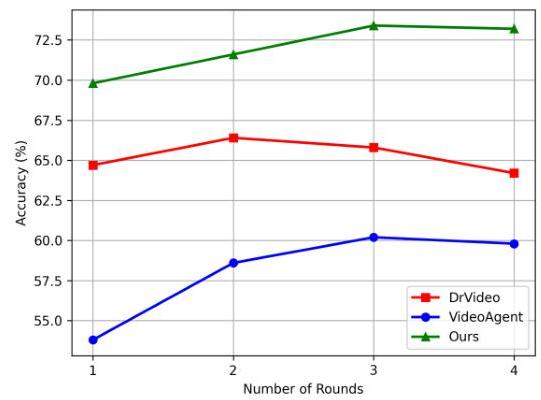
图5:MCAF在EgoSchema数据集上反映推理过程以回答问题的演示。
我们的MCAF通过更多轮次实现了稳定的精度提升,突显了其自我反思机制的有效性。此外,DrVideo [49] 由于过度思考导致响应准确性下降,表明仅通过过多信息进行更多理解并不一定能使模型受益。
D. 案例研究
图6和图7分别展示了MCAF在EgoSchema [64]和IntentQA [66]数据集上的反思推理过程。最初,我们定义一轮只有在执行相关片段选择模型的操作后才完整;否则,标记为零轮。在图6中,MCAF首先以1 FPS采样原始视频,并获得三个聚类中心:第8帧、第14帧和第38帧。MCAF直接将这三个聚类中心帧作为细聚焦帧,并在标题基于语义提取之前使用参数
w
n
=
1
,
w
=
0
,
r
=
2
w n=1, w=0, r=2
wn=1,w=0,r=2,和
s
=
s=
s= 3 对它们执行DTE。由于MCAF无法基于这个上下文生成高置信度答案,它继续粗略选择从第14帧到第38帧的片段作为粗选结果。随后,通过细聚焦,它感知到第29帧是最相关的查询,以更新上下文。这个增强的上下文能够为MCAF提供更多相关和综合的信息,并成功预测一个高度置信且正确的答案。同样,图7展示了MACF在IntentQA [66]数据集上另一个测试案例的推理过程,否则在VideoTree [59]框架中未正确响应。
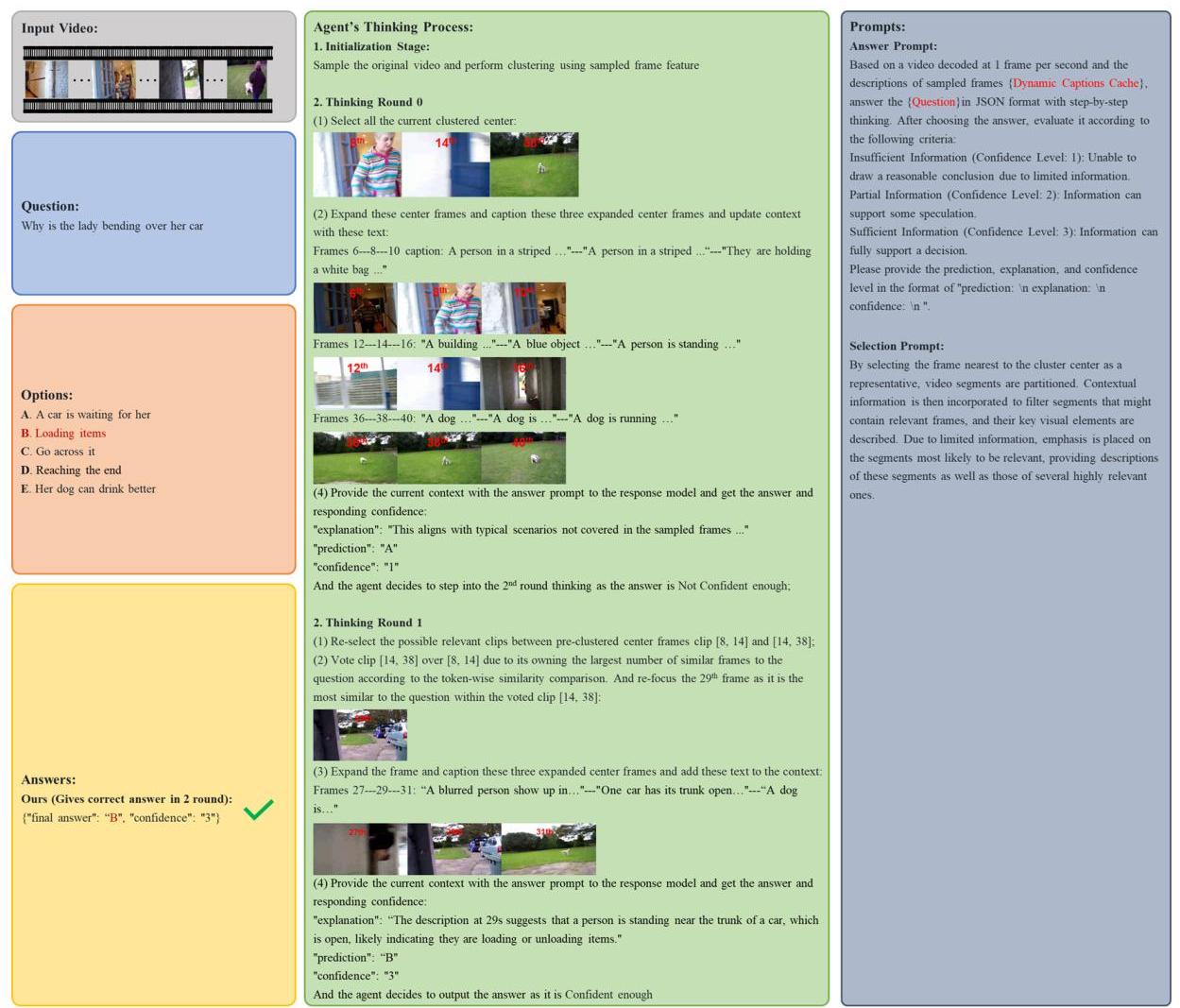
图6:MCAF在EgoSchema [64]数据集上反映推理过程以回答问题的演示。
E. 消融实验
我们在EgoSchema [64]数据集上设计了全面的消融实验,该数据集产生了最佳实验结果,以展示MCAF核心模块的重要性。
我们首先进行消融比较以评估MCRS框架中的两个关键创新模块:MCRS、DTE和自我反思模块。从表II可以看出,没有自我反思反馈的情况下,大约 8.1 % 8.1 \% 8.1%的查询在单轮中无法正确回答。这显示了我们的整体自我反思机制在解决难以首次正确回答的问题方面的优越性。我们进一步对关键模块MCRS进行消融比较。我们使用基于标记的相似性匹配代替MCRS,结果准确率显著下降了 7.4 % 7.4 \% 7.4%。特别是在概括或总结查询的情况下,仅仅依赖标记级相似性匹配极有可能导致错误答案,因为它将注意力聚焦限制在局部模式上。DTE的重要性也在表II中得到了验证,其准确率提高了预期的 9.4 % 9.4 \% 9.4%。这证明了即使在精心设计的注意力聚焦机制之上,有效的语义信息提取也是不可或缺的。
表II:MCAF核心组件的消融实验
| 条件 | 准确率 |
|---|---|
| 完整MCAF | 73.4 |
| 无自我反思 | 65.3 ( − 8.1 ) 65.3(-8.1) 65.3(−8.1) |
| 无MCRS | 66.0 ( − 7.4 ) 66.0(-7.4) 66.0(−7.4) |
| 无DTE | 64.1 ( − 9.3 ) 64.1(-9.3) 64.1(−9.3) |
表III显示了在MCRS模块的细聚焦步骤中不同视觉编码器对响应准确率的影响

图7:MCAF在IntentQA [66]数据集上反映推理过程以回答问题的演示。
模块对响应准确率的影响。比较显示视觉编码器的参数大小和输入图像分辨率对整体准确率有积极影响。
表III:视觉编码器的消融实验
| 视觉编码器 | 参数 | 分辨率 | 准确率 |
|---|---|---|---|
| OpenCLIP:ViT-G [72] | 1B | 224 | 70.5 |
| EVA-CLIP-8B [69] | 8B | 224 | 73.4 \mathbf{7 3 . 4} 73.4 |
| EVA-CLIP-8B-plus [69] | 8B | 448 | 71.4 |
为了评估MCAF中VLM的语义提取能力,我们纳入了三种基于VLM的字幕生成器:基于帧的Qwen-2-VL-7B [63]、LLaVA-NeXT [11]和基于片段的LaViLa [62]。如表IV所示,Qwen-2-VL-7B由于其在捕获动态对象信息方面的优越性,取得了最佳表现,这更适合我们EgoSchema [64]数据集的内容。------
表IV:基于VLM的字幕生成器的消融实验
| 字幕生成器 | 输入 | 准确率 |
|---|---|---|
| LLaVA-NeXT [11] | 帧级 | 68.1 |
| Qwen2-VL-7B [15] | 帧级 | 73.4 \mathbf{7 3 . 4} 73.4 |
| LaViLa [62] | 片段级 | 71.1 |
为了评估我们MCAF中基于单个LLM的反思器的能力
------,表V展示了这三种集成LLM的比较。由于MCAF中的LLM需要扮演响应者、评估者和粗相关视频片段选择者的角色,推理能力较强的模型如DeepSeek-V3 [3] 和 ChatGPT-4 [7] 如预期那样取得了更高的准确率。随着LLM推理能力的提高,MCAF框架的响应准确率也随之提高。
表V:作为反思器的LLM的消融实验
| 反思器 | 类型 | 尺寸 | 准确率 |
|---|---|---|---|
| Llama-3.3-70B [1] | 开源 | 70B | 66.9 |
| DeepSeek-V3 [3] | 开源 | 70B | 70.6 |
| Qwen2.5-72B [5] | 开源 | 72B | 69.7 |
| ChatGPT-4 [7] | 专有 | - | 73.4 \mathbf{7 3 . 4} 73.4 |
表VI展示了在MCRS模块的细聚焦步骤中候选帧数 K v K_{v} Kv 的有效性。忽略计算成本,来自粗选片段候选者的更多帧参与能够生成更多相关的细粒度匹配。结果验证了这一预期。
表VII和VIII说明了MCAF框架中DTE扩展范围与响应准确率的关系。我们在消融实验中列出了
w
n
w n
wn 和
r
r
r,它们是我们框架中的关键超参数。其他参数
表VI:执行细聚焦的候选帧数量的消融实验
| 相似性候选者 | 准确率 |
|---|---|
| 30 | 70.6 |
| 60 | 73.0 |
| 90 \mathbf{9 0} 90 | 73.4 \mathbf{7 3 . 4} 73.4 |
保持固定。结果显示更高的扩展并不一定导致更高的准确率,因为过度的时间扩展可能会将噪声引入先前关注的帧中。
表VII:DTE范围的消融实验
| DTE中的 w n w n wn | 准确率 |
|---|---|
| 1 \mathbf{1} 1 | 69.0 |
| 3 \mathbf{3} 3 | 73.4 \mathbf{7 3 . 4} 73.4 |
| 5 | 71.2 |
表VIII:DTE帧间隔的消融实验
| DTE中的 r r r | 准确率 |
|---|---|
| 1 \mathbf{1} 1 | 70.4 |
| 2 \mathbf{2} 2 | 73.4 \mathbf{7 3 . 4} 73.4 |
| 3 | 71.4 |
V. 未来工作
在这项工作中,我们提出了MCAF,一个高效的基于代理的视频理解框架。它具有多模态粗到精的相关感测和增强膨胀时间扩展功能,用于语义提取,并通过类似人类的迭代自我反思进行组织。我们证明了我们的MCAF无需使用领域内数据或其他定制工具进行大量监督微调即可实现最先进的(SOTA)性能和效率。
尽管MCAF在测试数据集上表现出SOTA性能,但它仍面临以下挑战:(1) 高计算延迟被认为是长视频处理过程中的主要瓶颈;这个问题也存在于其他同期解决方案如LLoVi [53] 和 DrVideo [49] 中。(2) 在每轮自我反思过程中实现上下文中语义信息保留与去除之间的自适应平衡。在未来,利用更广泛的数据库或更先进的分析方法可以产生更深的见解,并进一步加强结果的适用性。
参考文献
[1] Meta. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024.
[2] OpenAI. GPT-4o System Card. arXiv preprint arXiv:2410.21276, 2024.
[3] DeepSeek. DeepSeek-V3 Technical Report. arXiv preprint arXiv:2412.19437v2, 2025.
[4] QwenTeam. Qwen2 Technical Report. arXiv preprint arXiv:2407.10671v4, 2024.
[5] QwenTeam. Qwen2.5 Technical Report. arXiv preprint arXiv:2412.15115v2, 2024.
[6] Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An opensource chatbot impressing gpt-4 with
90
%
90 \%
90% * chatgpt quality. https://vicuna.lmsys.org, 2023.
[7] OpenAI. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
[8] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Roziere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
[9] Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In CVPR, pages 24185-24198, 2024.
[10] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In CVPR, pages 26296-26306, 2024.
[11] Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, 2024.
[12] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. NeurIPS, 36, 2024.
[13] Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Yaofeng Sun, et al. Deepseek-vl: towards real-world vision-language understanding. arXiv preprint arXiv:2403.05525, 2024.
[14] QwenTeam. Qwen2.5-VI, Technical Report, arXiv preprint arXiv:2409.12191v2, 2025.
[15] Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhibao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, Junyang Lin. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution. arXiv preprint arXiv:2409.12191v2, 2024.
[16] Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models. arXiv preprint arXiv:2402.12289, 2024.
[17] Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, Qianyu Chen, Huarong Zhou, Zhensheng Zou, Haoye Zhang, Shengding Hu, Zhi Zheng, Jie Zhou, Jie Cai, Xu Han, Guoyang Zeng, Dahai Li, Zhiyuan Liu, and Maosong Sun. Minicpm-v: A gpt-4v level mllm on your phone. arXiv preprint 2408.01800, 2024.
[18] Le Xue, Manli Shu, Anas Awadalla, Jun Wang, An Yan, Senthil Puuobwvalkam, Honglu Zhou, Viraj Prabhu, Yutong Dai, Michael S Ryoo, Shrikant Kendre, Jieyu Zhang, Can Qin, Shu Zhang, Chia-Chih Chen, Ning YuJuntao Tan, Tulika Manoj Awalgaonkar, Shelby Heinecke, Huan Wang, Yejin Choi, Ludwig Schmidt, Zeyuan Chen, Silvio Savarese, Juan Carlos Niebles, Caiming Xiong, Ran Xu. xGen-MM (BLIP3): A Family of Open Large Multimodal Models. arXiv preprint arXiv:2408.08872, 2024.
[19] Jannan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023.
[20] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified visionlanguage understanding and generation. In International Conference on Machine Learning, pages 12888-12900, PMLR, 2022.
[21] Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. Cogagent: A visual language model for gui agents. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14281-14290, 2024.
[22] Ziyuan Qin, Huahui Yi, Qicheng Lao,Kang Li. Medical Image Understanding with Pretrained Vision Language Models: A Comprehensive Study. arXiv preprint arXiv:2209.15517, 2022.
[23] An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Zaitian Gongyz, Xuaiyan Zou, Jan Kautz, Erdem Biyik, Hongxu Yin, Sifei Liu, Xiaolong Wang. NaVILA: Legged Robot Vision-Language-Action Model for Navigation. arXiv preprint arXiv:2412.04453, 2024.
[24] Huang, Bin and Wang, Xin and Chen, Hong and Song, Zihan and Zhu, Wenwu. Vtimellm: Empower llm to grasp video moments. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14271-14280, 2024.
[25] Yu, Shoubin and Cho, Jaemin and Yadav, Prateek and Bansal, Mohit. Self-Chained Image-Language Model for Video Localization and Question Answering. In Proceedings of the 37th International Conference on Neural Information Processing Systems (NeurIPS), pages 13647-13657, 2023.
[26] Wonkyun Kim, Changin Choi, Wonseok Lee, and Wonjong Rhee. An image grid can be worth a video: Zeroshot video question answering using a vlm. arXiv preprint arXiv:2403.18406, 2024.
[27] Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, and Jiashi Feng. Pflava: Parameter-free llava extension from images to videos for video dense captioning. arXiv preprint arXiv:2404.16994, 2024.
[28] Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Xun Guo, Tian Ye, Yan Lu, Jenq-Neng Hwang, et al. Moviechat: From dense token to sparse memory for long video understanding. arXiv preprint arXiv:2307.16449, 2023.
[29] Salman Khan Muhammad Maaz, Hanoona Rasheed and Fahad Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. ArXiv 2306.05424, 2023.
[30] Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. arXiv preprint arXiv:2306.02858, 2023.
[31] VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs. arXiv preprint arXiv:2406.07476v3, 2024.
[32] Kunchang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355, 2023.
[33] Muhammad Maaz, Hanoona Rasheed, Salman Khan, Fahad Shahbaz Khan. Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models. arXiv preprint arXiv:2306.05424v2, 2024.
[34] Peng Jin, Ryuichi Takanobu, Caiwan Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation empowers large language models with image and video understanding. arXiv preprint arXiv:2311.08046v3, 2024.
[35] Muhammad Maaz, Hanoona Rasheed, Salman Khan, FahadKhan. VideoGPT+: Integrating Image and Video Encoders for Enhanced Video Understanding. arXiv preprint arXiv:2406.09418, 2024.
[36] Enxin Song, Wenhao Chai, Tian Ye, Jeng-Neng Hwang, Xi Li, Gaoang VVang. MovieChat+: Question-aware Sparse Memory for Long Video Question Answering. arXiv preprint arXiv:2404.17176, 2024.
[37] Dan Kondratyuk, Lijun Yu, Xiuye Gu, José Lezama, Jonathan Huang, Rachel Hornung, Hartwig Adam, Hassan Akbari,
Yair Alon, Vighnesh Birodkar, et al. Videopoet: A large language model for zero-shot video generation. arXiv preprint arXiv:2312.14125, 2023.
[38] Bin Lin, Bin Zhu, Yang Ye, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. arXiv preprint arXiv:2311.10122, 2023a.
[39] Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, Bohan Zhualing. LongVLM: Efficient Long Video Understanding via Large Language Models. arXiv preprint arXiv:2404.03384v3, 2023.
[40] Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zangg, Zehui Chen, Haosong Duan, Bin Lin, Zhenyu Tang, Li Yuan, Yu QiaoDahua Lin, Feng Zhao, Jiaqi Wang. ShareGPT4Video: Improving Video Understanding and Generation with Better Captions. arXiv preprint arXiv:2406.04325, 2024.
[41] Luo, R., Zhao, Z., Yang, M., Dong, J., Qiu, M., Lu, P., Wang, T., Wei, Z.: Valley: Video assistant with large language model enhanced ability. arXiv preprint arXiv:2306.07207, 2023.
[42] Xijun Wang, Junbang Liang, Chun-Kai Wang, Kenan Deng, Yu Lou, Ming Lin, Shan Yang. ViLA: Efficient VideoLanguage Alignment for Video Question Answering. In ECCV, pages 186-204, 2024.
[43] Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. arXiv preprint arXiv:2404.07972, 2024.
[44] Junke Wang, Dongdong Chen, Chong Luo, Xiyang Dai, Lu YuarZuxuan Wu, Yu-Gang Jiang. ChatVideo: A Trackletcentric Multimodal and Versatile Video Understanding System. arXiv preprint arXiv:2304.14407, 2024.
[45] Kumara Kahatapitiya, Kanchana Ranasinghe, Jongwoo Park, and Michael S Ryoo. Language repository for long video understanding. arXiv preprint arXiv:2403.14622, 2024.
[46] Dídac Surís, Sachit Menon, and Carl Vondrick. Vipergpt: Visual inference via python execution for reasoning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 11888-11898, 2023.
[47] Rohan Choudhury, Koichiro Niinuma, Kris M. Kitani, and Laszlo A. Jeni. Zero-shot video question answering with procedural programs. arXiv preprint arXiv:2312.00937, 2023.
[48] Ying Wang, Yanlai Yang, and Mengye Ren. LibfongMemory: Leveraging LLMs for answering queries in long-form egocentric videos, 2024.
[49] Ziyu Ma, Chenhui Gou, Hengcan Shi, Bin Sun, Shutao Li, Hamid Rezatofighi, Jianfei Cai. DeVideo: Document Retrieval Based Long Video Understanding. arXiv preprint arXiv:2406.12846, 2024.
[50] Zeysan Yang, Delin Chen, Xueyang Yu, Maohao Shen, Chuang Gan. VCA: Video Curious Agent for Long Video Understanding. arXiv preprint arXiv:2412.10471v2, 2025.
[51] Kanchana Ranasinghe, Xiang Li, Kumara Kahatapitiya, Michael S. Ryoo. Understanding Long Videos with Multimodal Language Models. arXiv preprint arXiv:2403.16998v4, 2025.
[52] Zongxin Yang, Guikun Chen, Xiaodi Li, Wenguan Wang, and Yi Yang. Doraemongpt: Toward understanding dynamic scenes with large language models. arXiv preprint arXiv:2401.08392, 2024.
[53] Ce Zhang, Taixi Lu, Md Mohaimimul Islam, Ziyang Wang, Shoubin Yu, Mohit Bansal, Gedas Bertasius. A Simple LLM Framework for Long-Range Video Question-Answering. arXiv preprint arXiv:2312.17235v3, 2024.
[54] Jongwoo Park, Kanchana Ranasinghe, Kumara Kahatapitiya, Wonjeong Ryoo, Donghyun Kim, and Michael S Ryoo. Too many frames, not all useful: Efficient strategies for long-form video qa. arXiv preprint arXiv:2406.09396, 2024.
[55] Kevin Lin, Faisal Ahmed, Linjie Li, Chung-Ching Lin, Ehsan Azarmasah, Zhengyuan Yang, Jianfeng Wang, Lin Liang, Zicheng LiuYumao Lu, Ce Liu, Lijuan Wang. MM-VID: Advancing Video Understanding with GPT-4V(ision). arXiv preprint arXiv:2310.19773, 2023.
[56] Chaoyi Zhang, Kevin Lin, Zhengyuan Yang, Jianfeng Wang, Linjie Li, Chung-Ching Lin, Zicheng Liu, Lijuan Wang. MMNarrator: Narrating Long-form Videos with Multimodal InContext Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13647-13657, 2024.
[57] Fan, Yue and Ma, Xiaojian and Wu, Rujie and Du, Yuntao and Li, Jiaqi and Gao, Zhi and Li, Qing. Videoagent: A memory-augmented multimodal agent for video understanding. In ECCV, pages 75-92, 2025.
[58] Xiaohan Wang, Yuhui Zhang, Orr Zohar, Serena Yeung-Levy. VideoAgent: Long-Form Video Understanding with Large Language Model as Agent. In ECCV, pages 58-76, 2024.
[59] Ziyang Wang, Shoubin Yu, Elias Stengel-Eskin, Jaehong Yoon, Ferng Cheng, Gedas Bertasius, Mohit Bansal. VideoTree: Adaptive Tree-based Video Representation for LLM Reasoning on Long Videos. arXiv preprint arXiv:2405.19209v3, 2025.
[60] Ruotong Liao, Max Erler, Huiyu Wang, Guangyao Zhai, Gengyuan Zhang, Yunpu Ma, Volker Tresp. VideoINSTA: Zero-shot Long Video Understanding via Informative Spatial-Temporal Reasoning with LLMs. arXiv preprint arXiv:2409.20365v2, 2024.
[61] Jun Zhao, Can Zu, Hao Xu, Yi Lu, Wei He, Yiwen Ding, Tao Gui, Qi Zhang, and Xuanjing Huang. Longagent: Scaling language models to 128 k context through multi-agent collaboration. arXiv preprint arXiv:2402.11550, 2024.
[62] Yue Zhao, Ishan Misra, Philipp Krühenbühl, Rohit Girdhar. Learning video representations from large language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6586-6597, 2023.
[63] Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966, 2023.
[64] Karttikeya Mangalam, Raiymbek Akshulakov, Jitendra Malik. EgoSchema: A Diagnostic Benchmark for Very Long-form Video Language Understanding. arXiv preprint arXiv:2308.09126, 2023.
[65] Junbin Xiao, Xindi Shang, Angela Yao, Tat-Seng Chua. NExT-QA:Next Phase of Question-Answering to Explaining Temporal Actions. arXiv preprint arXiv:2105.08276, 2021.
[66] Li, Jiapeng and Wei, Ping and Han, Wenjuan and Fan, Lifeng. IntentQA: Context-aware Video Intent Reasoning. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11963-11974, 2023.
[67] Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Rongrong Ji, Xing Sun. Video-MME: The FirstEver Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis. arXiv preprint arXiv:2405.21075, 2024.
[68] Meng Chu, Yicong Li, Tat-Seng Chua. Understanding Long Videos via LLM-Powered Entity Relation Graphs. arXiv preprint arXiv:2405.21075, 2024. arXiv preprint arXiv:2501.15953, 2025.
[69] Quan Sun, Jinsheng Wang, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, and Xinlong Wang. EVA-CLIP18B: Scaling clip to 18 billion parameters. arXiv preprint arXiv:2402.04252, 2024.
[70] Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023. arXiv preprint arXiv:2310.06825, 2023.
[71] Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume
Lample, Lélio Renard Lavaud, Lucile Saulnier, MarieAnne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mixtral of experts. arXiv preprint arXiv:2401.04088, 2023.
[72] Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. arXiv preprint arXiv:2212.07143v2, 2024.
[73] Shijie Wang, Qi Zhao, Minh Quan Do, Nakul Agarwal, Kwonjoon Lee, and Chen Sun. Vamos: Versatile action models for video understanding. arXiv preprint arXiv:2311.13627v3. 2024.
[74] Anthropic. Claude-3.5-sonnet. https://www.anthropic.com/ news/claude-3-5-sonnet.
[75] Google. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530v5, 2023.
[76] Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, JingkangYang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, Ziwi Liu. Long Context Transfer from Language to Vision. arXiv preprint arXiv:2406.16852v2, 2023.
[77] InternVL2 Team. Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling. arXiv preprint arXiv:2412.05271, 2024.
[78] Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, Chunyuan Li. LLaVA-OneVision: Easy Visual Task Transfer. arXiv preprint arXiv:2408.03326v3, 2024.
参考论文:https://arxiv.org/pdf/2504.17213


















 787
787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











