






Kimi-Audio:引领音频大模型的全新时代
原创 OpenCSG社区 OpenCSG社区 2025年04月28日 14:45 上海
2025年4月,由月之暗面(Moonshot AI)杨植麟团队领导研发的Kimi-Audio模型横空出世,这款被称为"语音世界大一统"的音频大模型一经发布就引起业内广泛关注。Kimi-Audio不仅开源代码和模型参数,还提供了完整的评测工具包,标志着音频AI领域迈入了一个新的时代。本文将深入介绍这一开创性技术的核心特点、技术架构、训练方法以及性能表现。

全能型音频大模型
Kimi-Audio被设计为一个真正的通用音频基础模型,支持多种音频处理任务,包括:
-
语音识别(ASR)
-
音频理解与问答(AQA)
-
音频字幕生成(AAC)
-
语音情感识别(SER)
-
声音事件/场景分类(SEC/ASC)
-
文本到语音转换(TTS)
-
语音转换(VC)
-
端到端语音对话
与以往仅专注于单一领域的音频模型不同,Kimi-Audio能够"听"、"说"、"理解"和"对话",且支持实时语音会话和多轮交流,实现了音频全场景的能力统一。
核心亮点
创新技术架构
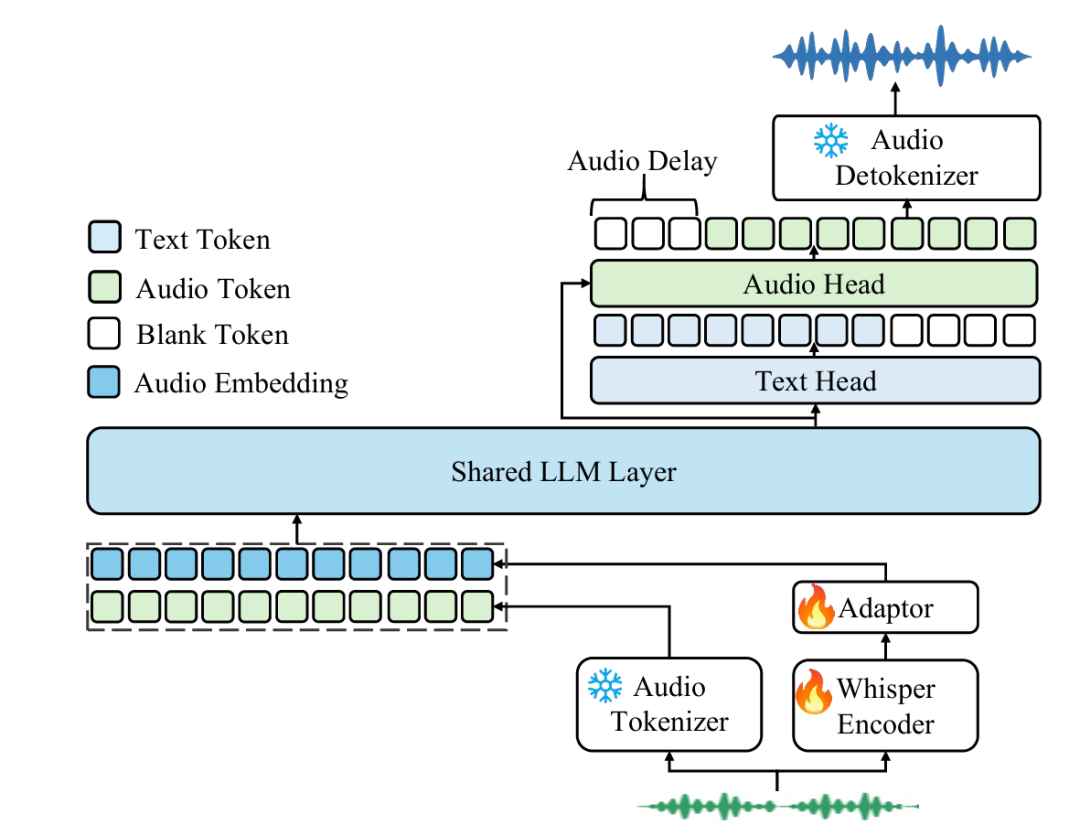
Kimi-Audio采用了三大核心组件构成的集成式架构:
1. 音频分词器(Audio Tokenizer)
-
将输入音频转化为离散语义tokens,帧率为12.5Hz
-
同时提取连续声学向量以增强感知能力
-
既能理解"说了什么"(语义内容),又能保留"怎么说"(音色、情感等细节)
2. 音频大模型(Audio LLM)
-
基于Qwen2.5 7B模型初始化
-
设计为"多模态大脑",同时处理音频词和文本词
-
采用共享transformer层结构,上层分为两个输出头:
-
文本头:专门"写字"输出文本
-
音频头:专门"说话"输出音频
-
-
这种设计使模型能同时具备强大的文本和音频处理能力
3. 音频反分词器(Audio Detokenizer)
-
使用流匹配(flow matching)技术将离散语义tokens转回连贯的音频波形
-
采用"分块+流式"方案处理长音频,每块单独快速合成后拼接
-
实现了"look-ahead"机制,让音频合成更自然,避免断句感
空前规模的预训练
Kimi-Audio的重要突破在于其前所未有的预训练规模和精心设计的数据处理管线:
- 预训练数据量
高达1300万+小时的音频数据,覆盖语音、音乐、环境声等
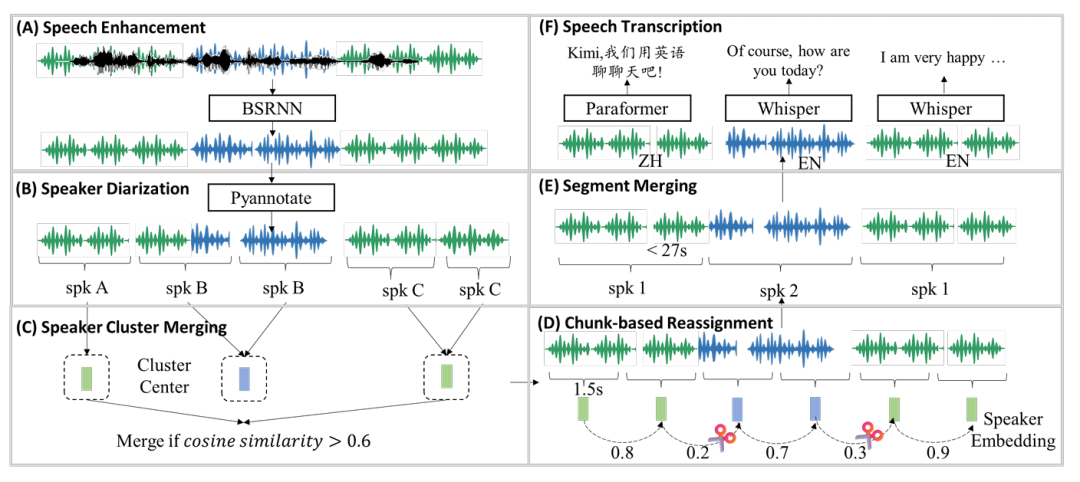
- 自动化数据管线
团队搭建了完整的自动化流水线处理原始音频
-
语音增强:使用AI降噪处理
-
说话人分割:采用PyAnnote工具进行声音分段
-
转写与标注:对英文使用Whisper模型,对中文使用FunASR的Paraformer-Zh
-
根据时间戳智能添加标点,保证数据质量
-
精心设计的训练策略
Kimi-Audio的训练分为两个阶段:
1. 万能预训练
- 多任务混合学习
-
纯文本学习(使用MoonLight数据)
-
纯音频学习
-
音频对文本/文本对音频互转任务
-
音频-文本交错混合任务
-
2. 精细指令微调
- 自然语言指令控制
不同任务通过指令区分,不需人为切换
- 多样化指令集
为ASR任务构建200条指令,其他任务30条,训练时随机选择
- 双模态指令
构建音频和文本两种指令版本,增强模型理解能力
- 大规模微调数据
约30万小时的监督微调数据
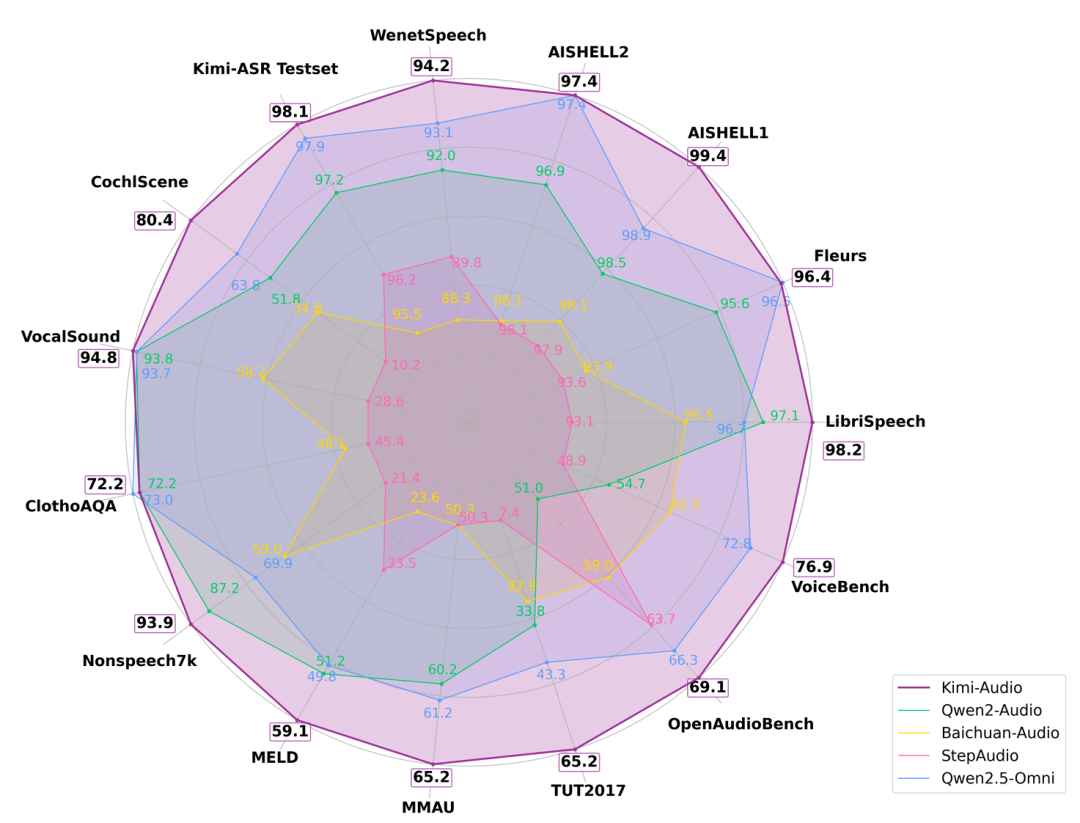
卓越性能表现
Kimi-Audio在多项基准测试中展现出了领先的性能:
语音识别(ASR)
-
LibriSpeech英文测试集:WER仅1.28%,远优于Qwen2.5-Omni的2.37%
-
AISHELL-1中文:WER 0.60%,比上一代模型低一半
-
WenetSpeech多场景测试:在会议和网络场景中均表现最佳

音频理解
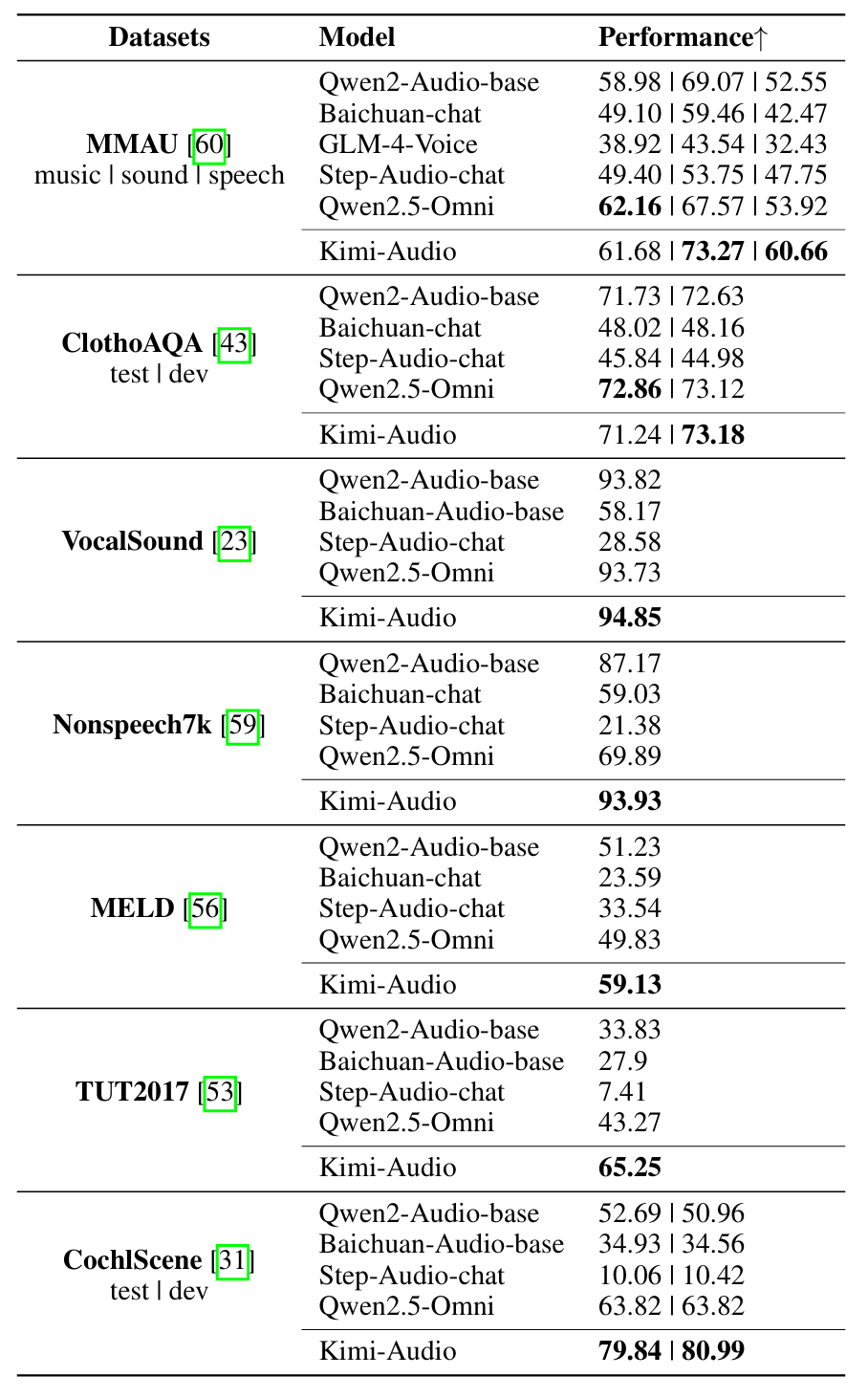
-
MMAU声音理解类:得分73.27,超越所有竞品
-
VocalSound测试:高达94.85%,接近满分
-
MELD语音情感理解:59.13分,明显高于其他模型
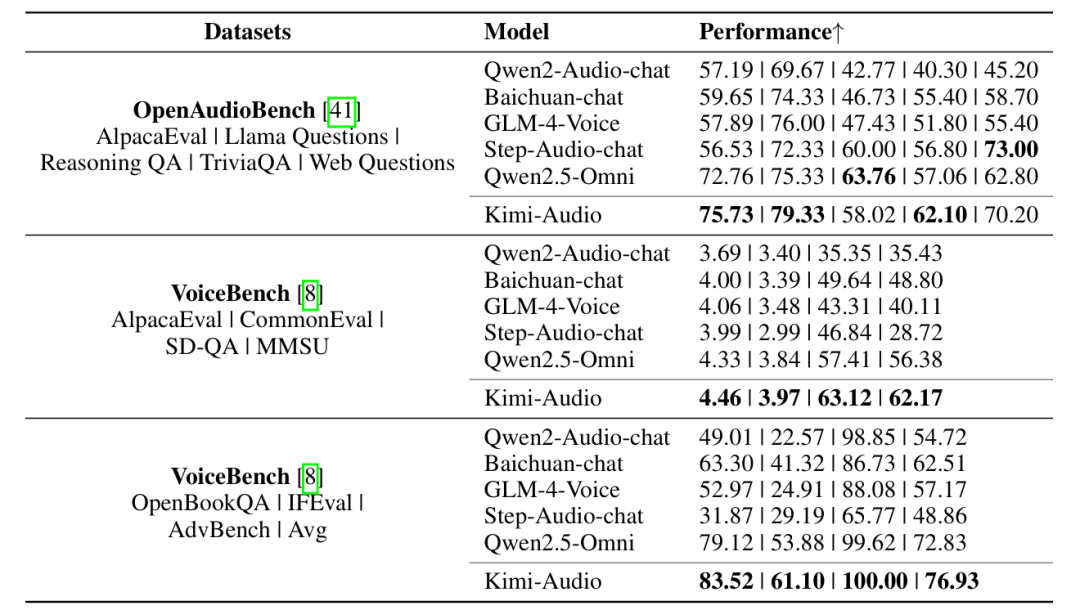
音频对话与聊天
-
VoiceBench多项任务评测:Kimi-Audio全部排名第一,平均得分76.93
-
人类主观评分:在速度控制、情感表达、同理心等多个维度,平均得分3.9(满分5分),接近GPT-4o水平
模型下载
OpenCSG社区:https://opencsg.com/models/AIWizards/Kimi-Audio-7B
hf社区:https://huggingface.co/moonshotai/Kimi-Audio-7B

















 799
799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









