







一、传统架构:
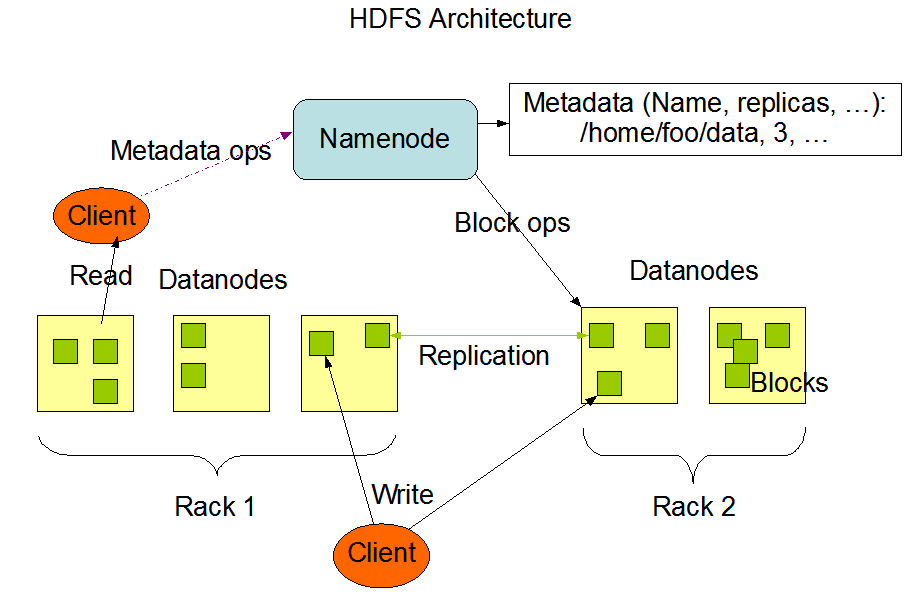
1. 如上图所示,hadoop1中HDFS分为:1个NameNode节点(NN,主)
2. 文件写入和读取过程详见:http://computerdragon.blog.51cto.com/6235984/1287660
3. DN负责存储和控制数据,客户端通过虚拟的文件目录(例如:http://namenode:9000/aa/bb/cc/dd.txt)访问数据,目录是虚拟的,实际上dd.txt文件在HDFS上并不存在,
而是以block的形式存在DN上(具体存在DN上的哪一个目录上可以通过配置文件自行设置),dd.txt文件与真实的数据块之间的映射关系等元数据在NN上。
4. NN上存储所有的元数据,记录文件内容存储相关信息元数据格式为:(Filename,replicas,block-ids,block所在hosts)。详细可见:http://blog.sina.com.cn/s/blog_a
94476040101cco2.html,http://blog.csdn.net/u011414200/article/details/50358603
5. 客户端写完一个副本,并将其上传到DN1上,则DN1再将其copy到DN2上,再由DN2将副本copy到其他DN(异步的)。
6. 假设客户端上传的都是非常多很小的文件,则会非常占用NN上的元数据存储空间。
7. NN的元数据管理机制:
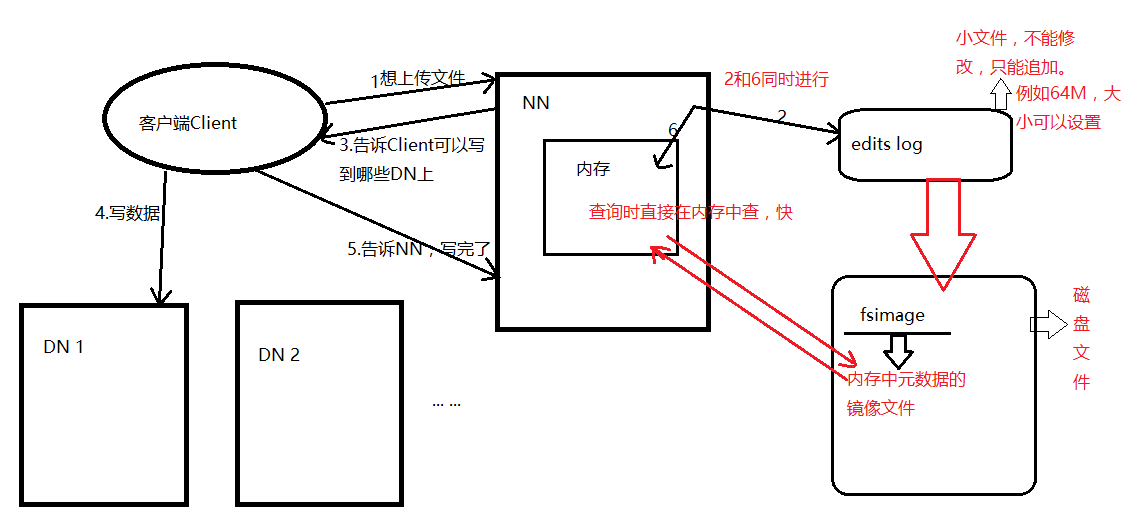
注:(1)客户端上传文件时,NN首先向edits log文件中记录元数据的操作日志。
(2)客户端上传文件完成后,即第5步骤完成后,返回成功的信息给NN,NN在内存中记录这次上传操作新产生的元数据信息,同时执行2
(3)每当edits log 文件写满以后要将新元数据刷到fsimage中。
(4)怎样使内存中数据与fsimage中数据保持同步且一致呢? 由 SNN 完成。
8. SNN并不是NN的备份。NN保存了元数据的快照-fsimage,同时将元数据的修改写到edits log。SNN就是负责定期将之前的文件系统快照与editlog合并生成新的快照,然后将这些快照传回给NN。SNN工作机制如下:
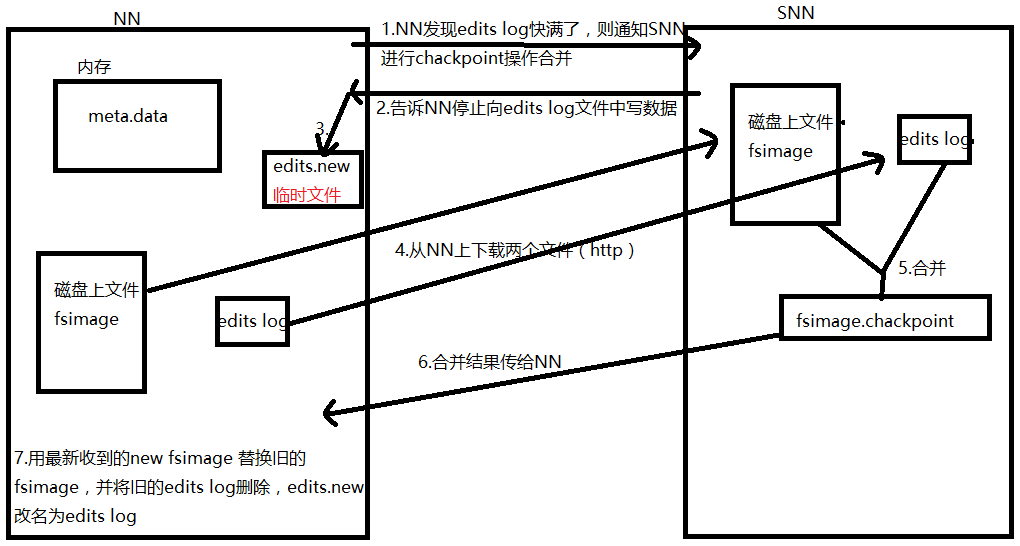
注:(1)什么时候要checkpoint?
fs.checkpoint.period 指定两次问的最大时间间隔,默认为3600s,即1小时。
fs.checkpoint.size 默认为64 M。
以上两个条件满足其一即可(上两个变量可在hdfs-site.xml文件中设置)。
(2)以上的所有文件都存在哪里?
core-site.xml文件中设置的dfs的工作目录下有3个文件夹
data/current/里面有edits和fsimage(都存了很多个版本)等文件。
name/.../.../.../.../.../finalized- - -此文件夹中存着block
namesecondary/.....
9. 一旦NN宕机,虽然元数据可以得到恢复,但是在修复期间该集群确实不能正常对外提供服务了,此为HA机制出现前的常见问题,此问题在hadoop2中得到了很好的解决。
二、hadoop2 架构
.
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









