







 SimRank是一种结构相似度度量方法,尤其适用于基于链接的数据。其基本思想是:相似的实体往往与相似的实体相连。通过矩阵计算和随机游走模型来计算节点间的相似度,解决路径无限长问题时采用概率跳出和函数映射。SimRank公式考虑了节点的邻居相似度,并通过迭代求解相似度。
SimRank是一种结构相似度度量方法,尤其适用于基于链接的数据。其基本思想是:相似的实体往往与相似的实体相连。通过矩阵计算和随机游走模型来计算节点间的相似度,解决路径无限长问题时采用概率跳出和函数映射。SimRank公式考虑了节点的邻居相似度,并通过迭代求解相似度。
详见:Glen Jeh 和 Jennifer Widom 的论文SimRank: A Measure of Structural-Context Similarity∗
一、简介
- 目前主要有两大类相似性度量方法:
(1) 基于内容(content-based)的特定领域(domain-specific)度量方法,如匹配文本相似度,计算项集合的重叠区域等;
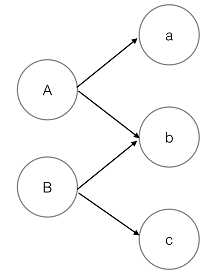
(2) 基于链接(对象间的关系)的方法,如PageRank、SimRank和PageSim等。最近的研究表明,第二类方法度量出的对象间相似性更加符合人的直觉判断。 - Simrank的基本思想是:如果两个实体相似,那么跟它们相关的实体应该也相似。比如在图一中如果a和c相似,那么A和B应该也相似。
- SimRank的特点:完全基于结构信息,且可以计算图中任意两个节点间的相似度。
图一
二、基本公式
- 在普通的同构网络中:
其中,s(a,b)是节点a和b的相似度Ii(a)Ii(a)表示a的第i个in-neighbor。参数c是个阻尼系数,它的含义可以这么理解:假如I(a)=I(b)={A},按照上式计算出sim(a,b)=c*sim(A,A)=c,很明显,c应该大于0小于1,所以c∈(0,1),论文中
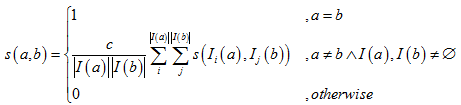
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









