






背压是分布式系统中的一种技术,通过控制请求流来防止过载和级联故障。
一场不受控制的洪水甚至会冲走最坚固的水坝。
– 古老的谚语
上面的引述表明,即使是最坚固、设计最精良的大坝也无法承受不受控制和控制的洪水的破坏力。同样,在分布式系统的上下文中,未经检查的调用方通常会使整个系统不堪重负并导致级联故障。在上一篇文章中,我写了如果没有适当的护栏,重试风暴如何有可能使整个服务瘫痪。在这里,我将探讨服务何时应考虑对其调用方应用背压、如何应用背压以及调用方可以采取哪些措施来处理它。
背压
顾名思义,背压是分布式系统中的一种机制,指的是系统限制数据消耗或生成速率以防止自身或其下游组件过载的能力。对其调用方应用背压的系统并不总是显式的,例如以限制或负载卸除的形式,但有时也是隐式的,例如通过增加所处理请求的延迟来减慢自己的系统速度,而无需明确说明。隐式和显式背压都旨在减慢调用方的速度,当调用方行为不佳或服务本身运行状况不佳且需要时间恢复时。
需要背压
让我们举一个例子来说明系统何时需要应用背压。在此示例中,我们将构建一个包含三个主要组件的控制平面服务:接收客户请求的前端、缓冲客户请求的内部队列,以及从队列中读取消息并写入数据库以实现持久性的使用者应用程序。
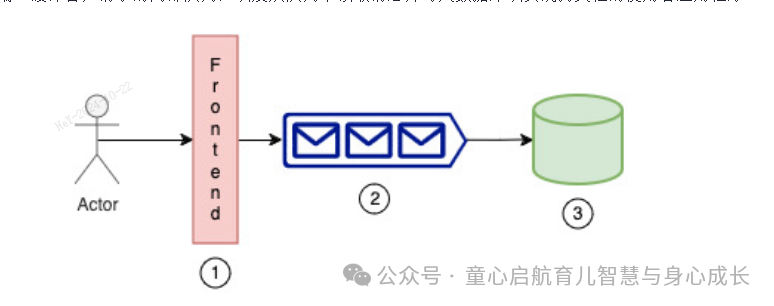
图 1:示例控制平面
生产者-使用者不匹配
考虑这样一个场景:参与者/客户以如此高的速率访问前端,以至于内部队列已满,或者写入数据库的工作程序繁忙,从而导致队列已满。在这种情况下,请求无法入队,因此最好提前通知客户,而不是放弃客户请求。这种不匹配可能由于各种原因而发生,例如传入流量的激增或系统中的轻微故障,其中使用者已经关闭了一段时间,但现在必须额外工作来耗尽停机期间积累的积压工作。
资源约束和级联故障
想象一下这样一个场景:您的队列接近其容量的 100%,但通常为 50%。为了匹配传入速率的增加,您需要扩展使用者应用程序并开始以更高的速率写入数据库。但是,数据库无法处理这种增加(例如,由于每秒写入次数的限制)并崩溃。这种故障将导致整个系统瘫痪,并增加平均恢复时间 (MTTR)。在这种情况下,在适当的位置施加背压变得至关重要。
错过 SLA
考虑这样一个场景:写入数据库的数据每 5 分钟处理一次,另一个应用程序会侦听这些数据以使自身保持最新状态。现在,如果系统由于任何原因无法满足该 SLA,例如队列已满 90%,并且可能需要长达 10 分钟才能清除所有消息,则最好采用背压技术。您可以通知客户您将错过 SLA,并要求他们稍后重试,或者通过从队列中删除非紧急请求来应用反压,以满足关键事件/请求的 SLA。
背压挑战
基于上述内容,我们似乎应该始终应用背压,并且不应该对此进行任何争论。听起来确实如此,主要挑战不在于我们是否应该应用背压,而主要在于如何确定应用背压的正确点以及满足特定服务 / 业务需求的施加背压的机制。
背压迫使在吞吐量和稳定性之间进行权衡,而负载预测的挑战使这变得更加复杂。
确定背压点
查找瓶颈/薄弱环节
每个系统都有瓶颈。有些人可以承受和保护自己,有些人则不能。考虑这样一个系统:大型数据平面队列(数千台主机)依赖于小型控制平面队列(少于 5 台主机)来接收数据库中保留的配置,如上图所示。大型机队很容易压倒小型机队。在这种情况下,为了保护自身,小型队列应具有对调用方施加背压的机制。架构中另一个常见的薄弱环节是负责整个系统决策的集中式组件,例如反熵扫描仪。如果它们失败,系统将永远无法达到稳定状态,并可能使整个服务瘫痪。
使用 System Dynamics:监视器/指标
为系统查找背压点的另一种常见方法是部署适当的监视器/指标。持续监控系统的行为,包括队列深度、CPU/内存利用率和网络吞吐量。使用此实时数据来识别新出现的瓶颈并相应地调整背压点。通过指标或观察者(如跨不同系统组件的性能金丝雀)创建聚合视图是了解系统是否承受压力并应对其用户/调用方施加背压的另一种方法。可以针对系统的不同方面隔离这些性能金丝雀,以找到阻塞点。此外,拥有内部资源使用情况的实时仪表板是使用系统动态来查找兴趣点并更加主动的另一种好方法。
边界:最小惊讶原则
对客户来说,最明显的是他们与之交互的服务外围应用。这些通常是客户用来为其请求提供服务的 API。这也是客户在背压情况下最不惊讶的地方,因为它清楚地表明系统处于压力之下。它可以采用限制或减载的形式。相同的原则可以在服务本身中应用于不同的子组件和接口,它们通过这些子组件和接口相互交互。这些表面是施加背压的最佳位置。这有助于最大限度地减少混淆并使系统的行为更具可预测性。
如何在分布式系统中应用背压
在上一节中,我们讨论了如何找到正确的兴趣点来断言背压。一旦我们知道了这些点,以下是我们可以在实践中断言这种背压的一些方法:
构建显式流控制
这个想法是让呼叫者可以看到队列大小,并让他们根据此控制呼叫速率。通过了解队列大小(或任何成为瓶颈的资源),他们可以增加或减少调用速率,以避免系统不堪重负。当多个内部组件协同工作并在不影响彼此的情况下尽可能地运行良好时,这种技术特别有用。以下公式可以随时用于计算呼叫者速率。注意:实际调用率将取决于各种其他因素,但下面的等式应该是一个好主意。
CallRate_new = CallRate_normal * (1 - (Q_currentSize / Q_maxSize))
倒置责任
在某些系统中,可以更改调用方不显式向服务发送请求,而是让服务请求在准备好服务时自行工作的顺序。这种技术使接收服务可以完全控制它可以执行多少操作,并且可以根据其最新状态动态更改请求大小。您可以采用令牌桶策略,其中接收服务填充令牌,并告诉调用方何时可以向服务器发送令牌以及发送多少。以下是调用方可以使用的示例算法:
# Service requests work if it has capacity
if Tokens_available > 0:
Work_request_size = min (Tokens_available, Work_request_size _max) # Request work, up to a maximum limit
send_request_to_caller(Work_request_size) # Caller sends work if it has enough tokens
if Tokens_available >= Work_request_size:
send_work_to_service(Work_request_size)
Tokens_available = Tokens_available – Work_request_size
# Tokens are replenished at a certain rate
Tokens_available = min (Tokens_available + Token_Refresh_Rate, Token_Bucket_size)主动调整
有时,您提前知道您的系统很快就会不堪重负,您会采取主动措施,例如要求呼叫者放慢通话量并慢慢增加通话量。考虑这样一个场景:您的下游已关闭并拒绝了您的所有请求。在此期间,您将所有工作排队,现在已准备好耗尽它以满足 SLA。当您以比正常速率更快的速度耗尽它时,您可能会关闭下游服务。为了解决这个问题,您可以主动限制呼叫者限制或与呼叫者接洽以减少其呼叫量并慢慢打开闸门。
节流
限制服务可以处理的请求数,并丢弃超出此数的请求。限制可以在服务级别或 API 级别应用。这种限制是调用方减慢调用量的背压的直接指标。您可以更进一步,进行优先级限制或公平性限制,以确保客户看到的影响最小。
减载
限制是指在超出某些预定义限制时丢弃请求。如果服务面临压力并决定主动放弃已承诺服务的请求,则客户请求仍然可以被丢弃。这种操作通常是服务保护自身并让调用方知道的最后手段。
结论
背压是分布式系统中的一项关键挑战,可能会显著影响性能和稳定性。了解背压的原因和影响以及有效的管理技术对于构建健壮且高性能的分布式系统至关重要。如果实施得当,背压可以提高系统的稳定性、可靠性和可扩展性,从而改善用户体验。但是,如果处理不当,可能会削弱客户的信任,甚至导致系统不稳定。通过仔细的系统设计和监控主动解决背压问题是维护系统运行状况的关键。虽然实施背压可能涉及权衡,例如可能影响吞吐量,但在整体系统弹性和用户满意度方面的好处非常明显。


















 9408
9408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











