







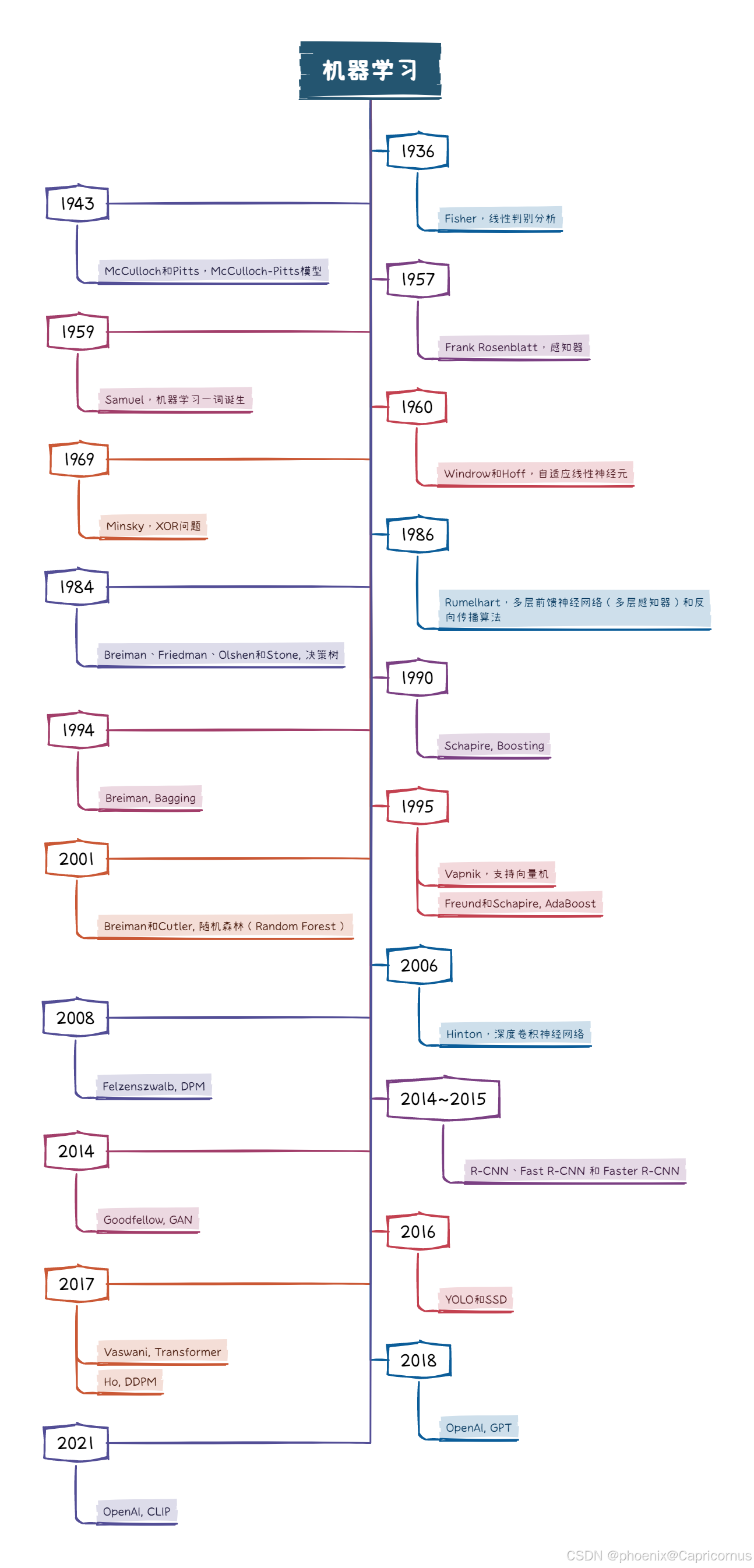
- 基础奠定时期
1936年Ronald Aylmer Fisher提出了线性判别分析(linear discriminant analysis),为统计模式识别的发展奠定了基础。
1943年沃伦·麦卡洛克(Warren McCulloch)和沃尔特·皮茨(Walter Pitts)提出了第一个人工神经元模型——阈值逻辑单元(Threshold Logic Unit),称为McCulloch-Pitts模型,为人工神经网络的发展奠定了基础。1957年,罗森·布拉特(Frank Rosenblatt)提出了第一个计算机神经网络感知器(perceptron),并提出了误差反馈学习算法实现分类。1960年,Bernard Widrow和Marcian E. Hoff提出了自适应线性神经元模型以及用于训练线性神经元的Delta学习规则(也称为Widrow-Hoff规则),尤其适用于解决回归问题。这个规则利用梯度下降法,通过计算误差相对于权重的梯度来更新权重,实现最小化预测输出与实际输出之间的误差。这种方法后来称为最小二乘法。1969年马文·明斯基(Marvin Minsky)提出了著名的XOR问题和感知器数据线性不可分的情形,将感知器推到最高顶峰。
1959年,阿瑟·塞缪尔(Arthur Samuel)开发了一个自动学习的跳棋程序。这一工作标志着机器学习的开端,并为计算机博弈领域奠定了基础。塞缪尔提出了"机器学习"这一术语,并将其定义为“无需明确编程让计算机进行学习的研究领域”。即计算机系统能够在不需要编程的情况下从数据中学习,并根据学习到的知识改进自身的性能。 - 停滞时期
从60年代中到70年代末,由于感知器局限性、理论基础不足、计算能力、数据集有限等,机器学习的发展进程经历了一段相对停滞的时期。在这一时期,通过形式化的符号表示和逻辑推理的符号AI和专家系统成为主流,因为它们在某些特定领域内表现出了较好的性能,尤其是在知识表示和推理方面。 - 复兴时期
1986年David Rumelhart提出了多层前馈神经网络(多层感知器)和反向传播算法(Back-propagation),这标志着神经网络研究的复苏。多层神经网络和反向传播算法允许神经网络能够处理更复杂的任务。反向传播算法仍然是深度神经网络学习的支撑。
1966年,Ellis Hunt和Thomas J. Devine提出了Hunt算法,奠定了决策树算法的基础。1979年和1993年George A. Quinlan分别提出ID3和C4.5算法,推动了决策树的实用化。1984年Leo Breiman、Jerome Friedman、Richard Olshen和Charles Stone在共同提出了CART(Classification and Regression Trees),进一步扩展了决策树的应用范围。 - 现代机器学习的成型时期
20世纪90年代以来,机器学习领域在集成方法方面取得了显著进展。1990年和1991年,Schapire和Freund分别提出了Boosting算法。1995年Freund和Schapire共同提出的AdaBoost算法(Adaptive Boosting)解决Boosting算法存在的一定局限性。1994年,Leo Breiman提出了Bagging(Bootstrap Aggregating)算法。集成学习通过组合多个弱学习器来创建一个更强的学习器,从而提高预测准确性。2001年Leo Breiman和Adele Cutler将集成学习Bagging方法与决策树相结合,提出了随机森林(Random Forest)算法。
1995年,Vladimir Vapnik提出了一种基于统计学习理论的监督学习模型——支持向量机(Support Vector Machine, SVM)。通过寻找最优超平面以最大化不同类别之间的间隔,SVM不仅提升了分类器的推广能力,还在处理小样本、非线性及高维模式识别问题上表现优异。SVM的一个重要特性是核技巧,它使得算法能够通过预先定义的核函数将输入数据映射到更高维度的空间中,从而在不增加计算复杂度的情况下找到更优的决策边界。支持向量机推动了机器学习技术的发展,奠定了其在机器学习领域的关键地位。
2008年,Pedro Felzenszwalb等在目标检测方面提出了可变形部件模型(Deformable Part Model, DPM),通过学习物体的关键部件及其相互关系来进行目标检测,允许模型中的各个部分可以在空间上有所偏移,从而能够更好地适应物体的形态变化。 - 蓬勃发展时期
在神经网络发展分为两个阶段,浅层学习(Shallow Learning)和深度学习(Deep Learning)。浅层学习起源于人工神经网络的反向传播算法。由于多层网络训练的梯度消失等问题,通常只有一层隐含层的浅层模型。
2006年Hinton提出了深度学习的概念,并基于深度信赖网络(DBN)提出了非监督贪心逐层训练算法。Yann LeCun提出了LeNet深度学习网络,随后出现了AlexNet、VGG、GoogLeNet、ResNet等多种经典的卷积神经网络结构。
随着深度学习的发展,自动特征学习成为了可能,这使得机器学习方法在许多模式识别任务中取得了显著的成功。深度神经网络能够在没有人工干预的情况下直接从原始数据中学习复杂的特征表示,从而提高了识别的准确性和鲁棒性。
2014年至2015年,提出了R-CNN、Fast R-CNN 和 Faster R-CNN一系列目标检测算法,这些模型的发展反映了目标检测算法从手工特征提取到端到端深度学习模型的转变。2016年,提出了YOLO(You Only Look Once)和SSD(Single Shot MultiBox Detector),YOLO和SSD相比R-CNN系列算法,提高了检测速度,准确率下降。
大规模预训练模型的发展,特别是在自然语言处理(NLP)领域取得了重大进展。2017年Vaswani等提出Transformer模型。它摒弃了传统的递归神经网络(RNN)和卷积神经网络(CNN),转而使用自注意力机制(Self-Attention Mechanism)来处理序列数据。Transformer模型能够并行处理输入序列中的每一个元素,因此在处理长序列数据时速度更快。此外,自注意力机制使得模型能够捕捉到输入序列中任意两个位置之间的关系。2018年OpenAI发布基于Transformer架构的预训练模型GPT(Generative Pre-trained Transformer),采用自注意力机制预测序列中的下一个词。
近年来在生成模型领域受到了极大的关注,2014年Ian Goodfellow 等提出了生成式对抗网络(Generative Adversarial Network, GAN)。借鉴2015年提出的扩散模型(Diffusion Models)的概念, 2017年,Jonathan Ho等发表了DDPM(Denoising Diffusion Probabilistic Models),用于生成新的数据样本,这是扩散模型发展史上的一个重要里程碑。
CLIP(Contrastive Language-Image Pre-training)模型是由OpenAI在2021年提出的一种用于联合训练文本和图像的模型,它通过对比学习的方式,在大量的未标注图像-文本对上进行预训练,从而实现对跨模态数据的理解和生成。CLIP是多模态学习领域的一个重要里程碑。CLIP使用对比学习(Contrastive Learning)的方法来训练模型。AIGC(AI Generated Content)是一个涵盖使用人工智能技术来创建或生成文字、图像、音频、视频等多种形式内容的领域。随着生成模型和多模态学习的发展,该领域在过去几年中取得显著提升。2022年,MidJourney、Stable Diffusion、DALL·E等图像生成工具的推出,进一步展示了扩散模型在生成高质量图像方面的潜力。
由于计算机硬件、软件技术的飞速发展,人工神经网络已经几乎可以全部取代传统分类器的工作来实现模式分类。但是,这绝对不意味着其他机器学习方法的终结。尽管深度学习迅速增长,但是对这些模型的训练成本是相当高的,调整外部参数也是很麻烦。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









