







决策树
- 决策树以自顶向下, 递归分治的方式构造
- 属性的选择基于启发式或统计度量(例如,信息增益)
- 节点上的样本递归地基于选定的属性划分停止划分的条件
朴素贝叶斯
先给个实例
类: C1:buys_computer=‘yes’ C2:buys_computer=‘no’
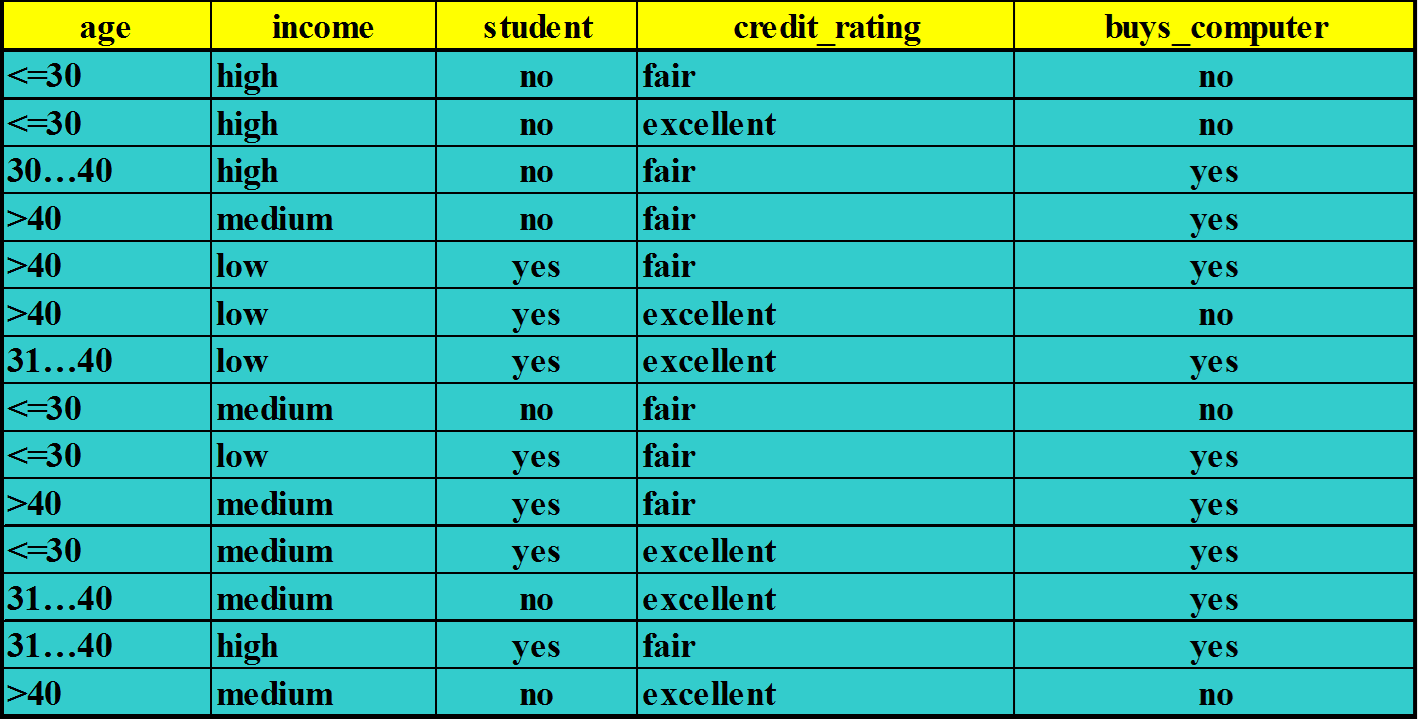
数据样本
X =(age<=30, income=medium, student=yes, credit_rating=fair)
每个类的先验概率P(Ci)可以根据训练样本计算
P(buys_computer = yes) = 9/14 = 0.643
P(buys_computer = no) = 5/14 = 0.357
计算下面的条件概率P(xk|Ci)
P(age=“<=30” | buys_computer=“yes”) = 2/9=0.222
P(age=“<=30” | buys_computer=“no”) = 3/5 =0.6
P(income=“medium” | buys_computer=“yes”)= 4/9 =0.444
P(income=“medium” | buys_computer=“no”) = 2/5 = 0.4
P(student=“yes” | buys_computer=“yes)= 6/9 =0.667
P(student=“yes” | buys_computer=“no”)= 1/5=0.2
P(credit_rating=“fair” | buys_computer=“yes”)=6/9=0.667
P(credit_rating=“fair” | buys_computer=“no”)=2/5=0.4
使用以上概率,我们得到 P(X|Ci)
P(X|buys_computer=“yes”)= 0.222 0.444 0.667 0.667 =0.044
P(X|buys_computer=“no”)= 0.6 0.4 x 0.2 0.4 =0.019
P(X|Ci) P(Ci )
P(X|buys_computer=“yes”) * P(buys_computer=“yes”)=0.028
P(X|buys_computer=“no”) * P(buys_computer=“no”)=0.007
因此,对于数据样本X,朴素贝叶斯分类预测buys_computer =” yes”
如果P(xk|Ci)为0,进行拉普拉斯变换
优点
易于实现,在数据较少的情况下仍然有效,可以处理多类别问题
在大部分情况下能够得到很好的结果
当类条件独立假定成立时,朴素贝叶斯分类是最精确的
缺点
假定: 类条件独立 , 因而损失精度
实践中, 变量之间存在依赖关系—-类条件独立的假定不切实际
对于输入数据的准备方式较为敏感
适用数据类型:标称型数据















 5520
5520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









