







聚类: 数据对象的集合
- 同一簇中的对象彼此相似
- 不同簇中的对象彼此相异
聚类分析: 将数据对象(观测)的集合划分成子集过程
聚类是无监督的分类: 没有预先定 义的类编号
基于划分方法-k-means
k均值聚类算法
输入:簇的数目k和包含n个对象的数据库。
输出:k个簇,使平方误差准则最小。
算法步骤:
1.为每个聚类确定一个初始聚类中心,这样就有K 个初始聚类中心。
2.将样本集中的样本按照最小距离原则分配到最邻近聚类
3.使用每个聚类中的样本均值作为新的聚类中心。
4.重复步骤2.3直到聚类中心不再变化。
5.结束,得到K个聚类 
伪代码
创建k个点作为起始质心(经常随机选择)
当任意一个点的簇分配结果发生改变时
对于数据集中的每个数据点
对每个质心
计算质心于数据点之间的距离
将数据点分配到距其最近的簇
对于每个簇,计算簇中所有点的均值并将均值作为质心- 优点:容易实现
- 缺点:
K 是事先给定的,这个 K 值的选定是非常难以估计,常采用遗传算法(GA)进行初始化来改进
存在噪点时,可能收敛到局部最小值
在大规模的数据集上收敛较慢
适用数据类型:数值型数据
k中心点聚类
当存在噪声和离群点时
——k-中心点
当n和k的值较大时
——k-均值算法效率要高的多
基于层次方法
输入:包含n个对象的数据集
输出:簇的分层结构
算法步骤:
计算邻近度矩阵
每个点作为一个簇
Repeat
合并最接近的两个簇
更新邻近度矩阵
Until 仅剩下一个簇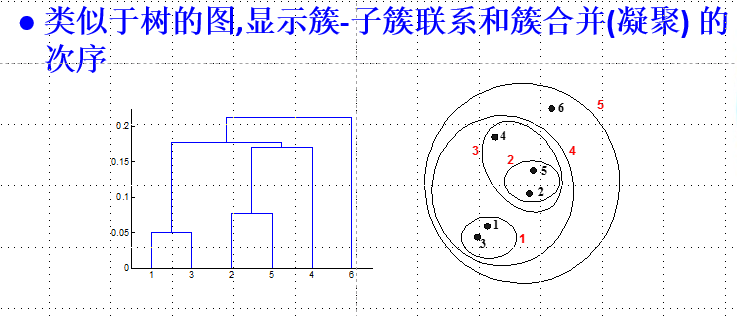
- 如果两个类被合并,那么将不能被恢复
- 不同的聚类模式都有以下一个或多个问题:
1.对噪音和异常点敏感
2.处理不同大小的簇和凸起的形状的簇比较困难
3.分割大的类
基于密度方法
DBSCAN
基于密度定义,我们将点分为:
- 稠密区域内部的点(核心点)
- 稠密区域边缘上的点(边界点)
- 稀疏区域中的点(噪声或背景点).
DBSCAN算法的本质就是随大流,边界点紧紧围绕着核心点,他们抱团,不带噪点玩儿

小团体多了,联系比较密切的小团体之间聚成了同个类
比较偏远的小团体想要加入这个圈子,进不去,就单干,我们自己玩自己的,聚成了另外的一个类
一开始就被孤立的噪点吧,自然有自己的傲骨,接着孤芳自赏

算法原理
DBSCAN通过检查数据集中每点的Eps邻域来搜索簇,如果点p的Eps邻域包含的点多于MinPts个,则创建一个以p为核心对象的簇。
然后,DBSCAN迭代地聚集从这些核心对象直接密度可达的对象,这个过程可能涉及一些密度可达簇的合并。
当没有新的点添加到任何簇时,该过程结束.DBSCAN(D, eps, MinPts) {
C = 0
for each point P in dataset D {
if P is visited
continue next point
mark P as visited
NeighborPts = regionQuery(P, eps)
if sizeof(NeighborPts) < MinPts
mark P as NOISE
else {
C = next cluster
expandCluster(P, NeighborPts, C, eps, MinPts)
}
}
}
expandCluster(P, NeighborPts, C, eps, MinPts) {
add P to cluster C
for each point P' in NeighborPts {
if P' is not visited {
mark P' as visited
NeighborPts' = regionQuery(P', eps)
if sizeof(NeighborPts') >= MinPts
NeighborPts = NeighborPts joined with NeighborPts'
}
if P' is not yet member of any cluster
add P' to cluster C
}
}
regionQuery(P, eps)
return all points within P's eps-neighborhood (including P)














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









