







雷峰网 作者:铁流 2017-05-12
导语: Intel 对 X86 的授权有着极为严格的限制,那么上海兆芯的 X86 芯片技术到底从何而来?ZX-C 目前的短板在哪里?在性能上和 Intel 相差多远呢?

雷锋网按:本文作者铁流,雷锋网首发文章。
在第 18 届中国国际工业博览会上,上海兆芯公司的 ZX-C 处理器获得了金奖。在 2017 年 3 月,更是接连荣获 “2017 年度大中华 IC 设计成就奖”(见图 22)、“第十一届(2016 年度)中国半导体创新产品和技术奖”。在国家十二五科技创新成就展中兆芯的宣传材料显示,“兆芯国产 X86 通用处理器的成功自主研发和量产,令国产处理器在性能方面完成了一次跨越式的提升,从十二五初期的不足国际整体水准的 10% 提升到了目前的 80%”。
众所周知,Intel 对 X86 的授权有着极为严格的限制,那么上海兆芯的 X86 芯片技术到底从何而来?ZX-C 目前的短板在哪里?在性能上和 Intel 相差多远呢?
兆芯 C4600 cpuinfo 的信息显示:设计厂商为美国 Centaur,微结构是 VIA 的以赛亚
在 Linux 系统中命令 cat /proc/cpuinfo 可以读出芯片的一些信息和特性。其命令和 Windows 系统中 cpu-z 软件获得的信息类似。芯片 cpuinfo 的信息是通过 CPUID 指令读出来的。例如 eax=1 时,读出的是处理器的信息以及特征位 (CPUID 指令的使用,见 en.wikipedia.org/wiki/CPUID)。
从图 1 兆芯 C4600 芯片 cpuinfo 的信息可以看出,这个芯片的厂商(vendor_id)为 CentaurHauls,即 Centaur 公司。其中 cpu family 表示那一代芯片,其中的 family 6 表示 VIA 的 Nano 系列。其中的 model 表示型号,也就是采用哪种微结构,15 表示以赛亚。model name 为处理器的型号,图中为 C-QuadCore C4600@2.0GHz。表示 4 核芯片 C4600,主频为 2GHz。
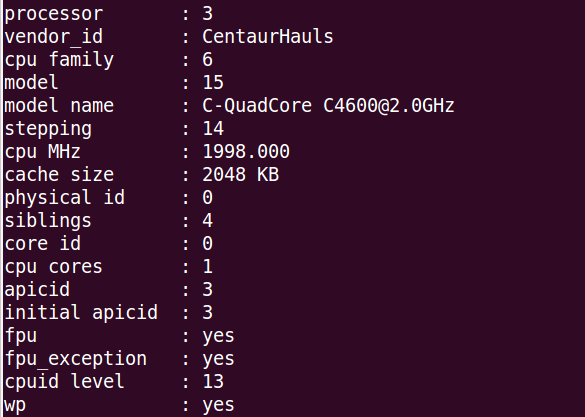
- 图 1 兆芯 C4600 芯片 cpuinfo 的信息 *
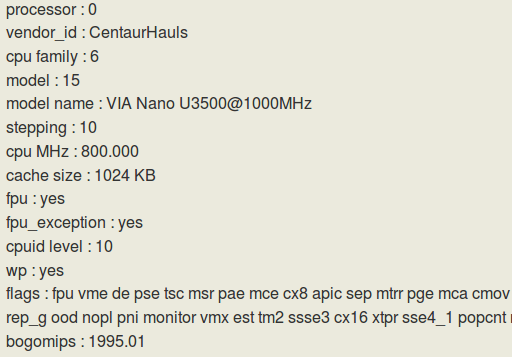
- 图 2 威盛 Nano U3500 芯片 cpuinfo 的信息 *
图 2 给出了威盛公司的 Nano U3500 芯片 cpuinfo 的信息,其 model name 为 VIA Nano U3500@1000MHz。对比 vendor_id 的信息可以看出都是 VIA 的 Centaur 公司,对比 cpu family 和 model 的信息,也可以看出都是 family 6 和 model 15,即都是 “以赛亚” 架构。
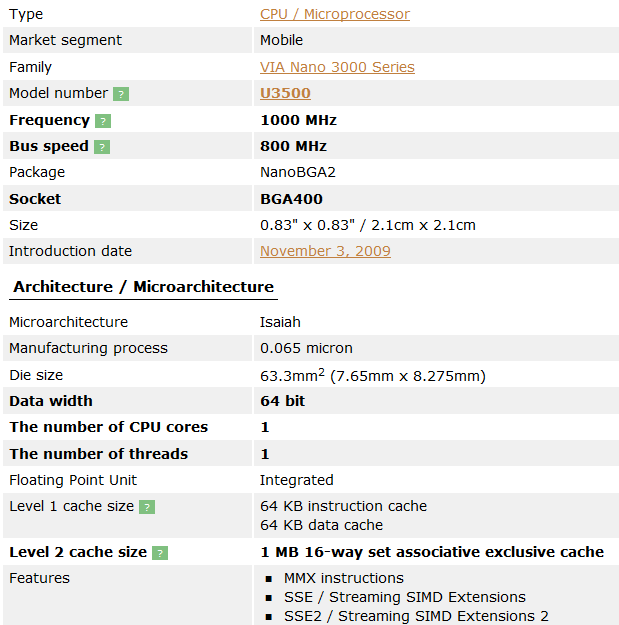
- 图 3 威盛 Nano U3500 芯片的信息 *
从图 3 可以看出 U3500 芯片属于 VIA Nano 系列。其中的微架构为 Isaiah(以赛亚)。支持的指令集到 SSE4.1 为止,并且支持 x86-64 指令集。
从 C4600 芯片 cpuinfo 的信息可以看出,C4600 的设计厂商(vendor_id)还是 VIA 的 Centaur 公司,而没有改为 ZX 的标志。
美国 Centaur 公司和 Glenn Henry
根据维基的资料显示:Centaur(半马人)科技公司,创立于 1995 年,创建者为 Glenn Henry, Terry Parks, Darius Gaskins 和 Al Sato,其获得的投资来自于 IDT 公司。其公司的目标是开发兼容的 x86 处理器,目标定位为开发比 Intel 公司的 x86 芯片价格更低,功耗更小的芯片。早期的产品称为 WinChip,1999 年 9 月,Centaur 被 IDT 公司出售给 VIA 公司,其后续的产品为 VIA C3 和 VIA C7,以及 VIA Nano。Centaur 公司的芯片主要面向嵌入式市场,包括移动市场,也就是面积更小、价格更便宜,功耗更低的 x86 芯片市场。Centaur 的设计理念是对于面向特定市场需求 “够用就好”。VIA Nano Isaiah(以赛亚),是 Centaur 第一款超标量、乱序执行的 CPU,第一款 64 位的 CPU,Nano 芯片这时更为强调性能,而不再是追随性能功耗比的等式,但是其维持和 C7 相同的功耗(TDP)。
根据 Centaur(半马人)公司的网站的介绍,Centaur(半马人)科技公司,位于德克萨斯 - 奥斯丁。主要设计高性能、低功耗的 x86 兼容的微处理器,号称具有最快的设计流程,设计周期是竞争对手厂商的三分之一。该公司没有管理者,所有的工程师直接向 Centaur 公司的创建者和总裁 Glenn Henry 汇报,Glenn Henry 是前 DELL 公司的 CTO 和 IBM 的工程系列的 Fellow(20 年的 Fellow)。1999 年 8 月,Centaur 公司被 VIA 公司收购。但是这次收购没有改变 Centaur 的文化,也就是 Centaur 作为 VIA 公司的子公司独立地运营,而不会受到 VIA 的影响。在 Cyrix 解散后,VIA 公司的 x86 芯片的设计都是来自于 Centaur 公司,而 VIA QuadCore C4650 芯片也是出自 Centaur 公司的 Glenn Henry 之手。

- 图 4 Glenn Henry*
这里介绍以下 Glenn Henry。Glenn Henry 于 1967 年加入 IBM,在 IBM 干了 21 年,担任首席架构师,是 RISC 工作站、AIX 操作系统和 AS/400 等创新产品的主要研发管理者,于 1985 年获得 IBM fellow 的称号,1988 年离开 IBM 加入 DELL 公司,为 DELL 公司负责研发的副总和 CTO,1994 年离开 DELL 公司,担任 MIPS 公司的咨询顾问,试图把 x86 和 MIPS 架构结合在一起,1995 年 Henry 获得了来自 IDT 公司的投资,创建了 Centaur 公司,设计低功耗、低成本的 x86 处理器。
揭开以赛亚神秘的面纱
正如 Intel 在研发出酷睿 2 后一举翻身,AMD 在开发出 Zen 之后终于做出能与 Intel 相比较的产品,一款 CPU 最关键的就在于其微结构,那么 QuadCore C4650 芯片的微结构究竟怎么样呢?

图 5 The VIA Isaiah Architecture
Centaur 公司的灵魂人物和总裁和 Glenn Henry 撰写的一篇文章 “The VIA Isaiah Architecture”(图 5),文章中分析了为什么采用 3 发射、乱序执行结构,和 Intel 的 Core 比较起来有什么优势,为了降低功耗,采用了什么样的权衡。文章介绍的非常详细,有兴趣的网友可以找原文品读。
从图 6 中可以看出,以赛亚采用类似于 Core 架构的设计,7 个部件,2 个定点 I1 和 I2,2 个浮点 MA 和 MB,1 个取数 LD,1 个存数 ST 和 1 个 SA 地址计算。也就是 2 个定点、2 个浮点、2 个访存。属于中规中矩的设计。
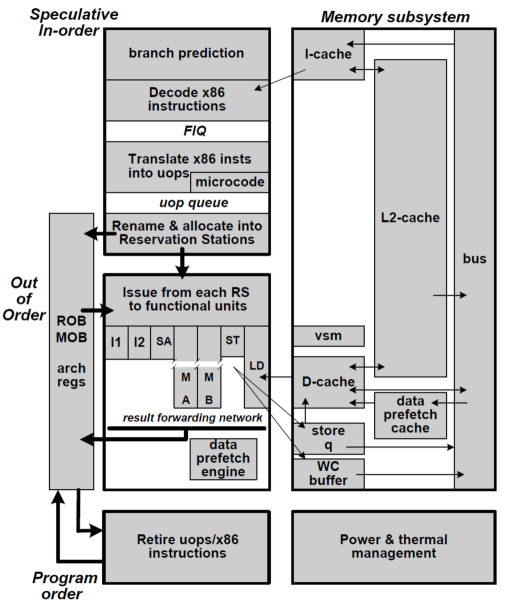
- 图 6 以赛亚微结构框图 *
Cache 的设计为 64KB+64KB L1 cache,16 路组相联,2M
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









