







CCCF 专栏 | 计算复杂性 50 年:王浩与计算理论
原创 尼克 中国计算机学会 2021 年 12 月 21 日 17:25 北京
库克(Cook)1971 年发表的文章《定理证明过程的复杂性》被认为是计算复杂性的开山之作。从这篇文章的发表日开始算,今年(2021 年),计算复杂性理论已经 50 岁了,且恰逢库克的导师王浩百年诞辰。本文回溯计算复杂性的起源,并力图梳理王浩和这门学科的关系。
如果说图灵 (Turing) 1936 年那篇开天辟地的文章《论可计算数及其在判定问题上的应用》[1] 奠定了计算理论的基础,那么称库克 (Cook) 1971 年发表的文章《定理证明过程的复杂性》[2] 是计算复杂性的开山之作,一点也不夸张。从库克这篇文章的发表日期开始算,今年(2021 年),计算复杂性理论已经 50 岁了,且恰逢库克的导师王浩百年诞辰。本文回溯计算复杂性的起源,并力图梳理王浩和这门学科的关系。
计算复杂性的源头
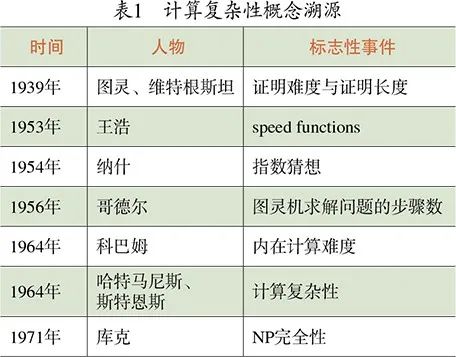
计算复杂性的基本概念的形成可以归功于科巴姆 (Cobham)、哈特马尼斯 (Hartmanis) 与斯特恩斯 (Stearns) 的工作。科巴姆于 1964 年发表了文章《函数的内在计算难度》[3],哈特马尼斯与斯特恩斯 1965 年在《美国数学学会会刊》上发表了《论算法的计算复杂性》[4]。这两篇文章定义了计算的时间和空间复杂性,科巴姆甚至探讨了用多项式时间作为有效计算的衡量,但他博士没有毕业就进入了工业界,后来帮助美国东部精英学校维思大学 (Wesleyan University) 创办了计算机系;而哈特马尼斯和斯特恩斯则获得了 1993 年 ACM 图灵奖。这两篇文章成文都在 1963 年,有意思的是科巴姆的文章是发表在科学哲学领域的会议上,尽管那会议和逻辑关系密切,但由此可见,计算复杂性在那时着实没人待见,会议论文集也出版于 1965 年。库克在哈佛读博期间就和科巴姆相熟,哈特马尼斯曾到哈佛大学做过一次关于计算复杂性的演讲,令库克记忆深刻。
哈特马尼斯在 1988 年发现了一封哥德尔 (Gödel) 于 1956 年 3 月 20 日写给冯・诺伊曼 (von Neumann) 的信 [5],哥德尔在信中指出:一个问题的难度可以表达为在图灵机上求解该问题所需步骤的函数,这个函数就是算法复杂性。于是,他把计算复杂性理论的诞生时间提早到 1956 年。

在 2012 年解密的美国国家安全署 (National Security Agency,NSA) 的一批文件中,人们发现了一封纳什 (Nash) 于 1955 年 1 月写给 NSA 的信 [6](见图 1)。这封信手写在麻省理工学院 (MIT) 的办公信纸上,一共 8 页。纳什在 1954 年就提出了多项式复杂性和指数复杂性的区别,他推测指数复杂性对加密算法是有用的。纳什和当时麻省理工学院的几位同仁还讨论过所谓的 “指数猜想”,其中就有后来发明霍夫曼编码的霍夫曼 (Huffman),而且英雄所见略同,霍夫曼也有类似想法。于是麻省理工学院的计算理论顶级学者西普塞 (Sipser) 认为纳什是计算复杂性概念的原创者 [7]。
但更早,王浩在 1953 年曾写过一篇文章《递归性和可计算性》(Recursiveness and calculability),文中提出了速度函数 (speed function) 的概念,这其实就是计算复杂性的雏形,可惜此文从未公开发表。王浩 1953 年夏天将此文提交给《英国科学哲学杂志》(British Journal for the Philosophy of Science)。评审的修改意见很长,王浩 1954 年做了修改,经过和评审的几次沟通,他失去了进一步修改的耐心。1984 年北京大学的逻辑学家吴允曾看到 1954 年的手稿后,建议王浩将此文收录进文集《计算,逻辑,哲学》[8](Computation, Logic, Philosophy),并将文章题目改为《可计算性的概念》(The Concept of Computability)。据此,我们也可以说计算复杂性起源于 1953 年。
我甚至曾把复杂性理论的缘起回溯得更早 [9]。1939 年,哲学家维特根斯坦 (Wittgenstein) 在剑桥开讲 “数学基础”(Foundations of Mathematics),内容主要是维特根斯坦转型期思想的杂烩。此时刚从美国回到英国的图灵在剑桥赋闲,计划开讲数理逻辑,碰巧也把自己的课名设置为 “数学基础”,当他得知大名鼎鼎的维特根斯坦也要开讲同名课程,于是决定去旁听维特根斯坦的课程。维特根斯坦讲课是苏格拉底式的,没有讲义。他去世后 20 多年,他的学生们把当年的听课笔记凑到一起,整理成《维特根斯坦剑桥数学基础讲义,1939》[10] 一书。其中图灵和维特根斯坦的对话构成该书很大一部分内容,图灵的发问很精彩。书中,他们就证明的复杂性有过深刻讨论:一个命题的证明难度和证明的长度有关。由此,把计算复杂性概念的诞生再推早到 1939 年似乎也不无道理。
计算复杂性概念溯源见表 1。其实如果只是泛泛而谈,我们甚至可以把计算理论的起源推早到巴贝奇(Babbage)和艾达(Ada)对 “分析机” 的研究。但任何事情的发展脉络都要有若干明确、毋庸置疑的里程碑,里程碑之前和之后确有明显不同。从这个意义上说,图灵(1936/1937)和库克(1971)有更显著更深刻的影响。最近德国计算机科学家施米德胡贝 (Schmidhuber) 对图灵的冷嘲热讽显示了他对英美学术话语体系的不满。但不满归不满,我们还是要看成果的彰显性 (significance)。库克的文章 [2] 提出了 P vs NP 的问题,该问题是当今计算机科学和数学中最重要的问题之一,库克因此获得 1982 年图灵奖。P vs NP 的问题也被克雷数学研究所列为七大千年数学难题之首。值得一提的是,这篇文章发表在计算理论的会议 (ACM SIGACT Symposium on the Theory of Computing) 上,该会议后来成为计算理论领域的顶级会议。
20 世纪 30 年代初期,对 “effectively calculable” 的定义也是不清楚的,类似现在对 “智能” 的定义。早期人们更喜欢用 “calculable”,甚至王浩在 1953 年也在用 “calculability”,而到了 60 年代,人们普遍使用 “computability” 一词了。丘奇 (Church) 和克里尼 (Kleene) 实际上在 1934 年(早于图灵)就知道他们的 λ- 可定义函数 (λ-definable) 和埃尔布朗 (Herbrand) 与哥德尔 1933 年提出的递归函数 (recursive function) 是一回事,于是有了所谓的丘奇论题,但哥德尔本人并不买账。哥德尔是在看到图灵的文章后才信服的,他说图灵 “第一次给出了一个有趣的认识论概念的绝对定义,这个定义不依赖任何形式化机制”。于是,丘奇论题变成了丘奇 - 图灵论题。
库克与 P vs NP
库克本科就读于密歇根大学,一开始学的是工程,但后来数学教授鼓励他改学了数学。他本科毕业后在哈佛大学读研究生,想学代数。但那时已经在哈佛读研究生的科巴姆影响了他。库克和王浩很聊得来,就选定王浩做博士导师,并于 1966 年获得博士学位。
库克于 1966~1970 年在伯克利大学数学系教书,但 1970 年因为没有拿到终身教席 (Tenure) 而被迫离开。图灵奖获得者理查德・卡普 (Richard Karp) 当时也是伯克利大学的教授,他后来回忆说:“我们没能给库克终身教席是伯克利永久的耻辱。” 库克后来去了离他老家水牛城不远的多伦多大学,同时担任该校计算机系和数学系的副教授。那时多伦多大学刚成立计算机系,只招收研究生,第二年他的划时代论文发表,他也获得了终身教职,全职在计算机系工作,而计算机系也日渐成熟,开始招本科生了。60 年代后期,计算机科学作为一门独立的学科刚刚开始发展,数学系的主流还没把计算理论当回事。
尽管那时伯克利大学数学系有个很强的逻辑学小组,带头人塔尔斯基 (Tarski) 曾经野心勃勃地想把数学系的十分之一教职分给逻辑学 [9],尽管相比数学系主流,逻辑学家会更加理解库克的工作。但很明显,不是所有的逻辑学家都曾远见到计算理论的重要性,计算理论一开始只是作为逻辑学四大论之一 —— 递归论的若即若离的边角料,而现在计算机系则成为逻辑学家最理想的就业地。王浩曾说罗素时代的数理逻辑是 90% 逻辑、10% 数学,而当下则是 90% 数学了。另一位图灵奖获得者戴克斯特拉 (Dijkstra) 大约在同时也被阿姆斯特丹大学拒绝了终身教职,之后搬到美国加入德克萨斯大学奥斯汀分校。
库克在 1971 年证明了命题逻辑的可满足问题 (Satisfiability,SAT) 是 NP 完全的,这是第一个 NP 完全问题。这个证明现在有标准的教科书式呈现方式,基本思路是:首先证明 SAT 属于 NP 类,这很简单,只要能够说明任何 SAT 问题是多项式可验证就可以了。另一方面比较难:要证明所有的 NP 问题都可以归约到 SAT。库克的办法是用命题逻辑来描述非确定图灵机多项式时间运行的所有可能状态。也恰是因为库克用了命题逻辑,于是他的论文题目和定理证明相关。
把库克的理论推向大众,首功是卡普。他 1972 年证明了 21 个问题(大部分是组合数学问题)都可以和库克的可满足性问题互相归约 (reducibility)[11]。这就意味着有一大类问题都和可满足性问题有类似的性质,即 NP 完全性。理论计算机科学的很多结果都有类似的呈现方式,就是把一些貌似不相干的东西,利用某种变换,找到隐藏于其中的内在共性。丘奇和克里尼在证明 λ- 可定义函数和递归函数等价时,证明了大量数论函数都是递归的,异曲同工。
图灵奖获得者瓦利安特 (Valiant) 讲述了他 1972 年在导师帕特森 (Mike Patterson) 的办公室里听到一场在 IBM 开会的录音,被震撼到,他听到的那段恰是卡普在讲那篇可归约性 (reducibility) 的文章,他回去研究了一晚上卡普的文章,第二天早上兴冲冲地去帕特森的办公室问 “你看过这篇文章了吗?” 帕特森反问 “为啥这么激动,你解决了吗?” 于是计算复杂性成为瓦利安特终生的学术追求 [12]。瓦利安特本科的背景是数学和物理,他说计算机科学那时还没成型,学校里教授的计算机课程的内容经常变来变去,没有定式,但卡普的文章使他脱胎换骨 (transforming experience)。这不仅是他的个人经验,对那时站在数学、逻辑和计算机科学交叉路口的一批人来说,库克和卡普的工作就是灯塔。后来 “计算机” 的研究被冠以 “计算机科学”,和这有着密切关系。数学家、菲尔兹奖得主斯梅尔 (Stephen Smale) 晚年沉迷于计算理论,他曾说 “NP 完全问题是计算机科学送给数学的大礼。”
王浩对计算理论的贡献
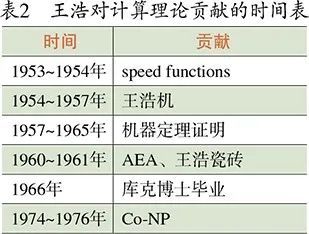
王浩 1948 年在哈佛哲学家蒯因 (Quine) 的指导下获得了博士学位,那时他的主要研究方向是数学基础和数学哲学。王浩在 50 年代曾动过回国的念头,于是把研究兴趣转向更接近实际、与计算机相关的研究,具体来说就是计算理论和机器定理证明。王浩在这方面的贡献总结见表 2。下面几节分别介绍其中重要且有趣的几项。
王浩 1961 年从牛津重回哈佛,职位是 “计算理论讲席教授”。他对计算机科学作出诸多贡献,其中一个重大而直接的贡献就是指导了库克的博士论文 (1966)。按照库克的回忆,王浩尽管是数理逻辑教授,但他的归属并不是在数学系,也不是在他导师蒯因所在的哲学系,而是在应用物理学部(这个回忆可能不严谨,哈佛那时正在扩大自己的应用科学和工程科系)。1914 年,哈佛和 MIT 曾计划把哈佛的应用科学系科并给 MIT,但后来麻省州法院取消了合并计划,这使得哈佛后来应用科学和工程系科一直落后于 MIT,直到 60 年代哈佛重振应用与工程学科。
一个极易被忽视的事实是库克用到的方法受到了王浩的启发。这个方法的核心就是用逻辑来描述一个要解决的问题,从而定义一个问题类。图灵是用一阶逻辑来描述图灵机,而库克就是用命题逻辑来描述非确定多项式时间运行的图灵机。库克 (1971) 引用了王浩 (1962) 的论文 [13]。王浩在那篇论文里提出了 “王浩瓷砖”(Wang Tiles),作为逻辑和被描述问题之间的一个中间环节。很多人头一次看明白库克定理时的震撼来自那方法,就像头一次看明白哥德尔定理和图灵 (1936) 时一样。库克后来回忆王浩对他的启发:“我很了解王浩的思想和方法,我对 NP 完全问题的结论与他非常类似。只不过图灵和王浩说的是谓词演算,我说的是命题演算。” 王浩有结集论文的习惯,他将那篇 1962 年的长达 33 页的长文编入他的文集《计算,逻辑,哲学》[8]。
库克和他的学生瑞克郝 (Reckhow) 1974 年的文章 [14] 是库克所有文章中引用量第二高的。命题逻辑的可满足性是测试一组逻辑公式是否有可满足的真值分配。而一般的定理证明问题则是测试不可满足性,也就是不存在可满足的真值分配。定理证明问题一般是用反证法,也就是 “不可满足问题”,它是 NP 问题的补,也称 “Co-NP” 问题。这篇文章开启了 “证明复杂性”。
王浩此时也和 IBM 人工智能的老兵顿汉 (Dunham) 合作研究永真式问题的复杂性,研究结果 1976 年发表在《数理逻辑年刊》[16] 上。永真式问题就是把不可满足性问题正过来说,也是 Co-NP 问题。王浩和顿汉对 Co-NP 问题感兴趣主要是因为它和定理证明的关系更加密切。定理证明中最常用的 “归结方法”(resolution)已经被证明不是多项式的 [17]。但 NP 和 Co-NP 是否相等,现在尚不知道。这是 2019 年在纪念库克在多伦多大学任教 50 年的会议上讨论最多的议题之一。素数分解问题属于 NP∩Co-NP,但不知道是否是 NP 完全的,如果素数分解是 NP 完全的,则 NP=Co-NP。相当多属于 NP∩Co-NP 的问题都是多项式的,最广为人知的问题就是线性规划,但我们不知道是不是 P=NP∩Co-NP。值得指出的是,素数分解是量子计算和传统理论计算机科学的最重要的链接。王浩那时正在深研唯物辩证法,能够分神和老友关注 Co-NP 问题实属难得,除了因为他们早期对定理证明的共同兴趣之外,王浩肯定也洞察到库克工作的深刻性并为之吸引。
一个鲜为人知的轶事是王浩把中国数学家洪加威推荐给库克做访问学者。洪加威在多伦多大学访问期间提出了曾经轰动一时的相似性原则,即:计算装置之间互相模拟的成本是多项式的 [18],也就是说靠谱的计算装置之间并不存在原则上的差异。相似性原则实际上是复杂性版本的丘奇 - 图灵论题,也就是强丘奇 - 图灵论题。恰如丘奇 - 图灵论题,它是观察而不是数学定理。洪加威证明了若干种计算模型之间都可以在多项式时间内互相模拟。相似性原则现在较少被人提起,主要原因是它已成为计算理论的工作假设,被大家默认。如果量子计算能够在多项式时间内解决图灵机上不能有效解决的问题,有可能导致强丘奇 - 图灵论题不成立。另外,相比可计算性问题,复杂性问题初看和哲学关系不大,但最熟悉量子计算的理论计算机科学家阿伦森 (Scott Aaronson) 认为复杂性实际上要比可计算性有更多的哲学涵义。
一个插曲:王浩机 (Wang Machine)
冯・诺伊曼架构有两个核心思想,第一是存储程序 (stored-program),第二是随机读取 (RAM)。图灵机的存储纸带是顺序读取而不是随机读取的。但一般大家都把冯・诺伊曼架构等同于第一条,而把第二条当作理所应当。冯・诺伊曼早就指出,存储程序就是通用图灵机 (Universal Turing Machine),原创权应归于图灵。王浩注意到在计算机设计上理论和实践的脱节,于是 1954 年在 ACM 的一次会议上发表了《图灵机的一个变种》[19],这篇文章后来重印在 1957 年的 JACM 上。文中,王浩对原始图灵机做了简化和增强,使得计算模型不只是某种思想实验,而在工程上更加可行,结果被称为 “王浩机”。在王浩机中,图灵机中的有限自动机被替换成了一系列程序指令,这已经有点像现代汇编语言了。
明斯基 (Minsky) 是王浩的 “铁粉”,他不仅是人工智能的先行者,也曾经深度介入计算理论,他的学生中唯一得过图灵奖的是理论家布鲁姆 (Manuel Blum)。明斯基在 1967 年出版了计算理论专著 Computation: Finite and Infinite Machines [20],这本书的价值被低估,其实内容深入浅出,今天读来仍有意思。明斯基在书中高度评价了王浩机,称之为 “第一个得自真正计算机模型的图灵机理论”(the first formulation of a Turing-machine theory in terms of computer-like models)。这带动了一批对原始图灵机修正的工作,于是在 60 年代的计算理论的刊物上充斥着各种机器模型的论文。王浩不大看得起这类工作,他说:“作者们不过是找个借口向做实际工作的工程师吹牛说他们是理论家,但又回头向真正的理论家小声说:我们在干实际工作”。
又一个插曲:王浩瓷砖
王浩在研究机器定理证明的过程中,碰到了一阶逻辑的某些子类,AEA 就是其中之一。AEA 就是前束范式只有三个量词的公式,这里 A 是全称量词,E 是存在量词。AEA 被证明也是不可判定的。这有点像把 SAT 问题缩小到 3SAT,仍然是 NP 完全的。为解决并说明 AEA 问题,王浩设计了王浩瓷砖。王浩瓷砖就是用一系列瓷砖来铺满地板,一块砖的四边可以有不同颜色,约束条件是两个相邻的砖头的边颜色必须相同。普遍的铺砖问题是不可解的:王浩的另一位学生伯格 (Robert Berger) 把图灵机归约为铺砖问题,也就是说可以用王浩瓷砖来实现任何图灵机。在贝格和其他人的后续工作中,进一步对 AEA 的各种子类作了梳理。
王浩瓷砖后来在逻辑之外找到了更加广泛的应用,王浩 1965 年在《科学美国人》杂志上写了一篇科普文章介绍王浩瓷砖 [21]。一时间,各路数学家和理论计算机科学家都在拓广王浩的结果。而后来得过诺贝尔物理奖的数学家彭罗斯 (Roger Penrose) 则把王浩瓷砖从四边形推广到多边形,提出了王浩瓷砖的变种 —— 彭罗斯瓷砖,可用于准晶体中原子排列的研究。王浩瓷砖变成了一种组合数学的工具,后来在证明二维细胞自动机可逆性不可判定时也起了重要作用。
思考与结语
获得过数学最高奖之一阿贝尔奖 (Abel Prize) 的理论计算机科学家威格森 (Wigderson) 一直在思考计算理论,特别是计算复杂性理论和其他几门科学的关系 [22],企图说明计算理论对其他学科是有用的。计算理论应该成为通识教育的一部分,就像数学、物理从古希腊时期起一直就是通识教育的核心内容一样。如果要我们定量地比较丘奇 - 图灵论题和牛顿第二定律哪个更重要更基础,恐无标准答案。但丘奇 - 图灵论题应该成为所有人受教育的一部分,这些知识为其他学科设定了边界和可能性,就是俗称 “第一性原则” 的东西。计算理论之于数字化社会,就像牛顿力学之于工业化社会。
和费曼、温伯格、杨振宁等对当代哲学的鄙视不同,阿伦森曾撰长文苦口婆心地劝说哲学家学一些计算理论尤其计算复杂性 [23],但这恐怕是对牛弹琴:学习计算理论需要一定的智力。王浩作为哲学家,有着深厚的数学背景,他对机器定理证明、逻辑的多个分支和计算理论都有过深刻的贡献。同时他又深度卷入他所处时代的重要事件。可惜他去世太早,没有把他的思想更加系统地写出来,这和他晚年一直没有找到合适的话语有关。
在可计算性理论和计算复杂性理论之间,王浩起了承上启下的作用,其实,他介入复杂性理论相对机器定理证明要更早,但他对复杂性理论的贡献多少被忽视。这有外在的原因:图灵 (1936) 和库克 (1971) 影响如此之广之深;另一方面,也有内在的原因:王浩晚年转向哲学,对计算理论兴趣不大。1986~1987 年间,我的老师杨学良教授曾在洛克菲勒大学访问,王浩请杨老师吃饭,席间杨老师谈起我们合作的一项工作用到了王浩研究过的 Co-NP 问题和调度问题的关系,但王浩说他对这类工程性的枝节问题已无兴趣。在哥德尔 40 年代的工作之后,连续统假设 (continuum hypothesis) 一直是数理逻辑学家在家偷偷努力的题目,就像当下数论家都在家里偷偷证明黎曼猜想一样。据说,王浩也曾下过功夫,但 1966 年这个问题被寇恩 (Paul Cohen) 解决之后,王浩就没再投入精力研究过大的技术问题。王浩曾经比较过自己和杨振宁的经历,杨振宁离开普林斯顿高等研究院到石溪分校,好似入世,他以此为基地培养了一批学生;而王浩自己则从哈佛跳槽到洛克菲勒大学,则似躲进象牙塔,因为洛克菲勒没有本科生,不用上课,他可以花更多的时间研究哲学。洛克菲勒大学体制独特,每个教授都有以自己名字命名的实验室,“王实验室” 网罗了当时逻辑学领域最重要的人物。但后来洛克菲勒重定位,消减了数学物理等学科,只保留生物学科,“王实验室” 只剩下王浩,他也真成了 “躲进小楼成一统”[9]。
芝加哥大学的逻辑学家索阿雷 (Robert Soare) 2013 年在评论图灵(1936)时自问 “Why Turing and not Church”[24],他的漂亮自答用了文艺复兴初期的艺术家多拿太罗 (Donatello) 和盛期的米开朗基罗 (Michelangelo) 作对比,他们都有以大卫为题的雕像。但米开朗基罗的大卫像是艺术史最重要的作品之一。多拿太罗比达芬奇大 60 多岁,而米开朗基罗比达芬奇小 23 岁。索阿雷引用艺术史家的评论,认为米开朗基罗最完美地体现了艺术家在现代的概念,即使是和达芬奇相比。他暗喻图灵是计算理论的米开朗基罗。我们也可以对计算复杂性类比发问 “Why Cook,but not Hartmanis,not Cobham,not Nash,not even Turing nor Wittgenstein”,因为库克就是复杂性理论的米开朗基罗。
王浩呢?他更像是比米开朗基罗年长一辈、更加多才多艺且兴趣广泛的达芬奇。对王浩其人和学问都深有研究的哈佛哲学家帕森斯 (Charles Parsons) 曾经在纪念哥德尔 90 岁诞辰的会议上有文:“作为哲学家的王浩”[25],比较了王浩和视王浩为知己的哥德尔两人的哲学方法,他们都是从更加专门的学问起家,逐渐过渡到更加广泛的哲学,帕森斯称之为 “逻辑之旅”(王浩书名),他们晚年都对自己的哲学阐述不够满意,但帕森斯说王浩的哲学对即使不赞同他立场的人也是有益的。这令我们宽慰。 ■
(参考文献略)

尼克
CCF 专业会员,CCCF 特邀专栏作家。乌镇智库理事长,图灵算力研究院院长。早年曾任职于哈佛大学和惠普,后连环创业,曾获吴文俊人工智能科技进步奖。中文著作包括《人工智能简史》、《UNIX 内核剖析》和《哲学评书》等。nick@iwuzhen.org
via:
-
CCCF 专栏 | 计算复杂性 50 年:王浩与计算理论 原创 尼克 中国计算机学会 2021 年 12 月 21 日 17:25 北京
计算复杂性理论:从 P 与 NP 问题到元复杂性
原创 Goñi-Moreno 集智俱乐部 2024 年 06 月 12 日 21:41 北京
~
导语
证明一个问题难以解决这件事究竟有多难?这是元复杂性理论学家一直追问的问题。经过数十年,探索的路径从 P 与 NP 问题转变到元复杂性问题,他们试图通过复杂性理论的视角观察复杂性理论本身。
研究领域:计算复杂性,理论计算机科学,P 与 NP 问题,信息论,元复杂性,自指

Ángel Goñi-Moreno | 作者
朱欣怡 | 译者
梁金 | 审校
文章题目:Complexity Theory’s 50-Year Journey to the Limits of Knowledge
文章链接:https://www.quantamagazine.org/complexity-theorys-50-year-journey-to-the-limits-of-knowledge-20230817/

复杂性理论发展的 100 年历程。|来源:Samuel Velasco/Quanta Magazine
1. 起源
2007 年秋季学期,Marco Carmosino 在读大二,正考虑从大学退学去设计电子游戏。开学第一周,他硬着头皮去参加马塞诸塞大学阿默斯特分校计算机科学专业必修的数学课。然后教授提出了一个改变他一生的简单问题:**你怎么知道数学真的有用?
Carmosino 现在成为了 IBM 的理论计算机科学家,他回忆当时场景说,“这个问题让我坐直起来,并集中注意力”。他后来报名了一个关于库尔特・哥德尔(Kurt Gödel)工作的选修研讨会。哥德尔关于自指论证的工作令人眼花缭乱,既暴露了数学推理的局限性,还为未来所有关于计算基本极限的工作奠定了基础。Carmosino 从中受益匪浅。他说道:“我完全听不懂,但我知道这就是我想干的。”
如今,即使是经验丰富的研究人员在面对理论计算机科学中的核心开放问题 —— 即 P 与 NP 问题 —— 时,也会发现理解欠缺。这个问题本质上在问:那些长期以来被认为难以计算的问题是否可以(通过我们尚未发现的秘密捷径)轻松解决?或者,就像绝大多数研究者怀疑的那样,他们的确就是很难。关键在于可知事物的本质。
尽管研究者们在计算复杂性理论(computational complexity theory)—— 研究不同问题的本质困难 —— 领域耕耘数十年,但 P 与 NP 问题仍让人摸不着头脑,甚至不知道证明该从何开始。Michael Sipser 是麻省理工学院资深复杂性理论学家,在 20 世纪 80 年代思考这个问题多年。他形容这种探索就像 “没有路线图,走进荒野。”
证明计算问题难以解决本身似乎就很艰巨。但为什么这么难呢?到底难成什么样呢?Carmosino 和其他元复杂性(meta-compl
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









