







注:本文为 AI 趋势相关文章合辑。
英文文章机翻,未校。
The next wave of AI won’t be driven by LLMs.
THE FUTURE – AUGUST 10. 2024
Here’s what investors should focus on instead
下一波 AI 浪潮不会由 LLM 驱动。
以下是投资者应该关注的
BY Vivek Wadhwa
Vivek Wadhwa is an academic, entrepreneur, and author. His book, From Incremental to Exponential, explains how large companies can see the future and rethink innovation.
October 18, 2024 at 6:03 PM GMT+8

Investors are piling in on large language models—but this particular technology may be plateauing.
Apple just published a paper that subtly acknowledges what many in the artificial intelligence (AI) community have been hinting at for some time: Large language models (LLMs) are approaching their limits. These systems—like OpenAI’s GPT-4—have dazzled the world with their ability to generate human-like text, answer complex questions, and assist in tasks across industries. But behind the curtain of excitement, it’s becoming clear that we may be hitting a plateau. This isn’t just Apple’s perspective. AI experts like Gary Marcus have been sounding the alarm for years, warning that LLMs, despite their brilliance, are running into significant limitations.
Apple 刚刚发表了一篇论文,巧妙地承认了人工智能 (AI) 社区中的许多人一段时间以来一直在暗示的事情:大型语言模型 (LLM) 正在接近其极限。这些系统(如 OpenAI 的 GPT-4)以其生成类似人类的文本、回答复杂问题和协助跨行业任务的能力而让世界眼花缭乱。但在兴奋的幕后,很明显我们可能正在进入一个平台期。这不仅仅是 Apple 的观点。多年来,像 Gary Marcus 这样的 AI 专家一直在敲响警钟,他们警告说,LLM 尽管非常出色,但正面临重大限制。
Yet, despite these warnings, venture capitalists (VCs) have been pouring billions into LLM startups like lemmings heading off a cliff. The allure of LLMs, driven by the fear of missing out on the next AI gold rush, has led to a frenzy of investment. VCs are chasing the hype without fully appreciating the fact that LLMs may have already peaked. And like lemmings, most of these investors will soon find themselves tumbling off the edge, losing their me-too investments as the technology hits its natural limits.
然而,尽管有这些警告,风险投资家 (VC) 还是向 LLM 初创公司投入了数十亿美元,就像跳下悬崖的旅鼠一样。由于担心错过下一次 AI 淘金热,LLM 的吸引力导致了投资狂潮。风险投资公司正在追逐炒作,而没有完全意识到 LLM 可能已经达到顶峰的事实。就像旅鼠一样,这些投资者中的大多数很快就会发现自己从边缘跌落,随着技术达到其自然极限,他们失去了他们的仿制投资。
LLMs, while revolutionary, are flawed in significant ways. They’re essentially pattern-recognition engines, capable of predicting what text should come next based on massive amounts of training data. But they don’t actually understand the text they produce. This leads to well-documented issues like hallucination—where LLMs confidently generate information that’s completely false. They may excel at mimicking human conversation but lack true reasoning skills. For all the excitement about their potential, LLMs can’t think critically or solve complex problems the way a human can.
LLM 虽然具有革命性,但在重大方面存在缺陷。它们本质上是模式识别引擎,能够根据大量训练数据预测接下来应该出现的文本。但他们实际上并不理解他们产生的文本。这会导致有据可查的问题,例如幻觉——LLM 自信地生成完全错误的信息。他们可能擅长模仿人类对话,但缺乏真正的推理能力。尽管对他们的潜力感到兴奋,但 LLM 无法像人类那样批判性地思考或解决复杂的问题。
Moreover, the resource requirements to run these models are astronomical. Training LLMs requires enormous amounts of data and computational power, making them inefficient and costly to scale. Simply making these models larger or training them on more data isn’t going to solve the underlying problems. As Apple’s paper and others suggest, the current approach to LLMs has significant limitations that cannot be overcome by brute force.
此外,运行这些模型所需的资源是天文数字。训练 LLM 需要大量的数据和计算能力,这使得它们效率低下且扩展成本高昂。简单地使这些模型更大或使用更多数据训练它们并不能解决根本问题。正如 Apple 的论文和其他论文所表明的那样,当前的 LLM 方法具有很大的局限性,无法通过暴力破解来克服。
This is why AI experts like Gary Marcus have been calling LLMs “brilliantly stupid.” They can generate impressive outputs but are fundamentally incapable of the kind of understanding and reasoning that would make them truly intelligent. The diminishing returns we’re seeing from each new iteration of LLMs are making it clear that we’re nearing the top of the S-curve for this particular technology.
这就是为什么像 Gary Marcus 这样的 AI 专家一直称 LLM “非常愚蠢”。他们可以产生令人印象深刻的输出,但从根本上无法获得使他们真正聪明的那种理解和推理能力。我们从 LLM 的每一次新迭代中看到的收益递减清楚地表明,我们正在接近这项特定技术的 S 曲线的顶部。
But this doesn’t mean AI is dead—not even close. The fact that LLMs are hitting their limits is just a natural part of how exponential technologies evolve. Every major technological breakthrough follows a predictable pattern, often called the S-curve of innovation. At first, progress is slow and filled with false starts and failures. Then comes a period of rapid acceleration, where breakthroughs happen quickly and the technology begins to change industries. But eventually, every technology reaches a plateau as it hits its natural limits.
但这并不意味着 AI 已经死了,甚至还差得很远。LLM 正在达到极限的事实只是指数级技术发展的自然组成部分。每一项重大技术突破都遵循一个可预测的模式,通常称为创新的 S 曲线。起初,进展缓慢,充满了错误的开始和失败。然后是快速加速的时期,突破迅速发生,技术开始改变行业。但最终,每一项技术都会在达到其自然极限时达到一个平台期。
We’ve seen this pattern play out with countless technologies before. Take the internet, for example. In the early days, skeptics dismissed it as a tool for academics and hobbyists. Growth was slow, and adoption was limited. But then came a rapid acceleration, driven by improvements in infrastructure and user-friendly interfaces, and the internet exploded into the global force it is today. The same happened with smartphones. Early versions were clunky and unimpressive, and many doubted their long-term potential. But with the introduction of the iPhone, the smartphone revolution took off, transforming nearly every aspect of modern life.
我们以前已经看到这种模式在无数技术中发挥作用。以互联网为例。在早期,怀疑论者将其视为学者和业余爱好者的工具。增长缓慢,采用率有限。但随后,在基础设施和用户友好界面的改进推动下,互联网迅速加速发展,互联网迅速发展成为今天的全球力量。智能手机也是如此。早期版本笨拙且不起眼,许多人怀疑它们的长期潜力。但随着 iPhone 的推出,智能手机革命掀起,几乎改变了现代生活的方方面面。
One of the most promising areas of AI development is neurosymbolic AI. This hybrid approach combines the pattern recognition capabilities of neural networks with the logical reasoning of symbolic AI. Unlike LLMs, which generate text based on statistical probabilities, neurosymbolic AI systems are designed to truly understand and reason through complex problems. This could enable AI to move beyond merely mimicking human language and into the realm of true problem-solving and critical thinking.
AI 开发最有前途的领域之一是神经符号 AI。这种混合方法将神经网络的模式识别功能与符号 AI 的逻辑推理相结合。与根据统计概率生成文本的 LLM 不同,神经符号 AI 系统旨在真正理解和推理复杂问题。这可能使 AI 超越仅仅模仿人类语言,进入真正的问题解决和批判性思维领域。
Another key area of research is focused on making AI models smaller, more efficient, and more scalable. LLMs are incredibly resource-intensive, but the future of AI may lie in building models that are more powerful while being less costly and easier to deploy. Rather than making models bigger, the next wave of AI innovation may focus on making them smarter and more efficient, unlocking a broader range of applications and industries.
另一个关键研究领域集中在使 AI 模型更小、更高效、更具可扩展性。LLM 非常耗费资源,但 AI 的未来可能在于构建更强大、成本更低且更易于部署的模型。下一波 AI 创新浪潮可能侧重于使模型更智能、更高效,从而解锁更广泛的应用和行业,而不是让模型变得更大。
Context-aware AI is also a major focus. Today’s LLMs often lose track of the context in conversations, leading to contradictions or nonsensical responses. Future models could maintain context more effectively, allowing for deeper, more meaningful interactions.
情境感知 AI 也是一个主要关注点。今天的 LLM 经常在对话中忘记上下文,导致矛盾或荒谬的回应。未来的模型可以更有效地维护上下文,从而实现更深入、更有意义的交互。
The ethical challenges that have plagued LLMs—such as bias, misinformation, and their potential for misuse—are also being tackled head-on in the next wave of AI research. The future of AI will depend on how well we can align these systems with human values and ensure they produce accurate, fair, and unbiased results. Solving these issues will be critical for the widespread adoption of AI in high-stakes industries like healthcare, law, and education.
困扰 LLM 的道德挑战(例如偏见、错误信息及其滥用的可能性)也在下一波 AI 研究中得到正面解决。AI 的未来将取决于我们如何将这些系统与人类价值观保持一致,并确保它们产生准确、公平和公正的结果。解决这些问题对于人工智能在医疗保健、法律和教育等高风险行业的广泛采用至关重要。
Every great technological leap is preceded by a period of frustration and false starts, but when it hits an inflection point, it leads to breakthroughs that change everything. That’s where we’re headed with AI. When the next S-curve hits, it will make today’s technology look primitive by comparison. The lemmings may have run off a cliff with their investments, but for those paying attention, the real AI revolution is just beginning.
每一次伟大的技术飞跃之前都会有一段挫折和错误的开始,但当它达到拐点时,它会导致改变一切的突破。这就是我们 AI 的发展方向。当下一个 S 曲线出现时,相比之下,它将使今天的技术显得原始。旅鼠的投资可能已经从悬崖上滑落,但对于那些关注的人来说,真正的 AI 革命才刚刚开始。
LLMs are a dead end to AGI, says François Chollet
LLM 是 AGI 的死胡同,François Chollet 说
August 10, 2024,Kristin Houser
His $1 million ARC Prize competition is designed to put us on the right path.
Key Takeaways
- Artificial general intelligence (AGI) could change the world, but no one seems to know how close we are to building it.
通用人工智能 (AGI) 可以改变世界,但似乎没有人知道我们离构建它还有多远。
-
Today’s generative AIs score well on benchmarks, but such benchmarks can be solved through memorization and don’t necessarily signal general intelligence.
今天的生成式 AI 在基准测试中得分很高,但这样的基准测试可以通过记忆来解决,并不一定表示一般智能。 -
To accelerate progress in AI, François Chollet launched ARC Prize, a competition to see which AIs can score highest on a set of abstraction and reasoning tasks.
为了加快 AI 的进步,François Chollet 发起了 ARC Prize,这是一项竞赛,旨在看看哪些 AI 可以在一组抽象和推理任务中获得最高分。
It’s 2030, and artificial general intelligence (AGI) is finally here. In the years to come, we’ll use this powerful technology to cure diseases, accelerate discoveries, reduce poverty, and more. In one small way, our journey to AGI can be traced back to a $1 million contest that challenged the AI status quo back in 2024.
现在是 2030 年,通用人工智能 (AGI) 终于来了。在未来几年,我们将利用这项强大的技术来治疗疾病、加速发现、减少贫困等。从某种程度上说,我们的 AGI 之旅可以追溯到 2024 年挑战 AI 现状的 100 万美元竞赛。
Artificial general intelligence 通用人工智能
Artificial general intelligence (AGI) — software with human-level intelligence — could change the world, but no one seems to know how close we are to building it. Experts’ predictions range from 2029 to 2300 to never. Some insist AGI is already here.
通用人工智能 (AGI) — 具有人类水平智能的软件 — 可以改变世界,但似乎没有人知道我们离构建它还有多远。专家的预测范围从 2029 年到 2300 年再到永远不会。一些人坚持认为 AGI 已经存在。
To find out why it’s so hard to predict the arrival of AGI, let’s take a look at the history of AI, the ways we currently measure machine intelligence, and the $1 million competition that could help guide us to this world-changing software.
要找出为什么很难预测 AGI 的到来,让我们来看看 AI 的历史、我们目前衡量机器智能的方式,以及可能有助于指导我们开发这款改变世界的软件的 100 万美元的竞争。
Where we’ve been 我们去过的地方

Where we’re going (maybe) 我们要去哪里(也许)
So, how will we know when AGI is going to arrive?
那么,我们如何知道 AGI 何时到来呢?
Benchmark tests are a useful way to track AI progress, and choosing them for AIs designed for just one task is generally pretty easy — if you’re training an AI to identify heart problems from echocardiograms, for example, your benchmark might be its accuracy compared to doctors.
基准测试是跟踪 AI 进度的有用方法,为专为一项任务设计的 AI 选择基准测试通常非常容易——例如,如果您正在训练 AI 从超声心动图中识别心脏问题,那么您的基准可能是它与医生相比的准确性。
But AGI is, by definition, supposed to possess general intelligence, the kind humans have. How do you benchmark for that?
但根据定义,AGI 应该拥有一般智能,即人类所拥有的那种智能。您如何对此进行基准测试?
For decades, many considered the Turing test a solid benchmark for AGI (even if that’s not exactly how Alan Turing intended it to be used). If an AI could convince a human evaluator that it was human, it was functionally exhibiting human-level intelligence, the thinking went.
几十年来,许多人认为图灵测试是 AGI 的可靠基准(即使这并不完全是 Alan Turing 的意图)。这种想法是,如果人工智能能够让人类评估者相信它是人类,那么它在功能上就表现出了人类水平的智能。
Top Stories
But when a chatbot modeled after a teenager “passed” the Turing test in 2014 by, well, acting like a teenager — deflecting questions, cracking jokes, and basically acting sort of dumb — nothing about it felt particularly intelligent, let alone intelligent enough to change the world.
但是,当一个以青少年为原型的聊天机器人在 2014 年“通过”了图灵测试时,嗯,表现得像个青少年——转移问题,开玩笑,基本上表现得有点愚蠢——它没有什么特别聪明的感觉,更不用说聪明到足以改变世界了。

The avatar of Eugene Goostman, the AI credited with passing the Turing test in 2014. (Credit: Vladimir Veselov)
Since then, breakthroughs in large language models (LLMs) — AIs trained on huge datasets of text to predict human-like responses — have led to chatbots that can easily fool people into thinking they’re human, but those AIs don’t seem very intelligent, either, especially since what they say is often false.
从那时起,大型语言模型 (LLM) 的突破——在大量文本数据集上训练以预测类似人类的反应的 AI——导致了聊天机器人很容易欺骗人们认为他们是人类,但这些 AI 似乎也不是很聪明,尤其是因为它们所说的往往是假的。
With the Turing test deemed broken, “outdated,” and “far beyond obsolete,” AI developers needed new benchmarks for AGI, so they started having their models take the toughest tests we have for people, like the bar exam and the MCAT, and the MMLU, a benchmark created in 2020 specifically to evaluate language models’ knowledge on a range of subjects.
由于图灵测试被认为已损坏、“过时”和“远远过时”,AI 开发人员需要新的 AGI 基准,因此他们开始让他们的模型参加我们为人们准备的最严格的测试,例如律师考试和 MCAT,以及 MMLU,这是一个于 2020 年创建的基准,专门用于评估语言模型在一系列学科上的知识。
Now, developers regularly report how their newest AIs performed relative to human test takers, previous AI models, and their AI competitors, and publish their results in papers with titles such as “Sparks of Artificial General Intelligence.”
现在,开发人员会定期报告他们最新的 AI 相对于人类考生、以前的 AI 模型和 AI 竞争对手的表现,并在标题为“通用人工智能的火花”的论文中发布他们的结果。
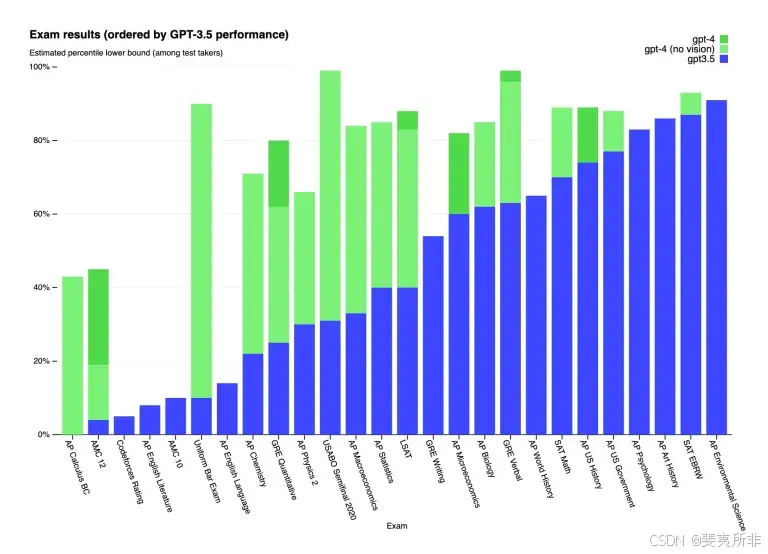
Credit: OpenAI
These benchmarks do give us a more objective way to evaluate and compare AIs than the Turing test, but despite the way they look, they aren’t necessarily showing progress toward AGI, either.
与图灵测试相比,这些基准测试确实为我们提供了一种更客观的方法来评估和比较 AI,但无论它们看起来如何,它们也不一定能显示 AGI 的进展。
LLMs are trained on massive troves of text, mostly pulled from the internet, so it’s likely that many of the exact same questions being used to evaluate a model were included in its training data — at best, tipping the scales and, at worst, allowing it to simply regurgitate answers rather than perform any sort of human-like reasoning.
LLM 是在大量文本上进行训练的,这些文本大部分来自互联网,因此其训练数据中可能包含许多用于评估模型的完全相同的问题——最好的情况是,天平倾斜,最坏的情况是,允许它简单地反刍答案,而不是执行任何类似人类的推理。
And because AI developers typically don’t release details on their training data, those outside the companies — the people trying to prepare for the (maybe) imminent arrival of AGI — don’t really know for certain whether this issue, known as “data contamination,” is affecting test results.
由于 AI 开发人员通常不会公布其训练数据的详细信息,因此公司外部的人——那些试图为(可能)即将到来的 AGI 做准备的人——并不确定这个被称为“数据污染”的问题是否会影响测试结果。
“Memorization is useful, but intelligence is something else.”
// “记忆是有用的,但智能是另一回事。”- François Chollet
It sure seems to be, though. In testing, researchers have found that a model’s performance on these benchmarks can fall dramatically when it is challenged with slightly reworded test problems or ones that have been created entirely after the cutoff date for its training data.
不过,它似乎确实是。在测试中,研究人员发现,当模型受到略微改写的测试问题或完全在其训练数据截止日期之后创建的测试问题的挑战时,模型在这些基准测试中的性能可能会急剧下降。
“Almost all current AI benchmarks can be solved purely via memorization,” François Chollet, a software engineer and AI researcher, told Freethink. “You can simply look at what kind of questions are in the benchmark, then make sure that these questions, or very similar ones, are featured in the training data of your model.”
“几乎所有当前的 AI 基准测试都可以纯粹通过记忆来解决,”软件工程师兼 AI 研究员 François Chollet 告诉 Freethink。“你可以简单地查看基准测试中有哪些类型的问题,然后确保这些问题或非常相似的问题出现在模型的训练数据中。”
“Memorization is useful, but intelligence is something else,” he added. “In the words of Jean Piaget, intelligence is what you use when you don’t know what to do. It’s how you learn in the face of new circumstances, how you adapt and improvise, how you pick up new skills.”
“记忆是有用的,但情报是另一回事,”他补充说。“用 Jean Piaget 的话来说,智能就是当你不知道该做什么时用到的东西。这是你在面对新环境时如何学习,如何适应和即兴创作,如何掌握新技能。
“It’s designed to be resistant to memorization. And so far, it has stood the test of time.”
“它的设计是为了抵抗记忆。到目前为止,它经受住了时间的考验。François Chollet
In 2019, Chollet published a paper in which he describes a deceptively simple benchmark for evaluating AIs for this kind of intelligence: the Abstraction and Reasoning Corpus (ARC).
2019 年,Chollet 发表了一篇论文,他在论文中描述了一个看似简单的基准来评估 AI 的这种智能:抽象和推理语料库 (ARC)。
“It’s a test of skill-acquisition efficiency, where every task is intended to be novel to the test-taker,” said Chollet. “It’s designed to be resistant to memorization. And so far, it has stood the test of time.”
“这是对技能获取效率的测试,每项任务对考生来说都是新的,”Chollet 说。“它的设计是为了抵抗记忆。到目前为止,它经受住了时间的考验。
ARC is similar to a human IQ test invented in 1938, called Raven’s Progressive Matrices. Each question features pairs of grids, ranging in size from 1×1 to 30×30. Each pair has an input grid and an output grid, with cells in the grids filled in with up to 10 different colors.
ARC 类似于 1938 年发明的人类智商测试,称为 Raven 的渐进矩阵。每个问题都有成对的网格,大小从 1×1 到 30×30 不等。每对都有一个输入网格和一个输出网格,网格中的单元格最多填充 10 种不同的颜色。
The AI’s job is to predict what the output should look like for a given input, based on a pattern established by one or two examples.
AI 的工作是根据一两个示例建立的模式来预测给定输入的输出应该是什么样子。
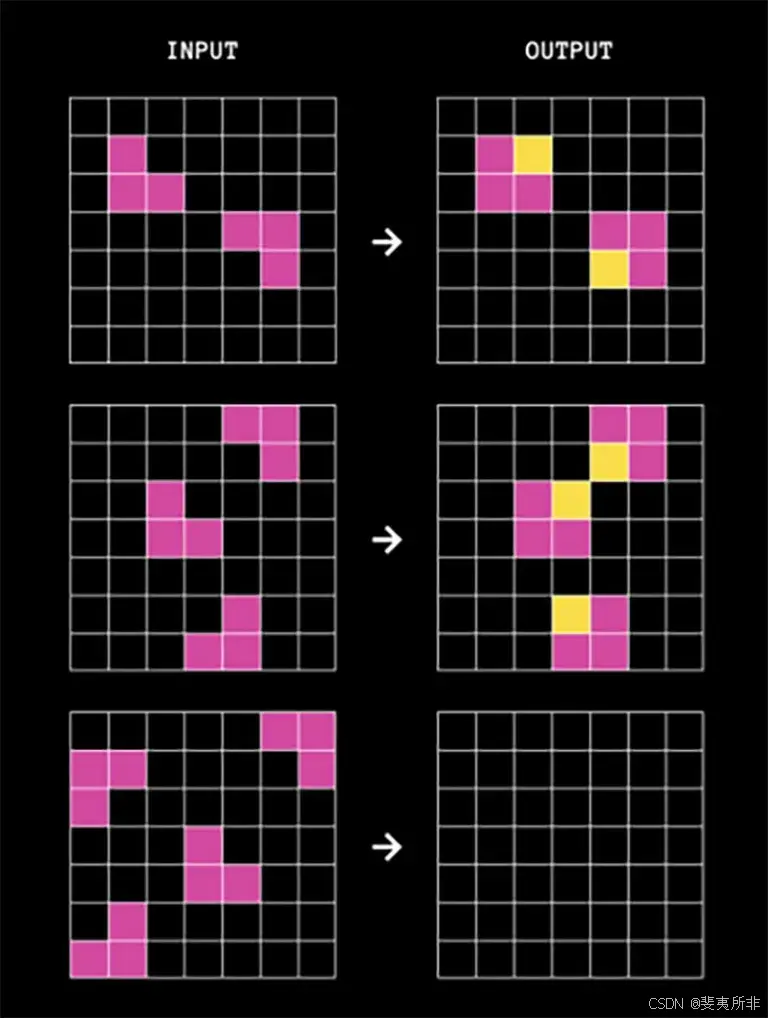
An example of an ARC problem. (Credit: ARC Prize)
Since publishing his paper, Chollet has hosted several ARC competitions involving hundreds of AI developers from more than 65 nations. Initially, their best AIs could solve 20% of ARC tasks. By June 2024, that had increased to 34%, which is still far short of the 84% most humans can solve.
自发表论文以来,Chollet 举办了多场 ARC 竞赛,涉及来自超过 65 个国家/地区的数百名 AI 开发人员。最初,他们最好的 AI 可以解决 20% 的 ARC 任务。到 2024 年 6 月,这一比例已增加到 34%,仍远低于大多数人可以解决的 84%。
To accelerate progress in AI reasoning, Chollet teamed up with Mike Knoop, co-founder of workflow automation company Zapier, in June to launch ARC Prize, a competition to see which AIs can score highest on a set of ARC tasks, with more than $1 million (and a lot of prestige) up for grabs for the best systems.
为了加快 AI 推理的进展,Chollet 与工作流自动化公司 Zapier 的联合创始人 Mike Knoop 合作,于 6 月发起了 ARC Prize,这是一项竞赛,旨在看看哪些 AI 可以在一组 ARC 任务中获得最高分,最佳系统将获得超过 100 万美元(和很高的声望)的奖金。
Public training and evaluation sets for the competition, each consisting of 400 ARC tasks, are available to developers on GitHub. Entrants must submit their code by November 10, 2024, to compete.
开发人员可以在 GitHub 上获得比赛的公开培训和评估集,每个集包含 400 个 ARC 任务。参赛者必须在 2024 年 11 月 10 日之前提交其代码才能参加比赛。
The AIs will then be tested on ARC Prize’s private evaluation set of 100 tasks offline — this approach ensures test questions won’t get leaked and AIs won’t get a chance to see them before the evaluation.
然后,AI 将在 ARC Prize 的 100 个任务的私人评估集上进行离线测试——这种方法可以确保测试问题不会泄露,并且 AI 没有机会在评估前看到它们。
Winners will be announced on December 3, 2024, with the five highest scoring AIs each receiving between 5,000 and 25,000 (at the time of writing, one team has managed 43%). To win the grand prize of $500,000, an entrant’s AI must solve 85% of the tasks. If no one wins, that prize money will roll over to a 2025 competition.
获胜者将于 2024 年 12 月 3 日公布,得分最高的五个 AI 每人获得 5,000 至 25,000 美元(在撰写本文时,一个团队获得了 43%)。要赢得 500,000 美元的大奖,参赛者的 AI 必须解决 85% 的任务。如果没有人获胜,这笔奖金将滚存到 2025 年的比赛中。
To be eligible for any prizes, developers must be willing to open source their code.
要获得任何奖品的资格,开发人员必须愿意开源他们的代码。
“The purpose of ARC Prize is to redirect more AI research focus toward architectures that might lead toward artificial general intelligence (AGI) and ensure that notable breakthroughs do not remain a trade secret at a big corporate AI lab,” according to the competition’s website.
“ARC Prize 的目的是将更多的 AI 研究重点转向可能导致通用人工智能 (AGI) 的架构,并确保重大突破不会在大型企业 AI 实验室中成为商业机密,”比赛网站称。
“OpenAI basically set back progress to AGI by five to 10 years.”
“OpenAI 基本上将 AGI 的进展倒退了 5 到 10 年。”François Chollet
This new direction could likely be away from LLMs and similar generative AIs. They raked in nearly half of AI funding in 2023, but — according to Chollet — are not only unlikely to lead to AGI, but are actively slowing progress toward it.
这个新方向可能会远离 LLM 和类似的生成式 AI。他们在 2023 年获得了近一半的人工智能资金,但根据 Chollet 的说法,它们不仅不太可能导致 AGI,而且正在积极减缓实现 AGI 的进展。
“OpenAI basically set back progress to AGI by five to 10 years,” he told the Dwarkesh Podcast. “They caused this complete closing down of frontier research publishing, and now LLMs have essentially sucked the oxygen out of the room — everyone is doing LLMs.”
“OpenAI 基本上将 AGI 的进展倒退了 5 到 10 年,”他告诉 Dwarkesh 播客。“他们导致了前沿研究出版的完全关闭,现在 LLM 基本上已经从房间里吸走了氧气——每个人都在做 LLM。”
He’s not alone in his skepticism that LLMs are getting us any closer to AGI.
他不是唯一一个怀疑 LLM 让我们更接近 AGI 的人。
Yann LeCun, Meta’s chief AI scientist, told the Next Web that “on the path towards human-level intelligence, an LLM is basically an off-ramp, a distraction, a dead end,” and OpenAI’s own CEO Sam Altman has said he doesn’t think scaling up LLMs will lead to AGI.
Meta 的首席人工智能科学家 Yann LeCun 告诉 Next Web,“在迈向人类水平智能的道路上,LLM 基本上是一个出口,一个分心,一个死胡同,”OpenAI 自己的首席执行官 Sam Altman 表示,他认为扩大 LLM 不会导致 AGI。
As for what kind of AI is most likely to lead to AGI, it’s too soon to say, but Chollet has shared details on the approaches that have performed best at ARC so far, including active inference, DSL program synthesis, and discrete program search. He also believes deep learning models could be worth exploring and encourages entrants to try novel approaches.
至于什么样的 AI 最有可能导致 AGI,现在说还为时过早,但 Chollet 分享了迄今为止在 ARC 上表现最好的方法的详细信息,包括主动推理、DSL 程序综合和离散程序搜索。他还认为深度学习模型值得探索,并鼓励参赛者尝试新颖的方法。
Ultimately, if he and others are right that LLMs are a dead end on the path to AGI, a new test that can actually identify “sparks” of general intelligence in AI could be hugely valuable, helping the industry shift focus to researching the kinds of models that will lead to AGI as soon as possible — and all the world-changing benefits that could come along with it.
归根结底,如果他和其他人认为 LLM 是通往 AGI 之路上的一条死胡同,那么一项可以真正识别 AI 中通用智能“火花”的新测试可能非常有价值,帮助行业将重点转移到研究将尽快导致 AGI 的模型类型——以及可能随之而来的所有改变世界的好处。
Yann LeCun 最新万字演讲:致力于下一代 AI 系统,我们基本上不做 LLM 了
AI 寒武纪 2024 年 10 月 16 日 12:49 江苏


Yann LeCun 最新哈德逊论坛演讲:了解我们在通往人类水平 AI 的旅程中所处的位置,Yann 基本上对现在 LLM 发展方向持否定态度
Yann LeCun 说,扎克伯格(Mark Zuckerberg)一直在问他需要多长时间才能达到人类水平的人工智能,而他告诉马克 - 扎克伯格,即使不是十年,也要好几年的时间
人类智能有四个基本特征是目前的人工智能系统所不具备的:推理、规划、持久记忆和理解物理世界。一旦我们拥有了具备这些能力的系统,还需要一段时间才能将它们提升到人类的水平
Yann LeCun 是 Facebook AI 研究院(Fair)的首席 AI 科学家,也是纽约大学的教授。他获得了许多奖项,包括 2018 年的 ACM 图灵奖。他是美国人工智能协会(AAAI)的成员,也是美国国家工程院院士
我们看看 Yann LeCun 最新的演讲又说了什么?
Yann LeCun 哈德逊论坛上的主题演讲全文
Yann LeCun,“人类水平的 AI”
我将要谈论人类水平的 AI,以及我们如何到达那里,以及我们不会如何到达那里

为何需要人类水平的 AI?
首先,我们需要人类水平的 AI,因为在未来,我们大多数人都会佩戴智能眼镜或其他类型的设备,我们会与它们交谈,而这些系统将托管助手,也许不只一个,也许是一整套助手。这将导致我们每个人基本上都有一组聪明的虚拟人为我们工作。就像每个人都是老板,只是不是真正的员工。我们需要构建这个来增强人类的智力,你知道,让人们更有创造力、更高效等等。但为此,我们需要能够理解世界的机器,它们可以记住事情,拥有直觉,拥有常识,可以像人类一样推理和计划。尽管你可能从一些最热情的人那里听到过,但当前的 AI 系统无法做到这些
所以这就是我们需要的,能够学习建立世界模型的系统,拥有关于世界如何运作的心理模型。每个动物都有这样的模型,你的猫肯定有一个比任何 AI 系统都更复杂的模型。拥有持久记忆的系统,这是目前的 LLM 所不具备的;能够规划复杂动作序列的系统,这在今天的 LLM 中是不可能的;以及可控和安全的系统
我将要提出一个架构,我称之为 “目标驱动 AI”。我写了一篇关于此的愿景论文,大约两年前发表了,Fair 的很多人都致力于实现这个计划。Fair 过去常常结合长期的和更应用的项目,但是一年半以前,Meta 创建了一个名为 GenAI 的产品部门,专注于 AI 产品,他们进行应用研发。所以现在 Fair 已经被重新定向到更长期的、下一代 AI 系统。我们基本上不做 LLM
当前 AI 系统的局限性:自监督学习的瓶颈
所以,AI 的成功,包括 LLM,包括过去五六年的许多其他系统,都依赖于一套我称之为自监督学习的技术。使用自监督学习的一种方法是,自监督学习包括训练一个系统,不是为了任何特定任务,而是基本上试图以一种良好的方式表示输入。一种方法是通过从损坏中重建:假设一段文本,你通过删除单词或更改其他单词来破坏它,你知道,它可以是文本,也可以是 DNA 序列或蛋白质或其他任何东西,甚至在某种程度上也可以是图像,然后你训练一个巨大的神经网络来重建完整的、未损坏的版本。这是一个生成模型,因为它试图重建原始信号
这应该是可以的,但它没有投射。所以红色框就像一个成本函数,它计算输入 y 和重建 y 之间的距离,这就是学习相对于系统中的参数最小化的目标。现在,在这个过程中,系统学习了输入的内部表示,可以用于各种后续任务。它当然可以用来预测文本中的单词,这就是自回归预测所发生的事情。LLM 是这种情况的特例,其中的架构被设计成,为了预测一个项目、一个标记或一个单词,它只能查看它左边的其他标记,它不能查看未来
所以如果你训练一个系统来做这个,你给它看一段文本,你让它预测文本中的下一个单词或下一个标记,然后你可以使用这个系统来预测下一个单词,然后你将下一个单词移到输入中,然后预测第二个单词,然后将它移到输入中,预测第三个单词,这就是自回归预测。这就是 LLM 所做的,这不是一个新概念,它自 CL Shannon 以来就一直存在,可以追溯到 50 年代,那是很久以前了。但改变的是,现在我们有了巨大的神经网络架构,我们可以在海量的数据上进行训练,而且看起来某些属性由此而生。但是自回归预测有一些主要的局限性,这里没有通常意义上的真正的推理。还有一个限制,就是这只适用于以离散对象、符号、标记、单词、你可以离散化的东西的形式出现的数据
我们仍然缺少一些重要的东西来达到人类水平的智力。我在这里不一定指的是人类水平的智力,但即使是你的猫或你的狗也能做出令人惊叹的壮举,而这些壮举仍然完全超出了当前 AI 系统的能力范围。一个 10 岁的孩子怎么能在一次尝试中就学会清理餐桌并装满洗碗机?一个 17 岁的孩子可以在大约 20 小时的练习中学会开车。我们仍然没有 5 级自动驾驶汽车,我们当然也没有可以清理餐桌并装满洗碗机的家用机器人。所以我们真的缺少了一些重要的东西,否则我们就能用 AI 系统做到这些事情
莫拉维克悖论与学习的挑战
我们不断地碰到这个叫做莫拉维克悖论的东西,那就是对我们来说看起来微不足道、我们甚至不认为是智能的事情,用机器来做似乎真的非常困难。但是像高级的、复杂的、抽象的思维,比如操纵语言,对机器来说似乎很容易,或者像下国际象棋和围棋之类的事情
所以,这其中的一个原因可能是以下几点。一个 LLM 通常训练在 20 万亿个标记上,一个标记基本上是…… 平均来说,对于一个典型的语言,大约是四分之三个单词。所以那是 1.5 x 10^13 个单词。每个标记通常大约是 3 个字节,所以那是 6 x 10^13 个字节。我们任何人读完这些都需要几十万年的时间,这基本上是互联网上所有公开文本的总量
但是,考虑一下一个 4 岁的人类孩子,一个 4 岁的人类孩子总共清醒的时间是 16000 个小时,顺便说一下,这相当于 30 分钟的 “油管” 上传量。我们有 200 万条视神经纤维进入我们的大脑,每条纤维每秒钟大约携带 1 字节,也许是 0.5 字节每秒。一些估计说它是 3 比特每秒,这无关紧要,这是一个数量级。所以数据量大约是 10^14 字节,与 LLM 大致相同数量级。所以在 4 年内,一个孩子看到的视觉数据或数据与在整个互联网上公开文本上训练的最大的 LLM 一样多
所以这告诉你一些事情。这告诉你,首先,我们永远不可能通过仅仅训练文本就达到接近人类水平的智力,这根本不会发生。然后反驳的观点是,好吧,但是视觉信息非常冗余。所以首先,这个每条视神经纤维每秒 1 字节的数据已经比你视网膜中的光感受器压缩了 100 倍。我们的视网膜中有大约 6000 万到 1 亿个光感受器,然后使用你视网膜前面的神经元压缩到 100 万条神经纤维。所以已经有 100:1 的压缩比。然后它到达大脑,然后它被扩展了 50 倍左右。所以我测量的是压缩信息,但它仍然非常冗余。而冗余实际上是自监督学习所需要的。自监督学习只有从冗余数据中学习到一些有用的东西,如果数据是高度压缩的,这意味着它是完全随机的,你什么也学不到。你需要冗余才能学习任何东西,你需要学习数据的底层结构
迈向更强大的 AI:超越像素级预测
所以我们将不得不训练系统通过观看视频或生活在现实世界中来学习常识和物理直觉。我将要稍微打乱一下顺序,然后告诉你一些关于这个目标驱动 AI 架构的真实情况。它与 LLM 或前馈神经网络有很大的不同,因为推理过程不仅仅是运行神经网络的几层,而是实际上运行一个优化算法。从概念上讲,它看起来像这样
前馈过程是一个过程,在这个过程中,你看到一个观察结果,运行通过系统感知系统,例如,神经网络的几层,并产生一个输出。对于任何单个输入,你只能有一个输出。但是有很多情况下,对于一个感知,有多个可能的输出解释,你希望有一个过程,它不仅仅计算一个函数,而是计算一个映射,对于单个输入可能有多个输出。你唯一能做到这一点的方法是通过隐式函数,基本上是一个像这样的目标,右边的红色框,它基本上测量输入和建议输出之间的兼容性,然后通过找到与输入最兼容的一个输出值来计算输出。你可以通过想象这个目标是某种能量函数,并且你正在相对于输出最小化这个能量来做到这一点。你可能有多个解决方案,你可能有一些方法来遍历这些多个解决方案。人类的感知系统就是这样做的,如果你对一个特定的感知有多个解释,你的大脑会自发地循环遍历这些解释。有一些证据表明这种类型的事情可以发生。
但是让我回到架构。使用这种通过优化进行推理的原则,人们思考方式的假设是这样的:你在世界上进行观察,一个感知系统让你了解世界的状态,世界的当前状态。但是当然,它只让你了解你目前可以感知到的世界状态,你可能从记忆中对世界其他状态有一些了解。所以这可能会与记忆的内容相结合,并将其馈送到一个世界模型。什么是世界模型?世界模型是你关于世界如何运作的心理模型。
所以你可以想象你可能会采取的一系列动作,你的世界模型将允许你预测这一系列动作对世界的影响。所以绿色的框,世界模型,你给它一个假设的动作序列,它预测世界的最终状态是什么,或者预测世界中将要发生的事情的整个轨迹。你将它馈送到一堆目标函数,一个目标函数测量目标实现的程度,任务完成的程度,也许还有一组其他目标是护栏,这些目标基本上测量所遵循的轨迹或已采取的行动或对机器人或机器周围的人不危险的事情的程度等等。
所以现在的推理过程,我还没有谈到学习,它只是推理,包括找到使这些目标最小化的动作序列,找到使这些目标最小化的动作序列。这就是推理过程,所以它不仅仅是前馈。你可以通过搜索离散选项来做到这一点,但这效率低下。一个更好的方法是确保所有这些框都是可微的,你通过它们反向传播梯度,并使用梯度下降来更新动作序列。
现在,这个想法一点也不新,它已经有 60 多年了,如果不是更久的话。它是基于…… 好的,所以首先,让我谈谈使用世界模型进行这种推理的好处。好处是你可以基本上完成新的任务而不需要任何学习。我们一直在这样做。我们面临一个新的情况,我们思考它,我们想象我们行动的后果,我们采取将实现我们目标的行动序列,无论它是什么。我们不需要学习来完成这项任务,我们可以计划。所以这基本上就是计划。你也可以将大多数形式的推理简化为优化。
所以这种通过优化进行推理的过程本质上比仅仅运行神经网络中的几层更强大。现在,这种通过优化进行推理的想法,正如我所说的,在最优控制理论领域已经存在了 60 多年,它被称为模型预测控制。你有一个你试图控制的系统的模型,比如说火箭或其他什么东西,或者一架飞机,或者一个机器人,你可以想象,你可以使用你的世界模型计算一系列控制命令的影响,然后你优化这个序列,使运动按照你想要的方式进行。所有经典的机器人运动规划都是这样做的。这不是一件新事物。这里的新事物是我们正在学习世界模型,我们正在学习将提取世界情况的适当抽象表示的感知系统。
现在,在我进入如何运行它的示例之前,你可以构建一个包含所有这些组件的整体 AI 系统:世界模型,可以根据手前任务配置的成本函数,执行器,它是真正优化的模块,根据世界模型找到最佳动作序列,短期记忆,感知系统等等。
那么它是如何工作的呢?所以你…… 如果你的动作不是单个动作,而是一个动作序列,你的世界模型实际上是一个系统,它告诉你,给定时间 t 的世界状态和我可以采取的动作,预测时间 t+1 的世界状态。你想预测在这种情况下两个动作的序列将产生什么结果,你可以多次运行你的世界模型。所以这里它表示为时间展开。获取初始世界状态表示,输入动作 0 的假设,使用世界模型预测世界的下一个状态,然后是动作 1,下一个世界的下一个状态,计算成本,然后通过反向传播和基于梯度的优化方法,找出将最小化成本的两个动作。这就是模型预测控制。
由于世界通常不是完全确定的,你可能需要使用潜在变量来馈送到你的世界模型。所以潜在变量基本上是可以在集合上滑动或从分布中抽取的变量,它们代表…… 它们基本上导致世界模型遍历与观察结果兼容的多个预测。世界并非完全可预测,因此在进行预测时,你可能需要处理这种类型的不确定性。
更有趣的是做人类似乎能够做的事情,当然也包括一些动物,那就是分层规划。如果你正在计划一次从纽约到巴黎的旅行,你可以使用你的世界模型,你身体的模型,也许还有你从这里到巴黎的整个世界配置的想法,根据你的低级肌肉控制来规划你的整个旅行。但当然,没有人会这样做。你做不到,你甚至没有信息来做,而且这有点疯狂。在你到达巴黎之前,你必须做的每 10 毫秒的肌肉控制的步数简直是太疯狂了。所以你所做的是分层规划。你在一个非常高的层次上进行规划,你说,好吧,要去巴黎,我首先需要去机场并乘坐飞机。我如何去机场?假设我在纽约市,我必须走到街上并叫一辆出租车。我如何走到街上?好吧,我必须从椅子上站起来,走到门口,打开门,走到电梯,按下按钮,等等。我如何从椅子上站起来?在某些时候,你可以用低级肌肉控制动作来表达事情,但我们不是用低级来规划整个事情,我们正在进行分层规划。如何用 AI 系统做到这一点是完全未解决的,我们不知道如何做到这一点。这似乎是智能行为的一个相当大的要求。
那么,我们将如何学习具有层次结构、在几个不同抽象层次上工作的世界模型?没有人展示过任何接近这一点的东西。这是一个巨大的挑战。是的,这只是我刚才所说的例子的图形表示。
那么,我们将如何训练这个世界模型呢?因为这真的是一个巨大的挑战。你看看婴儿,这对动物也是如此,心理学家和认知科学家试图弄清楚婴儿在什么年龄学习关于世界的基本概念,比如他们如何学习直觉物理学,物理直觉,所有这些东西。这发生在他们开始学习语言和互动之类的很久以前。
所以像面部追踪这样的事情发生得非常早,生物运动,有生命和无生命物体之间存在差异的事实,这也发生得非常早。物体永久性发生得非常早,当一个物体被另一个物体隐藏时,它仍然存在的事实。然后,你知道,婴儿学习自然种类,你不需要给他们东西的名字,他们会知道椅子、桌子和猫是不同的。稳定性和支撑,但是像重力、惯性、动量守恒这样的东西,实际上只出现在 9 个月左右,这需要很长时间。所以如果你给一个 6 个月大的婴儿看左边的场景,一辆小车在一个平台上,你把它推下平台,它似乎漂浮在空中。6 个月大的婴儿几乎不会注意。一个 10 个月大的婴儿会像那个小女孩一样,她明白这不应该发生,物体应该掉下来。当发生一些令人惊讶的事情时,这意味着你的世界模型是错误的,所以你要注意,因为它可能会杀死你。
所以这里需要发生的学习类型与我们之前讨论的学习类型非常相似。取一个输入,以某种方式破坏它,并训练一个大型神经网络来预测缺失的部分。如果你训练一个系统来预测视频中将要发生的事情,就像我们训练神经网络来预测文本中将要发生的事情一样,也许这些系统将能够学习常识。
坏消息是,我们已经尝试了 10 年,这是一个彻底的失败。我们从来没有能够接近任何真正学习任何关于世界的一般知识的系统,仅仅通过试图预测视频中的像素。你可以训练一个系统来预测看起来不错的视频,现在有很多视频生成系统的例子,但在内部,它们并不是物理世界的良好模型,它们不能用于此。这个想法,我们将使用生成模型来预测视频中将要发生的事情,系统将神奇地理解世界的结构,彻底失败,我们在 10 年里尝试了很多东西。
失败的原因是因为有很多可能的未来,在像文本这样的离散空间中,你无法预测哪个单词将跟随一个单词序列,但你可以生成字典中所有可能单词的概率分布。但如果是视频,视频帧,我们没有很好的方法来表示视频帧上的概率分布。事实上,我的意思是,这项任务是完全不可能的。就像,如果我拍下这个房间的视频,我拿一个相机,我拍下那部分,然后我停止视频,我让系统预测视频中的下一个是什么,它可能会预测在某个时候会有房间的其余部分,会有墙,会有人坐着,密度可能与左边相似,但它不可能在像素级别上准确地预测你们所有人的样子,世界的纹理是什么样子,房间的精确大小,以及所有类似的事情。你不可能准确地预测所有这些细节
联合嵌入预测架构 (JEPA):一种新的希望
所以解决这个问题的方法就是我所说的联合嵌入预测架构,其想法是放弃预测像素。与其预测像素,不如学习一个表示,一个关于世界中发生的事情的抽象表示,然后在该表示空间中进行预测。所以这就是架构,联合嵌入预测架构。这两个嵌入采用 x,损坏的版本,运行到一个编码器;采用 y,运行到一个编码器,然后训练系统从 x 的表示预测 y 的表示。
现在的问题是你如何做到这一点,因为如果你只是使用梯度下降、反向传播来训练这样的系统,以最小化预测误差,它将会崩溃。它会说,它将学习一个常数的表示,现在预测变得超级容易,但它没有信息量。所以,但这就是我希望你们记住的区别,生成架构试图重建预测器、自动编码器、生成架构、自动编码器等等之间的区别,然后是联合嵌入架构,你在表示空间中进行预测。我认为未来在于这些联合嵌入架构。我们有大量的经验证据表明,要学习图像的良好表示,最好的方法是使用这些联合嵌入架构。所有尝试使用重建来学习图像表示的尝试都很糟糕,它们的效果并不好。在这个方面有巨大的项目,并声称它们有效,但它们实际上并没有。最好的性能是通过右边的架构获得的。
现在,如果你仔细想想,这实际上就是我们用智力所做的,找到一个事物或现象的良好表示,以便你可以进行预测。这确实是科学的本质,真的。就像,想想这样一个事实,如果你想预测行星的轨迹,行星是一个非常非常复杂的物体,它非常巨大,它有天气和温度,你知道,密度和所有你可以测量到的关于行星的事情,也许是一个极其复杂的物体,但要预测行星的轨迹,你只需要知道 6 个数字,3 个位置和 3 个速度,仅此而已,你不需要知道任何其他事情。所以这是一个非常重要的例子,它真正证明了这样一个事实:预测能力的本质实际上是为我们观察到的事物找到良好的表示
那么我们如何训练这些东西呢?所以这是一个…… 我们如何训练这些东西?所以你想防止这个系统崩溃。一种方法是有一些成本函数来测量来自编码器的表示的信息内容,并尝试最大化信息内容或最小化负信息,这就是这里写的内容。所以你训练系统同时从输入中提取尽可能多的信息,但同时最小化该表示空间中的预测误差。因此,系统将在提取尽可能多的信息与不提取不可预测的信息之间找到某种平衡。你将得到一个良好的表示空间,在这个空间中你可以进行预测,你可以进行预测
现在,你如何测量信息?这才是事情变得有点奇怪的地方。好的,我将跳过这一点。嗯,有一种方法可以根据训练基于能量的模型和能量函数从数学上理解这一点,但我没有时间深入讨论这个问题。但基本上,我在这里告诉你一些不同的事情:
放弃生成模型,转而使用这些 JEPA 架构;放弃概率模型,转而使用这些基于能量的模型;放弃对比方法,我没有谈论这个,因为我马上就会谈到这个;还有强化学习,但我已经说了 10 年了。而这些都是当今机器学习最流行的四大支柱。所以我现在不是很受欢迎
好的,所以…… 一种方法是对来自编码器的信息内容进行一些估计,目前有六种方法可以做到这一点。实际上这里少了一种叫做 VICReg 的方法,来自我在纽约大学和 Flatiron 的同事。所以这里的一个想法是防止系统崩溃并产生常数。取编码器输出的变量,并确保这些变量具有非零标准偏差。你可以把它放在一批样本的成本函数中,确保权重是这样的,变量不会崩溃并变成常数,这很容易做到。现在的问题是,系统可以作弊,使所有变量相等或高度依赖或相关。所以你必须做的是添加另一个术语,它说我想最小化这些变量的协方差矩阵的非对角线项,以确保它们不相关。当然,这还不够,因为变量仍然可以是依赖的,你知道,依赖但不相关。所以我们使用了另一个技巧,就是将 sx 的维度扩展到更高维的空间 vx,然后在这个空间中应用这种方差 - 协方差正则化,这似乎就足够了
但是有一个技巧,就像我愚弄了你或你们中的一些人,因为我在这里最大化的是信息内容的上限,我祈祷实际的信息内容会跟随我对上限的最大化。我需要的是一个下限,这样会推高下限,信息就会上升。不幸的是,我们没有信息的下限,或者至少我们不知道如何计算它,如果我们有的话。
还有第二套方法,它被称为蒸馏式方法,这种方法以神秘的方式工作。如果你真的想要一个清晰的解释它为什么有效,你应该问 Sylvain Ghouli,他就坐在那里,他有一篇关于这个的论文。就我个人而言,我不明白,但它确实有效。它包括只更新这个架构的一半,而不是在另一半上反向传播梯度,然后以一种有趣的方式共享权重。有很多关于这个的论文,如果你想训练一个完全自监督的系统来学习图像的良好表示,这和任何其他方法一样好。图像的损坏是通过掩码来实现的。
我们有一些更近期的工作,我们在视频上做这个,所以我们可以训练一个系统来基本上提取视频的良好表示,我们可以将其用于下游任务,比如动作识别、视频等等。它包括拍摄一段视频,掩盖其中的一大块,运行它,并在表示空间中进行预测,并使用这种蒸馏技巧来防止崩溃。这非常有效
所以在未来,我们所有的互动,如果我们在这个项目中取得成功,并最终得到能够推理、能够计划、能够理解物理世界的系统,这将需要数年时间,直到我们让这里的一切都运作起来,如果不是十年的话。马克・扎克伯格一直问我需要多长时间。所以如果我们成功地做到了这一点,我们将拥有真正能够调节我们与数字世界所有互动的系统,它们可以…… 它们将回答我们所有的问题,它们将一直与我们同在,它们将基本上构成所有人类知识的宝库。这感觉像是一种基础设施,就像互联网一样,它不像一个产品,更像一个基础设施
开源 AI:构建开放的未来
这个 AI 平台必须是开源的。我不需要说服这里任何来自 IBM 的人,因为 IBM 和 Meta 都是一个叫做 AI 联盟的组织的一部分,该组织推广开源 AI 平台。我真的很感谢 Dario 领导这件事,以及 IBM 的所有人。所以我们需要这些平台是开源的,因为我们需要这些 AI 助手是多样化的,我们需要它们理解世界上所有的语言、所有的文化、所有的价值体系。你不会从美国西海岸或东海岸的一家公司生产的单一助手中获得这些。你知道,这将需要来自全世界的贡献
当然,训练基础模型非常昂贵,所以只有少数公司可以做到这一点。所以如果像 Meta 这样的公司可以开源提供这些基础模型,那么全世界都可以根据自己的目的对其进行微调。所以这就是 Meta 和 IBM 所采用的理念。所以开源 AI 不仅仅是一个好主意,它对于文化多样性,甚至可能是维护民主来说是必要的
所以…… 训练和微调将是众包的,或者是由创业公司和其他公司的生态系统完成的。这真的是启动了 AI 创业公司生态系统的原因,是这些开源 AI 模型的可用性。达到人类水平的 AI 需要多长时间?我不知道,可能是几年到几十年。存在巨大的差异,有很多问题需要解决,而且几乎可以肯定比我们想象的要难。它不会在一天内发生,它会像…… 渐进的进化。所以这不像,有一天我们会发现 AI 的秘密,然后我们会打开一台机器,然后我们立即拥有了超级智能,然后我们所有人都会被超级智能系统杀死。不,不会这样发生。机器将超越人类的智力,但它们将处于控制之下,因为它们将是目标驱动的,我们给它们目标,它们实现这些目标。就像我们这里的许多人都是行业或学术界或其他领域的领导者,我们与比我们聪明的人一起工作,我当然也是。有很多与我一起工作的人比我聪明,但这并不意味着他们想要支配或接管
所以这就是故事。存在风险,但我将把它留到问答环节。非常感谢
诺奖得主 DeepMind CEO 最新万字访谈:视 AI 为普通技术错误,AGI 还差 2 到 3 项重大创新
AI 寒武纪 2024 年 10 月 18 日 10:31 江苏

谷歌 DeepMind CEO Demis Hassabis 说,将人工智能视为普通技术是错误的,人工智能将具有 “划时代的意义”,很快将治愈所有疾病、解决气候和能源问题并丰富我们的生活,AGI 大概需要 10 年时间,因为还需要 2 到 3 项重大创新,下一项就是基于代理的系统。
谷歌 DeepMind CEO Demis Hassabis 最近在《泰晤士报》和《泰晤士报商业版》的主办的科技峰会上发表演讲,Hassabis 回顾了 DeepMind 的创立,谈了 AGI、AlphaFold 和 AI 的未来。

照例先给大家划个重点(访谈全文附在文后):
Demis Hassabis 看见了什么? Hassabis 已经在游戏的微观世界中看到了一点,并且理解得很清楚:从一个随机的系统 AlphaZero 开始 8 小时就可以训练出超越最顶尖人类的国际象棋实体,虽然这只是游戏狭窄领域,但一定会扩展出世界模型。
DeepMind 的初心: Hassabis 30 年前就开始研究 AI 了!从游戏 AI 到神经科学,他一直坚信 AI 的潜力。2010 年,他创立 DeepMind,因为他看到了深度学习和强化学习的巨大潜力,以及 GPU 等硬件的快速发展。他想打造一个通用的、能自我学习的 AI 系统,这正是 DeepMind 的初心!
游戏 AI,AGI 的 “练兵场”: DeepMind 早期专注于游戏 AI,是因为游戏可以快速验证算法的有效性,而且容易进行基准测试。但他们的目标不仅仅是赢得游戏,而是开发通用的 AI 技术,并将其应用于其他领域,例如科学和商业。
AlphaFold:AI for Science 的典范: Hassabis 一直对用 AI 解决科学难题充满热情,而蛋白质折叠问题是他最想攻克的目标之一。AlphaFold 的成功(Hassabis 因 AlphaFold 获得 2024 诺贝尔化学奖),证明了 AI 在科学领域的巨大潜力!
多模态模型,AGI 的关键: Hassabis 认为,多模态模型是 AGI 系统的关键组成部分,例如 DeepMind 的 Gemini 模型,它可以处理文本、图像、音频、视频和代码等多种输入。
通往 AGI 的道路:更强大的 Agent: 现在的聊天机器人大多是被动的问答系统,而未来的 AI 系统需要更主动、更智能,能够像 AlphaGo 一样进行规划和推理,并在现实世界中采取行动。
AGI 时代,还有多远? Hassabis 预计,我们距离 AGI 还有大约 10 年的时间。
DeepMind 的未来: DeepMind 将继续以研究为导向,同时也会加大产品研发的投入,与谷歌的其他部门合作,将 AI 技术应用于更多产品和服务中
AGI 时代,人类将进入富足时代! Hassabis 认为,AGI 将彻底改变经济和社会,消除能源和资源的稀缺性,让人类进入一个物质极大丰富的时代。我们需要提前思考如何分配这些财富,例如,是否应该实行全民基本收入制度。
访谈全文:强烈推荐
注意:这是 Demis Hassabis10 月 1 日的访谈,此时距离 10 月 9 日他获得 2024 年诺贝尔化学奖还有几天时间,但是访谈视频今天才放出来。

主持人: 我想,在座的各位几乎都知道 DeepMind,也知道它现在在做什么。让我们先简单回顾一下您的故事,因为您在 2010 年左右创立了 DeepMind,而在此之前,人工智能经历了 40 年的寒冬,作为一名科学记者,我当时并没有关注人工智能。DeepMind 为何在那个时候出现?是有什么有利因素吗?
Demis Hassabis: 嗯,我研究人工智能实际上已经超过 30 年了,最初是做游戏,为游戏设计人工智能,以及模拟游戏。后来我学习了计算机科学和神经科学,并且一直在观察人工智能领域的发展。在您提到的 90 年代的人工智能寒冬时期,都是逻辑系统,也就是所谓的专家系统。你们很多人可能还记得深蓝在国际象棋比赛中击败了加里・卡斯帕罗夫(俄罗斯国际象棋棋手,国际象棋特级大师,前国际象棋世界冠军),这些都是预编程系统,实际上是程序员和系统设计者解决了问题,并将其封装成规则。计算机、人工智能系统实际上根本不智能,它只是在执行这些启发式方法。这样做的问题是,最终会得到脆弱的系统,它们无法学习新东西,当然也无法发现新东西,因为它们显然天生就受到设计者或程序员已知能力的限制。
所以对我来说,很明显,在整个 90 年代,我在剑桥和麻省理工学院学习期间,这仍然是主流观点,尤其是在那些地方,逻辑系统才是正道。我认为这就是出现很多人工智能寒冬的原因,因为它们天生就脆弱且局限。所以在 2010 年,DeepMind 的想法是,我们可以看到深度学习刚刚在学术界被发明出来
强化学习是我们发现的东西,大脑中的多巴胺系统,动物和包括人类在内都使用强化学习来学习。
因此,对我来说,显而易见的是,我们需要构建的是一个能够自学且通用的学习系统,这就是 DeepMind 的起源。然后我们也看到了 GPU 和硬件加速等技术的进步。所以我使用了第一代 GPU,它是用于计算机图形、计算机游戏的,但它们是非常通用的,事实证明,世界上的一切都是矩阵乘法。我们很早就开始了,我们觉得这就像一个阿波罗计划,需要付出巨大的努力才能将所有这些新奇的想法和成分整合在一起可以取得非常快的进展,结果也确实如此。
主持人: 这是您在普林斯顿时期预想的结果吗?您是否想过 15 年后,我会在这里与您对话,人工智能会成为热门话题,并且蛋白质折叠问题会被解决?
Demis Hassabis: 实际上,它大致沿着我们计划的路线发展,当然,过程中也有一些小插曲和意想不到的事情,但当我们在 2010 年开始时,我们认为要达到通用人工智能大约需要 20 年的时间。我认为我们可能距离这个目标还有 10 年左右的时间。从现在开始,大致是那个时间线,用人工智能系统进行科学研究,在通往人工智能的道路上解决科学问题一直是我的主要热情所在。蛋白质折叠一直是我最想解决的科学难题之一,如果我们能够取得突破,它将带来变革。
主持人: 好的,让我们回到这一点,我认为我们也应该谈谈人工智能,因为有趣的是,自从 ChatGPT 出现以来,我们作为一个社会一直在非常深入地讨论人工智能,它与您一直在做的人工智能是截然不同的,作为一名观察者,您的人工智能一直都非常具体,观察它有点奇怪,你知道,它开始做一些毫无意义的事情。它非常擅长电脑游戏。
Demis Hassabis: 我不会说它们毫无意义,但它们更多的是为了好玩,也许你可以这么说。我们从游戏入手,部分原因是我的游戏背景以及认真下棋等等。但我可以看到,游戏与人工智能一直有着悠久的历史。从图灵和香农在人工智能领域的早期开始,所有这些伟大的,他们都是从象棋程序开始的。几乎每个 AI 先驱都这样做过。而且,它一直是我们的试验场。你能用你的算法思想快速取得进展吗?然后很容易衡量你的水平,如果你能击败世界冠军或最好的计算机,那么你就知道你做得很好。但关键是,它们始终是达到目的的手段,而不是目的本身。所以我们的想法是:
不要仅仅为了击败围棋或国际象棋的冠军,而是要以一种能够推广到其他领域的方式来做到这一点,包括科学和商业应用。这就是我们用深度强化学习和 AlphaGo 所做的,所有这些都是非常通用的系统,我们至今仍在使用。
现在,当你谈到像 AlphaFold 或我们的科学程序,它们解决了蛋白质折叠等问题时,你真正感兴趣的是解决方案本身。如果你找到了治疗癌症的方法,你不会在乎它是如何做到的。你只想要治疗癌症的方法。所以你真的想全力以赴。所以你首先要做的就是把你所有的通用技术作为基线。然后你再看领域本身,如果这个领域对社会或商业足够有价值,那么你就在上面添加定制的东西。这就是你如何得到像 AlphaFold 这样的突破性程序。但最终,DeepMind 的目标,从我们创立之初到现在,仍然是实现通用人工智能,这意味着一个通用的系统,它能够开箱即用地完成任何你能完成的认知任务。完全通用,就像阿兰・图灵在 50 年代所定义的那样,能够计算任何可计算的东西。这是人工智能作为一个领域的最初目标,也是 DeepMind 的目标。
当然,你最近看到的是像这些语言模型之类的东西。实际上是 ChatGPT 进入了大众市场,进入了公众的视野。但实际上,所有顶级实验室,包括谷歌和 DeepMind,都在研究语言模型。我们有自己的内部模型,叫做 Chinchilla,谷歌也有他们的模型。当然,它们都是基于 Transformer 架构的,这是谷歌研究院发明的,所有当前的模型都是基于它的。所以这是一个激动人心的时刻,因为语言显然是一种通用能力。这就是为什么每个人都对聊天机器人感到非常兴奋的原因。而且非常有趣,而且有点出乎意料的是,这项技术能够扩展到如此程度。我认为我们比以往任何时候都更接近构建这些类型的通用系统。但目前你仍然需要专门的系统来在特定领域做到最高水平。
主持人: 大型语言模型更接近 AGI 吗?我的意思是,它感觉更像是在与人互动,而这感觉就像 AGI。但它真的是吗?
Demis Hassabis: 我认为,多模态,现在甚至不应该说是大型语言模型,因为它们不仅仅是大型语言模型。它们也是多模态的。例如,我们的 Gemini 模型从一开始就是多模态的。它们可以处理任何输入。视觉、音频、视频、代码,所有这些东西,以及文本。所以我认为我的观点是,这将成为 AGI 系统的一个关键组成部分,但可能仅凭它本身还不够。
我认为从现在到我们实现 AGI,还需要两到三个重大创新。这就是为什么我给出的时间表是超过 10 年的原因。其他人,我的一些同事和同行,以及我们的一些竞争对手,他们的时间表比这要短得多。但我认为 10 年左右是比较合适的。
主持人: 这与 DeepMind 内部的,我猜是内部的紧张关系是如何协调的呢?因为我感觉,尤其是在早期,你们就像世界上资金最雄厚的大学实验室之一。就像贝尔实验室之类,一个伟大的商业研究机构。但现在你们正在做一些非常有用的事情,你们有一系列的,我的意思是,你提到了蛋白质折叠,但你们还有天气预报。你们刚刚在国际数学奥林匹克竞赛中获得了一枚奖牌。对不起,我相信如果你自己去参加的话,你也能获得金牌,但你们的系统获得了一枚银牌。你们正在做所有这些其他的事情。你们在背后也在做吗?你们有团队在思考吗?但是现在我们需要继续前进,制造 AGI?
Demis Hassabis: 是的,我们有一个很大的组织。正如你所说,我们最初的 DeepMind 模式有点像贝尔实验室,它是世界上最好的工业实验室之一,能够发明未来,能够长远思考。我们真正展示了这种模式能够做什么。我认为它在为我们今天看到的各种技术奠定基础方面非常有效。所以我认为任何类型的深度技术初创公司都需要时间来发展其成熟的技术。
在过去的两三年里,我们已经到了一个非常激动人心的时刻,这项技术已经相当成熟。它已经准备好应用于各种领域。很明显,有科学、数学、医学,以及所有这些领域的进步。可以算是应用科学。如果你愿意,但也有生产力和商业应用,比如聊天机器人或重新构想工作流程和电子邮件等等,这还处于萌芽阶段,以及帮助编码等等。我们显然也致力于所有这些工作,我们是谷歌的引擎。谷歌拥有令人难以置信的,我想是 150 亿用户,以及平台和产品,而人工智能是所有这些的核心,新的功能不断涌现,来自我们 DeepMind 开发的一些技术。
这在某种程度上是很好的,因为产品所需的技术类型实际上与你无论如何都会进行的 AGI 研究类型有 90% 的相似之处。这些东西已经有很多融合了,而在五年前或十年前,如果你想将人工智能融入产品中,你必须这样做,因为通用系统和学习系统还不够好,你必须回到逻辑网络,专家系统。像早期那一代的助手,例如,都仍然建立在那种旧的技术之上,这就是为什么它们很脆弱,它们不能泛化,最终它们也没那么有用,而建立在这些学习系统上的新一代助手将更加强大。而且,实际上,非常令人兴奋,我实际上认为像 Gemini 以及我们自己对未来多模式助手的设想,目前称为 Astra,它们是通往 AGI 系统的关键路径,因为它们实际上推动了朝着这个方向的研究。
Demis Hassabis: 这只是一个能够在日常生活中帮助你的通用助手的开始。我听到要把它做成员工。也会有不同的形式。你可以在手机上看到它,你可以在眼镜上看到它。我无法形容这会有多么神奇。如果我们回到五年前,你告诉我我们会走到今天这一步,你只需用相机指向某个东西,它就能完全理解空间环境。这真是太不可思议了。就好像它有概念,它理解什么是物体,甚至能认出我们所在的街区。仅仅是通过窗户看到的周围景色。像记住你把东西放在哪里的记忆,这可能非常有用,就像一个助手一样。个性化和所有这些东西都在这个我称之为下一代助手的产品中出现。我称之为通用助手,因为我想象你把它随身携带在不同的设备上。它是同一个助手,无论它是和你玩游戏,还是在你的桌面上帮助你工作,或者是在移动设备上陪你旅行。
主持人: 是这样吗?我认为我理解对了。有些人会认为这是通往通用智能的一步。如果没有我们还没有的秘密武器,那么它本质上就是这个目标。它与我们目前使用的方法之间没有无法弥合的差距。它只是你达到了 70%,你达到了 80%,你达到了 90% 吗?还是有什么其他的东西需要解决?
Demis Hassabis: 嗯,我们肯定需要这些系统,我相信你们所有人都已经体验过各种最先进的聊天机器人了。这些系统非常被动,它们是问答系统。它们对于回答问题,也许做一些研究,总结一些文本之类的事情很有用。
我们接下来想要的是更多 基于代理的系统,能够完成你给它的特定目标或任务。这当然是我使用助手,数字助手需要做的。你计划一个假期,你在城市里旅行,你告诉它帮你订票。所以它们需要能够在世界上行动,执行动作并进行规划。所以我们需要 规划、推理、行动,我们需要更好的记忆,我们需要个性化,所以它需要了解你的喜好,记住你告诉它的内容和你喜欢的东西。所以所有这些技术都是需要的。
现在,我给出的简略说法是:
我们的一些游戏程序,比如击败了围棋世界冠军的 AlphaGo,它有规划和推理能力,尽管是在这个狭窄的游戏领域。我们必须引入这些技术,并将它们应用于像 Gemini 这样的多模态模型,它们基本上是世界模型,正如你刚才看到的,它理解它周围的世界。但是如何在杂乱的现实世界中进行规划,而不是像游戏这样的干净的环境呢?所以我认为这是下一个需要取得的重大突破。
主持人: 那这个系统也能应用 AlphaGo 级别的游戏和拉动某种方法吗?
Demis Hassabis: 是的,没错。有两种方式可以实现,这是我们内部以及学术界目前正在进行的非常有趣的辩论。你可以想象,你希望你的通用代理系统能够做的一件重要的事情就是 使用工具。这些工具可以是硬件,比如机器人或物理世界中的东西,但它们当然也可以是其他软件,比如计算器,诸如此类。但它们也可以是其他人工智能系统。所以你可以拥有,你可以想象一个像大脑一样的通用人工智能系统,然后调用像 AlphaFold 或 AlphaGo 这样的东西来下围棋或折叠蛋白质,或者因为它是全数字化的,你可以想象将这种能力折叠到通用大脑中,折叠到 Gemini 中。但这需要权衡取舍,因为这样你是否会用专门的信息超载它,比如太多的棋局,然后这会让它在语言方面变得更差。
这是一个开放的研究问题,你是想把它分离成一个工具,即使是一个通用人工智能可以在特定情况下使用的 AI 工具,还是你想把它上游到主系统中。有些东西你想上游到主系统中,比如编码和数学,因为事实证明,如果你把它放在主系统中,它实际上会让一切变得更好。所以有点像你在学习理论和儿童发展理论等等,实际上是为了思考哪些东西可能是通用的,并且最好放在主系统中而不是外围工具中
主持人: 你现在组织还有多少比例是一个科学组织?你还有多少比例在努力成为贝尔实验室?
Demis Hassabis: 我们永远都会是一个以研究为主导的组织。这就是我们现在在 Google DeepMind 所做的。但我们越来越多地拥有一个越来越大的产品应用团队,与谷歌的其他部门进行互动。但我们仍然试图让我们的基础研究稍微不受其影响,这样它就可以根据我们自己的研究路线图进行更长远的、更具蓝天意义的思考,而不仅仅是由产品路线图所主导。
主持人: 您个人是如何跟上这一切的呢?
Demis Hassabis: 嗯,我努力,我的意思是,我曾经在 18 个月前说过,我会保留我的晚上时间,而且我是一个很自律的人。所以我把午夜到凌晨 3 点的时间留给思考、阅读论文和提出想法,我仍然在伦敦。但现在我在加州有很多团队。所以很多黄金思考时间都被与美国的电话会议占据了。想想如何腾出这些时间。
主持人: 我们可以把计时器放在这里吗,如果可以的话。否则,我们会让你错过你的饮料,而且我不确定我们还有多少时间。未来会怎样?我认为你是其中的一员,你是签署了其中一封公开信的人之一,警告说,你知道,真正的生存风险,但这并没有特别明确的定义。你对 希望、炒作和末日持什么立场?
Demis Hassabis: 我认为这个等式的两边都有很多疯狂的炒作。有一种现在被称为末日阵营的人,他们认为肯定会出错。然后还有那些波莉安娜阵营的人,他们认为这只是另一种技术,以前在移动互联网时代就见过这种情况,它会像那样发展壮大,但是我们作为一个社会和作为人类适应性很强,没什么特别的。。
显然这是错的。我认为,这比互联网或移动设备之类的东西要重要得多。我认为这是一个划时代的定义。我一直这样认为,我想对更多人来说,这一点正变得越来越清晰,但我从我还是个孩子的时候就一直这样认为,这就是为什么我毕生致力于此的原因。
我认为它可以做到。它将产生难以置信的影响。当然,我做这一切的原因是因为我认为人工智能对世界将产生难以置信的积极影响。我认为我们距离用人工智能治愈所有疾病的目标已经不远了,通过材料科学和新能源以及我认为人工智能可以发明的其他东西来帮助应对气候变化,以及在我们的日常生活中,只是提高生产力,丰富我们的日常生活,平凡的管理工作。我认为,平凡的管理工作可以自动处理。我认为这些都很棒,而且很快就会实现。
但是这些系统存在风险,它们是新技术的新系统,它们非常强大。
我已经在游戏的微观世界中看到了这一点,我理解得很清楚,比如下棋,你从一个随机的系统 AlphaZero 开始,到了早上喝咖啡休息的时候,它可以打败我,然后到了午餐时间,它已经比世界冠军更厉害了,然后到了下午,在大约 8 个小时内,它就比最好的国际象棋,高端的、硬编码的国际象棋计算机更厉害了。
所以它是世界上有史以来最伟大的国际象棋实体,在 8 个小时内从随机变成了这样。我实际上观察了这个过程超过 8 个小时,这真是太不可思议了,当然,那只是一个游戏,而且范围很窄。
但我认为没有理由认为这种能力不能推广到这些更通用的语言和世界模型系统中。所以它将非常强大,但必须谨慎处理。而且我认为我们根本不知道。所以我签署那封信的原因是我只是想给那些认为这里没什么可看的,实际上有一些未知风险的波莉安娜主义者一些压力。
我们需要定义,我认为我们有时间,但十年时间对于即将到来的如此重大的事情来说并不长。所以我们需要对可控性等方面进行更多研究,从理论层面理解这些系统的作用。你知道,非常重要的事情,比如我们如何为系统定义目标和价值观,以及我们如何确保它们坚持这些目标和价值观。这些都是当前新兴技术的未知数。所以我想说我是一个谨慎的乐观主义者。所以我认为如果我们齐心协力,我们就能解决这个问题。我们在国际范围内这样做,让所有最优秀的人才都参与进来。我们现在就开始行动。我很高兴看到在英国和美国成立的人工智能安全研究所,我们将倡导这种情况的发生,并测试最新的模型。但我们需要更多这样的机构。我只是在鼓励这种情况的发生。而且我认为,如果有足够的时间,有足够的脑力,人类的聪明才智,我们会做好的。但风险是存在的,我们不能抄近路,我们需要认真对待它。我认为应该怀着敬畏之心。我认为这项技术值得我们去努力。
主持人: 你所说的有点吓人。我的意思是,如果你从国际象棋中发生的事情进行概括,国际象棋还好。但假设我每天去办公室工作,靠下棋谋生,不是靠打败其他人,而是因为它对下棋有一些功利价值。你所说的系统可能会消除几乎所有的人类价值。
Demis Hassabis: 我认为即将出现一些重要的 哲学讨论。它们很快就会出现。我们如何分配?我们应该生活在一个 AGI 运作的零和世界中。所以激进的富足。像能源之类的东西不应该短缺,因此资源和其他东西也不应该短缺。我认为这确实改变了经济的动态,我指的是长远来看。所以我们现在需要开始思考这个问题,为它做好准备。我们希望如何分配这些额外的富足和财富。无论是某种普遍基本供应还是其他类似的东西。我们需要现在就开始思考这个问题,经济学家和像他们这样的人。我觉得他们需要现在就开始研究这个问题。
主持人: 最后一个问题英国。我们在英国,美国正走向人工智能的中心。我们正在讨论英国是否需要更多计算能力,政府是否需要支持它。这是必需的吗?我们有哪些可能会落后的方面?
Demis Hassabis: 我认为这是一个巨大的增长领域,我认为英国政府应该鼓励它。我想说的是,更重要的是鼓励国内投资,地方投资,规划许可等等。我认为这是一个建立新世界的绝佳机会。我认为这是一个巨大的机遇。许多大公司都认为英国是一个吸引人的研究和开展业务的地方。我们在这里有一个很棒的生态系统。我们拥有一流的大学。这就是我们 DeepMind 在这里的原因之一。我们在这里有助于建立一个由英国优秀初创公司组成的生态系统,这些公司基于人工智能或与人工智能相邻。所以我认为政府只需要释放这种潜力,让公司很容易在这里投资和建设,包括大型数据中心。
- 完
杨立昆:AI 很像一个「盲人摸象」的故事
学术头条 2024年12月07日 07:17 北京

近年来,人工智能(AI)大模型在文字、图像、视频等领域展现了强大性能。然而,它们是否能够持续学习进而理解物理世界,实现人类级智能,仍然是一个亟待解答的问题。
日前,图灵奖得主、Meta 首席科学家 Yann LeCun(杨立昆)接受了印度企业家、投资者 Nikhil Kamath 的专访。
在访谈中,Yann LeCun 谈到了他对于 AI 的独特理解,并介绍了自监督学习、transformer、卷积神经网络等。他还详述了大语言模型(LLM)在理解物理世界和实现持久记忆方面的挑战以及可能的解决方法,并对 AI 的未来做了预测。
他乐观地认为,目前人类距离通用人工智能(AGI)并不遥远,“我不认为我对于离 AGI 还有多远的看法,与你从 Sam Altman 或 Demis Hassabis 那里听到的非常不同。你知道的,很可能在十年内,但不会在明年或近两年发生。”
学术头条在不改变原文大意的情况下,对部分访谈内容做了精编。内容如下:
Nikhil Kamath:我们很多人都听说过围绕 AI 的猜想,既有积极的一面,也有消极的一面。今天,我们希望可以清楚地理解 AI 对于所有人来说究竟是什么,我们是如何到达这一步的,以及未来会怎样。
我们先从什么是 AI 开始。
Yann LeCun:好的,这是一个好问题。甚至我们还要问,什么是智能(intelligence)。**在 AI 的历史上,我认为什么是 AI 的问题有点像是盲人摸象的故事。**智能有非常不同的方面,纵观 AI 的历史,人们对什么是智能提出了一种观点,并基本上忽略了所有其他方面。
20 世纪 50 年代,人们认为智能就是推理,那么我们应该如何进行逻辑推理呢?如何寻找新问题的解决方案呢?
人们当时发现,当我们遇到问题时,可以将其形式化为一个特定的数学问题。例如,一个经典的问题是旅行推销员问题(Traveling Salesman Problem):给定一堆城市,如何设计出经过每个城市的最短路径?这种问题可以看作一种优化问题。优化的本质是寻找一个问题的解决方案,通过一个数值(比如路径长度)来衡量解决方案的好坏,数值越小,解决方案越好。
Nikhil Kamath:那么,寻找解决方案与智能有关吗?如果你问我什么是智能并用一句话定义,我会感到目瞪口呆。
Yann LeCun:是的,正确的。这实际上又回到了大象的例子。
Nikhil Kamath:能解释一下这个大象的例子吗?
Yann LeCun:好吧,你肯定知道盲人摸象的故事。第一个盲人走到大象身边说,这摸起来像堵墙。第二个盲人走到大象腿旁边说,这摸起来像棵树。第三个盲人摸到了大象的鼻子,说这是根管子。没有人能完整地了解大象是什么,你会从不同的角度看到它。
因此,**智能的一个角度就是寻找解决方案。**但你知道,寻找特定问题的解决方案只是“大象”的一小部分,只是智能的一个方面,不是全部。
但从 20 世纪 50 年代至 20 世纪 90 年代,当时占据主导地位的 AI 分支基本上只关注到这一点,认为 AI 就是寻找问题的解决方案,就是去“规划”。例如,将一堆大小不一的物体堆叠起来,需要规划堆叠的顺序;或者控制机器人手臂抓取一个物体时,需要规划避开障碍物的路径。这些都属于“规划”问题的范畴。
然而,这一分支完全忽略了感知问题,例如怎样理解世界、识别物体或将物体从背景中分离出来。这些问题在当时并未被重视。
Nikhil Kamath:是的。
Yann LeCun:与此同时,还有另一个 AI 分支也始于 50 年代**。这一分支试图重现人类和动物的智能机制**。动物和人类的大脑通过连接的神经元网络进行自我组织和学习。智力并非自发生成,而是从大量简单元素的网络中涌现而出。
20 世纪 40 到 50 年代,人们开始认识到,智力和记忆来自神经元之间连接强度的变化。大脑通过调整神经元之间的连接强度来学习。科学家基于此提出了理论模型,并设计了能够模拟这种行为的电子电路,试图以此重现智力的机制。你知道,我们可以建立。
Nikhil Kamath:所以,你是说,智能主要是解决某个问题的能力?
Yann LeCun:是的,这是我们刚刚提到的第一个观点,第二个是学习能力。这就是 AI 的两个分支。
Nikhil Kamath:好的。
Yann LeCun:所以,关注学习能力的分支在 20 世纪 50 年代末、60 年代初取得了一些成果。但在 60 年代末消亡了,因为事实证明,那些在 60 年代设计的神经网络的能力是极其有限的,不能用于生产真正的智能机器。但它对工程的各个部分都产生了影响,例如产生一个称为模式识别的工程领域。
Nikhil Kamath:嗯,所以你现在说的智能也是系统学习的能力?
Yann LeCun:学习,是的,你需要机器学习来感知,解读图像、声音、语音。
Nikhil Kamath:那么,如果我们需要画一棵 AI 树,AI 是在最上面的,其下是机器学习,机器学习有三种类别,其下是不同的神经网络,再下面是强化工具,比如深度学习,之后是 LLM,这是现在最流行的。
Yann LeCun:是的,正确的结构是顶部是 AI,之后机器学习是解决 AI 问题的一种特殊方法。深度学习,它确实是当今 AI 的基础,然后,神经网络有很多层,这仍然是我们所做一切的基础。再此之下,有几个架构系列,卷积网络、transformer 及其组合,再然后,在 transformer 下面会放置图像或音频识别、自然语言表示这些功能。
然后还有一个子类别,LLM,它们是自回归 transformer。Transformer 有特殊的架构使它们能预测下一个 token,所以能被用来生成 token。这就是自回归预测。
Nikhil Kamath:而且它最适合文本,但不适用于图片、视频或任何其他内容?
Yann LeCun:是的。LLM 适用于文本而不适用于其他事,是因为文本是离散的,因此可能发生的事情是有限的,但如果你想预测视频中会发生什么,可能的帧数之类,本质上是无限的。就比如说,一幅图像,1000*1000 像素,像素又是有颜色的,有三个值,这说明必须要生成 300 万个值。我们不知道怎样用概率分布去表示超过 300 万像素的所有可能图像的集合。
Nikhil Kamath:但这正是大家所关注的事情。
Yann LeCun:这是我们很多人认为 AI 的下一个挑战。基本上,你有一个可以通过观看视频了解世界如何运作的系统。
Nikhil Kamath:如果你要说从视频和图片中学习,这将是下一个阶段,这一阶段会在 LLM 的当前位置吗?
Yann LeCun:不,它与 LLM 截然不同,我一直直言不讳地说 LLM 不是通往人类级智能的道路。LLM 适用于离散世界,它们不适用于连续的高维世界,视频就是这种情况。
这就是为什么 LLM 不了解物理世界。尽管 LLM 在语言方面的功能是惊人的,但它们可能会犯非常愚蠢的错误,这表明它们不了解世界是如何运作的,不了解底层世界。所以我一直地说,最聪明的 LLM 都不如你家里的猫聪明,这是事实。
那么,未来几年的挑战,是建立解除 LLM 限制的 AI 系统。建立能够理解物理世界,有持久记忆的系统。
Nikhil Kamath:持久记忆?
Yann LeCun:是的,持久记忆意味着它们可以记住任何事情,将事实存储在内存中,然后在需要的时候检索。
Nikhil Kamath:LLM 现在记不住东西吗?
Yann LeCun:LLM 有两种类型的内存。第一种类型在参数中,在训练期间调整的系数中,它们在这一过程中会学到一些东西,但这并不是真正存储一条信息。如果你在一堆小说上训练 LLM,它无法反驳小说,但它会记住一些关于那本小说中单词的统计数据,它也许能回答问题,关于故事和类似事情的一般问题,但它无法复述所有单词。
Nikhil Kamath:这有点像人类,对吧?
Yann LeCun:你读一本小说,你不可能记住所有单词,除非你花费很多精力,这就是第一种记忆。上下文是第二种记忆。你输入提示(prompt)。
并且由于系统能够生成单词,这些单词或 tokens 被注入到输入中,可以用作某种工作记忆,但这是一种非常有限的记忆形式。你真正需要的是一种更接近于人类大脑海马体功能的记忆。哺乳动物有一种叫海马体的东西,是大脑中心的一个结构。如果你没有海马体,你将无法记住超过 90 秒的事情。
Nikhil Kamath:所以如果 AI 可以预测未来,这是乌托邦还是反乌托邦?
Yann LeCun:这将是乌托邦。因为除了我们的大脑之外,还有一种预测未来的方法,通过规划动作序列以满足特定条件来实现目标,这也许需要积累很多的知识才能够做到这一点,也许拥有人类不具备的能力,因为人脑有局限而计算机能够有计算之类的能力。
所以,如果这个计划在未来取得成功,可能五年到十年内,我们可以让 AI 达到人类水平的智能。这可能是乐观的,对吧?
Nikhil Kamath:像通用人工智能(AGI)和人类级智能,你认为很遥远或者不太可能?
Yann LeCun:不,我不认为这些是遥远的。我不认为我对于离 AGI 还有多远的看法与你从 Sam Altman 或 Demis Hassabis 那听到的非常不同。很可能在十年内,但这不会在明年或近两年发生。它需要更久的时间。
而且,如果只是扩大 LLM 规模、使用更大的计算机和更多的数据来训练它们,这样的方法是行不通的。我们必须要拥有那些新的架构,那些 JEPAs(世界模型架构),以及能从现实世界中学习、可以分层规划的系统。而不是不加思索一个接一个产生单词。所以,要系统 2,而不是系统 1。LLM 是系统 1,我所描述的架构,我称之为“目标驱动 AI”,是系统 2。
Nikhil Kamath:今天我们试图定义什么是智能。我是这样写的:智能是信息的集合以及吸收新技能的能力。
Yann LeCun:智能是技能的集合,以及快速学习新技能的能力。或者无需学习即可解决问题的能力。**这在 AI 领域被称为 zero-shot。将三者结合就是所说的智能。
Nikhil Kamath:非常感谢你,Yann,感谢你所做的一切。
Yann LeCun:谢谢。
访谈链接:
https://www.youtube.com/watch?v=JAgHUDhaTU0&t=316s
整理:阮文韵
via:
-
LLMs are a dead end to AGI, says François Chollet - Big Think
-
The next wave of AI won’t be driven by LLMs. Here’s what investors should focus on | Fortune
https://fortune.com/2024/10/18/next-wave-ai-llms-investor-focus-tech/?abc123
-
AI pioneer LeCun to next-gen AI builders: ‘Don’t focus on LLMs’ – Every Intel
https://everyintel.ai/ai-pioneer-lecun-to-next-gen-ai-builders-dont-focus-on-llms/
-
Yann LeCun’s big bet for building intelligent machines | MIT Technology Review
-
The Limits of Large Language Models: A Path Forward to Artificial General Intelligence | LLM Reporter
-
Yann LeCun 最新万字演讲:致力于下一代 AI 系统,我们基本上不做 LLM 了 AI 寒武纪 2024 年 10 月 16 日 12:49 江苏
-
诺奖得主 DeepMind CEO 最新万字访谈:视 AI 为普通技术错误,AGI 还差 2 到 3 项重大创新 AI 寒武纪 2024 年 10 月 18 日 10:31 江苏
-
杨立昆:AI 很像一个「盲人摸象」的故事 学术头条 2024年12月07日 07:17 北京
https://mp.weixin.qq.com/s/C-qyl_gieI7m5oLz98XBFA


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









