







注: 本文为 “Linux 进程” 相关文章合辑。
略作重排,未整理去重。
Linux 进程概念(精讲)
A little strawberry 于 2021-10-15 10:23:55 发布
基本概念
课本概念:程序的一个执行实例,正在执行的程序等。
内核观点:担当分配系统资源(CPU 时间,内存)的实体。
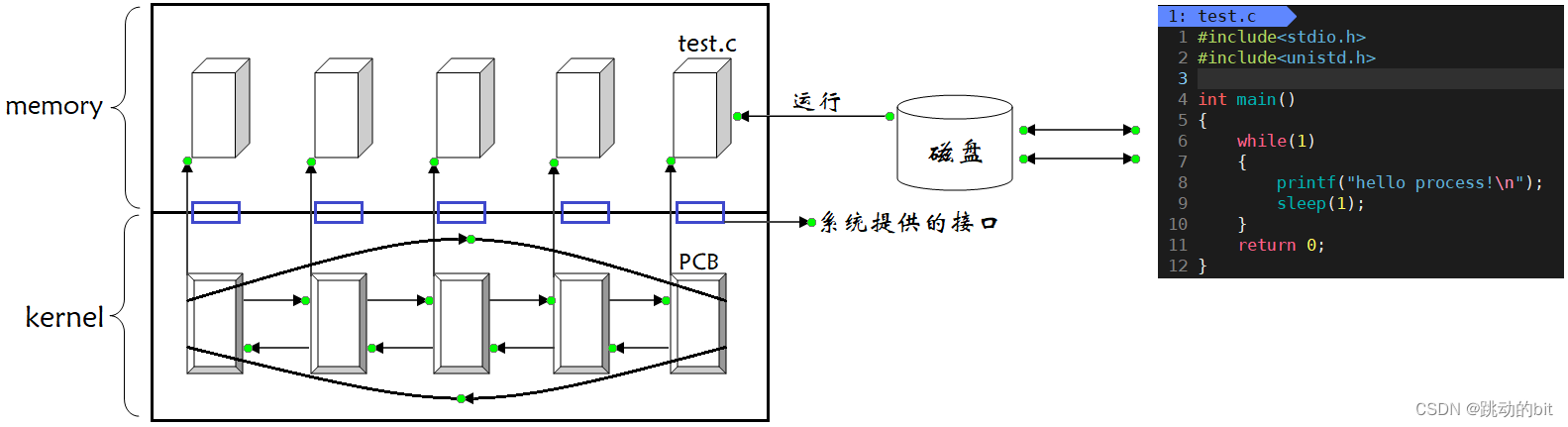
只要写过代码的都知道,当代码进行编译链接后便会生成一个可执行程序,这个可执行程序本质上是一个文件,是放在磁盘上的。当我们双击这个可执行程序将其运行起来时,本质上是将这个程序加载到内存当中,因为只有加载到内存后,CPU 才能对其进行逐行语句执行,而一旦将这个程序加载到内存后,我们就不应该将这个程序再叫做程序了,严格意义上应该将其称之为进程。

描述进程 - PCB
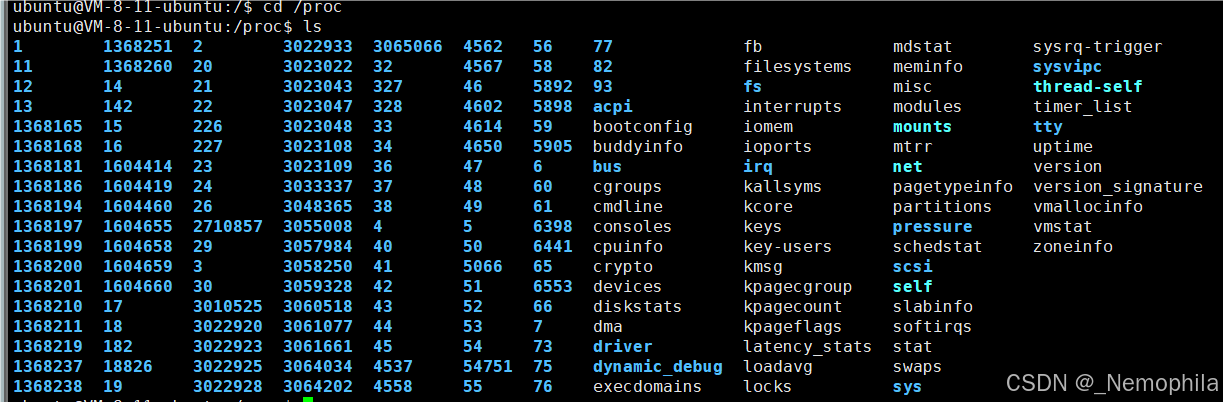
系统当中可以同时存在大量进程,使用命令 ps aux 便可以显示系统当中存在的进程。

而当你开机的时候启动的第一个程序就是我们的操作系统(即操作系统是第一个加载到内存的),我们都知道操作系统是做管理工作的,而其中就包括了进程管理。而系统内是存在大量进程的,那么操作系统是如何对进程进行管理的呢?
这时我们就应该想到管理的六字真言:先描述,再组织。操作系统管理进程也是一样的,操作系统作为管理者是不需要直接和被管理者(进程)直接进行沟通的,当一个进程出现时,操作系统就立马对其进行描述,之后对该进程的管理实际上就是对其描述信息的管理。
进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合,课本上称之为 PCB(process control block)。
操作系统将每一个进程都进行描述,形成了一个个的进程控制块(PCB),并将这些 PCB 以双链表的形式组织起来。

这样一来,操作系统只要拿到这个双链表的头指针,便可以访问到所有的 PCB。此后,操作系统对各个进程的管理就变成了对这条双链表的一系列操作。
例如创建一个进程实际上就是先将该进程的代码和数据加载到内存,紧接着操作系统对该进程进行描述形成对应的 PCB,并将这个 PCB 插入到该双链表当中。而退出一个进程实际上就是先将该进程的 PCB 从该双链表当中删除,然后操作系统再将内存当中属于该进程的代码和数据进行释放或是置为无效。
总的来说,操作系统对进程的管理实际上就变成了对该双链表的增、删、查、改等操作。
task_struct - PCB 的一种
进程控制块(PCB)是描述进程的,在 C++ 当中我们称之为面向对象,而在 C 语言当中我们称之为结构体,既然 Linux 操作系统是用 C 语言进行编写的,那么 Linux 当中的进程控制块必定是用结构体来实现的。
-
PCB 实际上是对进程控制块的统称,在 Linux 中描述进程的结构体叫做 task_struct。
-
task_struct 是 Linux 内核的一种数据结构,它会被装载到 RAM(内存)里并且包含进程的信息。
task_struct 内容分类
task_struct 就是 Linux 当中的进程控制块,task_struct 当中主要包含以下信息:
-
标示符:描述本进程的唯一标示符,用来区别其他进程。
-
状态:任务状态,退出代码,退出信号等。
-
优先级:相对于其他进程的优先级。
-
程序计数器 (pc):程序中即将被执行的下一条指令的地址。
-
内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
-
上下文数据:进程执行时处理器的寄存器中的数据。
-
I/O 状态信息:包括显示的 I/O 请求,分配给进程的 I/O 设备和被进程使用的文件列表。
-
记账信息:可能包括处理器时间总和,使用的时钟总和,时间限制,记账号等。
-
其他信息。
查看进程
通过系统目录查看
在根目录下有一个名为 proc 的系统文件夹。

文件夹当中包含大量进程信息,其中有些子目录的目录名为数字。

这些数字其实是某一进程的 PID,对应文件夹当中记录着对应进程的各种信息。我们若想查看 PID 为 1 的进程的进程信息,则查看名字为 1 的文件夹即可。

通过 ps 命令查看
单独使用 ps 命令,会显示所有进程信息。
[cl@VM-0-15-centos dir2]$ ps aux
1

ps 命令与 grep 命令搭配使用,即可只显示某一进程的信息。
[cl@VM-0-15-centos dir2]$ ps aux | head -1 && ps aux | grep proc | grep -v grep
1

通过系统调用获取进程的 PID 和 PPID
通过使用系统调用函数,getpid 和 getppid 即可分别获取进程的 PID 和 PPID。
我们可以通过一段代码来进行测试。

当运行该代码生成的可执行程序后,便可循环打印该进程的 PID 和 PPID。

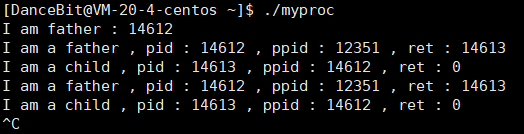
我们可以通过 ps 命令查看该进程的信息,即可发现通过 ps 命令得到的进程的 PID 和 PPID 与使用系统调用函数 getpid 和 getppid 所获取的值相同。

通过系统调用创建进程 - fork 初始
fork 函数创建子进程
fork 是一个系统调用级别的函数,其功能就是创建一个子进程。
例如,运行以下代码:

若是代码当中没有 fork 函数,我们都知道代码的运行结果就是循环打印该进程的 PID 和 PPID。而加入了 fork 函数后,代码运行结果如下:

运行结果是循环打印两行数据,第一行数据是该进程的 PID 和 PPID,第二行数据是代码中 fork 函数创建的子进程的 PID 和 PPID。我们可以发现 fork 函数创建的进程的 PPID 就是 proc 进程的 PID,也就是说 proc 进程与 fork 函数创建的进程之间是父子关系。
每出现一个进程,操作系统就会为其创建 PCB,fork 函数创建的进程也不例外。

我们知道加载到内存当中的代码和数据是属于父进程的,那么 fork 函数创建的子进程的代码和数据又从何而来呢?
我们看看以下代码的运行结果:

运行结果:

实际上,使用 fork 函数创建子进程,在 fork 函数被调用之前的代码被父进程执行,而 fork 函数之后的代码,则默认情况下父子进程都可以执行。需要注意的是,父子进程虽然代码共享,但是父子进程的数据各自开辟空间(采用写时拷贝)。
小贴士:使用 fork 函数创建子进程后就有了两个进程,这两个进程被操作系统调度的顺序是不确定的,这取决于操作系统调度算法的具体实现。
使用 if 进行分流
上面说到,fork 函数创建出来的子进程与其父进程共同使用一份代码,但我们如果真的让父子进程做相同的事情,那么创建子进程就没有什么意义了。
实际上,在 fork 之后我们通常使用 if 语句进行分流,即让父进程和子进程做不同的事。
fork 函数的返回值:
-
如果子进程创建成功,在父进程中返回子进程的 PID,而在子进程中返回 0。
-
如果子进程创建失败,则在父进程中返回 -1。
既然父进程和子进程获取到 fork 函数的返回值不同,那么我们就可以据此来让父子进程执行不同的代码,从而做不同的事。
例如,以下代码:

fork 创建出子进程后,子进程会进入到 if 语句的循环打印当中,而父进程会进入到 else if 语句的循环打印当中。

Linux 进程状态
一个进程从创建而产生至撤销而消亡的整个生命期间,有时占有处理器执行,有时虽可运行但分不到处理器,有时虽有空闲处理器但因等待某个时间的发生而无法执行,这一切都说明进程和程序不相同,进程是活动的且有状态变化的,于是就有了进程状态这一概念。

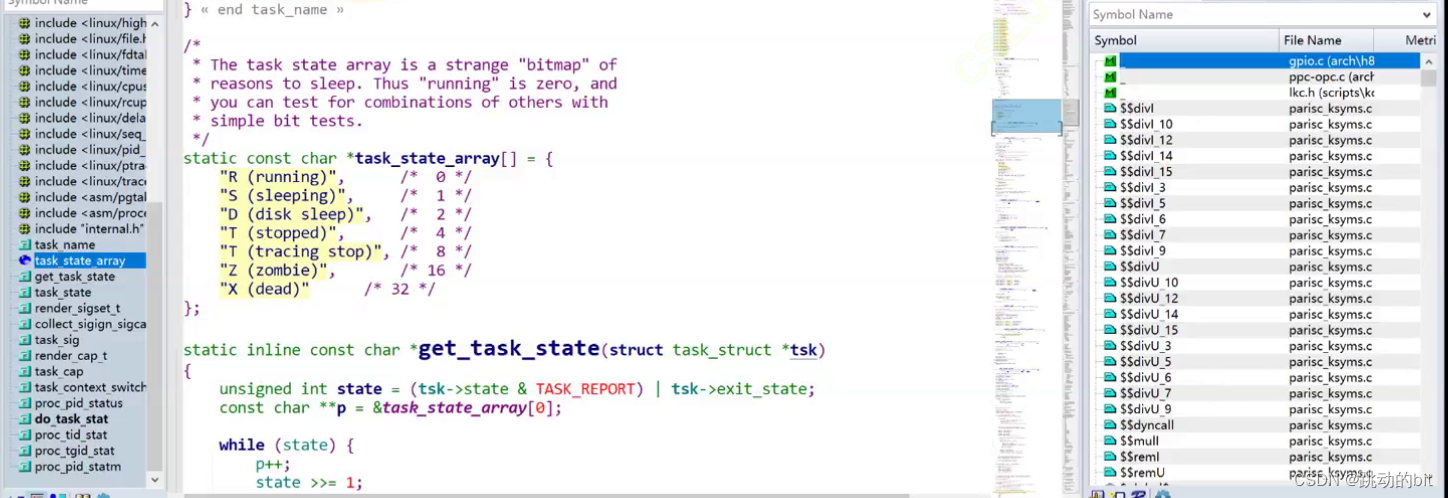
这里我们具体谈一下 Linux 操作系统中的进程状态,Linux 操作系统的源代码当中对于进程状态有如下定义:
/*
* The task state array is a strange "bitmap" of
* reasons to sleep. Thus "running" is zero, and
* you can test for combinations of others with
* simple bit tests.
*/
static const char *task_state_array [] = {
"R (running)", /* 0*/
"S (sleeping)", /* 1*/
"D (disk sleep)", /* 2*/
"T (stopped)", /* 4*/
"T (tracing stop)", /* 8*/
"Z (zombie)", /* 16*/
"X (dead)" /* 32*/
};
123456789101112131415
小贴士:进程的当前状态是保存到自己的进程控制块(PCB)当中的,在 Linux 操作系统当中也就是保存在 task_struct 当中的。
在 Linux 操作系统当中我们可以通过 ps aux 或 ps axj 命令查看进程的状态。
[cl@VM-0-15-centos ~]$ ps aux
1

[cl@VM-0-15-centos ~]$ ps axj
1

运行状态 - R
一个进程处于运行状态(running),并不意味着进程一定处于运行当中,运行状态表明一个进程要么在运行中,要么在运行队列里。也就是说,可以同时存在多个 R 状态的进程。
小贴士:所有处于运行状态,即可被调度的进程,都被放到运行队列当中,当操作系统需要切换进程运行时,就直接在运行队列中选取进程运行。
浅度睡眠状态 - S
一个进程处于浅度睡眠状态(sleeping),意味着该进程正在等待某件事情的完成,处于浅度睡眠状态的进程随时可以被唤醒,也可以被杀掉(这里的睡眠有时候也可叫做可中断睡眠(interruptible sleep))。
例如执行以下代码:

代码当中调用 sleep 函数进行休眠 100 秒,在这期间我们若是查看该进程的状态,则会看到该进程处于浅度睡眠状态。
[cl@VM-0-15-centos stat]$ ps aux | head -1 && ps aux | grep proc | grep -v grep
1

而处于浅度睡眠状态的进程是可以被杀掉的,我们可以使用 kill 命令将该进程杀掉。

深度睡眠状态 - D
一个进程处于深度睡眠状态(disk sleep),表示该进程不会被杀掉,即便是操作系统也不行,只有该进程自动唤醒才可以恢复。该状态有时候也叫不可中断睡眠状态(uninterruptible sleep),处于这个状态的进程通常会等待 IO 的结束。
例如,某一进程要求对磁盘进行写入操作,那么在磁盘进行写入期间,该进程就处于深度睡眠状态,是不会被杀掉的,因为该进程需要等待磁盘的回复(是否写入成功)以做出相应的应答。(磁盘休眠状态)
暂停状态 - T
在 Linux 当中,我们可以通过发送 SIGSTOP 信号使进程进入暂停状态(stopped),发送 SIGCONT 信号可以让处于暂停状态的进程继续运行。
例如,我们对一个进程发送 SIGSTOP 信号,该进程就进入到了暂停状态。

我们再对该进程发送 SIGCONT 信号,该进程就继续运行了。

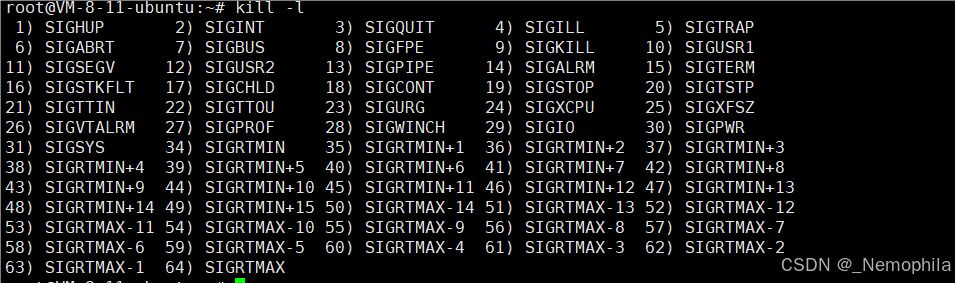
小贴士:使用 kill 命令可以列出当前系统所支持的信号集。
[cl@VM-0-15-centos stat]$ kill -l

僵尸状态 - Z
当一个进程将要退出的时候,在系统层面,该进程曾经申请的资源并不是立即被释放,而是要暂时存储一段时间,以供操作系统或是其父进程进行读取,如果退出信息一直未被读取,则相关数据就不会被释放掉,一个进程若是正在等待其退出信息被读取,那么我们称该进程处于僵尸状态(zombie)。
首先,僵尸状态的存在是必要的,因为进程被创建的目的就是完成某项任务,那么当任务完成的时候,调用方是应该知道任务的完成情况的,所以必须存在僵尸状态,使得调用方得知任务的完成情况,以便进行相应的后续操作。
例如,我们写代码时都在主函数最后返回 0。

实际上这个 0 就是返回给操作系统的,告诉操作系统代码顺利执行结束。在 Linux 操作系统当中,我们可以通过使用 echo $? 命令获取最近一次进程退出时的退出码。
[cl@VM-0-15-centos exitcode]$ echo $?

小贴士:进程退出的信息(例如退出码),是暂时被保存在其进程控制块当中的,在 Linux 操作系统中也就是保存在该进程的 task_struct 当中的。
死亡状态 - X
死亡状态只是一个返回状态,当一个进程的退出信息被读取后,该进程所申请的资源就会立即被释放,该进程也就不存在了,所以你不会在任务列表当中看到死亡状态(dead)。
僵尸进程
前面说到,一个进程若是正在等待其退出信息被读取,那么我们称该进程处于僵尸状态。而处于僵尸状态的进程,我们就称之为僵尸进程。
例如,对于以下代码,fork 函数创建的子进程在打印 5 次信息后会退出,而父进程会一直打印信息。也就是说,子进程退出了,父进程还在运行,但父进程没有读取子进程的退出信息,那么此时子进程就进入了僵尸状态。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main ()
{
printf ("I am running...\n");
pid_t id = fork ();
if (id == 0){ //child
int count = 5;
while (count){
printf ("I am child...PID:% d, PPID:% d, count:% d\n", getpid (), getppid (), count);
sleep (1);
count--;
}
printf ("child quit...\n");
exit (1);
}
else if (id > 0){ //father
while (1){
printf ("I am father...PID:% d, PPID:% d\n", getpid (), getppid ());
sleep (1);
}
}
else { //fork error
}
return 0;
}
观察代码运行结果,在父进程未退出时,子进程的 PPID 就是父进程的 PID,而当父进程退出后,子进程的 PPID 就变成了 1,即子进程被 1 号进程领养了。

僵尸进程的危害
-
僵尸进程的退出状态必须一直维持下去,因为它要告诉其父进程相应的退出信息。可是父进程一直不读取,那么子进程也就一直处于僵尸状态。
-
僵尸进程的退出信息被保存在 task_struct (PCB) 中,僵尸状态一直不退出,那么 PCB 就一直需要进行维护。
-
若是一个父进程创建了很多子进程,但都不进行回收,那么就会造成资源浪费,因为数据结构对象本身就要占用内存。
-
僵尸进程申请的资源无法进行回收,那么僵尸进程越多,实际可用的资源就越少,也就是说,僵尸进程会导致内存泄漏。
孤儿进程
在 Linux 当中的进程关系大多数是父子关系,若子进程先退出而父进程没有对子进程的退出信息进行读取,那么我们称该进程为僵尸进程。但若是父进程先退出,那么将来子进程进入僵尸状态时就没有父进程对其进行处理,此时该子进程就称之为孤儿进程。
若是一直不处理孤儿进程的退出信息,那么孤儿进程就会一直占用资源,此时就会造成内存泄漏。因此,当出现孤儿进程的时候,孤儿进程会被 1 号 init 进程领养,此后当孤儿进程进入僵尸状态时就由 int 进程进行处理回收。
例如,对于以下代码,fork 函数创建的子进程会一直打印信息,而父进程在打印 5 次信息后会退出,此时该子进程就变成了孤儿进程。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main ()
{
printf ("I am running...\n");
pid_t id = fork ();
if (id == 0){ //child
int count = 5;
while (1){
printf ("I am child...PID:% d, PPID:% d\n", getpid (), getppid (), count);
sleep (1);
}
}
else if (id > 0){ //father
int count = 5;
while (count){
printf ("I am father...PID:% d, PPID:% d, count:% d\n", getpid (), getppid (), count);
sleep (1);
count--;
}
printf ("father quit...\n");
exit (0);
}
else { //fork error
}
return 0;
}
观察代码运行结果,在父进程未退出时,子进程的 PPID 就是父进程的 PID,而当父进程退出后,子进程的 PPID 就变成了 1,即子进程被 1 号进程领养了。
进程优先级
基本概念
什么是优先级?
优先级实际上就是获取某种资源的先后顺序,而进程优先级实际上就是进程获取 CPU 资源分配的先后顺序,就是指进程的优先权(priority),优先权高的进程有优先执行的权力。
优先级存在的原因?
优先级存在的主要原因就是资源是有限的,而存在进程优先级的主要原因就是 CPU 资源是有限的,一个 CPU 一次只能跑一个进程,而进程是可以有多个的,所以需要存在进程优先级,来确定进程获取 CPU 资源的先后顺序。
查看系统进程
在 Linux 或者 Unix 操作系统中,用 ps -l 命令会类似输出以下几个内容:
[cl@VM-0-15-centos pri]$ ps -l

列出的信息当中有几个重要的信息,如下:
- UID:代表执行者的身份。
- PID:代表这个进程的代号。
- PPID:代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号。
- PRI:代表这个进程可被执行的优先级,其值越小越早被执行。
- NI:代表这个进程的 nice 值。
PRI 与 NI
- PRI 代表进程的优先级(priority),通俗点说就是进程被 CPU 执行的先后顺序,该值越小进程的优先级别越高。
- NI 代表的是 nice 值,其表示进程可被执行的优先级的修正数值。
- PRI 值越小越快被执行,当加入 nice 值后,将会使得 PRI 变为:
PRI (new) = PRI (old) + NI。 - 若 NI 值为负值,那么该进程的 PRI 将变小,即其优先级会变高。
- 调整进程优先级,在 Linux 下,就是调整进程的 nice 值。
- NI 的取值范围是 - 20 至 19,一共 40 个级别。
- 注意:在 Linux 操作系统当中,PRI (old) 默认为 80,即 PRI = 80 + NI。
查看进程优先级信息
当我们创建一个进程后,我们可以使用 ps -al 命令查看该进程优先级的信息。
[cl@VM-0-15-centos pri]$ ps -al

注意:在 Linux 操作系统中,初始进程一般优先级 PRI 默认为 80,NI 默认为 0。
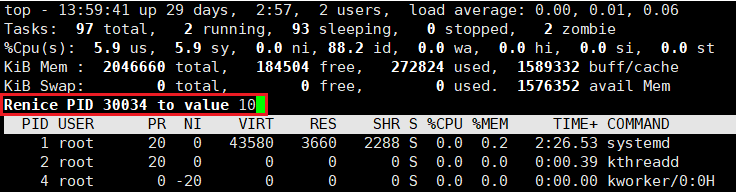
通过 top 命令更改进程的 nice 值
top 命令就相当于 Windows 操作系统中的任务管理器,它能够动态实时的显示系统当中进程的资源占用情况。

使用 top 命令后按 “r” 键,会要求你输入待调整 nice 值的进程的 PID。

输入进程 PID 并回车后,会要求你输入调整后的 nice 值。

输入 nice 值后按 “q” 即可退出,如果我们这里输入的 nice 值为 10,那么此时我们再用 ps 命令查看进程的优先级信息,即可发现进程的 NI 变成了 10,PRI 变成了 90(80+NI)。

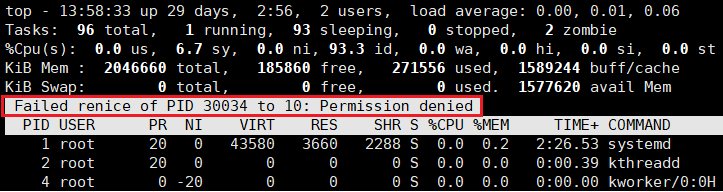
注意:若是想将 NI 值调为负值,也就是将进程的优先级调高,需要使用 sudo 命令提升权限。
通过 renice 命令更改进程的 nice 值
使用 renice 命令,后面跟上更改后的 nice 值和进程的 PID 即可。

之后我们再用 ps 命令查看进程的优先级信息,也可以发现进程的 NI 变成了 10,PRI 变成了 90(80+NI)。

注意:若是想使用 renice 命令将 NI 值调为负值,也需要使用 sudo 命令提升权限。
四个重要概念
竞争性:系统进程数目众多,而 CPU 资源只有少量,甚至 1 个,所以进程之间是具有竞争属性的。为了高效完成任务,更合理竞争相关资源,便有了优先级。
独立性:多进程运行,需要独享各种资源,多进程运行期间互不干扰。
并行:多个进程在多个 CPU 下分别同时进行运行,这称之为并行。
并发:多个进程在一个 CPU 下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发。
环境变量
基本概念
环境变量(environment variables)一般是指在操作系统中用来指定操作系统运行环境的一些参数。
例如,我们编写的 C/C++ 代码,在各个目标文件进行链接的时候,从来不知道我们所链接的动静态库在哪里,但是照样可以链接成功,生成可执行程序,原因就是有相关环境变量帮助编译器进行查找。
环境变量通常具有某些特殊用途,并且在系统当中通常具有全局特性。
常见环境变量
- PATH:指定命令的搜索路径。
- HOME:指定用户的主工作目录(即用户登录到 Linux 系统中的默认所处目录)。
- SHELL:当前 Shell,它的值通常是 /bin/bash。
查看环境变量的方法
我们可以通过 echo 命令来查看环境变量,方式如下:
echo $NAME //NAME为待查看的环境变量名称
例如,查看环境变量 PATH。
[cl@VM-0-15-centos ENV]$ echo $PATH
1

测试 PATH
大家有没有想过这样一个问题:为什么执行 ls 命令的时候不用带./ 就可以执行,而我们自己生成的可执行程序必须要在前面带上./ 才可以执行?

容易理解的是,要执行一个可执行程序必须要先找到它在哪里,既然不带./ 就可以执行 ls 命令,说明系统能够通过 ls 名称找到 ls 的位置,而系统是无法找到我们自己的可执行程序的,所以我们必须带上./,以此告诉系统该可执行程序位于当前目录下。
而系统就是通过环境变量 PATH 来找到 ls 命令的,查看环境变量 PATH 我们可以看到如下内容:

可以看到环境变量 PATH 当中有多条路径,这些路径由冒号隔开,当你使用 ls 命令时,系统就会查看环境变量 PATH,然后默认从左到右依次在各个路径当中进行查找。
而 ls 命令实际就位于 PATH 当中的某一个路径下,所以就算 ls 命令不带路径执行,系统也是能够找到的。

那可不可以让我们自己的可执行程序也不用带路径就可以执行呢?
当然可以,下面给出两种方式:
方式一:将可执行程序拷贝到环境变量 PATH 的某一路径下。
既然在未指定路径的情况下系统会根据环境变量 PATH 当中的路径进行查找,那我们就可以将我们的可执行程序拷贝到 PATH 的某一路径下,此后我们的可执行程序不带路径系统也可以找到了。
[cl@VM-0-15-centos ENV]$ sudo cp proc /usr/bin

方式二:将可执行程序所在的目录导入到环境变量 PATH 当中。
将可执行程序所在的目录导入到环境变量 PATH 当中,这样一来,没有指定路径时系统就会来到该目录下进行查找了。
[cl@VM-0-15-centos ENV]$ export PATH=$PATH:/home/cl/dirforproc/ENV

将可执行程序所在的目录导入到环境变量 PATH 当中后,位于该目录下的可执行程序也就可以在不带路径的情况下执行了。

测试 HOME
任何一个用户在运行系统登录时都有自己的主工作目录(家目录),环境变量 HOME 当中即保存的该用户的主工作目录。
普通用户示例:

超级用户示例:

测试 SHELL
我们在 Linux 操作系统当中所敲的各种命令,实际上需要由命令行解释器进行解释,而在 Linux 当中有许多种命令行解释器(例如 bash、sh),我们可以通过查看环境变量 SHELL 来知道自己当前所用的命令行解释器的种类。

而该命令行解释器实际上是系统当中的一条命令,当这个命令运行起来变成进程后就可以为我们进行命令行解释。

和环境变量相关的命令
echo:显示某个环境变量的值。

export:设置一个新的环境变量。
env:显示所有的环境变量。

部分环境变量说明:
| 环境变量名称 | 表示内容 |
|---|---|
| PATH | 命令的搜索路径 |
| HOME | 用户的主工作目录 |
| SHELL | 当前 Shell |
| HOSTNAME | 主机名 |
| TERM | 终端类型 |
| HISTSIZE | 记录历史命令的条数 |
| SSH_TTY | 当前终端文件 |
| USER | 当前用户 |
| 邮箱 | |
| PWD | 当前所处路径 |
| LANG | 编码格式 |
| LOGNAME | 登录用户名 |
set:显示本地定义的 shell 变量和环境变量。

unset:清除环境变量。

环境变量的组织方式
在系统当中,环境变量的组织方式如下:

每个程序都会收到一张环境变量表,环境表是一个字符指针数组,每个指针指向一个以’\0’结尾的环境字符串,最后一个字符指针为空。
通过代码获取环境变量
你知道 main 函数其实是有参数的吗?
main 函数其实有三个参数,只是我们平时基本不用它们,所以一般情况下都没有写出来。我们可以在 Windows 下的编译器进行验证,当我们调试代码的时候,若是一直使用逐步调试,那么最终会来到调用 main 函数的地方。

在这里我们可以看到,调用 main 函数时给 main 函数传递了三个参数。
我们先来说说 main 函数的前两个参数。
在 Linux 操作系统下,编写以下代码,生成可执行程序并运行。

运行结果如下:

现在我们来说说 main 函数的前两个参数,main 函数的第二个参数是一个字符指针数组,数组当中的第一个字符指针存储的是可执行程序的位置,其余字符指针存储的是所给的若干选项,最后一个字符指针为空,而 main 函数的第一个参数代表的就是字符指针数组当中的有效元素个数。

下面我们可以尝试编写一个简单的代码,该代码运行起来后会根据你所给选项给出不同的提示语句。
#include <stdio.h>
#include <string.h>
int main (int argc, char *argv [], char* envp [])
{
if (argc > 1)
{
if (strcmp (argv [1], "-a") == 0)
{
printf ("you used -a option...\n");
}
else if (strcmp (argv [1], "-b") == 0)
{
printf ("you used -b option...\n");
}
else
{
printf ("you used unrecognizable option...\n");
}
}
else
{
printf ("you did not use any option...\n");
}
return 0;
}
代码运行结果如下:

现在我们来说说 main 函数的第三个参数。
main 函数的第三个参数接收的实际上就是环境变量表,我们可以通过 main 函数的第三个参数来获取系统的环境变量。
例如,编写以下代码,生成可执行程序并运行。

运行结果就是各个环境变量的值:

除了使用 main 函数的第三个参数来获取环境变量以外,我们还可以通过第三方变量 environ 来获取。

运行该代码生成的可执行程序,我们同样可以获得环境变量的值:

注意:libc 中定义的全局变量 environ 指向环境变量表,environ 没有包含在任何头文件中,所以在使用时要用 extern 进行声明。
通过系统调用获取环境变量
除了通过 main 函数的第三个参数和第三方变量 environ 来获取环境变量外,我们还可以通过系统调用 getenv 函数来获取环境变量。
getenv 函数可以根据所给环境变量名,在环境变量表当中进行搜索,并返回一个指向相应值的字符串指针。
例如,使用 getenv 函数获取环境变量 PATH 的值。

运行结果:

程序地址空间
下面这张空间布局图相信大家都见过:

在 Linux 操作系统中,我们可以通过以下代码对该布局图进行验证:

运行结果如下,与布局图所示是吻合的:

下面我们来看一段奇怪的代码:

代码当中用 fork 函数创建了一个子进程,其中让子进程相将全局变量 g_val 该从 100 改为 200 后打印,而父进程先休眠 3 秒钟,然后再打印全局变量的值。
按道理来说子进程打印的全局变量的值为 200,而父进程是在子进程将全局变量改后再打印的全局变量,那么也应该是 200,但是代码运行结果如下:

可以看到父进程打印的全局变量 g_val 的值仍为之前的 100,更奇怪的是在父子进程中打印的全局变量 g_val 的地址是一样的,也就是说父子进程在同一个地址处读出的值不同。
如果说我们是在同一个物理地址处获取的值,那必定是相同的,而现在在同一个地址处获取到的值却不同,这只能说明我们打印出来的地址绝对不是物理地址!!!
实际上,我们在语言层面上打印出来的地址都不是物理地址,而是虚拟地址。物理地址用户一概是看不到的,是由操作系统统一进行管理的。
所以就算父子进程当中打印出来的全局变量的地址(虚拟地址)相同,但是两个进程当中全局变量的值却是不同的。

注意:虚拟地址和物理地址之间的转化由操作系统完成。
进程地址空间
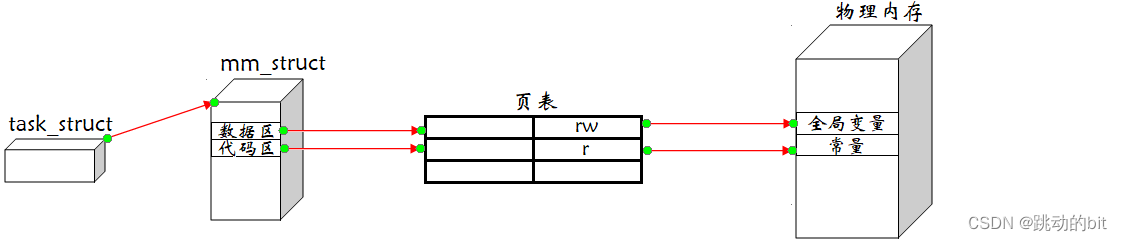
我们之前将那张布局图称为程序地址空间实际上是不准确的,那张布局图实际上应该叫做进程地址空间,进程地址空间本质上是内存中的一种内核数据结构,在 Linux 当中进程地址空间具体由结构体 mm_struct 实现。
进程地址空间就类似于一把尺子,尺子的刻度由 0x00000000 到 0xffffffff,尺子按照刻度被划分为各个区域,例如代码区、堆区、栈区等。而在结构体 mm_struct 当中,便记录了各个边界刻度,例如代码区的开始刻度与结束刻度,如下图所示:

在结构体 mm_struct 当中,各个边界刻度之间的每一个刻度都代表一个虚拟地址,这些虚拟地址通过页表映射与物理内存建立联系。由于虚拟地址是由 0x00000000 到 0xffffffff 线性增长的,所以虚拟地址又叫做线性地址。
扩展知识:
1、堆向上增长以及栈向下增长实际就是改变
mm_struct当中堆和栈的边界刻度。
2、我们生成的可执行程序实际上也被分为了各个区域,例如初始化区、未初始化区等。当该可执行程序运行起来时,操作系统则将对应的数据加载到对应内存当中即可,大大提高了操作系统的工作效率。而进行可执行程序的 “分区” 操作的实际上就算编译器,所以说代码的优化级别实际上是编译器说了算。
每个进程被创建时,其对应的进程控制块(task_struct)和进程地址空间(mm_struct)也会随之被创建。而操作系统可以通过进程的 task_struct 找到其 mm_struct,因为 task_struct 当中有一个结构体指针存储的是 mm_struct 的地址。
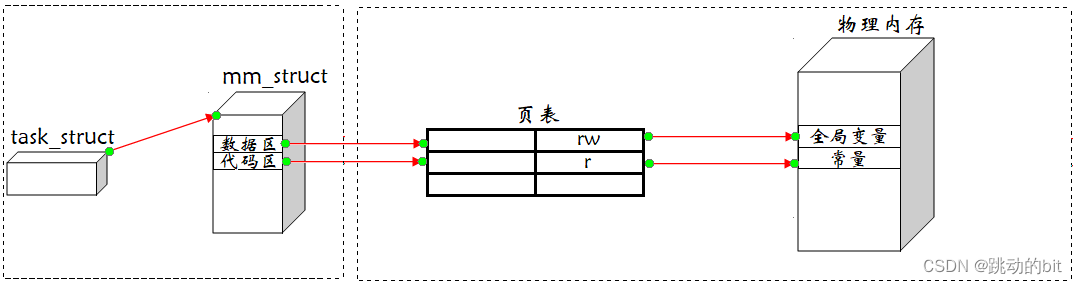
例如,父进程有自己的 task_struct 和 mm_struct,该父进程创建的子进程也有属于其自己的 task_struct 和 mm_struct,父子进程的进程地址空间当中的各个虚拟地址分别通过页表映射到物理内存的某个位置,如下图:

而当子进程刚刚被创建时,子进程和父进程的数据和代码是共享的,即父子进程的代码和数据通过页表映射到物理内存的同一块空间。只有当父进程或子进程需要修改数据时,才将父进程的数据在内存当中拷贝一份,然后再进行修改。
例如,子进程需要将全局变量 g_val 改为 200,那么此时就在内存的某处存储 g_val 的新值,并且改变子进程当中 g_val 的虚拟地址通过页表映射后得到的物理地址即可。

这种在需要进行数据修改时再进行拷贝的技术,称为写时拷贝技术。
1、为什么数据要进行写时拷贝?
进程具有独立性。多进程运行,需要独享各种资源,多进程运行期间互不干扰,不能让子进程的修改影响到父进程。
2、为什么不在创建子进程的时候就进行数据的拷贝?
子进程不一定会使用父进程的所有数据,并且在子进程不对数据进行写入的情况下,没有必要对数据进行拷贝,我们应该按需分配,在需要修改数据的时候再分配(延时分配),这样可以高效的使用内存空间。
3、代码会不会进行写时拷贝?
90% 的情况下是不会的,但这并不代表代码不能进行写时拷贝,例如在进行进程替换的时候,则需要进行代码的写时拷贝。
为什么要有进程地址空间?
1、有了进程地址空间后,就不会有任何系统级别的越界问题存在了。例如进程 1 不会错误的访问到进程 2 的物理地址空间,因为你对某一地址空间进行操作之前需要先通过页表映射到物理内存,而页表只会映射属于你的物理内存。总的来说,虚拟地址和页表的配合使用,本质功能就是包含内存。
2、有了进程地址空间后,每个进程都认为看得到都是相同的空间范围,包括进程地址空间的构成和内部区域的划分顺序等都是相同的,这样一来我们在编写程序的时候就只需关注虚拟地址,而无需关注数据在物理内存当中实际的存储位置。
3、有了进程地址空间后,每个进程都认为自己在独占内存,这样能更好的完成进程的独立性以及合理使用内存空间(当实际需要使用内存空间的时候再在内存进行开辟),并能将进程调度与内存管理进行解耦或分离。
对于创建进程的现阶段理解:
一个进程的创建实际上伴随着其进程控制块(task_struct)、进程地址空间(mm_struct)以及页表的创建。
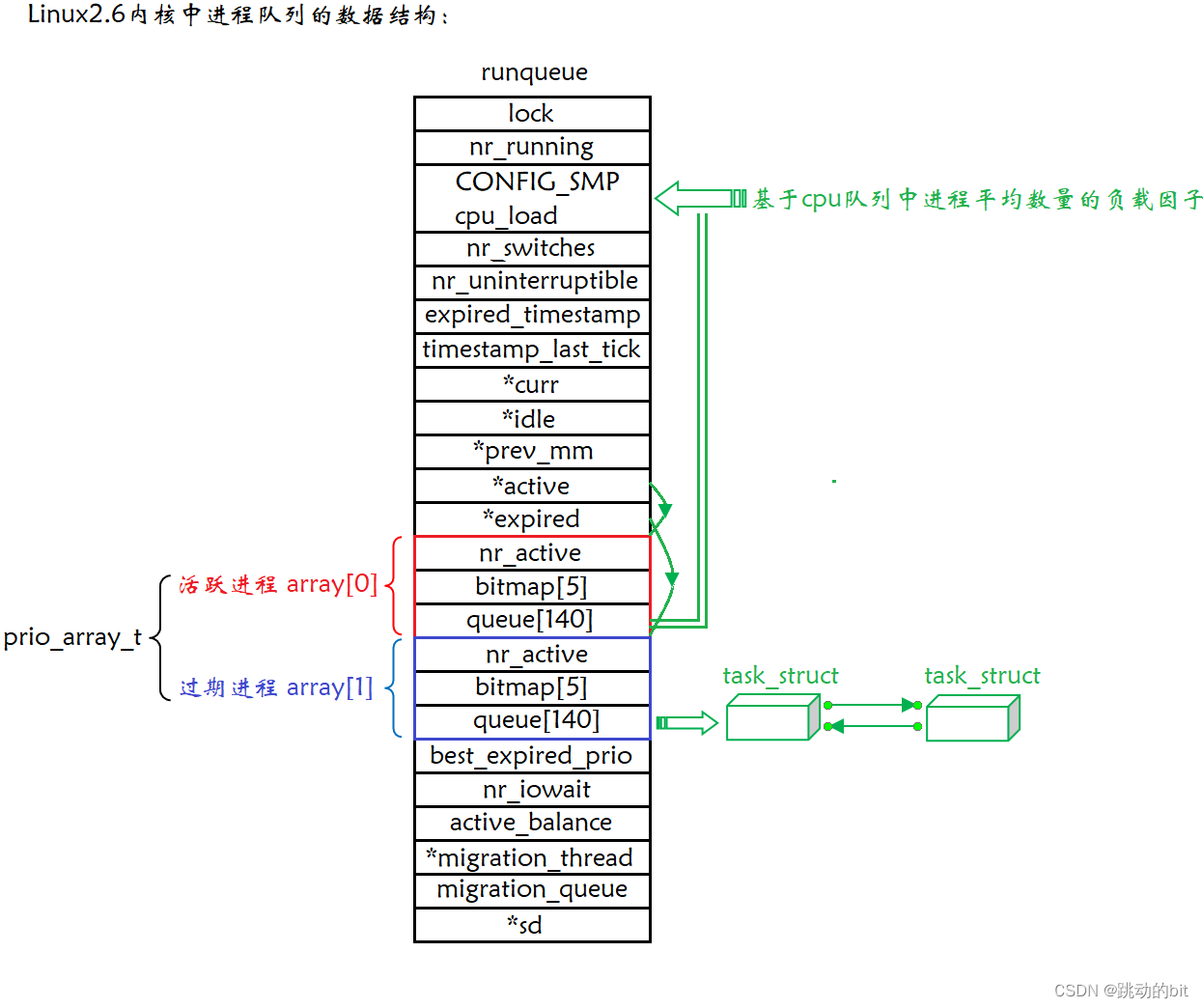
Linux2.6 内核进程调度队列

一个 CPU 拥有一个 runqueue
如果有多个 CPU 就要考虑进程个数的父子均衡问题。
优先级
queue 下标说明:
-
普通优先级:100~139。
-
实时优先级:0~99。
我们进程的都是普通的优先级,前面说到 nice 值的取值范围是 - 20~19,共 40 个级别,依次对应 queue 当中普通优先级的下标 100~139。
注意:实时优先级对应实时进程,实时进程是指先将一个进程执行完毕再执行下一个进程,现在基本不存在这种机器了,所以对于 queue 当中下标为 0~99 的元素我们不关心。
活动队列
时间片还没有结束的所有进程都按照优先级放在活动队列当中,其中 nr_active 代表总共有多少个运行状态的进程,而 queue [140] 数组当中的一个元素就是一个进程队列,相同优先级的进程按照 FIFO 规则进程排队调度。
调度过程如下:
-
从 0 下标开始遍历 queue [140]。
-
找到第一个非空队列,该队列必定为优先级最高的队列。
-
拿到选中队列的第一个进程,开始运行,调度完成。
-
接着拿到选中队列的第二个进程进行调度,直到选中进程队列当中的所有进程都被调度。
-
继续向后遍历 queue [140],寻找下一个非空队列。
bitmap [5]:queue 数组当中一共有 140 个元素,即 140 个优先级,一共 140 个进程队列,为了提高查找非空队列的效率,就可以用 5 × 32 个比特位表示队列是否为空,这样一来便可以大大提高查找效率。
总结:在系统当中查找一个最合适调度的进程的时间复杂度是一个常数,不会随着进程增多而导致时间成本增加,我们称之为进程调度的 O (1) 算法。
过期队列
-
过期队列和活动队列的结构相同。
-
过期队列上放置的进程都是时间片耗尽的进程。
-
当活动队列上的进程被处理完毕之后,对过期队列的进程进行时间片重新计算。
active 指针和 expired 指针
-
active 指针永远指向活动队列。
-
expired 指针永远指向过期队列。
由于活动队列上时间片未到期的进程会越来越少,而过期队列上的进程数量会越来越多(新创建的进程都会被放到过期队列上),那么总会出现活动队列上的全部进程的时间片都到期的情况,这时将 active 指针和 expired 指针的内容交换,就相当于让过期队列变成活动队列,活动队列变成过期队列,就相当于又具有了一批新的活动进程,如此循环进行即可。
【Linux 进程概念 —— 上】冯・诺依曼体系结构 | 操作系统 | 进程 | fork | 进程状态 | 优先级
跳动的 bit 已于 2023-09-16 15:58:15 修改
【写在前面】
从此篇开始,就开始学习 Linux 系统部分 —— 进程,在正式学习 Linux 进程之前,我们需要铺垫一些概念,如冯诺依曼体系结构 (解释可执行程序运行时,必须先加载到内存的原因)、操作系统的概念及定位、进程概念,我们会先铺垫理论,再验证理论。其次对于某些需要深入的概念我们只是先了解下。本文中的 fork 只会介绍基本使用,以及解答 fork 为啥会有 2 个返回值、为啥给子进程返回 0,而父进程返回子进程的 pid;而对于用于接收 fork 返回值的 ret 是怎么做到 ret == 0 && ret > 0、写时拷贝、代码是怎么做到共享的、数据是怎么做到各自私有的等问题会在《Linux 进程控制》中进行展开。
一、冯・诺依曼体系结构
体系结构
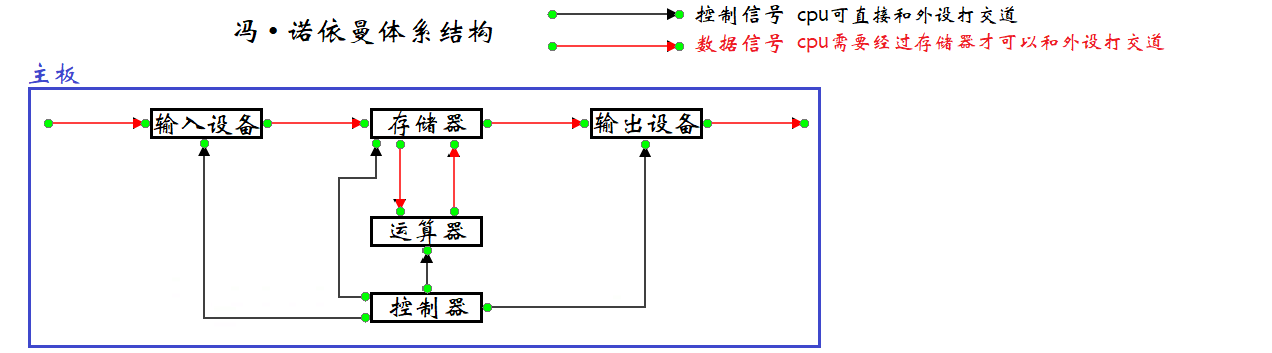
冯・诺依曼结构也称普林斯顿结构,是一种将程序指令存储器和数据存储器合并在一起的存储器结构。数学家冯・诺依曼提出了计算机制造的三个基本原则,即采用 二进制逻辑、程序存储执行 以及 计算机由五个部分组成 (运算器、控制器、存储器、输入设备、输出设备),这套理论被称为冯・诺依曼体系结构。我们常见的计算机,如笔记本。我们不常见的计算机,如服务器,大部分都遵守冯诺依曼体系。其中:
-
输入设备:键盘、鼠标 … … 。
-
输出设备:显示器、音响 … … 。
-
存储器:如没有特殊说明一般是内存。
-
运算器:集成于 CPU,用于实现数据加工处理等功能的部件。
-
控制器:集成于 CPU,用于控制着整个 CPU 的工作。
各个组件之间的互通是通过 “线” 连接实现的,这可不是那种电线杆上的线,因为计算机更精密,所以使用 “主板” 来把它们关联在一起。
数据流向
冯・诺依曼体系结构规定了硬件层面上的数据流向,所有的输入单元的数据必须先写到存储器中 (这里只是针对数据,不包含信号),然后 CPU 通过某种方式访问存储器,将数据读取到 CPU 内部,运算器进行运算,控制器进行控制,然后将结果写回到内存,最后将结果传输到输出设备中。
我们在 C/C++ 中说过,可执行程序运行时,必须加载到内存,为啥 ❓

在此之前先了解一下计算机的存储分级,其中寄存器离 CPU 最近,因为它本来就集成在 CPU 里;L1、L2、L3 是对应的三级缓存,它也集成于 CPU;主存通常指的是内存;本地存储 (硬盘) 和网络存储通常指的是外设。如图所示,这样设计其实是因为造价的原因,对于绝大多数的消费者,你不可能说直接把内存整个 1 个 T 吧,当然,氪金玩家除外。
其中通过这个图,我们想解释的是为啥计算机非得把数据从外设 (磁盘) ➡ 三级缓存 (内存) ➡ CPU,而非从外设 (磁盘) ➡ CPU。原因是因为离 CPU 更近的,存储容量更小、速度更快、成本更高;离 CPU 更远的,则相反。假设 CPU 直接访问磁盘,那么它的效率可太低了。这里有一个不太严谨的运算速度的数据,CPU 是纳秒级别的;内存是微秒级别的;磁盘是毫秒级别的。当一个快的设备和一个慢的设备一起协同时,最终的运算效率肯定是以慢的设备为主,就如 “木桶原理” —— 要去衡量木桶能装多少水,并不是由最高的木片决定的,而是由最短的木片决定的。也就是说一般 CPU 去计算时,它的短板就在磁盘上,所以整个计算机体系的效率就一定会被磁盘拖累。所以我们必须在运行时把数据加载到内存中,然后 CPU 再计算,而在计算的期间可以同时让输入单元加载到内存,这样可以让加载的时间和计算的时间重合,以提升效率。
同理因为效率原因 CPU 也是不能直接访问输出单元的,这里以网卡为例,我刚发条 qq 消息给朋友,发现网络很卡,四五秒才发出去,而在这个过程,你不可能让 CPU 等你四五秒吧,那成本可太高了,所以通常 CPU 也是把数据写到内存里,合适的时候再把数据刷新到输出单元中。
所以本质上可以把 内存看作 CPU 和所有外设之间的缓存,所有设备也都只能和内存打交道,也可以理解成这是内存的价值。

💨小结:所有数据 ➡ 外设 ➡ 内存 ➡ CPU ➡ 内存 ➡ 刷新到外设,其中我们现在所谈论的观点是在数据层面上 CPU 不直接和外设交互,外设只和内存交互,这也就是可执行程序运行时,必须加载到内存的原因,因为冯诺依曼体系结构规定了,而我们上面花了大量篇幅主要是阐述了冯诺依曼体系结构为什么这样规定,本质电脑在开机的时候就是将操作系统加载到内存。注意一定要区分清楚某些概念是属于 “商业化的概念” 还是 “技术的概念”。
实例
对冯诺依曼的理解,不能只停留在概念上,要深入到对软件数据流理解上,请解释,你在 qq 上发送了一句 “在吗” 给朋友,数据的流动过程 ?如果是在 qq 上发送文件呢 (注意这里的计算机都遵循冯・诺依曼体系结构,且这里不谈网络,不考虑细节,只谈数据流向) ?
☣ 消息:
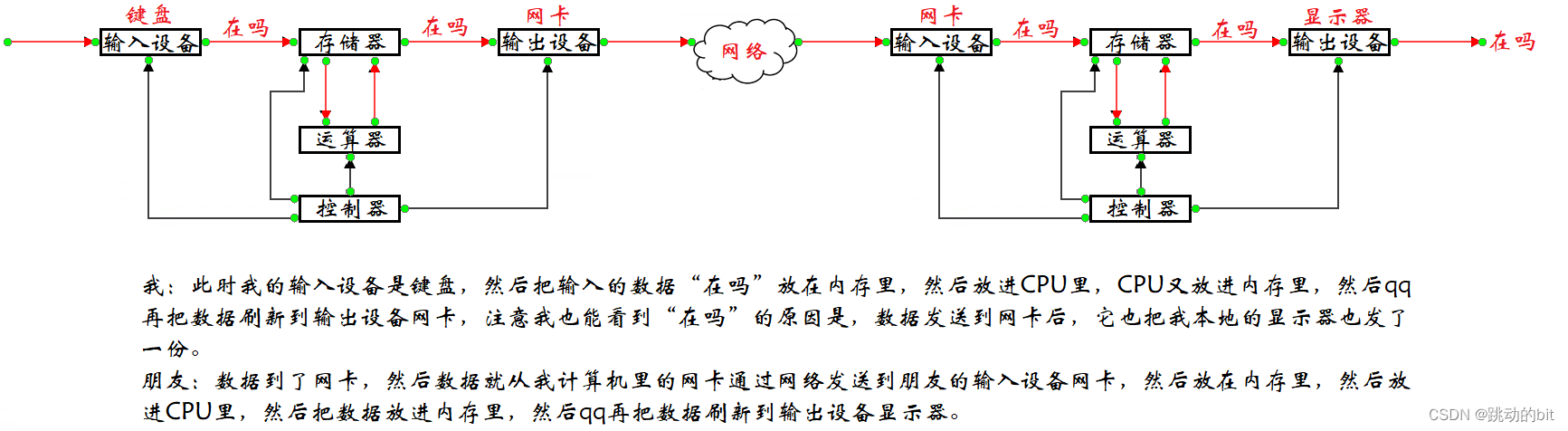
☣ 文件:

本质上发消息和发文件是没有区别的。学习这里实例的意义是让我们在硬件层面上理解了它的数据流,你的软件无论是 QQ、WeChat 等都离不开这样的数据流。
二、操作系统 (Operate System)
概念
操作系统是一个不易理解的领域,它被调侃为计算机学科中的哲学。操作系统是进行 软硬件资源管理的软件,任何计算机系统都包含一个基本的程序集合,称为操作系统 (OS)。笼统的理解,操作系统包括:
-
内核 (进程管理,内存管理,文件管理,驱动管理)。
-
其他程序 (例如函数库,shell 程序等等)。
狭义上的操作系统只是内核,广义上的操作系统是内核 + 图形界面等,我们以后谈的也只是内核。
为什么要有操作系统 ❓
-
最明显的原因是如果没有操作系统,我们就没有办法操作计算机。换句话说,操作系统的出现可以
减少用户使用计算机的成本。你总不能自己拿上电信号对应的电线自己玩吧,那样成本太高了。 -
对下管理好所有的软硬件,对上给用户提供一个稳定高效的运行环境。其中硬件指的是 CPU、网卡、显卡等;软件指的是进程管理、文件、驱动、卸载等。不管是对下还是对上,都是为了方便用户使用。
计算机体系及操作系统定位
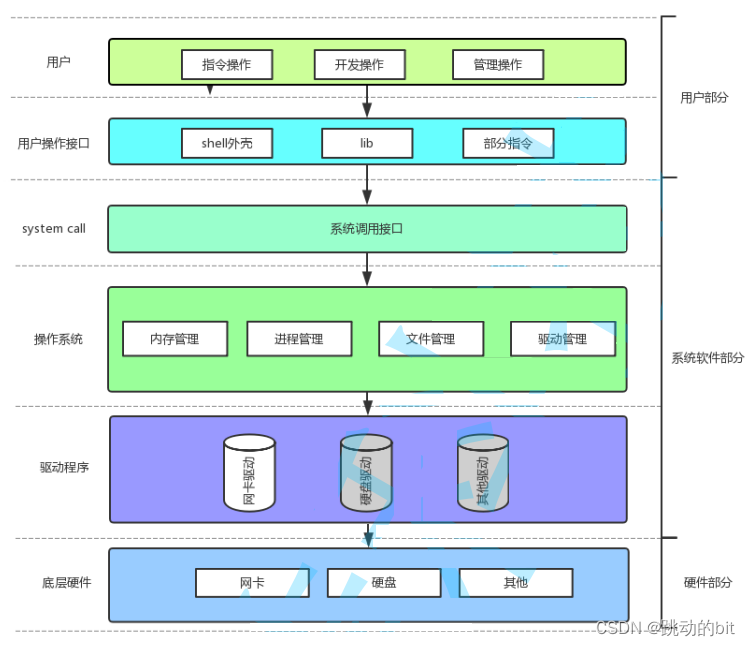
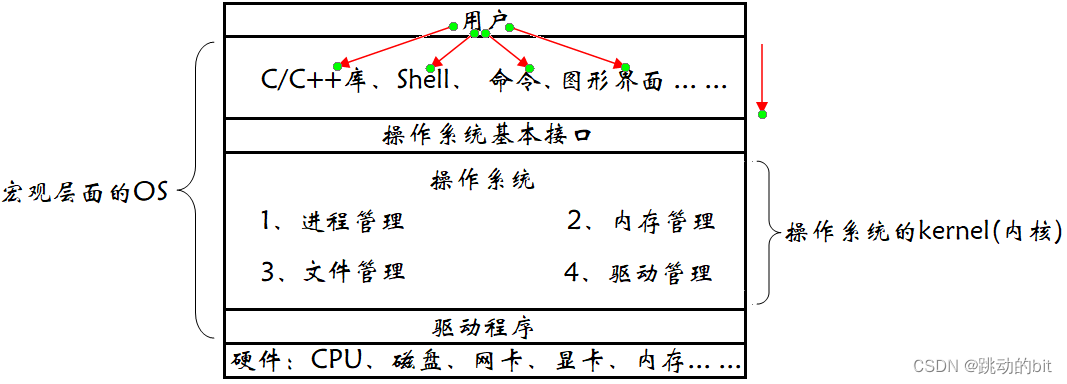
其中用户可以操作 C/C++ 库、Shell、命令、图形界面,然后底层可以通过操作系统接口完成操作系统工作,比如用户调用 C 库使用 printf 在显示器上输出,printf 又去调用系统接口最后再输出于显示器。当然后面我们会直接接触到一些系统接口;操作系统目前主流的功能有四大类 —— 1、进程管理。2、内存管理。3、文件管理。4、驱动管理。后面我们重点学习进程管理和文件管理,其次内存管理学习地址空间和映射关系就行了。
其次操作系统是 不信任任何用户的,所以用户不可能通过某种方式去访问操作系统,甚至对系统硬件或者软件的访问。而对系统软硬件的访问都必须经过操作系统。也就是说作为用户想要去访问硬件,只能通过操作系统所提供的接口去完成,但是操作系统提供的接口使用成本高,所以我们就有了基于系统调用的库等。就比如银行不信任任何人,你要去取钱 (硬件),你不能直接去仓库拿钱,你也不能私底下指挥工作人员 (驱动) 给你去仓库拿钱,银行规定你要拿钱,必须通过银行提供的 ATM 机 (操作系统提供的接口) 来取钱,而对于一些老人来说所提供的窗口 (系统接口) 使用成本也较高,所以便有了人工窗口 (库函数)。DZL AAA
也就是说我们使用 print、scanf 等库函数时,都使用了系统接口,称之为系统调用。
系统调用和库函数概念 ❓
它们本质都是一种接口,库函数是语言或者是第三方库给我们提供的接口,系统调用是 OS 提供的接口。库函数可能是 C/C++,但是操作系统是 C,因为它是用 C 写的。
-
在开发角度,操作系统对外会表现为一个整体,它不相信任何用户,但是会
暴露自己的部分接口,供上层开发使用,这部分由操作系统提供的接口,叫做系统调用。 -
系统调用在使用上,功能比较基础,对用户的要求相对也比较高,所以,有心的开发者就对
部分系统调用进行适度封装,从而形成库,有了库,就很有利于更上层用户或者开发者进行二次开发。类似于银行取钱时,一般都会人工窗口 (库),王大爷不会取钱,就去人口窗口 (调用库)。其实对于库函数的使用要么使用了 SystemCall,如 printf 函数;要么没使用 SystemCall,如 sqrt 函数或者简单的 1 + 1 或循环,C 语言中还有很多数学函数,像这些函数并没有访问操作系统,因为这些函数的实现是在用户层实现的。
我们学习的 C/C++ 的范畴实际上在系统提供的接口之上,当然 Java 等语言还要在往上点。所以我们经常说的可 “ 跨平台性 ” 的根本原因就是因为 C 语言的库对用户提供的接口是一样的,但系统调用的接口可能不一样,Windows 下就用 W 的,Linux 下就用 L 的。
现阶段所写的 C/C++ 代码价值并不大,因为大部分使用到的硬件资源是 CPU 和内存,所以更多的是完成存储器和内存之间的计算工作。事实上学了 C/C++ 什么都做不了,根本原因是只使用了 CPU 和内存,实际上语言要发挥更大的价值,需要你能访问其它的设备。
可以看到计算机体系是一个层状结构,任何访问硬件或者系统软件的行为,都必须通过 OS 接口,贯穿 OS 进行访问操作。
管理
90% 的人操作系统学不会的根本原因是不理解 “ 管理 ”。
在学校里大概有这三种角色:
-
学生 (被管理者) —— 软硬件
-
辅导员 (执行者) —— 驱动
-
校长 (管理者) —— 操作系统
现实中我们做的事情无非是 a) 做决策。 b) 做执行。总之你是不是一个真正的管理者取决于你做决策的占比多还是少,所以辅导员严格来说不是真正的管理者。在现实生活中一般都有一个现象,管理者和被管理者并不见面,校长不会因为你挂科就过来找你谈心。
管理者和被管理者并不直接打交道,那么如何进行管理 ❓
是的,在现实生活中,可能就入学的时候和毕业的时候见过校长两面,很明显学生和校长并不直接见面,但还是把学生安排的明明白白的,比如拿奖学金与否、挂科与否。事实上我要管理你并不一定要和你见面,原因是你的个人信息在学校的系统里面,也就是说本质管理者是通过 数据 来进行管理的。比如说评选奖学金,校长在教学管理系统中筛选好某系某级综合成绩排名前 3 的学生来发奖学金,这时校长把 3 位同学对应的辅导员叫过来,并要求开一个表彰大会来奖励 3 位同学,然后辅导员就开始着手执行工作。
管理者和被管理者并不直接打交道,那么数据从哪来的 ❓
其实是执行者在你入学时把你的个人信息档案录入系统。
既然是管理数据,就一定要把学生信息抽取出来,要多少信息取决于被管理对象,抽取信息的过程,我们称之为描述学生,Linux 是用 C 语言写的,而学生信息就可以用一个 struct 来描述,因为学校里肯定不止一名学生,所以每一名同学创建一个结构体变量,然后利用指针把所有的同学关联起来,构成一个双向循环链表。此时校长要对旷课超出一定次数的张三进行开除学籍的处分,那么校长先通知辅导员,叫张三不要来了,然后从系统中遍历到张三,再把张三的个人信息给删除掉。所以本质学生管理的工作,就是对链表的增删查改。
说了这么多就是想说操作系统并不和硬件打交道,而是通过驱动程序进行操作硬件。操作系统里会形成对所有硬件相关的数据结构,并连接起来,所以 对硬件的管理最后变成了对数据结构的管理。
管理的本质是:a) 对信息或数据进行管理 b) 对被管理对象先描述,然后通过某种数据结构组织起来,简化为 先描述,后组织。后面我们都会围绕着这些观点学习。
三、进程 (process)
概念
-
课本概念:进程就是一个运行起来的程序。
-
内核观点:进程就是担当分配系统资源 (CPU 时间、内存) 的实体。
当然对于进程的理解不能这么浅显,我们接着来了解一下 PCB。
描述进程 - PCB
-
至此 test.c 文件在运行前是一个普通的磁盘文件,而要运行它,就必须先加载到内存中,此时 OS 中就增加了一个需要管理的进程。
-
OS 能否一次性运行多个程序 ❓
当然可以,运行的程序很多很多,OS 当然要管理起来这些运行起来的程序。
- 正如校长和学生的例子,OS 如何管理运行起来的程序 ❓
先描述,在组织 !!!
操作系统要管理进程不仅仅是把磁盘加载到内存里 (这只是第一步),其次还会在 OS 中创建一个描述该进程的结构体,这个结构体在操作系统学科或 Linux kernel 中叫做 PCB(process control block 进程控制块),说人话就是在 Linux 下这个进程控制块是用 struct 来描述的 task_struct (因为 Linux kernel 是用 C 语言写的),这个 PCB 中几乎包含了进程相关的所有属性信息。其中被加载到内存中的程序就是学生,PCB 就是描述学生的属性信息。今天 OS 跑了一个进程,将来这些 PCB 是一定能够帮我们找到对应代码和数据的,就像学校系统中是一定包含你的个人信息的。
其次进程多了之后,操作系统为了更好的管理,需要使用 “ 双向循环链表 ” 将所有的 PCB 进行关联起来。
所以本质我们在 Linux 中 ./a.out 时主要做两个工作,其一先加载到内存,其二 OS 立马为该进程创建进程控制块来描述该进程。OS 要进行管理,只要把每一个进程的 PCB 管理好就行了,对我们来讲,要调整一个进程的优先级、设置一个进程的状态等都是对 PCB 进行操作。
💨小结:
描述:每个进程对应的 PCB 几乎包含了进程相关的所有属性信息。
组织:OS 使用了双向链表进行将每个进程对应的 PCB 组织起来。
所以 OS 对进程的管理转化为对进程信息的管理,对信息的管理就是 “ 先描述,后组织 ”,所以对进程的来之不易转化为对双链表的增删查改。
所以站在程序员以更深入的角度来看待进程就是等于:你的程序 + 内核申请的数据结构 (PCB)。
PCB (task_ struct) 内容分类
- 标示符 PID:描述本进程的唯一标示符,用来区别其他进程。
ps ajx,查看系统当前所有进程。

- 状态:任务状态,退出代码,退出信号等。
稍后我们会见到 Linux 进程的具体状态,细节下面再说。
- 优先级:相对于其他进程的优先级。
比如去食堂干饭,需要排队,而排队就是在确定优先级,这口饭你是能吃上的,只不过因为排队导致你是先吃上,还是后吃上,所以优先级决定进程先得到资源还是后得到资源。在排队打饭时有人会插队,本质就是更改自己的优先级,你插队了,就一定导致其它人的优先级降低,对其它人就不公平,所以一般不让插队。其中 CPU、网卡等类似食堂的饭,进程类似干饭的人。
为啥需要排队 ❓
也就是说为啥要有优先级呢 ?假设世界上有无限的资源,那么就不会存在优先级了。而这里因为窗口太少了,所以优先级是在有限资源 (CPU、网卡等) 的前提下,确立谁先访问资源,谁后访问的问题。所以优先级存在的本质是资源有限。 到目前为止,除了进行文件访问、输入输出等操作,大部分所写的代码竞争的都是 CPU 资源,比如说遍历数组、二叉树等,最终都会变成进程,然后竞争 CPU 资源,而我们后面需要竞争网络资源。
优先级 and 权限有什么区别 ❓
优先级一定能得到某种资源,只不过是时间长短问题;而权限是决定你能还是不能得到某种资源。
- 程序计数器 eip:程序中即将被执行的下一条指令的地址。
CPU 运行的代码,都是进程的代码,CPU 如何知道,应该取进程中的哪条指令 ❓
我们都知道语言中一般有三种流程语句 a) 顺序语句。 b) 判断语句。c) 循环语句。一般程序中默认是从上至下执行代码的。

在 CPU 内有一个寄存器,我们通常称之为 eip,也称为 pc 指针,它的工作是保存当前正在执行指令的下一条指令的地址。当进程没有结束,却不想运行时,我们可以将当前 eip 里的内容保存到 PCB 里 (其实不太准确,这里只是先为了好理解,后面知识储备够了,再回头校准),目的是为了恢复,具体细节后面会谈。
你说 eip 是指向当前正在执行的下一条指令的地址,那么第一次 eip 在干啥 ❓
这里是属于硬件上下文的概念,下面在谈进程切换时再学习。
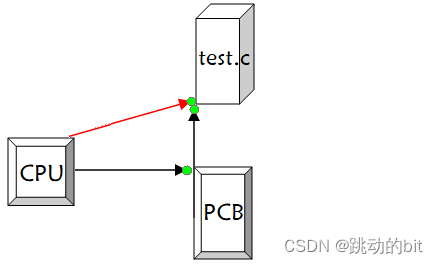
- 内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。
CPU 不能直接去访问代码和数据,需要通过 PCB 去访问。内存指针可以理解为它是代码和进程相关数据结构的指针,通过这些内存指针可以帮助我们在 PCB 找到该进程所对应的代码和数据。
- 上下文数据:进程执行时处理器的寄存器中的数据。
其中寄存器信息可以通过 VS 集成开发环境下查看:代码 ➡ 调试 ➡ 转到反汇编 ➡ 打开寄存器窗口。
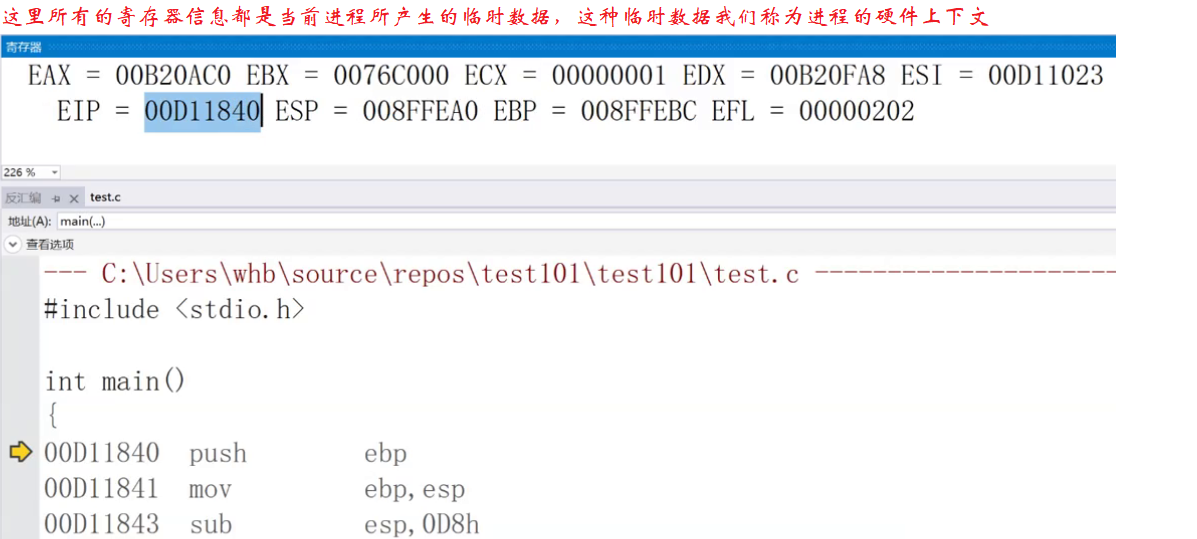
我们常说的什么多核处理器,如四核八线程,注意它不是指 CPU 里的控制器,而是 CPU 里的运算器变多了,所以它计算的更快。后面我们可能会听过一个概念叫超线程,它其实是 CPU 开启了 并发指令流 的一种技术,所以它就允许有多种执行流在 CPU 上同时跑。
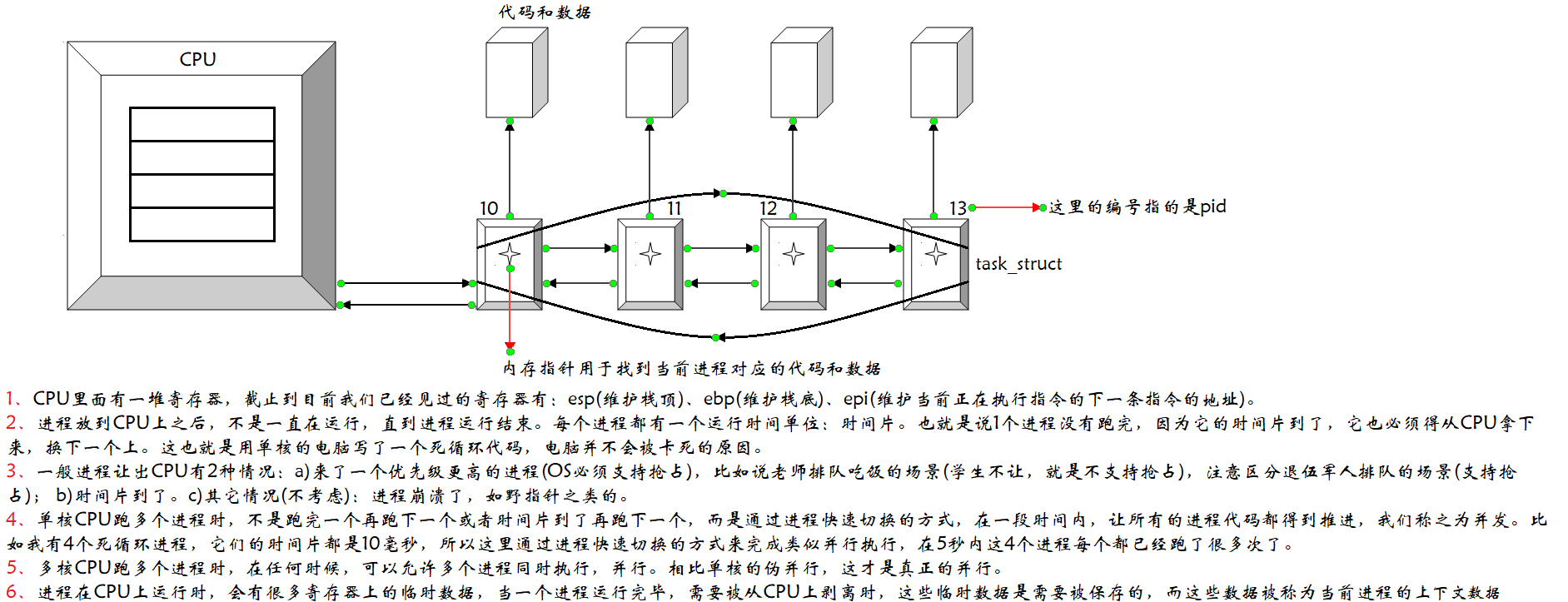
进程快速切换 && 运行队列 ❓
比如你是一名大二的学生, 已经上了二十几节课了,但因为身体原因,需要休一年的学,于是你就走了,而当你一年后回来时,你发现你能挂的科都已经挂完了,甚至你已经被退学了,原因是学校的资源都给你分配着呢,但因为你的一走了之,且没有跟导员打招呼而休学。所以正确方式是在你休学前,你应该跟导员打招呼,待导员向上级申明并把你当前的学籍信息 (你大几、挂了几科、累计学分、先把当前正在学习的课程停了) 保存后,才能离开,一年后,你回来了,但是你在上课时并没有你的位置,老师点名册上也没有你的名字,根本原因是你没有恢复学籍,你应该跟导员说恢复学籍,然后把你安排到对应的班级,此时你就接着上次保存学籍的学习状态继续学习。
也就是说当一个进程运行时,因为某些原因需要被暂时停止执行,让出 CPU,此时当前 CPU 里有很多当前进程的临时数据,所以需要在 PCB 里先保存当前进程的上下文数据,而保存的目的是为了下一次运行前先恢复。所以对于多个进程,一个运算器的情况下,为了实现并发,进程对应的时间片到了,就把进程从 CPU 上剥离下来,在这之前会把上下文数据保存至 PCB,然后再换下一个进程,在这之前如果这个进程内有曾经保存的临时数据,那么它会先恢复数据,CPU 再运行上次运行的结果,这个过程就叫做 上下文保存恢复 以及 进程快速切换。
系统里当前有 4 个进程是处于运行状态的,此时会形成 运行队列 (runqueue),它也是一种数据结构,你可以理解为通过运行队列也能将所有在运行的 PCB 连接起来,凡是在运行队列中的进程的状态都是 R,也就是说每一个 PCB 结构在操作系统中有可能是链表,也有可能是队列,这个 PCB 里面会通过某种方式包含了大量的指针结构。注意以上所有的结构都是在内核中由操作系统自动完成的,这其中细节很多,后面每个阶段我们都会对细节进行完善,其次还包括 阻塞队列、等待队列 会再详谈。
- I/O 状态信息:包括显示的 I/O 请求,分配给进程的 I/O 设备和被进程使用的文件列表。
白话就是哪些 I/O 设备是允许进程访问的。
- 记账信息:可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
白话就是你的一个进程,在调度时所使用的时间、在切换时切换的次数等。
记帐信息的意义 ❓
现实中也存在 “ 记帐信息 ”,也有一定的意义,比如每个人的年龄,每过一年,第人都会增长一岁,那么不同人累计下来的 “ 记帐信息 ” 值不同时,会有不同的状态,如六个月,你不会走路;六年,学习;二十四年,工作;八十年,有人主动让座。所以对系统来讲可以通过 “ 记帐信息 ” 来指导进程,比如有 2 个优先级相同的进程,一个累计调度了 10 秒钟,另一个累计调度了 5 秒钟,下一次则优先调度 5 秒钟的进程,因为调度器应该公平或较为公平的让所有进程享受 CPU 资源。
调度 ???
调度就是在从多的进程中,选择一个去执行,好比高铁站,你能准时准点的坐上高铁,根本原因是高铁站内部有自己的调度规则。
- 其他信息。
查看进程
通过系统调用获取进程标示符 ❓
-
进程 id:
PID -
父进程 id:
PPID
我们可以使用 man 2 getpid/getppid 命令来查看人生中第一个系统调用接口:
代码一跑起来就查看当前进程的 pid and ppid:

当然我们也可以查看当前进程的父进程 bash:

父进程和子进程之间的关系就如同村长家的儿子指明道姓要找王婆找如花媳妇,可是如花已经跟李四跑了,王婆一看生意没法做,风险太大,此时王婆就面临着两难,其一,张三是村长的儿子;其二,如花已经跟李四跑了。所以王婆就在婚介所招聘有能力说这桩媒的媒婆实习生,王婆不自己去,而让实习生去。如果事说成了,王婆脸上也有光,如果事没说成,那么对王婆也没影响。同样的 bash 在执行命令时,往往不是由 bash 在进行解释和执行,而是由 bash 创建子进程,让子进程执行。所以一般情况我们执行的每一个命令行进程都是命令行解释器的子进程。其细节,后面再谈。
其它方式查看进程 ❓
- 可以使用
top命令来查看进程,类似于 Windows 下的任务管理器,一般用的少。
- 可以使用
ls /proc命令来查看,proc 在 Linux 的根目录下。
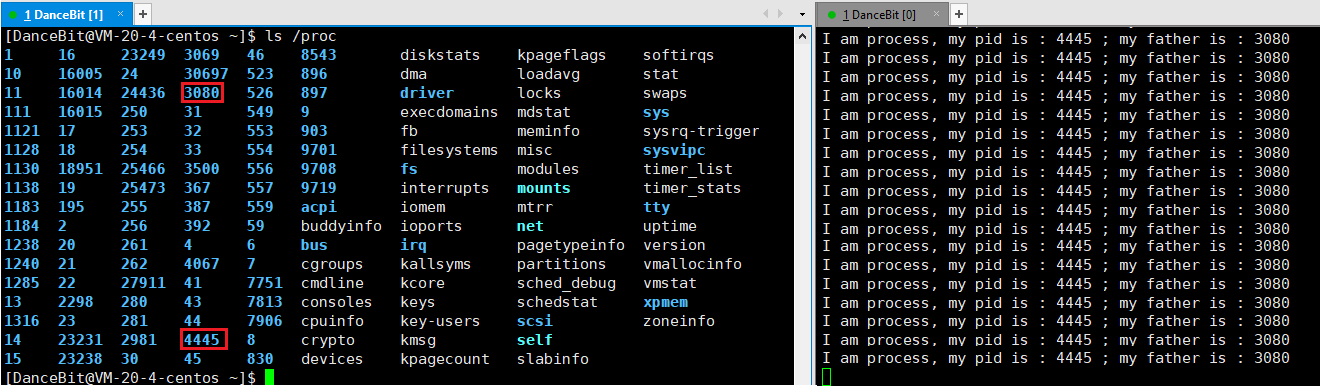
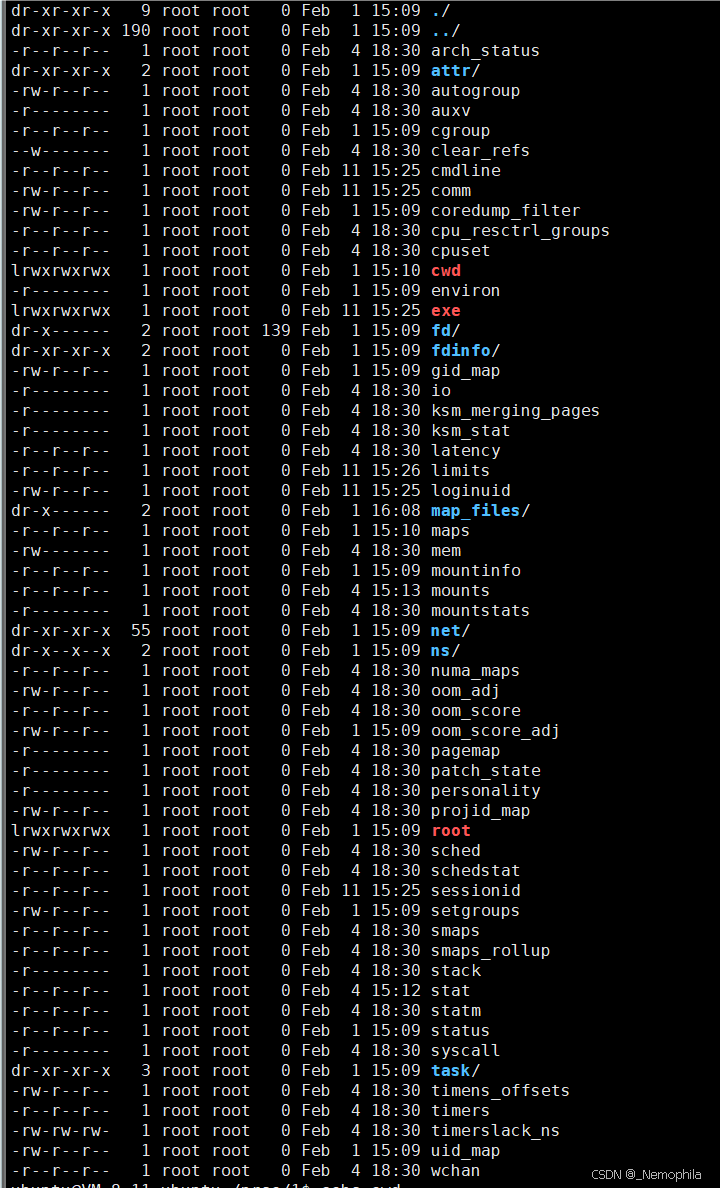
如果要查看对应进程的信息,可以使用 ls/proc/pid -al 命令:
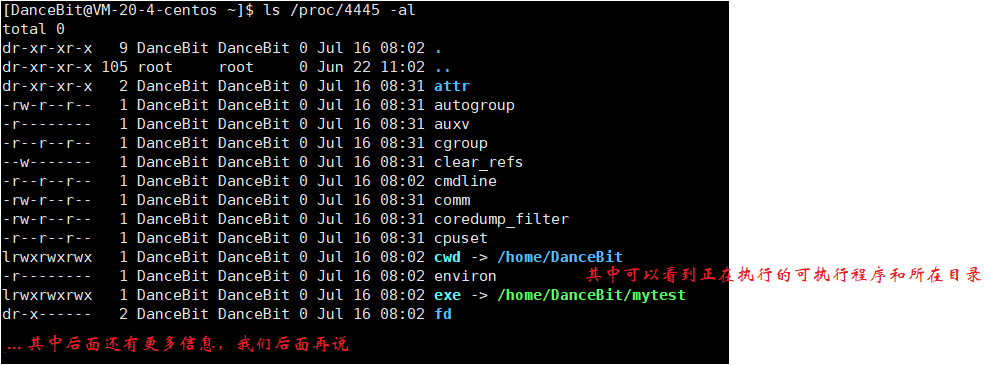
接着我们再看下 1 号进程:
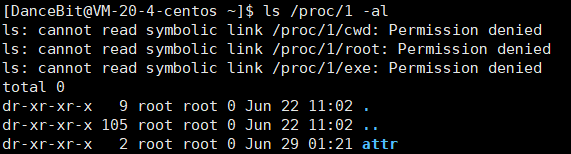
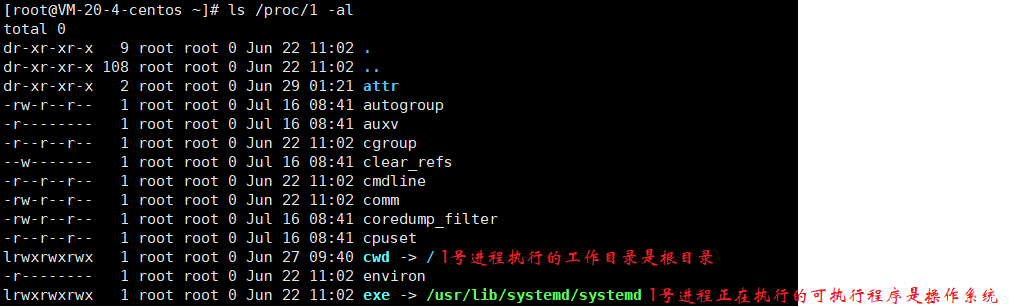
当然因为权限问题有部分文件不让我们看,今天还非看不可,直接换 root 用户 (这里就拎两个看得懂的出来):
三、创建子进程 fork
上面我们写了一个死循环代码,然后 “ ./ ” 运行,一般我们称之为命令式创建进程,实际上我们也可以用代码来创建子进程。
fork 也是系统调用接口,对于 fork 我们还会在 “ 进程控制 ” 章节中再深入,在此文中我们会通过 a) 程序员角度。 b) 内核角度。来学习 fork。
认识 fork
man 2 fork 来查找 fork 的相关手册:
使用 fork 创建进程
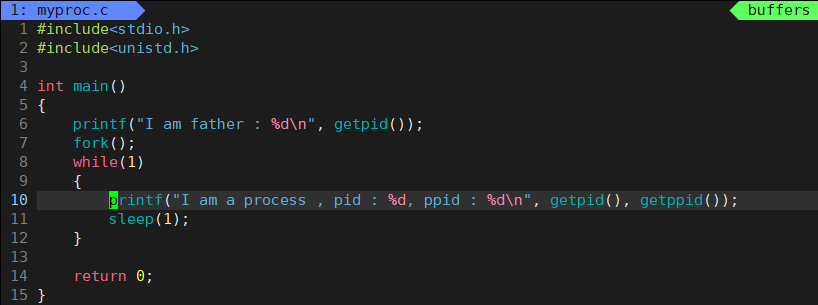
这里 fork 后,后面的代码一定是被上面的父子进程共享的,换言之,这个循环每次循环都会被父子进程执行一次:
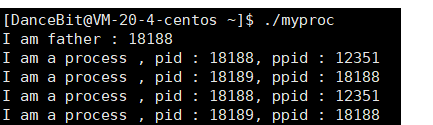
可以看到 fork 之前,当前进程的 pid 是 18188,fork 之后,也可以看到 18188 的父进程 bash 是 12351。然后 fork 之后的那个进程是 18189,它的父进程就是 18188。换言之,父进程 fork 创建了子进程,谁调用 fork,谁就是父进程,:
ps ajx 查看当前进程:

程序员角度理解 fork
通过上面的代码知道了 fork 可以创建子进程,也就意味着 fork 之后,这个子进程才能被创建成功,父进程和子进程都要执行一样的代码,但是 fork 之后,父进程和子进程谁先执行,不是由 fork 决定的,而是由系统的调度优先级决定的。
也就是说 父子进程共享用户代码 —— 只读的;而 用户数据各自私有一份 —— 比如使用任务管理器,结束 Visual Studio2017 进程,并不会影响 Xshell,一个进程出现了问题,并不会影响其它进程,所以操作系统中,所有进程是具有独立性,这是操作系统表现出来的特性。而将各自进程的用户数据私有一份,进程和进程之间就可以达到不互相干扰的特性。
注意这里私有数据的过程并不是一创建进程就给你的,而是采用 写时拷贝 的技术,曾经在 C++ 里的 深浅拷贝 谈过,这里后面还要再详谈,因为我们虽然在语言上学过了,但是在系统上还没学过。
内核角度理解 fork
fork 之后,站在操作系统的角度就是多了一个进程,以我们目前有限的知识,我们知道 进程 = 程序代码 + 内核数据结构 (task_struct),其中操作系统需要先为子进程创建内核数据结构,在系统角度创建子进程,通常以父进程为模板,子进程中默认使用的是父进程中的代码和数据 (写时拷贝)。
fork 的常规用法
- 如上代码,fork 之后与父进程执行一样的代码,有什么意义 ❓
我直接让父进程做不就完了嘛,所以大部分情况下这样的父子进程,是想让父和子执行不同的代码。所以不是这样用 fork 的,而是通过 fork 的返回值来进行代码的分支功能。
- fork 返回值 ❓


你没有看错,当 fork 成功时,它会返回两个值,在父进程中返回子进程的 pid,在子进程中返回 0。当 fork 失败时,它会在父进程中返回 -1,且没有子进程的创建,并设置 errno。虽然文档中提示它会返回 -1,但在内核中 pid_t 其实是无符号整型的。
- 在之前的学习中我们都知道 if … 、else if …,是不可能同时进入的,更过分的是那有没有可能它们在进入时同时跑 2 份死循环呢 ❓
放在以前根本不可能,因为它是单进程,而现在我们使用 fork 创建父子进程 (多进程),所以对于 if … 、else if …,它都会被进入,且 2 个死循环都会跑。对我们来讲这里的父进程就是自己,然后你自己 fork 创建了子进程,所以从 fork 之后,就有 2 个执行流,这里让子进程执行 if,父进程执行 else if。
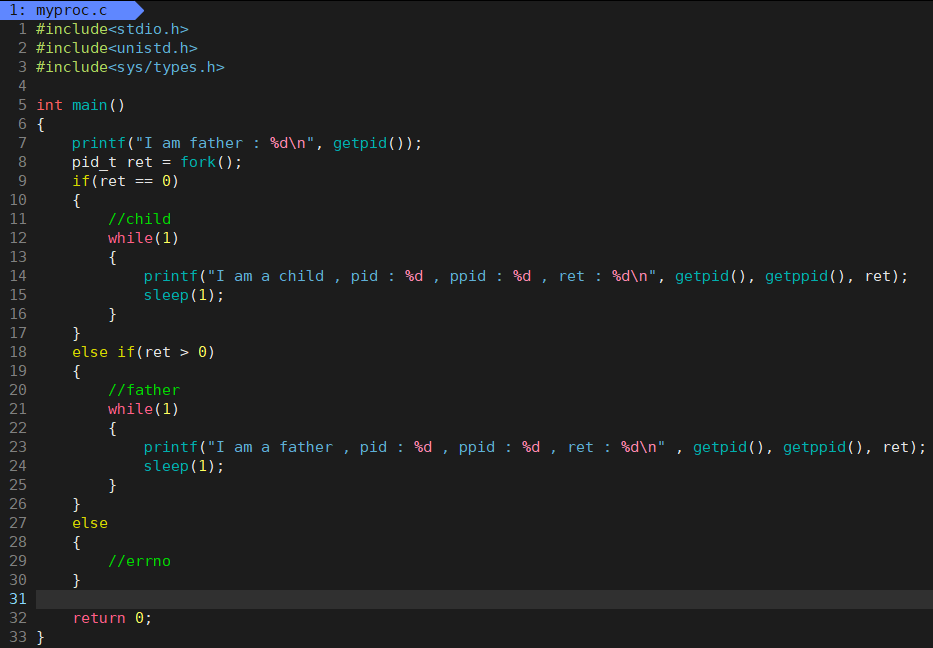
可以看到 fork 之前只有 1 个进程,但 fork 后就有 2 个进程一起运行,注意这里是系统来规定父子进程执行的先后顺序。这里肯定是并发,因为我的云服务器只是 1 核的配置,所以它底层其实是以 “ 进程快速切换 ” 来达到并行的效果。就意义而言,我们创建子进程是想帮助父进程来完成任务的,现在我们刚涉及,所以让它俩各自测试输出。如果我们要实现边下载边播放的功能那么价值就可以体现了,这样就可以实现一个并发执行的多进程程序。

- 一个变量 ret 是怎么做到既等于 0,又大于 0 的 ❓
按以前的知识,就现在看到的场景,用于接收 fork 返回值的 ret 是怎么可以既等于 0,又大于 0 的,在我们 C/C++ 上是绝对不可能的。这个的理解是需要我们进程控制中的 进程地址空间 的知识来铺垫才能理解的,所以本章中不会解释。
- fork 为啥会有 2 个返回值 ❓
我们在调用一个函数时,这个函数已经准备 return 了,那么就认为这个函数的功能完成了,return 并不属于这个函数的功能,而是告诉调用方我完成了,这里 fork 在准备 return 时,fork 创建子进程的工作已经完成了,甚至子进程已经被放在调度队列里了。我们刚刚说过,fork 之后,父子进程是共享代码的,return 当然是代码,是和父子进程共享的代码,所以当我们父进程 return 时,这里的子进程也要 return,所以说这里的父子进程会使 fork 返回 2 个值。注意即使是父进程已经跑过的代码,对于那段代码,子进程也是共享的,只不过子进程不再执行罢了。

- 为啥给子进程返回 0,而父进程返回子进程的 pid ❓
在生活中,对于儿子,只能有 1 个父亲,而对于父亲,却可以有多个儿子,比如家里有 3 个儿子正在被训,其中老二犯了错,父亲不可能说 “ 儿子,过来,我抽你一顿 ”,而应该是说 “ 老二 过来,我抽你一顿 ”;而儿子却可以说 “ 爸爸,我来啦 ”。既定事实是儿子找父亲是特别简单的,而父亲找儿子,特别是有成百上千个儿子时就很不容易,所以可以看到父亲为了能更好的区别,会对每个儿子进行标识,并且记住它们。所以父进程返回子进程的 pid 的原因是因为父进程可能会创建多个子进程 (好比你出生后你爸就给你起了个名字),所以这为了保证父进程能拿到想拿到的子进程;而子进程返回 0 的原因是父进程对于子进程是唯一的 (好比你不可能给你爸起名字)。
父进程拿子进程干嘛 ???
那你爸拿你的名字干嘛,肯定是叫你办事呀,同样的父进程拿子进程有很多用途:比如说有 5 个子进程,我想把某个任务指派给某个子进程,这时就通过它的 pid 来指定;当然你要杀掉某个子进程,可以使用 pid 来杀掉想杀掉的子进程。
子进程的 pid 会存储在父进程的 PCB ???
不会,因为子进程的 pid 是给你看的,你可以拿着 pid 去搞事情。而实际在内核里它们父子是由对应的链表结构去维护的。
- 如何创建多个子进程 ???
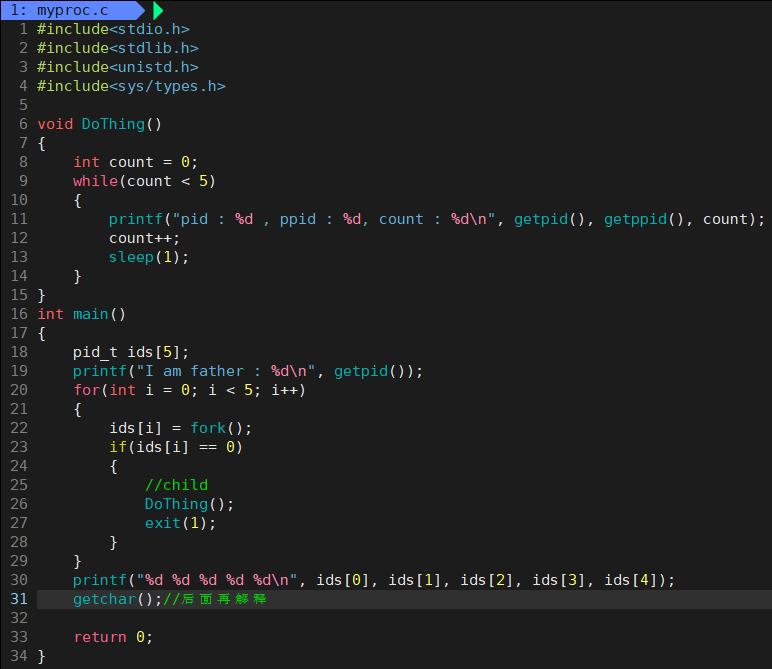
循环初始声明仅在 C99 模式中允许,所以需要 -std=c99 编译:

运行后:
进程状态
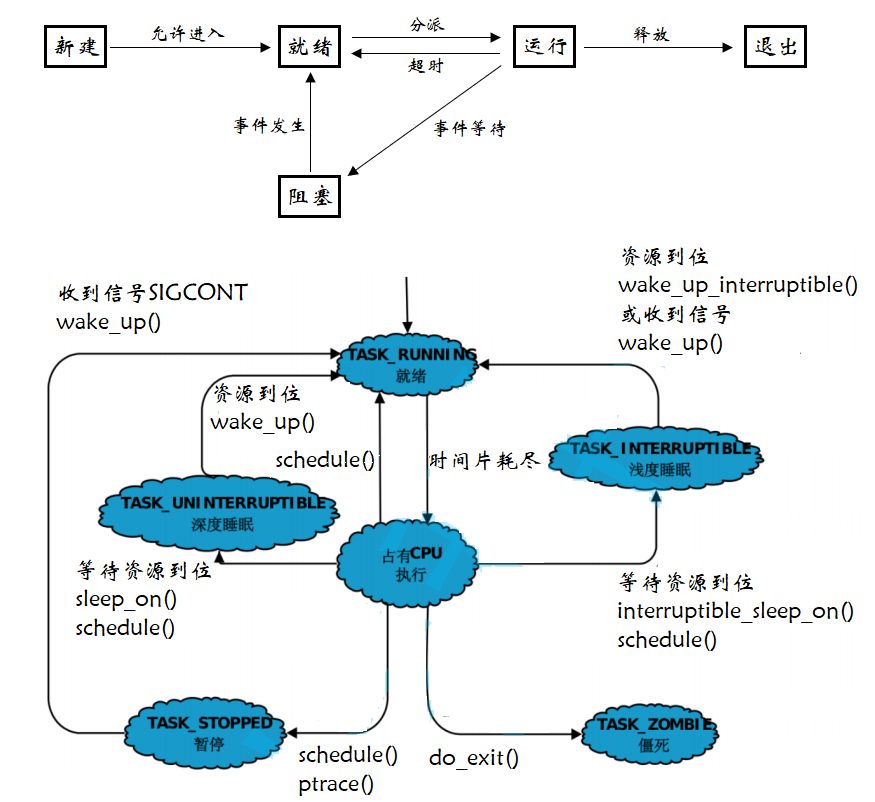
对于操作系统进程状态,大部分教材或者网上的一些资料,都是这种图。图肯定是没有问题的,只不过不好理解,比如超时就是时间片到了;什么是就绪,它是什么状态;这种状态是操作系统描述的状态,意思是说如上图所描述的状态,放在 windows 下是对的,放在 linux 下也是对的,放在任何一款操作系统下都是对的,它描述的更多的是一个宏观的操作系统,比较笼统,我们需要所见即所得的去具体了解一个操作系统。所以下面我们就需要学习具体 linux 操作系统的状态,等认识完 linux 操作系统的状态后再回过头来看上图 (其实是可以对应的)。
1、Linux 2.6 内核源码
后期我们主要也是以 Linux 2.6 为主来学习,因为它匹配的书籍较多。
其中 task_state_array [] 里描述的是 Linux 的进程状态:
2、R (running)
- 进程是 R 状态,是否一定在 CPU 上运行 ❓
进程在运行队列中,就叫做 R 状态,也就是说进程想被 CPU 运行,前提条件是你必须处于 R 状态,R:我准备好了,你可以调度我。
- 为啥我在死循环跑,但状态却是 S ❓

因为代码大部分时间是在 sleep 的,且每次 1 秒钟,其次 printf 是往显示器上输出的,涉及到 I/O,效率比较低,一定会要求进程去等我们把数据刷新到显示器上。所以综合考量,我们这个程序可能只有万分之一的时间在运行,其它时间都在休眠,站在用户的角度它一直都是 R,但是对于操作系统来说可能只有一瞬间才是 R,它有可能在队列中等待调度。
- 如果我们就想看下 R 状态呢 ❓
循环里啥都不要做。

3、S (sleeping)
休眠状态 (浅度休眠),大部分情况都是这种休眠,它可被换醒,我们可以 Ctrl + C 退出循环,而此时的进程就没了,也就是说它虽然是一种休眠状态,但是它随时可以接收外部的信号,处理外部的请求。

4、D (disk sleep)
休眠状态 (深度休眠)
-
如上图,进程拿着一批数据找到了磁盘说:磁盘,你帮我把数据放在你对应的位置。磁盘说:好嘞,你先等着。然后进程就慢慢的往磁盘写数据,磁盘也慢慢地写到对应的位置。此时进程处于等待状态,它在等磁盘把数据写完,然后告诉进程写入成功 or 失败。此时操作系统过来说:你没发现现在内存严重不足了吗,我现在要释放一些闲置的内存资源,随后就把进程干掉了。磁盘写失败后,然后跟进程说:不好意思,我写失败了,然而进程已经挂了,此时我们的数据流向就不确定了。这种情况是存在的。
-
对于上面的场景,这个锅由谁来背 —— 操作系统 / 内存 / 磁盘 ❓
于是它们三方开始了争论:
操作系统说,你在那等,我又不知道你在等啥,系统内存不足了,我就尽我的职责,我的工程师就是这样写我的,杀掉闲置的内存。假如我这次不杀你,那你说下次我再遇到一些该杀死的闲置的内存,我怕我又被责怪,所以没杀,你就认为我不作为?操作系统说:我又识别不了哪些进程是重要或不重要的。
磁盘说,我就是一个跑腿的,你们让我干啥就干啥,又不是写入的结果不告诉你,而是你不在了。
进程说,我在那规矩的等着呢,是有人把我杀了,我自己也不想退出。
这里好像谁也没有错,但是确实出现了问题,难道说错的是用户,内存买小了吗?无论是操作系统、内存、磁盘都是为了给用户提供更好的服务。根本原因是操作系统能杀掉此进程,如果让操作系统不能杀掉此进程就可以了。我现在做的事情很重要,即便操作系统再牛,也杀不了我,你系统内存不够了,你想其它办法去,不要来搞我。所以我们针对这种类型的进程我们给出了 D 状态,所以操作系统从此就知道了以后 D 是个大哥,不能搞。
所以对于深度睡眠的进程不可以被杀死,即便是操作系统。通常在访问磁盘这样的 I/O 设备,进行数据拷贝的关键步骤上,是需要将进程设置为 D 的,好比 1 秒钟内,平台有 100 万的用户注册,如果数据丢失,那么带来的损失是巨大的。
- 对于深度睡眠的进程怎么结束 ❓
只能等待 D 状态进程自动醒来,或者关机重启,但有可能会卡住。深度睡眠的进程在我们云服务机器上暂时没法演示,万一把自己的机器玩挂了,成本较高。
不管是浅度睡眠还是深度睡眠都是一种等待状态,因为某种条件不满足。
5、T (stopped)
- 对于一个正在运行的进程,怎么暂停 ❓

使用 kill -l 命令,查看信号,这里更多内容后面我们再学习:
使用 kill -19 13095 命令,给 13095 进程发送第 19 号信号来暂停进程:

使用 kill -18 13095 命令,给 13095 进程发送第 18 号信号来恢复进程:
我们也可以认为 T 是一种等待状态,不过更多的应该认为程序因为某种原因,所以想让程序先暂停执行。
6、T (tracing stop)
当你使用 vs of gdb 调试代码,比如你打了一个断点,然后开始调试,此时在断点处停下来的状态就是 t,这里是小 t 为了和上面进行区分。这里先不细谈。
7、Z (zomble)
比如你早上去晨跑时,突然看到其他跑友躺地上已经无躺倒状态了,你虽然救不了人,也破不了案,但是作为一个热心市民,可以打电话给 110 和 120。随后警察来了,第一时间肯定不会把这个人抬走,清理现场,如果是这样的话凶手肯定会笑开花。第一时间肯定是先确定人是正常死亡还是非正常死亡,如果是非正常死亡,那么立马封锁现场,拉上警戒线,判断是自杀的还是他杀,医生对人的状态进行判断,如果是正常死亡,就判断是因为疾病,还是年纪大了,最终判断出人是是因为疾病离开的,警察和医生的任务已经完成后,不会就把人放这,直接撤了,而是把人抬走,恢复地方秩序,然后通知家属,需要做很多的工作,所以当一个人死亡时,并不是立马把这个人从世界上抹掉,而是分析这个人身上的退出信息,比如说体态特征、血压等信息来确定具体的退出原因。
同样进程退出,一般不是立马让 OS 回收资源,释放进程所有的资源,作为一个死亡的进程,OS 不会说你已经死了,就赶紧把你释放了,就像不会人一死亡,就赶紧把你拉到火葬场,而是要做很多繁杂的工作,同样 OS 也要做工作,比如要知道进程是因为什么原因退出的。创建进程的目的是为了完成某件任务,进程退出了,我得知道他把我任务完成的怎么样了,所以 OS 在进程退出时,要搜集进程退出的相关有效数据,并写进自己的 PCB 内,以供 OS 或父进程来进行读取。只有读取成功之后,该进程才算真正死亡,此时我们称该进程为 死亡状态 X,再由操作系统进行回收,关于回收会在进程控制中讲 wait 时提及。其中我们把一个进程退出,但还没有被读取的那个时间点,我们称该进程为 僵尸状态 Z 。
我作为父进程 fork 创建一个子进程,子进程死亡了,但父进程没通过接口让 OS 回收,此时子进程的状态就是 Z。
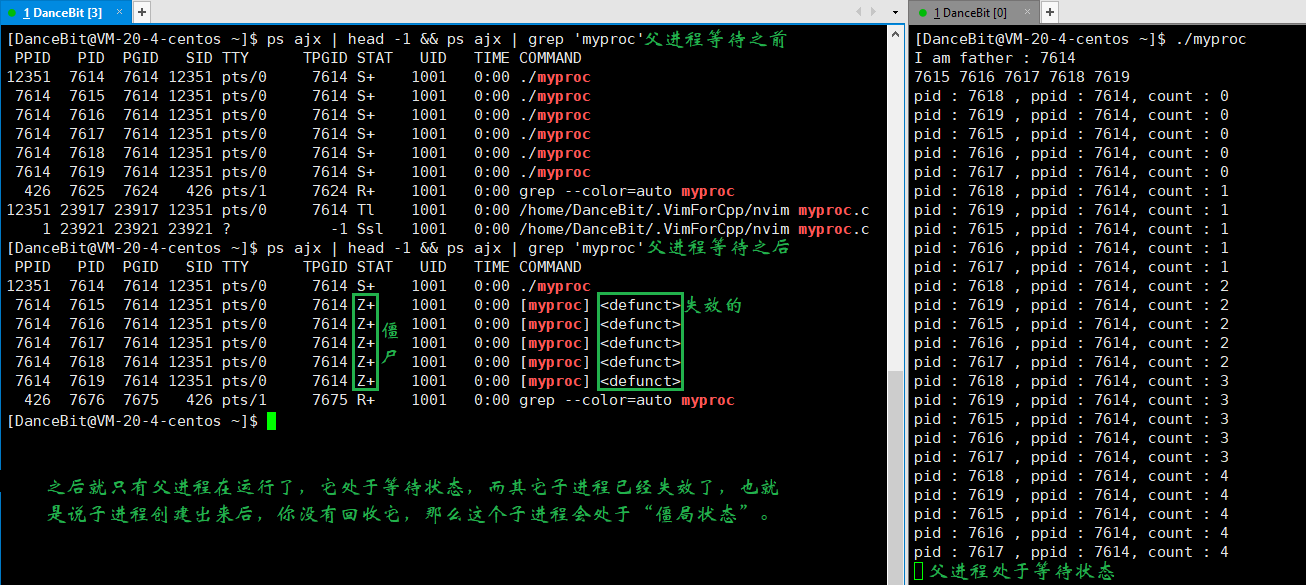
僵尸状态演示 ❓
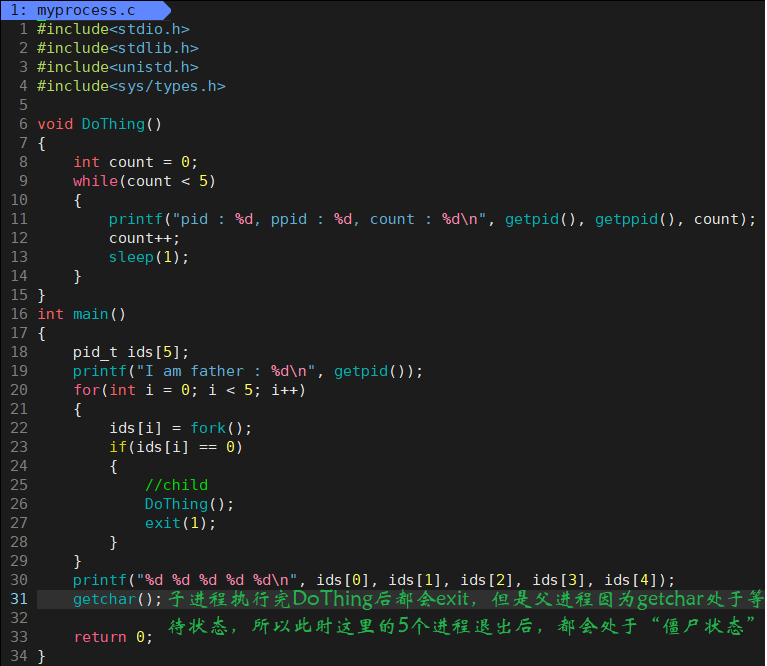
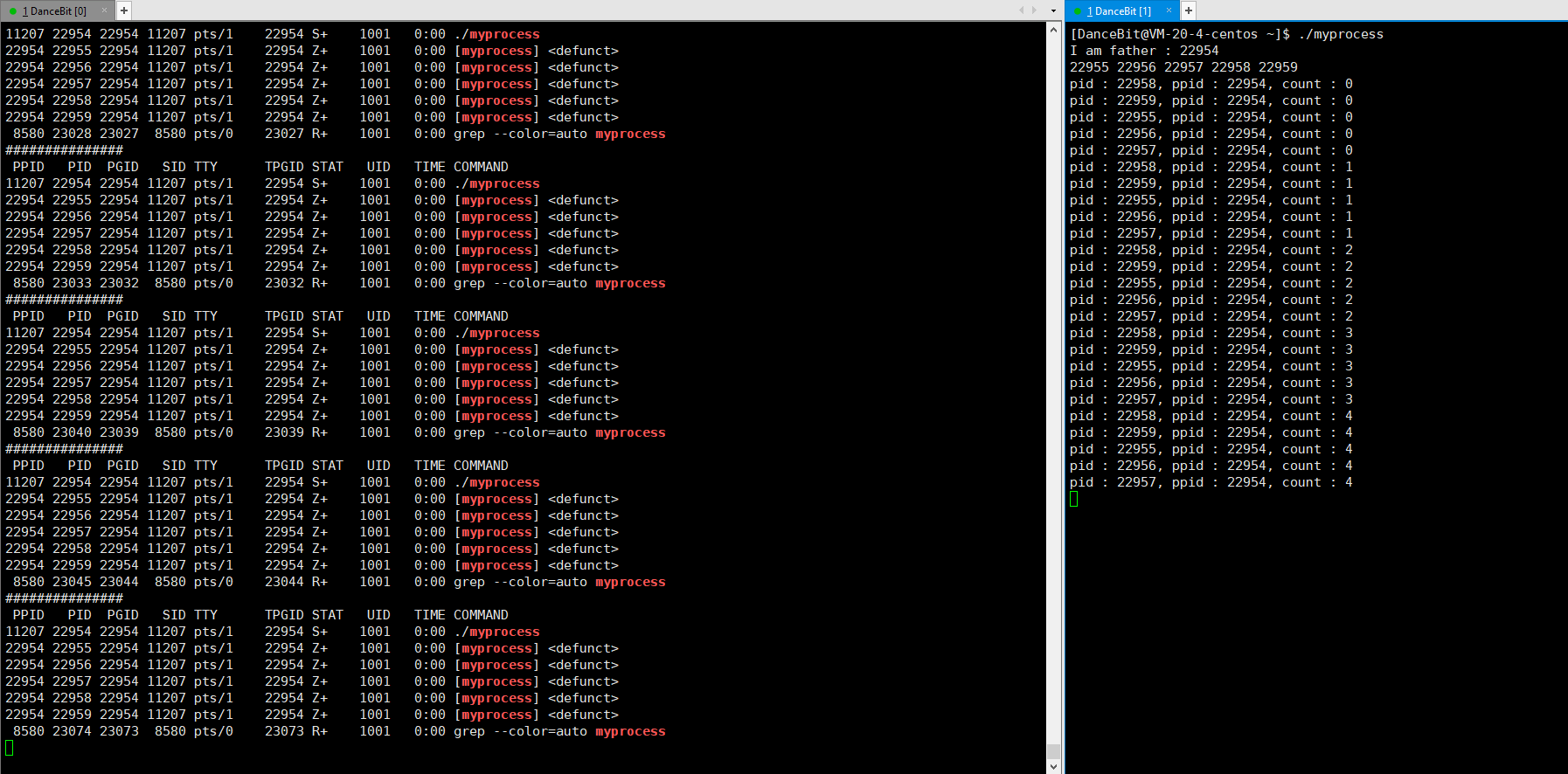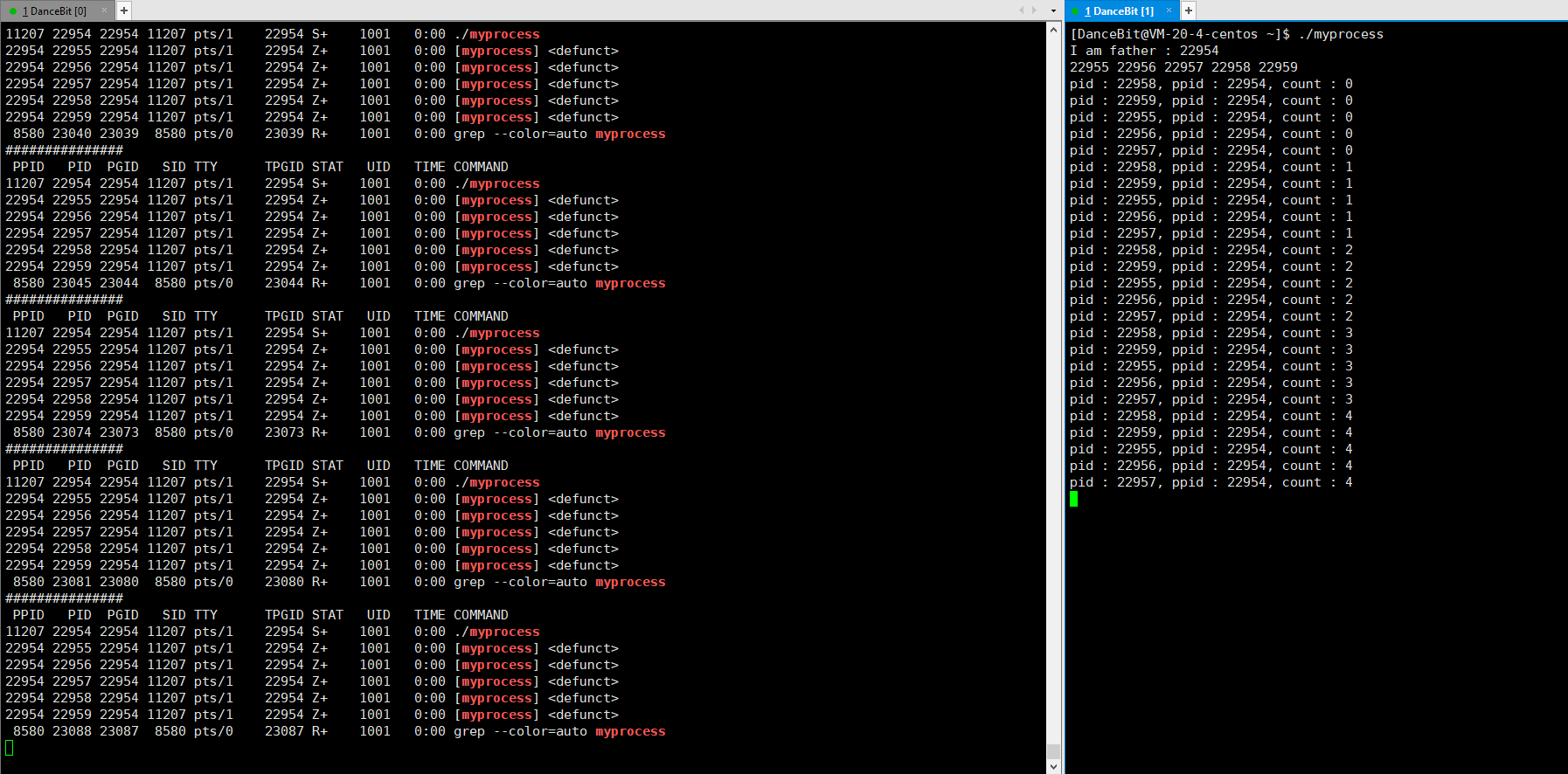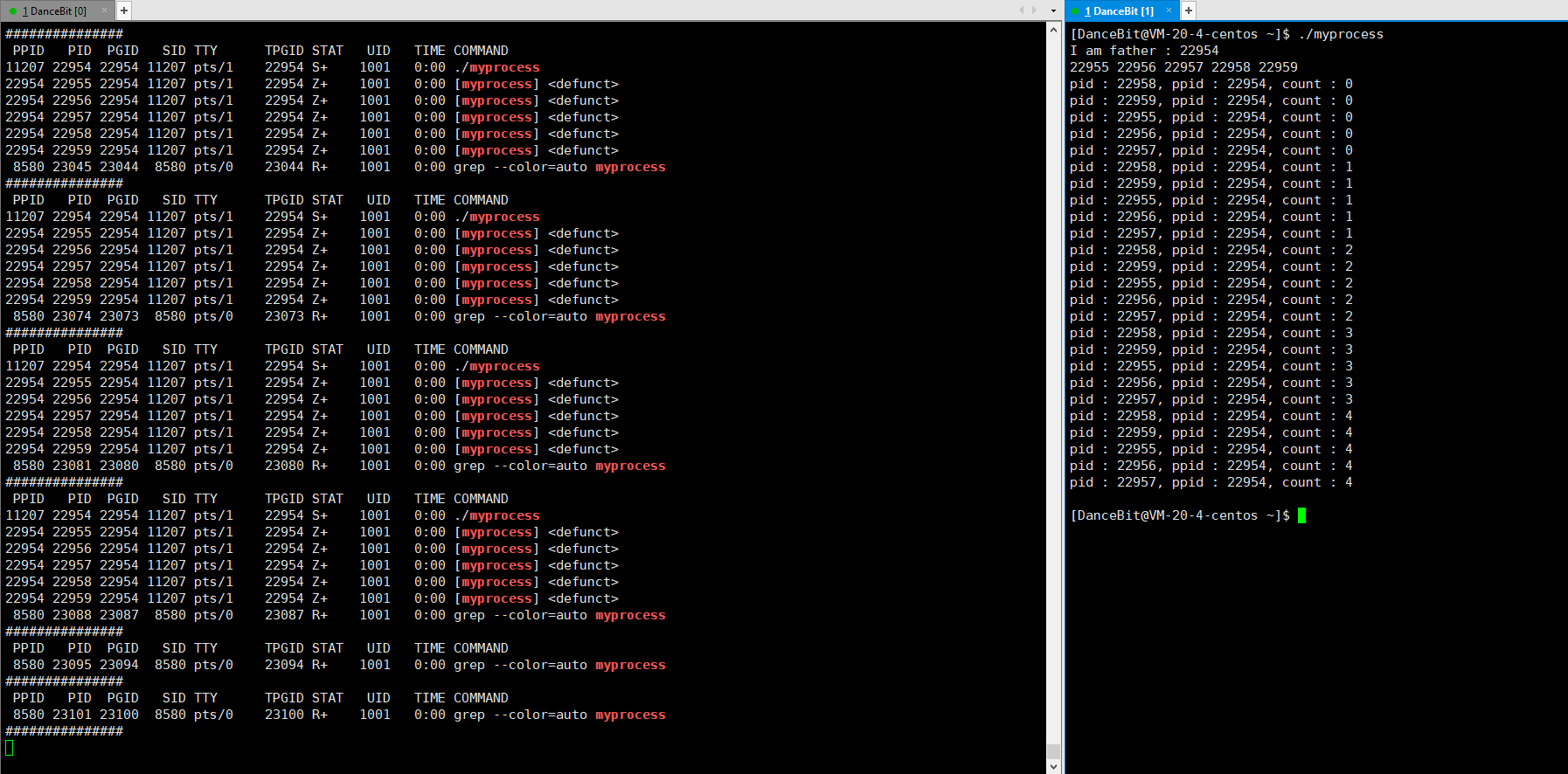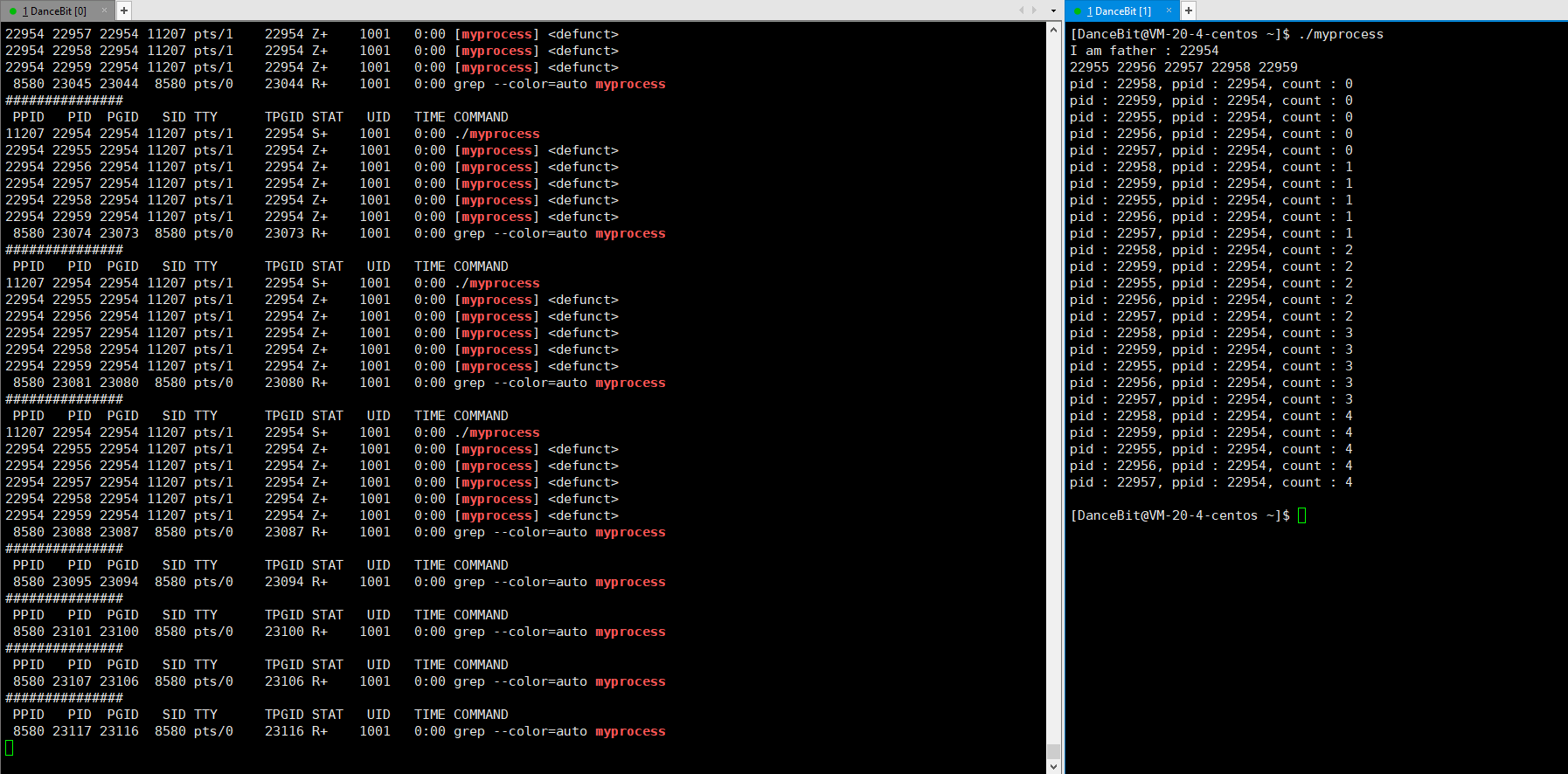
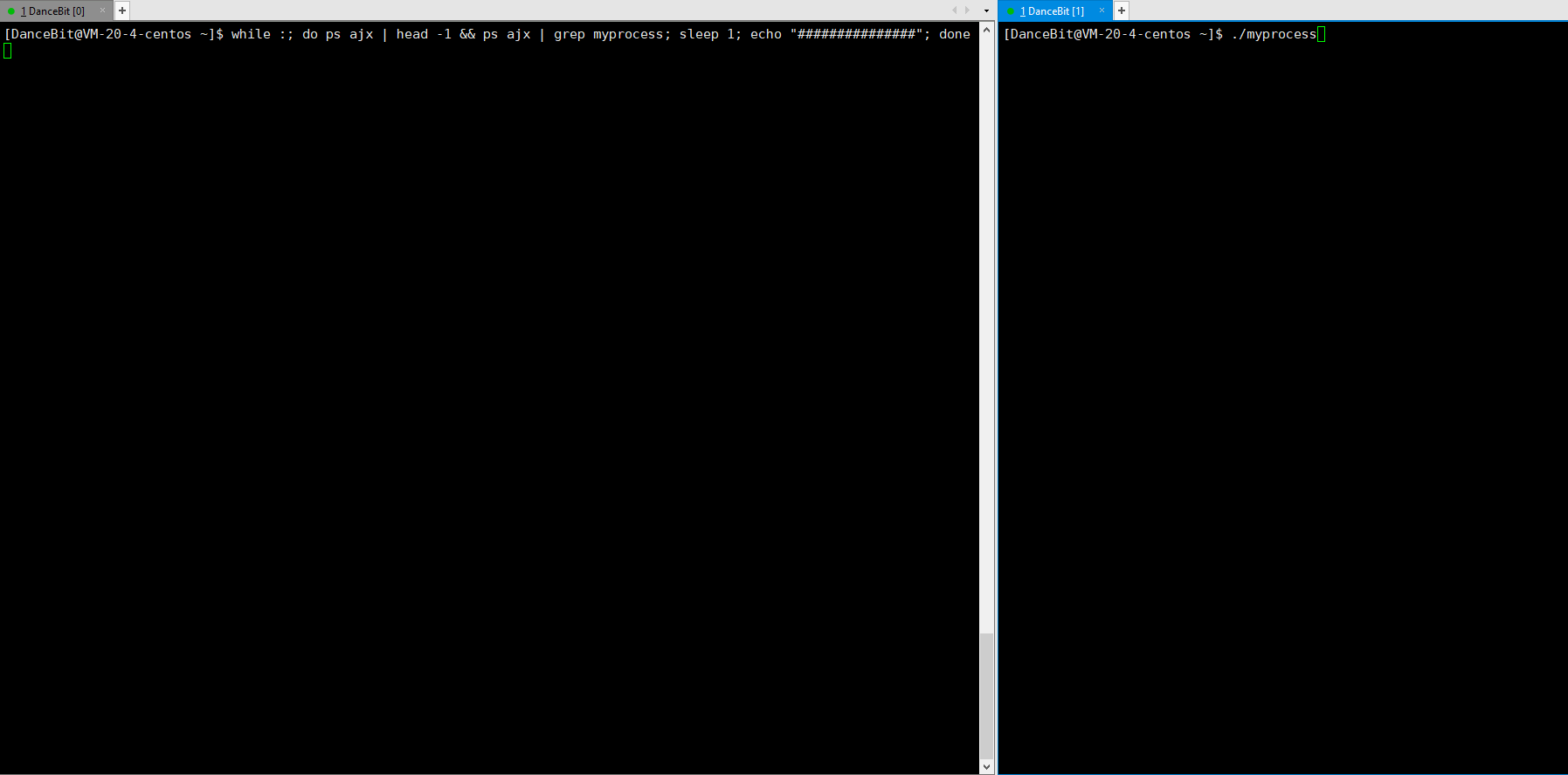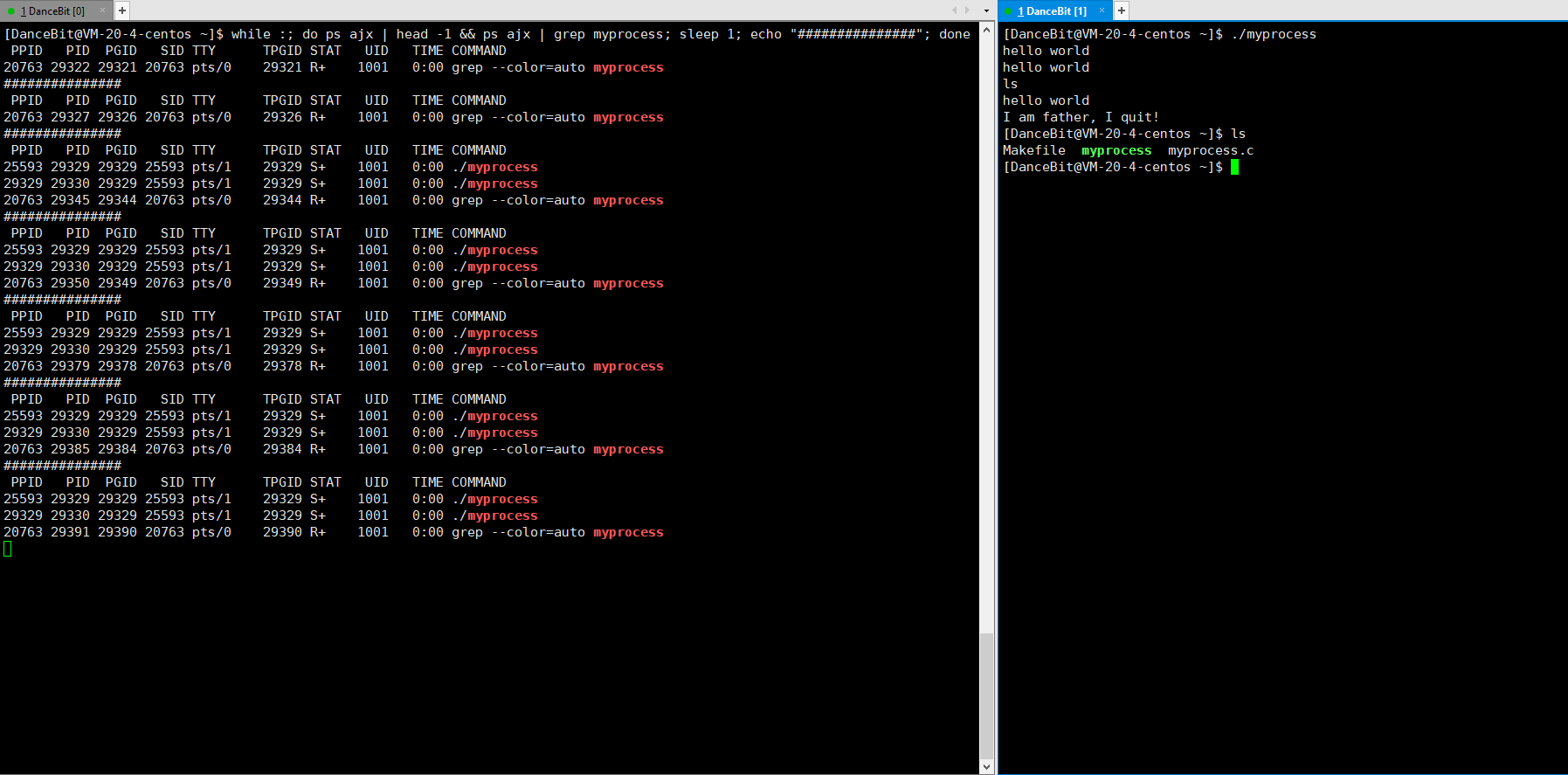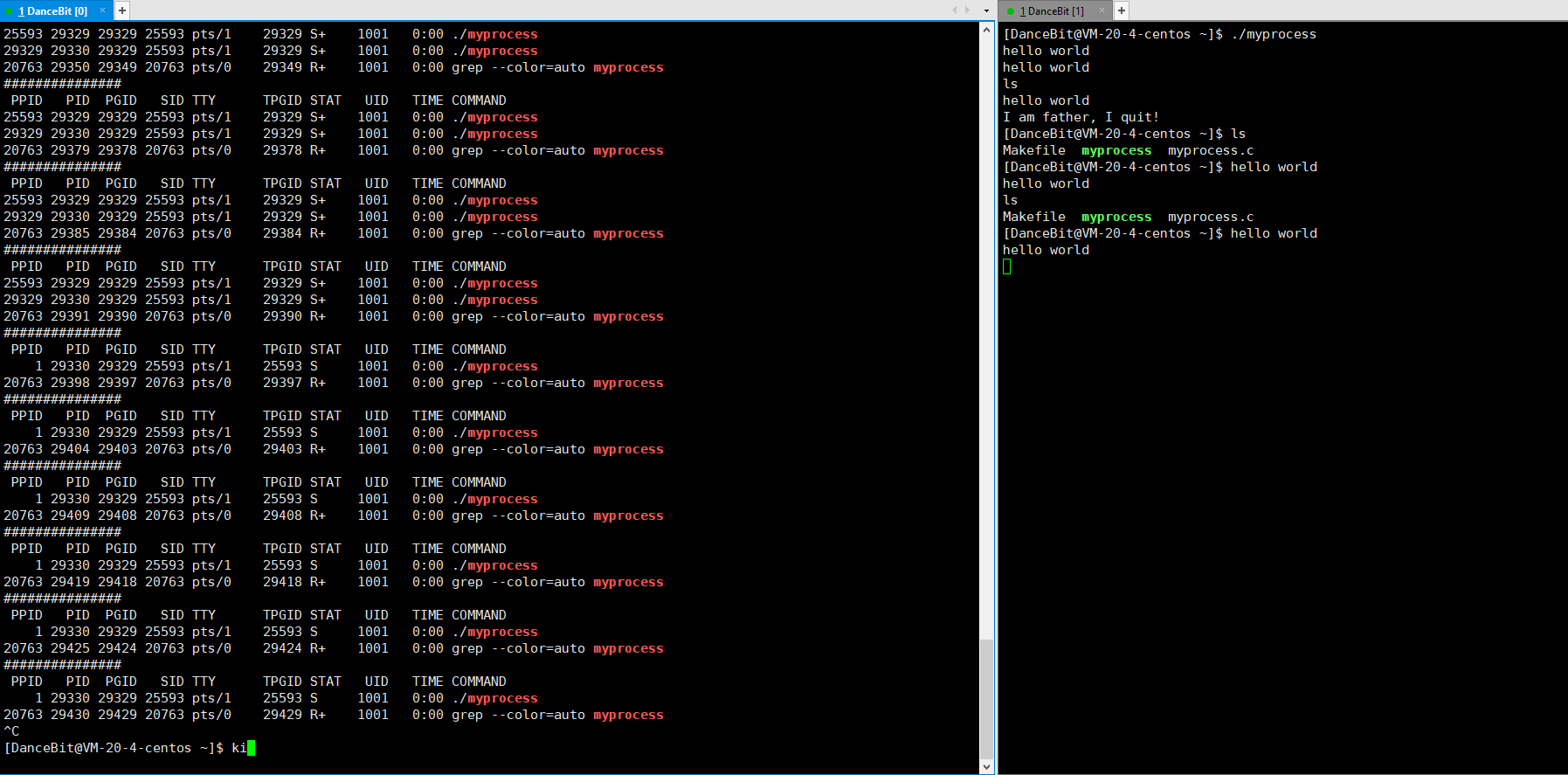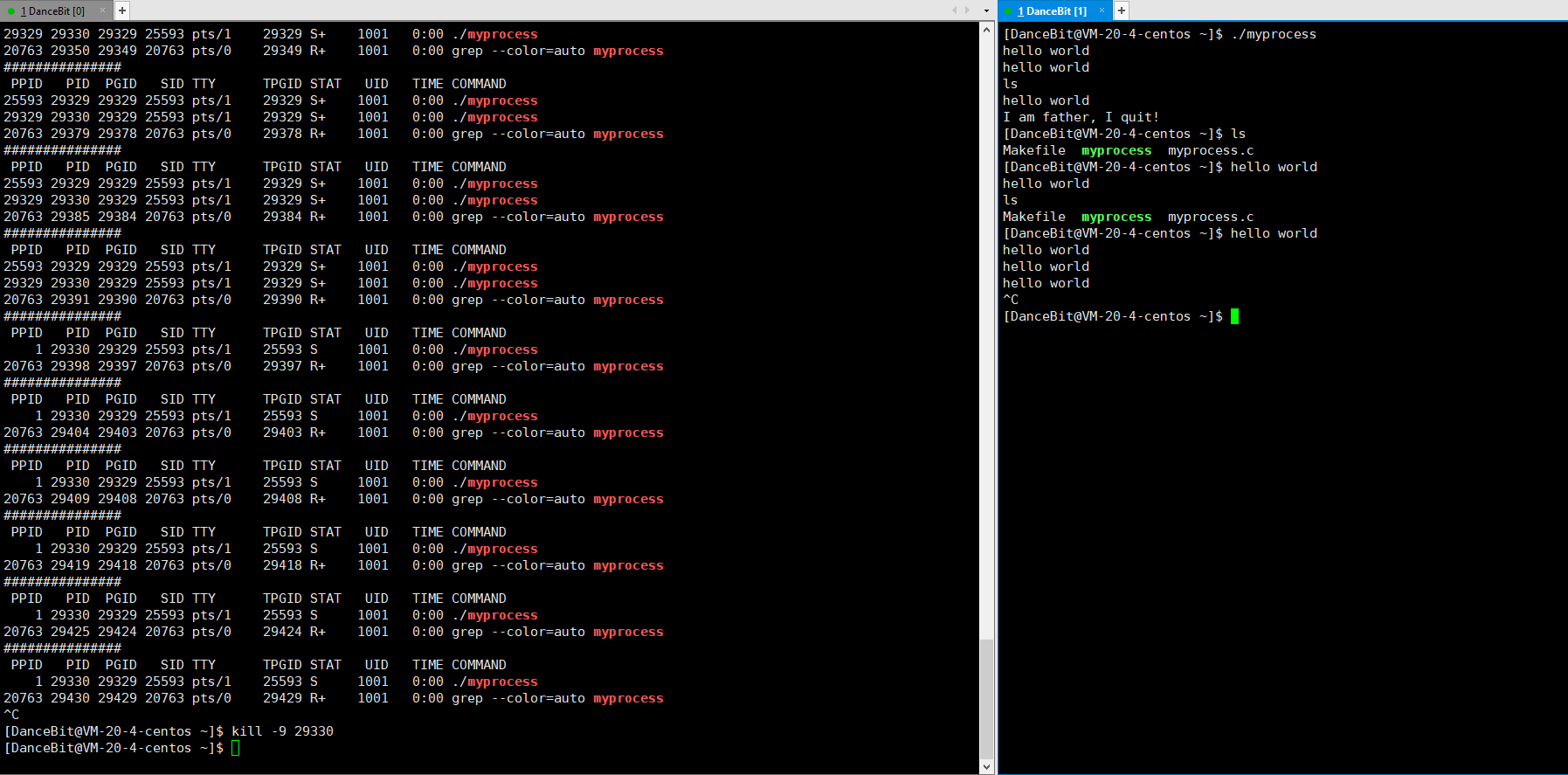
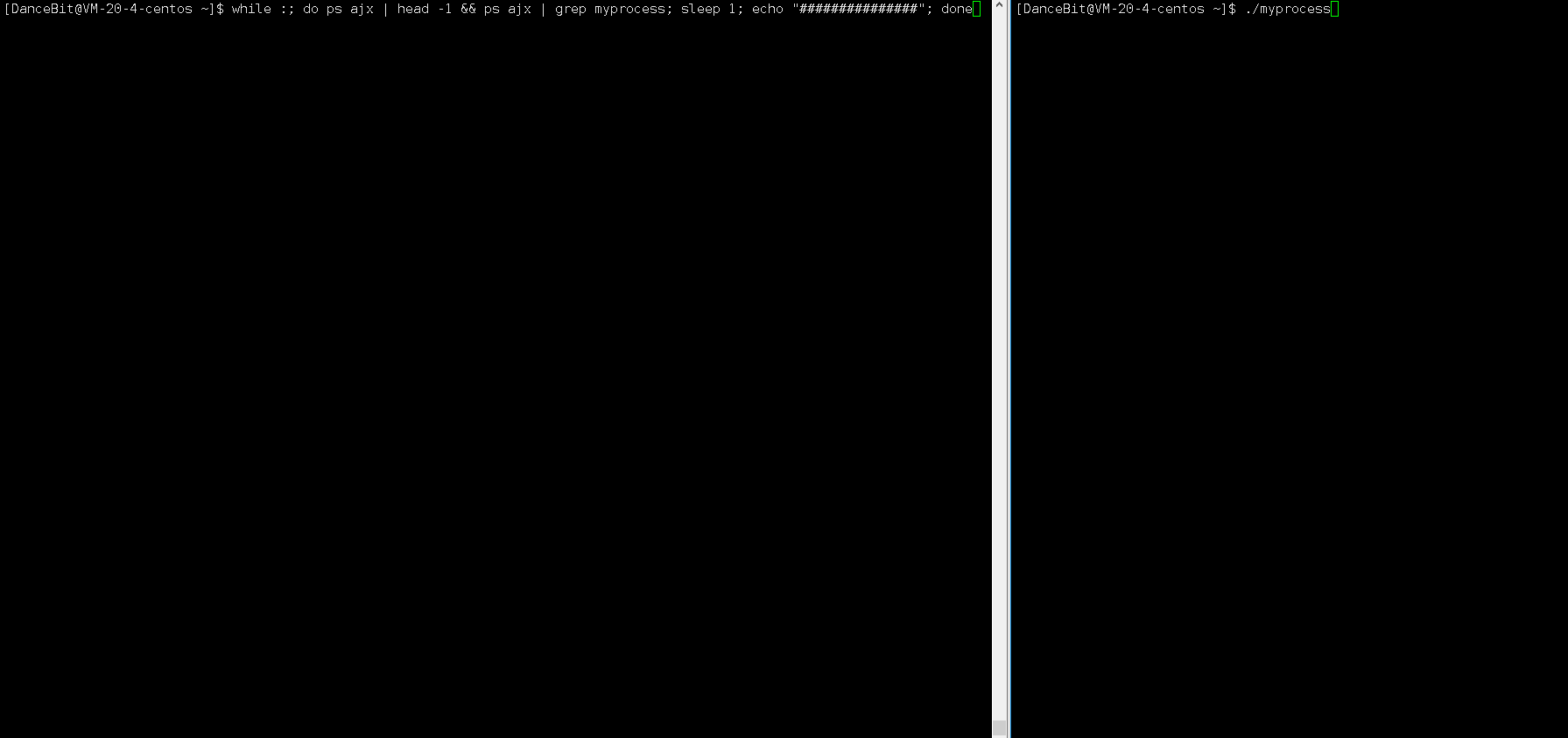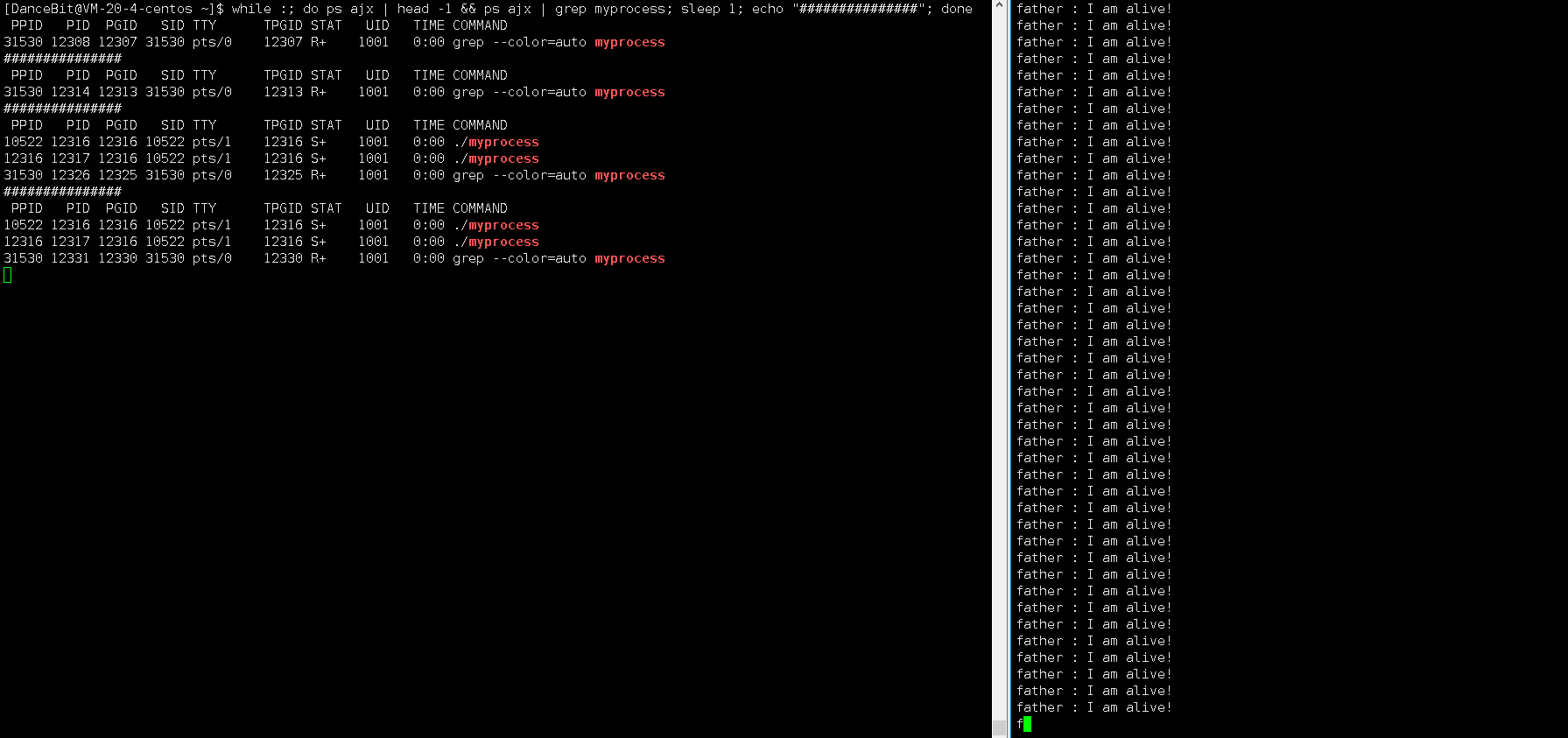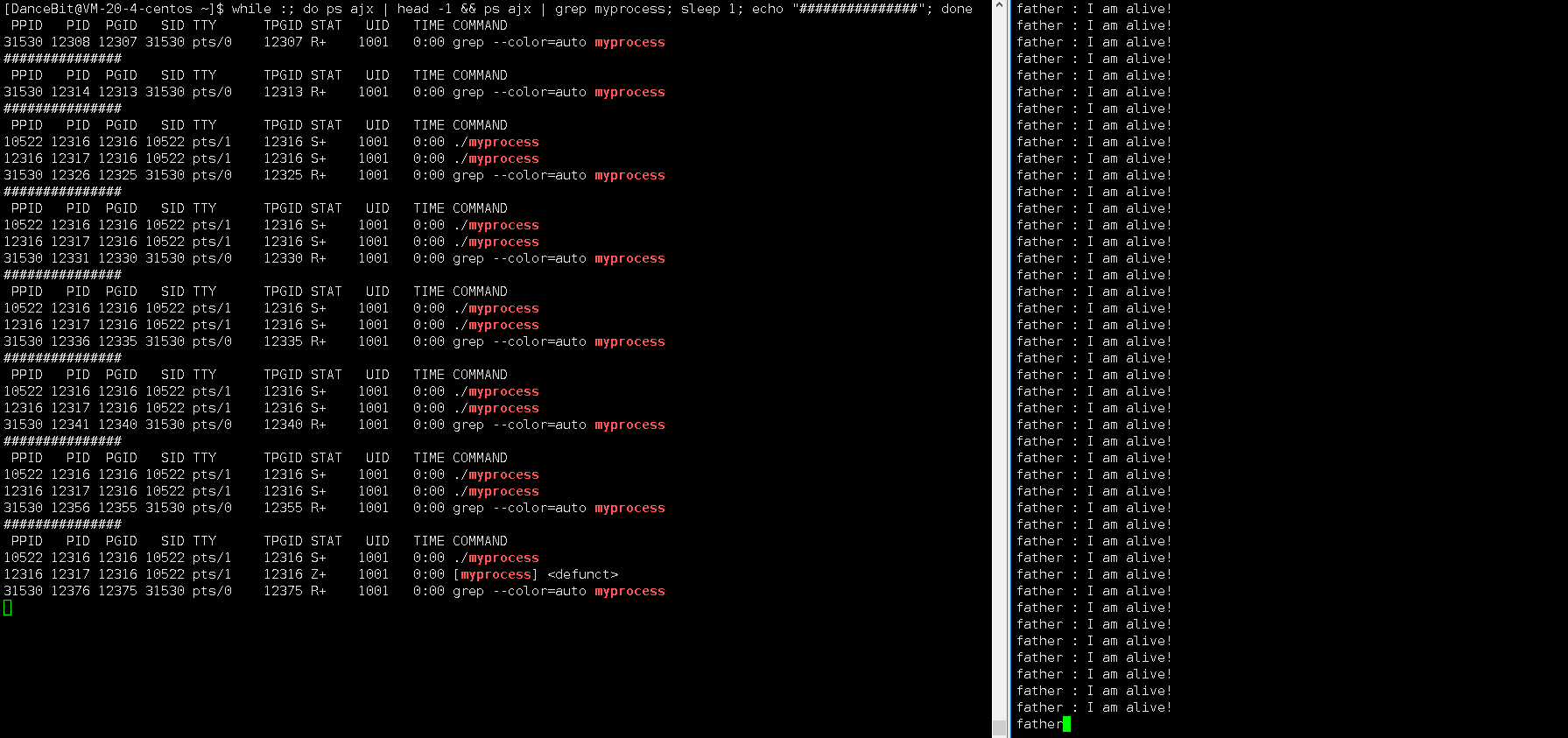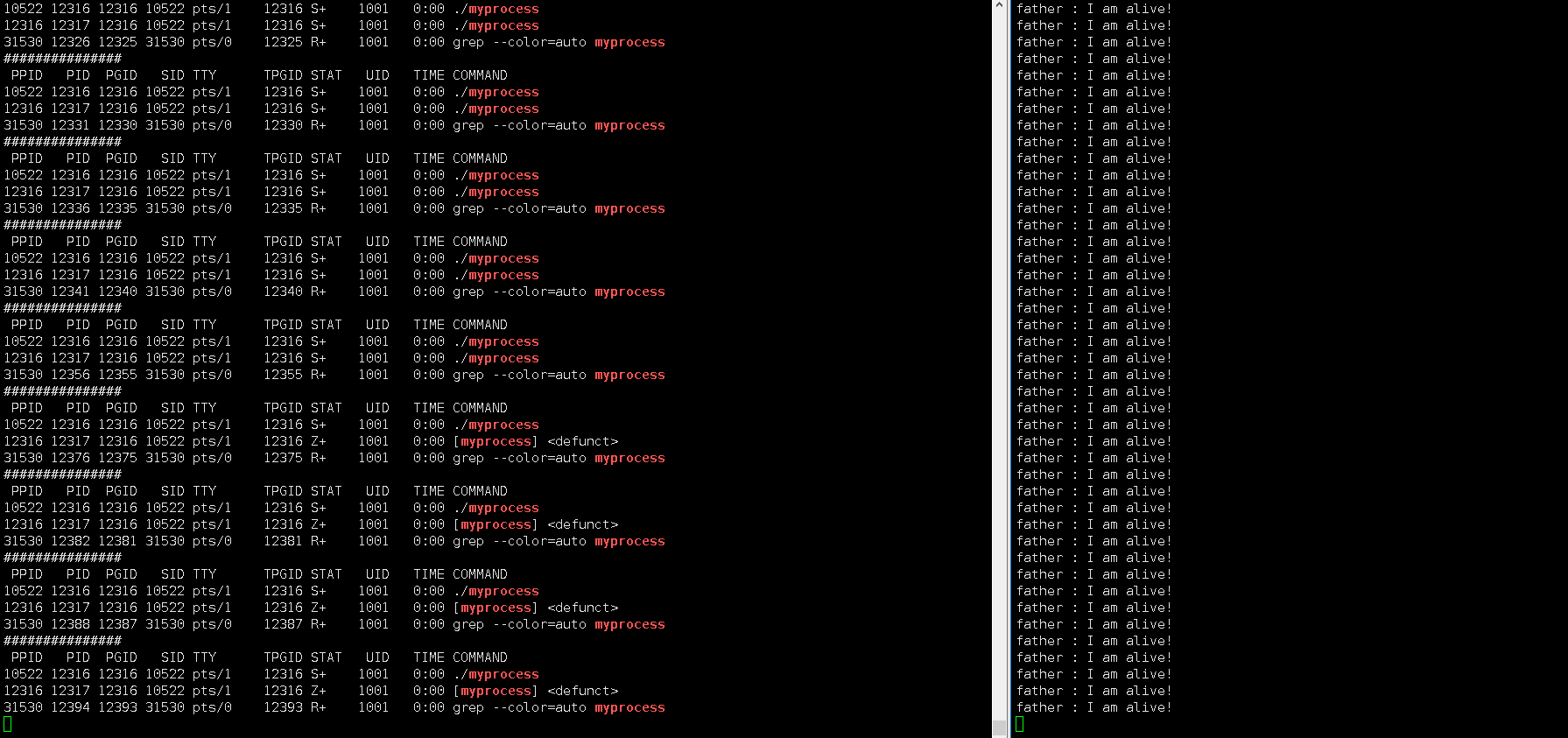
这里我们可以写一个循环执行的监控脚本 while :; do ps ajx | head -1 && ps ajx | grep myprocess; sleep 1; echo"######"; done 来观测:
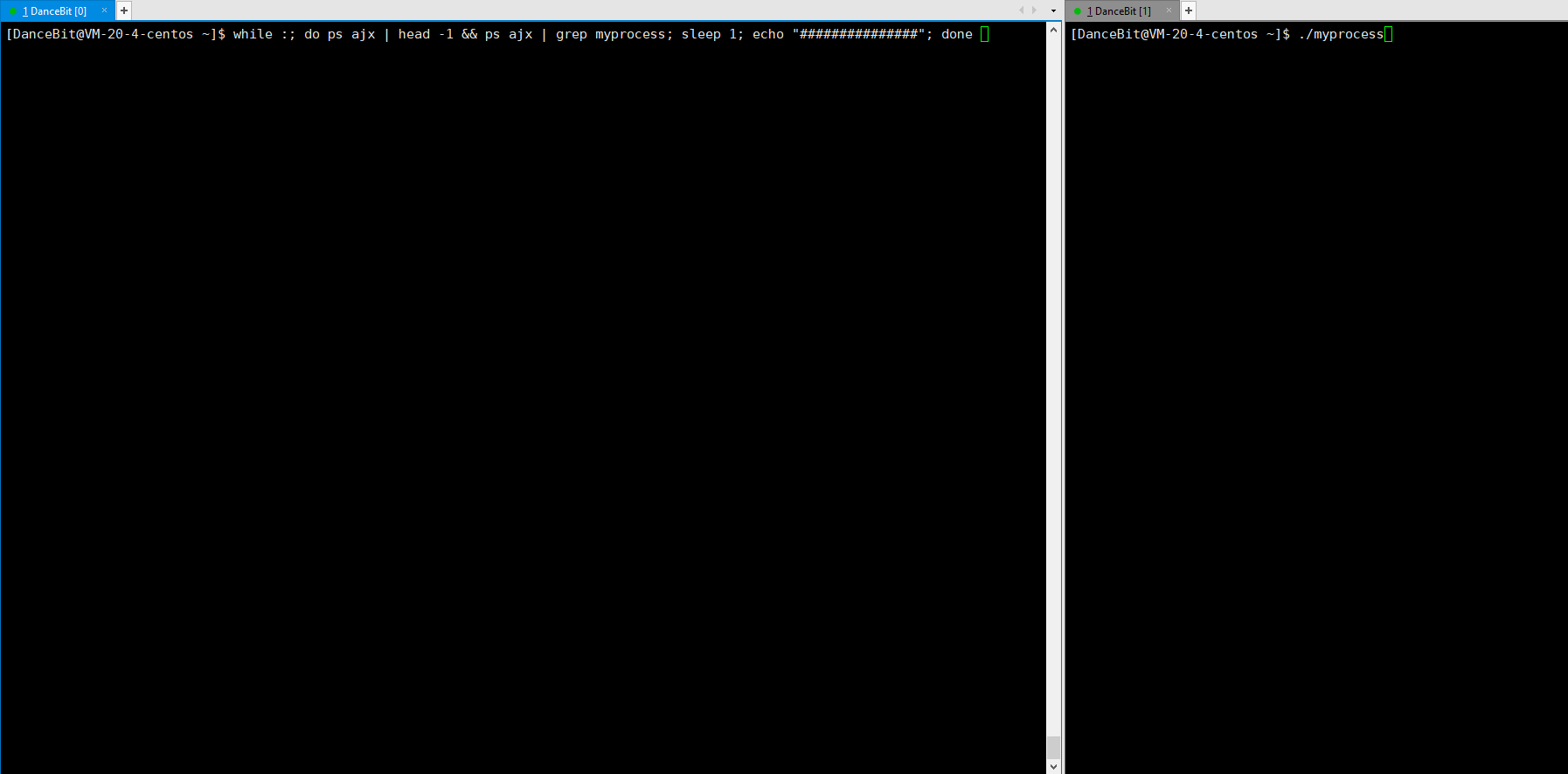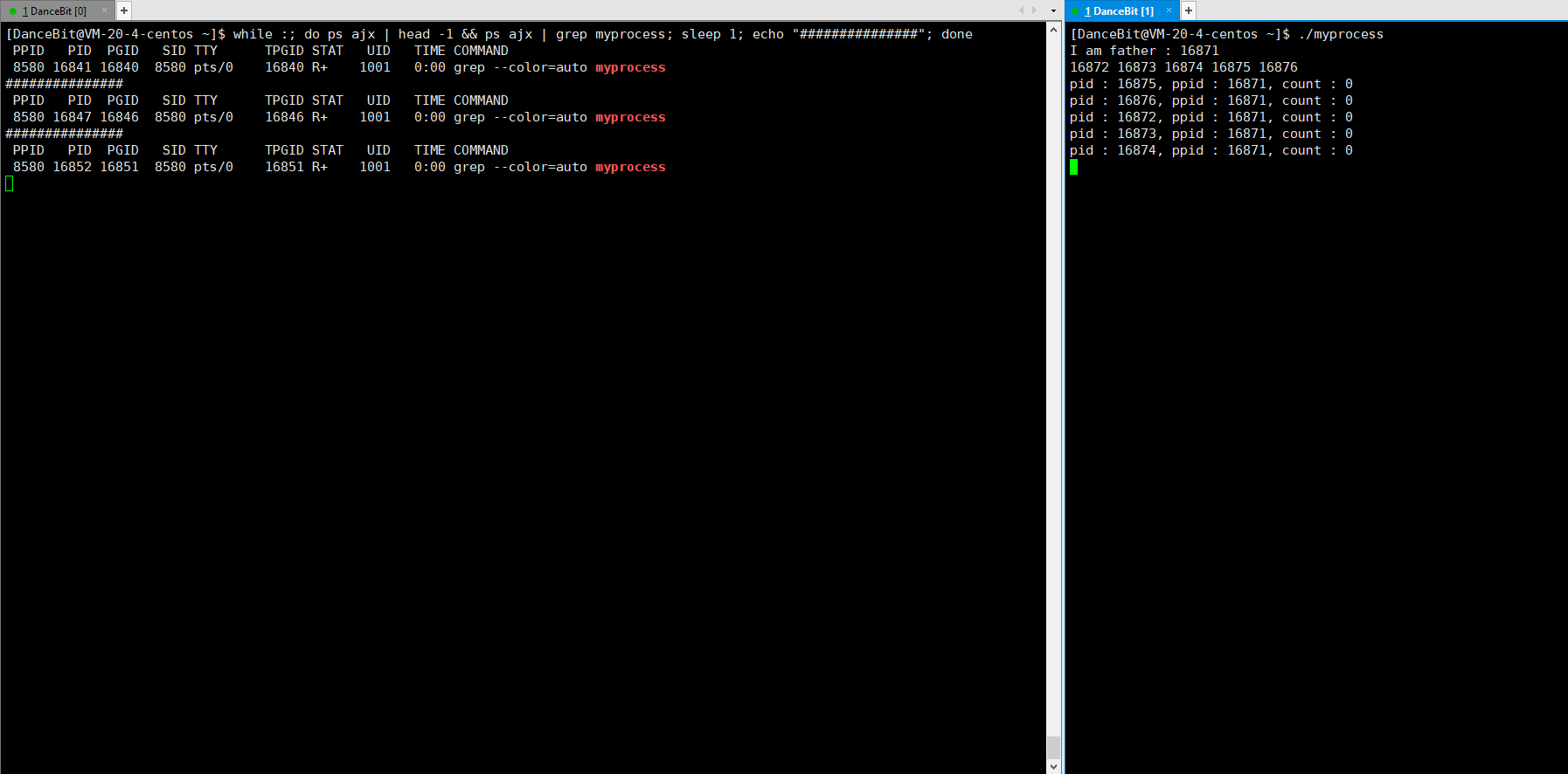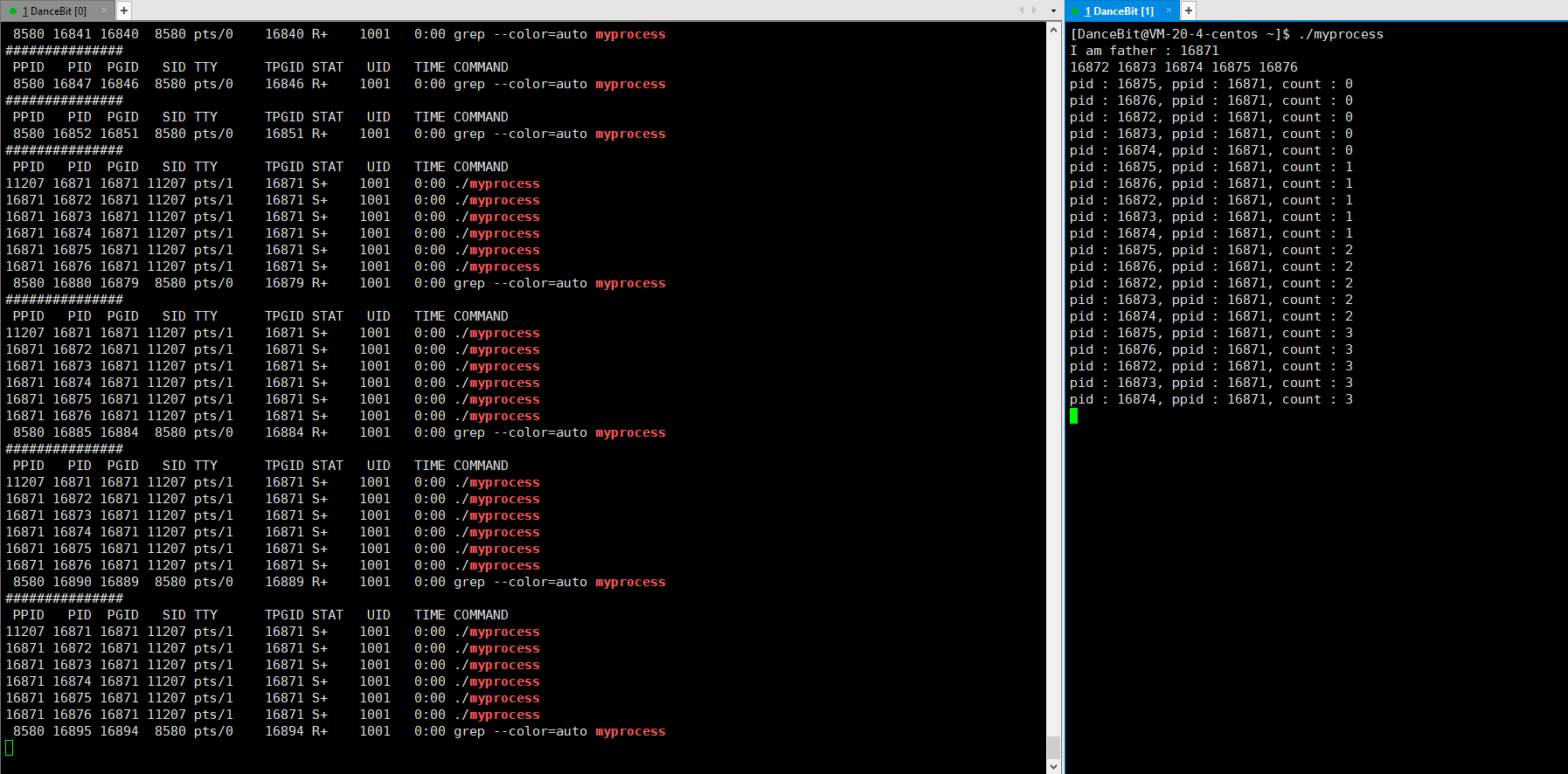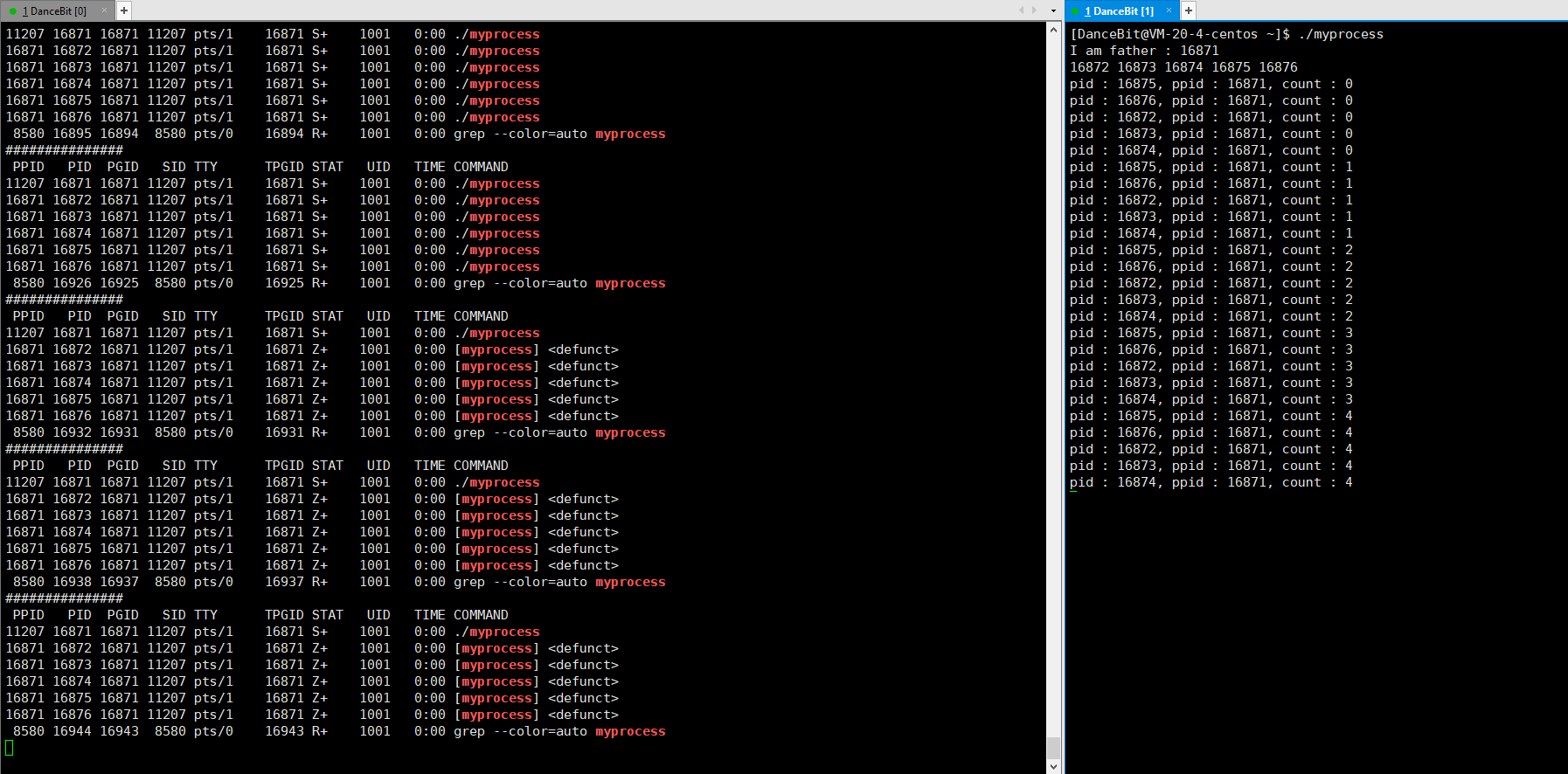
当我们运行脚本时,发现只有脚本这个进程再运行,运行 myprocess 时,一瞬间就有 6 个进程运行,其中包含 1 个父进程,和 5 个子进程,它们都处于浅度休眠。当所有子进程都 exit 后,父进程也来到了 getchar,此时父进程再等待,而子进程还没有被回收,所以 5 个子进程都处于僵尸状态。
8、X (dead)
这里回车让父进程执行 getchar,所以父进程不再等待,操作系统就回收了所有进程 (1 个父进程和 5 个子进程),因为它是一瞬间的,所以我们看不到 X 状态。
💦、补充说明
1、 S and S+
一般在命令行上,如果是一个前台进程,那么它运行时的状态后会跟 +。前台进程一旦执行,bash 就无法进行命令行解释,ls、top 等命令都无法在当前命令行上执行,只有 Ctrl + C 可以进行终止。

如果想把一个进程放在后台可以 ./myprocess &,此时 bash 就可以进行命令行解释,ls、pwd 等命令就可以执行了,此外 CTRL + C 也无法对后台进程终止了,只能对该进程发送第 9 号信号来结束进程。
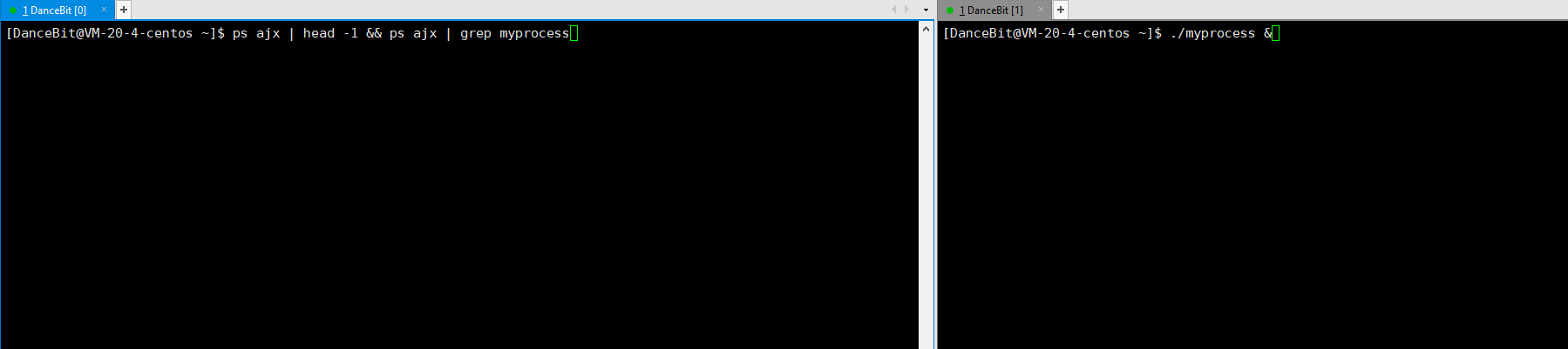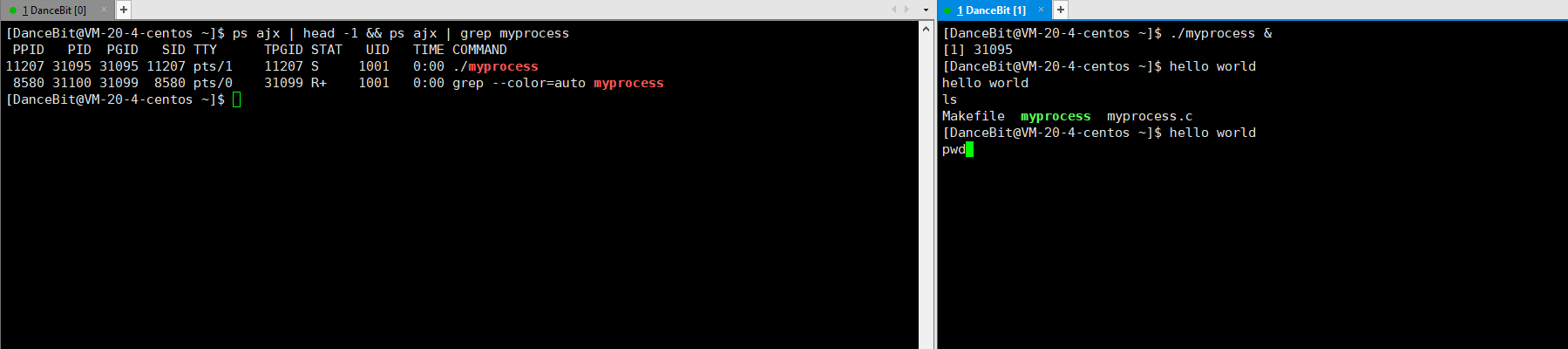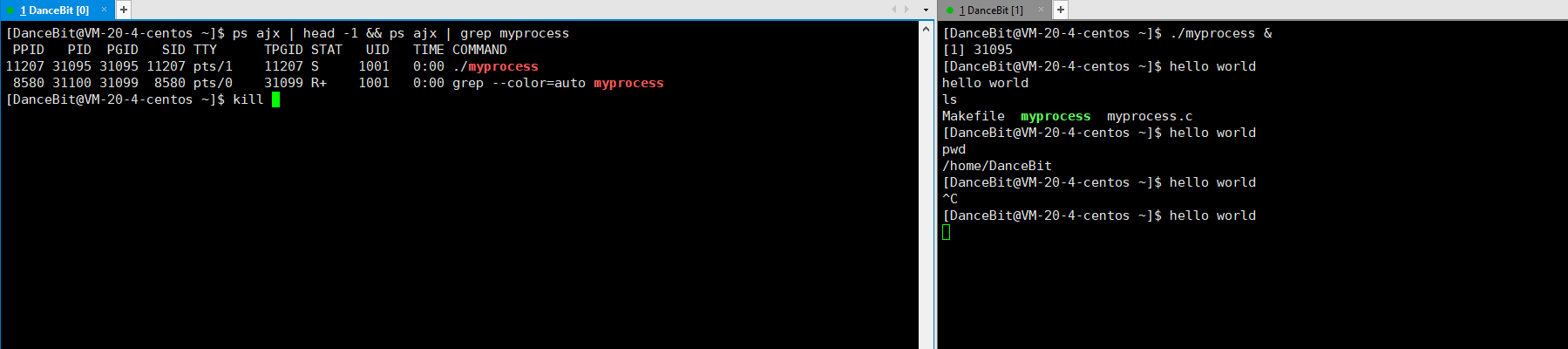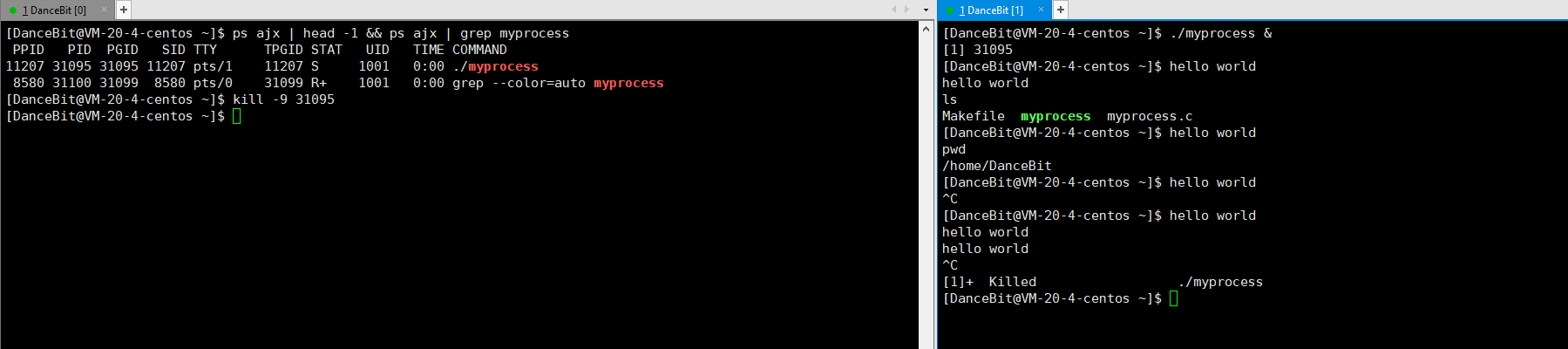
2、 OS 描述的状态 && 具体的 Linux 进程状态
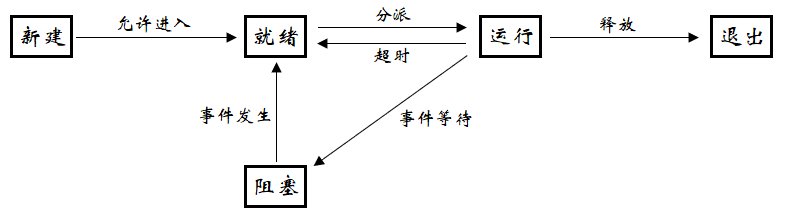
其中新建没有对应的 Linux 进程状态;就绪可对应到 Linux 进程中的 R;运行也可对应到 Linux 进程中的中的 R;退出可对应到 Linux 进程中的 Z/X;阻塞可对应到 Linux 进程中的 S/D/T;
所以 Linux 状态的实现和操作系统的实现是有点差别的。操作系统的所描述的概念是所有操作系统都遵守这样的规则,而 Linux 就是一种具体的操作系统规则。
3、僵尸进程的危害
-
进程的退出状态必须被维持下去,因为它要告诉关心它的进程 (父进程),你交给我的任务,我办的怎么样了。可父进程如果一直不读取,那子进程就一直处于 Z 状态。
-
维护退出状态本身就是要用数据维护,也属于进程基本信息,所以保存在 task_struct (PCB) 中,换句话说,Z 状态一直不退出,PCB 一直都要维护。
-
那一个父进程创建了很多子进程,就是不回收,就会造成内存资源的浪费,因为数据结构对象本身就要占用内存,想想 C 中定义一个结构体变量 (对象),就是要在内存的某个位置进行开辟空间。
-
内存泄漏。
-
如何避免,后面再谈。
4、孤儿进程
父进程如果先子进程退出,那么子进程就是 孤儿进程,那么子进程退出,进入 Z 之后,又该怎么处理 ❓
可以看到 5 秒前有 2 个进程,5 秒后父进程死亡了,只有 1 个子进程 (父进程没有被僵尸的原因是因为父进程也有父进程 25593 -> bash,父进程退出后就被 bash 回收了)。这里 29330 就为孤儿进程,此时孤儿进程会被 1 号进程 领养,它是 systemd (操作系统),被领养后进程状态会由前台转换为后台,后台进程可以使用第 9 号信号来结束进程,此时操作系统就可以直接对它回收资源。
5、1 号进程
操作系统启动之前是有 0 号进程 的,只不过完全启动成功后,0 号进程就被 1 号进程取代了,具体的取代方案,后面学习 进程替换 时再谈。可以看到 pid 排名靠前的进程都是由 root 来启动的。注意在 Centos7.6 下,它的 1 号进程叫做 systemd,而 Centos6.5 下,它的 1 号进程叫做 initd。
四、Linux 系统中的优先级
基本概念
优先级是得到某种资源的先后顺序;权限是你能否得到某种资源;
优先级存在的原因是因为资源有限;
PRI and NI
ps -al 查看当前进程 PRI 和 NI:

-
PRI 比较好理解,即进程的优先级,或者通俗点说就是程序被 CPU 执行的先后顺序,此值越小,进程的优先级别越高。
-
NI 就是我们所要说的 nice 值了,其表示进程可被执行的优先级的修正数值。
饥饿问题 ❓
Linux 中的优先级由 pri 和 nice 值共同确定。Linux 优先级的特点,对于普通进程,优先级的数值越小,优先级越高;优先级的数值越大,优先级越低。但是优先级不可能一味的高,也不可能一味的低,比如说优先级最高的是 30,最低的是 99,那么我们不可以把最高搞成 -300,最低搞成 999。为啥优先级能设置,但不能很夸张的设置,是因为即使再怎么优先,操作系统的调度器也要适度的考虑公平问题,比如我把 A 进程优先级搞到 -300,对我来讲,A 进程老是得到资源,别人长时间得不到资源,这种就叫 饥饿问题。好比你在打饭窗口排着队呢,老是有些人觉得自己优先级高往前插队,那么你就长时间打不到饭,导致最后吃不到饭。所以 CPU 也是有度的来根据优先级调度。
其中 pri 的优先级是多少就是多少,但实际上 Linux 的优先级是可以被修正的,nice 值就是优先级的修正数据 [-20 ~ 19],一共 40 个级别,其中 -20 优先级最高,19 优先级最低。也就是说想修改某进程的优先级,就要设置 nice 值,而后这个进程的优先级就会重新被计算。
-
PRI 值越小越快被执行,那么加入 nice 值后,将会使得 PRI 变为:
PRI (new) = PRI (old) + nice,这里的 old 永远是 80,下面解释。 -
调整进程优先级,在 Linux 下,就是调整进程 nice 值。需要强调的是,进程的 nice 值不是进程的优先级,他们不是一个概念,但是进程 nice 值会影响到进程的优先级变化。可以理解 nice 值是进程优先级的修正数据
-
PID 是当前进程的专属标识;PPID 是当前进程的父进程的专属标识;TTY 可以理解为终端设备;CMD 是当前进程的命令。
-
UID 是执行者的身份。
ll 后,其中可以看到我:

ll -n,就可以看到我的 ID:
也就是说在 Linux 中标识一个用户,并不是通过用户名 DanceBit,而是通过用户的 UID 1001。比如 qq 里,每人都有一个昵称,如果昵称可以随便改的话,就意味着昵称不是标识你的唯一方式,而是通过 qq 号码来唯一标识你。所以对于操作系统来说,当你新建用户时,除了你自己给自己起的名称之外,还有操作系统所分配给你的 UID。原因是因为计算机比较擅于处理数据

所以可以看到这里的进程是我启动的:

调整优先级
ps -al 查看当前进程优先级:

top 命令查看所有进程相关信息:
r 命令后输入要调整的 pid:
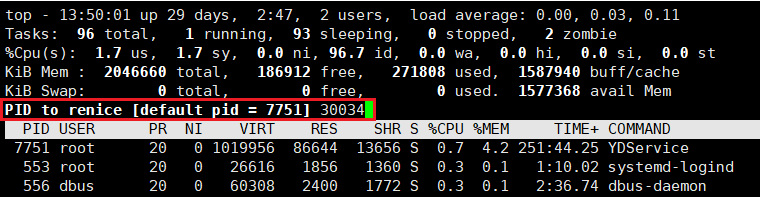
给 30034 进程 Renice 要调整的 nice 值:
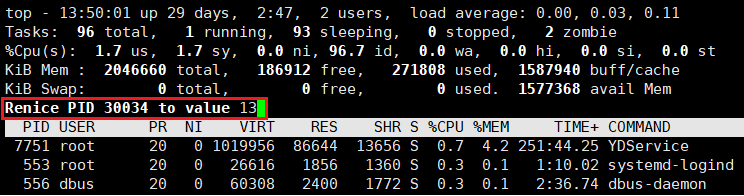
q 退出 top,然后 ps -al 验证:

继续调整时,它不让我调了:
sudo top 提升权限进行调整:
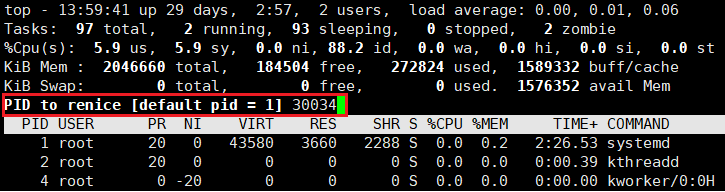
q 退出 top,然后 ps -al 验证:

之前第一次调整后的优先级是 93,随后第二次调整后的优先级应该是 103,但是却是 90 ❓
其中我们在 Linux 中进行优先级调整时,pri 永远是默认的 80,也就是说即使你曾经调整过 nice 值,当你再次调整 nice 值时,你的优先级依旧是从 80 开始的,也就是说 PRI (new) = PRI (old) + nice 中的 old 永远是 80,这里这样设计的原因下面会解释,我们继续往下走。
上面说每次调整优先级永远是从 80 开始,上面又说 nice 值的最小值是 -20,最大值是 19,这意味着 nice 值是 -100,不会真正的设置到 -100,而是设置成了 nice 值的最小值 -20:
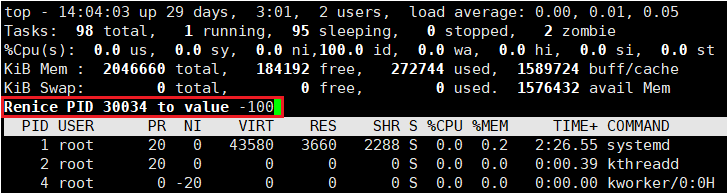
ps -al 验证:我们发现最小的 nice 值就是 -20,而它的优先级最高只能到 60

继续往下走,瞅瞅它的优先级最低是多少:尽管我们设置的 nice 值是 1000,但不会真的设置到 1000,而是设置到 nice 值的最大值 19,所以此时调整后的优先级是 99。
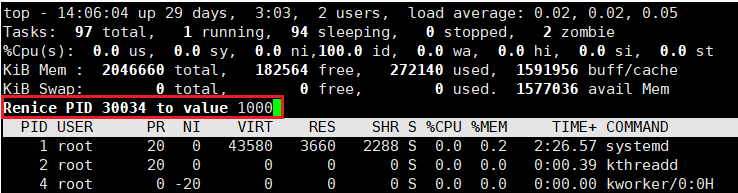
ps -al 验证:我们发现最大的 nice 值就是 19,而它的优先级最高只能到 99。也就是说 pri 的取值区间是 [60, 99]。

每次我们重新计算新的优先级时, old 为啥默认都是 80 ❓
其一,有一个基准值,方便调整。你都想调整了,意味着你不想要老的优先级,那么我给你一个基准点,下次就方便许多了,否则你每次调整之前,还得先查一下当前进程现在的优先级。
其二,大佬并不想让我们对一个进程的优先级设置的很高或很低,用户可能会钻空子,比如每次设置 1,不断叠加,让优先级越来越低,但是显然人家考虑到了,所以每次设置时,pri 又都会默认从 80 开始,old 每次都是 80,同时 nice 值区间是 [-20, 19],最终你的优先级区间 [60, 99],这样的设计,成本不高。
nice 值是 [-20, 19],意味着当前的 nice 值是一种可控状态,为啥 ❓
也就意味着这个值,你可以往大了设置,也可以往小了设置,但始终不会超过这个区间。进程是被操作系统调度的,如果可以让一个用户按他的需求去定制当前进程的优先级,比如我把我的进程优先级搞成 1,其它进程优先级搞成 10000,那么这样调度器就没有公平可言了。就是说操作系统可以让用户调整优先级,但是优先级必须是可控状态,因为不可控,就没有公平高效可言了。就像你妈让你出去玩,但规定你必须 8 点钟回来。所以本质是操作系统中的调度器要 公平 且 较高效的调度,这是基本原则。
调度器的公平 ❓
这里不是指平均。有多个进程,不是说我现在给你调度了 5 毫秒,就一定要给其它进程都调度 5 毫秒。而必须得结合当前进程的特性去进行公平调度的算法。所以这里的公平可以理解为我们是尽量的给每个进程尽快、尽好的调度,尽量不落下任何一个进程,但并不保证我们在同一时间上启动的所有进程在调度时间上完全一样,而只能说是大致一样,因为调度器是服务计算机上所有进程的。
【写在后面】
-
可以看到 Linux 它的进程状态,一会僵尸,一会孤儿,感觉 Linux 操作系统很惨的样子。实际上后面我们还会再学一种
守护进程 (精灵进程)。 -
如果一个进程是 D 状态是不能 kill -9 的;但如果一个进程是 Z 状态,那么它能 kill -9 吗 ❓
如果一个人已经死了,你上去踢它两脚,有用吗 ?所以一个进程是 Z 状态,你去 kill 它是杀不掉的。
- [ 面试题 ]:什么样的进程杀不死 ❓
D 状态进程和 Z 状态进程。因为一个是在深度休眠,操作系统都得叫大哥,一个是已经死了。
-
并行:多个进程在多个 CPU 下分别,同时运行,这称之为并行。
-
并发:多个进程在一个 CPU 下采用进程切换的方式,在一段时间内,让多个进程都得以推进,这称之为并发。
-
独立性:多进程运行,需要独享各种资源,多进程运行期间互不干扰。独立性也是操作系统设计进程的一个原则,不管你是 Linux、Windows、Macos、Android 都需要遵守,代码共享,数据各自私有就是为了实现独立性原则。
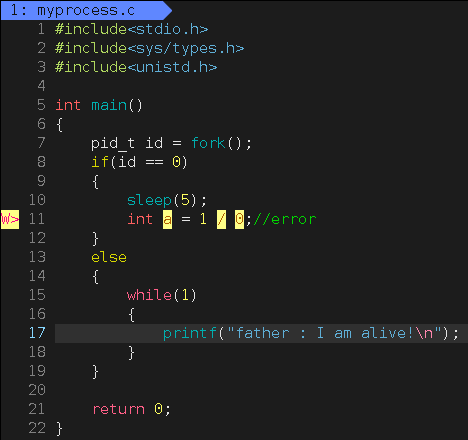
注意这里的除 0 操作在 vs 下是直接编译不过的,也不会执行 sleep。但在 linux 下可心编译过,也会执行 sleep。这里子进程等 5 秒后执行除 0 错误后一定会退出,此时子进程就变成了僵尸,且不会影响父进程执行。
- 竞争性:系统进程数目众多,而 CPU 资源少,所以进程之间是具有竞争属性的。为了高效完成任务,更合理竞争相关资源,便具有了优先级。你现在为什么正在看我的文章呢,根本原因就是因为社会大环境里需要竞争,而你需要提升自己的竞争力和优先级。
【Linux 进程概念 —— 下】验证进程地址空间的基本排布 | 理解进程地址空间 | 进程地址空间如何映射至物理内存 (页表的引出) | 为什么要存在进程地址空间 | Linux2.6 内核进程调度队列
跳动的 bit 已于 2023-08-01 08:51:42 修改
【写在前面】
本文中会介绍很多结构化的知识,我们会通过很多例子里的角色和场景来对一个概念进行定位和阐述,让大家有一个宏观的认识,之后再循序渐进的填充细节,如果你一上来就玩页表怎么映射,那么你可能连页表存在的价值是什么都不知道,最后也只是竹篮打水。
一、回顾与纠正
C/C++ 内存布局这个概念比较重要,之前我们也涉及过 —— 我们在语言上定义的各种变量等在内存中的分布情况,如果没有听说过,那么你的 C/C++ 是不可能学好的。

上图表示的是内存吗 ❓
其实我们曾经在语言中说过的 C/C++ 内存布局,严格来说是错误的,从今天开始我们应该称之为 C/C++ 进程地址空间。为啥要故意说错呢,其实是因为方便理解,如果当时说 C/C++ 进程地址空间,那么不谈进程、地址、空间,就很容易误导大家。也就是说实际上要真正理解 C/C++ 的空间布局,光学习语言是远远不够的,还需要学习系统以及进程和内存之间的关系。
进程地址空间既然不是内存,那么栈、堆等这些空间的数据存储在哪 ???
进程地址空间,会在进程的整个生命周期一直存在,直到进程退出,这也就解释了为什么全局变量具有全局属性。其实这些数据最后一定会存储于内存,只不过进程地址空间是需要经过某种转换才到物理内存的。
上图的共享区 / 内存映射段会在进程间通信以及动静态库的时候再去细谈,现在可以简单理解计算机中是有很多动静态库的,而共享区主要用来加载它们。
二、 验证进程地址空间的基本排布
#include <stdio.h>
#include <stdlib.h>
// 全局变量声明
int g_unval; // 全局未初始化,故意与全局初始化写反
int g_val = 100; // 全局初始化变量
int main(int argc, char* argv[], char* env[]) {
// 以下由低地址到高地址分别验证,除了栈
// 打印代码段地址
printf("code addr: %p\n", main); // 对于一个函数的地址,main 同 &main
// 打印只读数据段地址
const char* p = "hello bit!";
printf("read only: %p\n", p); // p 就是字符串的首地址
// 打印静态全局变量地址
static int a = 5;
printf("static global val: %p\n", &a); // static 后局部变量的存储地方就由栈变为数据段
// 打印全局变量地址
printf("global val: %p\n", &g_val);
printf("global uninit val: %p\n", &g_unval);
// 打印堆区地址
char* q1 = (char*)malloc(10);
char* q2 = (char*)malloc(10);
printf("heap addr: %p\n", q1); // 栈区的地址 &q1 会指向堆区的 q1
printf("heap addr: %p\n", q2);
// 打印栈区地址
printf("p stack addr: %p\n", &p);
printf("q1 stack addr: %p\n", &q1);
// 打印参数地址
printf("args addr: %p\n", argv[0]); // 数组的第一个元素
printf("args addr: %p\n", argv[argc - 1]); // 数组的最后一个元素
// 打印环境变量地址
printf("env addr: %p\n", env[0]);
// 释放堆区分配的内存
free(q1);
free(q2);
return 0;
}


args 的地址是一样的,根本原因是 ./checkarea 时只有一个命令行参数,如果加上选项那么就不一样了:

三、 进程地址空间
虚拟地址
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int g_val = 0; // 全局变量
int main() {
printf("begin......%d\n", g_val);
pid_t id = fork(); // 创建子进程
if (id == 0) {
// 子进程逻辑
int count = 0;
while (1) {
printf("child pid: %d, ppid: %d, [g_val: %d][&g_val: %p]\n",
getpid(), getppid(), g_val, (void*)&g_val);
sleep(1); // 每秒打印一次
count++;
if (count == 5) {
g_val = 100; // 修改全局变量
}
}
} else if (id > 0) {
// 父进程逻辑
while (1) {
printf("father pid: %d, ppid: %d, [g_val: %d][&g_val: %p]\n",
getpid(), getppid(), g_val, (void*)&g_val);
sleep(1); // 每秒打印一次
}
} else {
// 错误处理(fork失败)
// TODO: 添加错误处理逻辑
}
return 0;
}


根据我们现有的知识,无可厚非的是前 5 次父子进程的 g_val 的值是一样的,且地址也一样,因为我们没有修改 g_val, 5 次后,子进程把 g_val 的值改了之后,父进程依旧是旧值,这个我们一点都不意外,因为 父子共享代码,数据各自私有,后面会站在系统角度讲数据各自私有是 写时拷贝 来完成的,以前我们是在语言层面上了解;但匪夷所思的是 5 次后,父子进程的 g_val 的地址竟然也是一样的。
推导和猜测???
从上图我们可以知道 &g_val 一定不是物理地址 (真正在内存中的地址),因为同一个物理地址处怎么可能读取到的是不同的值。所以我们断言曾经所看到的任何地址都不是物理地址,而这种地址本质是 虚拟地址,它是由操作系统提供的,那么操作系统一定要有一种方式帮我们把虚拟地址转换为物理地址,因为数据和代码一定在物理内存上存储,这是由冯・诺依曼体系结构规定的。上面说到虚拟地址是由操作系统提供的,我们也说过程序运行起来之后,该程序立即变成进程,那么虚拟地址和进程大概率存在某种关系。
什么是进程地址空间

地址空间在 Linux 内核中是一个 mm_struct 结构体,这个结构体没有告诉我们空间大小,但是它告诉我们空间排布情况,比如 [code_start (0x1000), code_end (0x2000)],其中就会有若干虚拟地址,这是因为操作系统为了把物理内存包裹起来,给每个进程画的一把尺子,这把尺子我们叫进程地址空间。进程地址空间是在进程和物理内存之间的一个软件层,它通过 mm_struct 这样的结构体来模拟,让操作系统给进程 画大饼,每一个进程可以根据地址空间来划分自己的代码。
所以我们再回顾:进程地址空间当然不是物理内存,它本质只是操作系统让进程看待物理内存的方式,其中 Linux 内核中是用 mm_struct 数据结构来表示的,这样的话每个进程都认为自己独占系统内存资源 (好比每个老婆都认为自己独占 10 亿);区域划分的本质是将线性地址空间划分成为一个一个的区域 [start, end];而所谓的虚拟地址本质是在 [start, end] 之间的各个地址。
看看源码中怎么写 ❓


页表

进程地址空间如何映射至物理内存这就引出了页表,页表的结构是 b 树,目前不打算深入它。假设存在三个进程 A B C,操作系统就会给每一个进程画一张大饼,叫做当前进程的虚拟地址空间,其中会通过指针将进程和虚拟地址空间关联起来。运行进程 A,就要把进程 A 加载到物理内存中,其中操作系统会给每一个进程创建一张独立的页表结构,我们称之为 用户级页表,当然后面还有 内核级页表,而页表构建的就是从地址空间中出来的虚拟地址到物理地址中的映射,每个进程都通过页表来维护进程地址空间和物理内存之间的关系,这是页表的核心工作,所以进程就可以根据页表的映射访问物理内存。当然单纯一张页表是不可能完成映射的,还要配合某些硬件,以后会谈。
能否把进程 A 中的代码和数据加载到物理内存中的任意位置 ❓
在不考虑特殊情况下,是可以将进程对应的代码和数据在物理内存的任意位置加载的,因为最终只需要将物理内存上的代码和数据与页表建立映射关系,就可以通过虚拟地址找到物理地址。所以进程中的代码和数据是能够加载到物理内存中的任意位置的,其中本质是通过页表去完成的。
多个进程之间会互相干扰吗,不同的进程它们的虚拟地址可以一样吗 ❓
同样进程 B 也可以通过页表把代码和数据加载到物理内存的任意位置,就算不同的进程的虚拟地址完全一样也没问题,因为不同进程通过一样的虚拟地址查的是不同的页表,其中的工作细节是由页表去完成的,这也解释了上面为啥两个进程虚拟地址一样却不会互相影响。
如果物理地址重址呢 ❓
这是操作系统的代码,一般不可能重址。当然也存在这样的特殊情况,如果进程 B 和进程 C 是父子关系,我们在创建子进程 C 的 PCB、地址空间、页表、建立各种映射关系,把代码区、数据区等区域映射时,只需要将子进程 C 映射到物理内存中父进程的代码和数据处,但当子进程 C 修改数据时,操作系统就会重新申请内存,修改当前进程的指向关系,此时子进程就不再指向父进程的数据了,而让子进程指向新的空间,把旧数据拷贝至新数据,最后再修改数据,此时这就是 写时拷贝。所以不同的页表,物理地址可以重址,只不过这种重址是刻意的,因为父子代码共享。
为什么要存在进程地址空间
- 其实早期操作系统是没有所谓的虚拟地址空间的。如果进程直接访问物理内存,那么我们看到的地址就是物理地址,当我们认识过在 C 语言中有一个概念叫做
指针,那么就能理解有可能会出现:如果进程 A 出现了越界,那么就有可能直接访问到了另一个进程的代码和数据,所以进程的独立性便无法保证。甚至因为物理内存暴露,其中就有可能有恶意程序直接通过物理地址,进行内存数据的篡改。比如说某进程里有帐号和密码的数据,那就有可能会被更改密码,如果操作系统不让改,那也可以进行读取,如果操作系统不想让你读取,操作系统就要实现一些较为困难的权限管理,成本较高。后来大佬对进程和物理内存之间就引出了进程地址空间,其中每一个进程都有自己的地址空间、页表。虚拟地址最终通过页表转换为物理地址,那么页表需要根据实际情况转或不转。好比小时候过年,收到亲戚的压岁钱后,妈妈怕你乱花钱,所以就帮你存起来,当你要买资料时,你妈就帮你支出,但你要买游戏机时,你妈就可以拒绝你。换言之,虚拟地址到物理地址的转换,是由页表完成的,同时也需要进行合法性检测。所以进程地址空间的意义就是保存物理内存,不受任何进程内的地址的直接访问,也方便进行合法性校验;另一方面可以不用在物理内存上找一块连续的区域存储了,减少内存碎片。实际有了地址空间后,以进程的视角看它的代码区,数据区等区域时都是连续的,而真正在物理内存上不一定连续。
- 至此我们认识到地址空间的引入可以保护物理内存。其它情况,越界时不一定报错,比如在栈区越界后还是在栈区,在一个合法区域内,操作系统是有其它机制去检测的,那么既定的 C/C++ 事实是我们在越界时是不一定报错的,因为编译器是以抽查的形式来检测,这里可以去了解一下
金丝雀技术。对于有区域划分的地址空间,你访问数据区,但是因为越界访问了代码区,操作系统就可以根据你曾经区域划分时的[start, end]来确认是否越界。对于页表,它将每个区域映射至物理内存中,页表要进行某种映射级别的权限管理,比如在映射数据区时,物理内存的任意位置都是可以被修改的,否则曾经的数据是怎么被加载的;但在映射代码区后,你有任何的写入操作时,操作系统发现对应页表你只有r权限,一旦写了,操作系统就终止你的进程。我们都知道如下这种字符串是在代码区存储,代码区是只读的,所以你要修改它,在 Linux 下报的是段错误,在 VS 下报的是表达式必需是可修改的左值。从 Linux 报的错误来看,这段代码是能编译通过的,但是运行后,操作系统发现页表在映射时,你要映射的区域是不可写的,那么经过这样的进程地址空间 + 页表,操作系统就可以直接终止进程,换言之,进程地址空间是为了更好的进行权限管理。
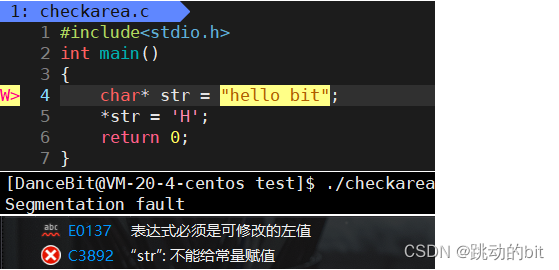
只读的代码区不能被修改,那么第一次是怎么形成的 ❓
形成代码区时不就是把数据往代码区里写吗,其实代码区在操作系统的角度,它一定是物理内存的任何位置都可以改的,只不过 *str = 'H' 是在你进行写入后修改字符串起始的第一个字符,所以经过对应的页表映射时,发现你对这个区域的权限是只读的,而你竟然想写入,所以操作系统就不会映射,而直接终止进程。
我们都知道操作系统具有 4 种核心功能:进程管理、内存管理、驱动管理、文件管理。而下图很明显是与进程管理和内存管理有关,比如说一个进程要执行,首先要申请内存资源,并加载到内存,然后创建 PCB 等进程管理工作;而进程死亡后,就需要内存管理模块来进行尽快回收,内存管理必须得做到知道某个进程的状态。所以内存管理模块和进程管理模块是 强耦合 的。如果有了虚拟地址空间的概念,那么更多的是进程管理只关注左半部分 —— 为进程创建 task_struct,mm_struct 等等,而内存管理关注右半部分 —— 它只需知道哪些内存区域 (page) 是无效的或是有效的。如下图,这样的好处是将内存管理和进程管理进行解耦,比如创建进程只需要在页表中向系统申请内存,而进程释放则通过页表释放即可。在 C++ 中有一个技术叫做 智能指针,比如说给物理内存的一块区域设置一个计数器 count,其中当页表映射一个进程后,count++,当进程释放后,映射关系消失,count–。所以内存管理只需要检测当前物理内存中的 count 是否为 0。
一个 16G 的游戏能否在 4G 的物理内存上运行 ❓
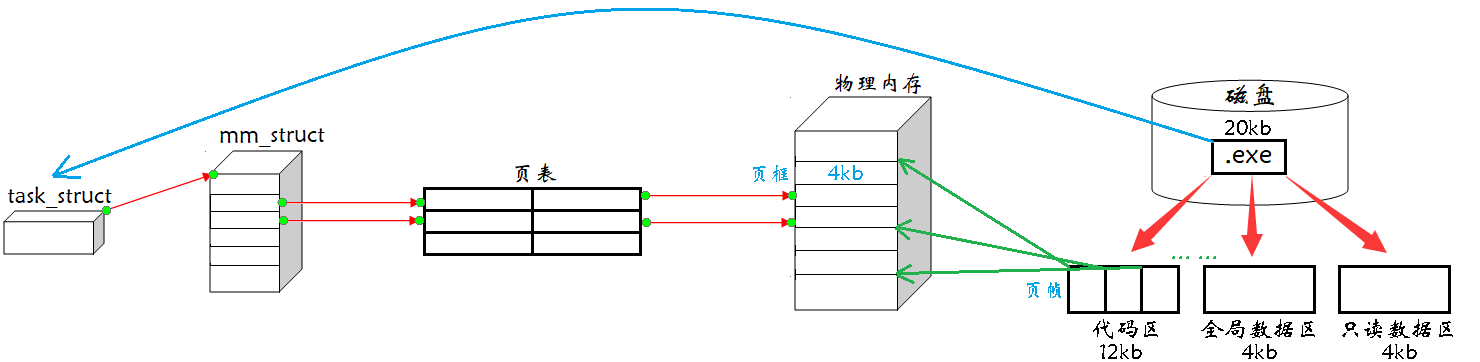
能,比如你的内存是 32G,即便直接来 16G,对计算机而言,它是从头开始访问的,也就是说 16G,你已经有 15G 已经加载到物理内存了,但你尚没有正常使用,还需要等待后面的数据加载进来,所以这是一种很低效的方案。所以操作系统要执行这个进程,但内存管理模块认为给你搞这么多你又不使用,所以就先加载 200M 给你,当你从上至下访问到最后时,如果你还需要,就再给你覆盖式的加载 200M,此时进程是不知道内存管理模块给他做的操作,内存管理就可以通过不断 延迟加载 的技术方案,来保证进程照样可以正常运行,这就是进程管理模块和内存管理模块解耦。所以对于用户来说,唯一感受到的是我的电脑变慢了,当然就这配置也是应该的。
- 在磁盘上形成的 .exe 文件在编译时其实并不是无脑的一分为二成代码和数据就完了,而是在磁盘中按照文件的方式组织成一个一个区域,也就是说可执行程序本身在磁盘上就已经被划分成了一个个区域,为什么要在编译的时候要这样划分区域,因为这样便于生成可执行程序,如果划分好了区域,那么就会减少程序链接过程的成本。因为磁盘上的可执行程序本身就是按模块划分的,所以进程地址空间才有了区域划分的概念,但要注意物理内存的情况有可能大部分的空间已经被使用了,那么进程的代码和数据可能就零散的分布于物理内存的不同位置,甚至你的代码的数据都不一定在一起,可能会被零散的加载到物理内存的任意地方,具体加载到哪里是由内存所处的状态以及 linux 内核的内存管理算法决定的,所以对于进程而言就不好找到代码的位置了,所以就在虚拟地址空间中将区域进行划分,划分成在磁盘中可能看到的区域,当然内存中的栈区,堆区磁盘中没有,然后再经页表将所有区域的数据整合,所以通过地址空间看到的就和在磁盘中看到的就是同一种物理排序了,所以每个进程就可以以同样的方式来看待代码和数据,比如进程怎么找到第一行代码呢,如果有地址空间就可以默认的在地址空间的一个确定的区域执行代码的入口,继而执行整个代码。物理内存也有区域,只不过它的内存分配是按页为单位,一页是 4kb,也就是说内存和磁盘进行交互时是按 4kb 为基本单位,所以可执行程序的生成基本都是 4kb 的整数倍,比如如下的代码区就被划分了若干个 4kb 的段。在内存中的若干个小框称为
页框,而在磁盘中可执行程序被划分为若干个 4kb 大小的数据称为页帧。
- 顺序语句
顺序语句就是从上至下执行,那么这里所有的代码它们的地址是连续的,如果它们不连续,那么 pc (eip) 指针如何进行加减呢。所以本质是将虚拟地址线性连续后,顺序语句就能实现了。所以顺序语句就是当前语句的起始地址 + 当前代码的长度。
show 函数调用完后,字符串还在吗 ❓
当 show 函数调用完后,函数栈帧销毁,所以局部变量 str 一定是不在了;但是对于字符串,它存储于常量区,只要进程还在,那么字符串就还在。show 栈帧结束,理论上是找不到字符串了,所以我们就能理解所有的地址信息都必须要用变量保存,当你在物理内存中 malloc 好一块内存,页表构建映射关系,把地址映射到堆区,最后这个区域的起始地址就返回给用户,如果用户不使用变量保存,那么就会存在 内存泄漏。
- 所以虚拟地址空间存在的意义有:
-
更好的进行权限管理和保护物理内存不受到任何进程内地址的直接访问,方便进行合法性校验。
-
进程管理和物理管理进行解耦。
-
让每个进程以同样的方式,来看待代码和数据。
- 为什么要区域划分
区域划分的本质是将线性地址空间划分成一个个区域 [start, end];而所谓的虚拟地址本质是在 [start, end] 之间的各个地址。
其一是可以初步判定当前进行区域寻址时是否越界,其二是可执行程序本身是按照若干个 4kb 模块划分好的,这就影响了操作系统在进行进程设计时也必须进行模块划分,所以就有了区域划分的概念。
解释虚拟地址中的现象
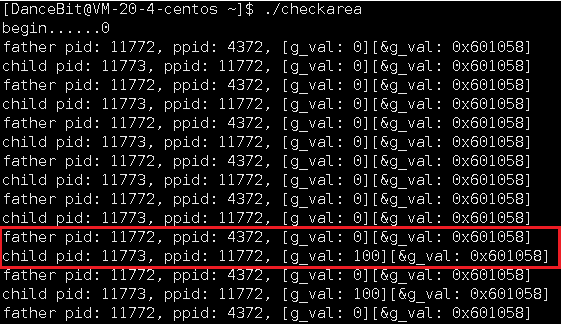
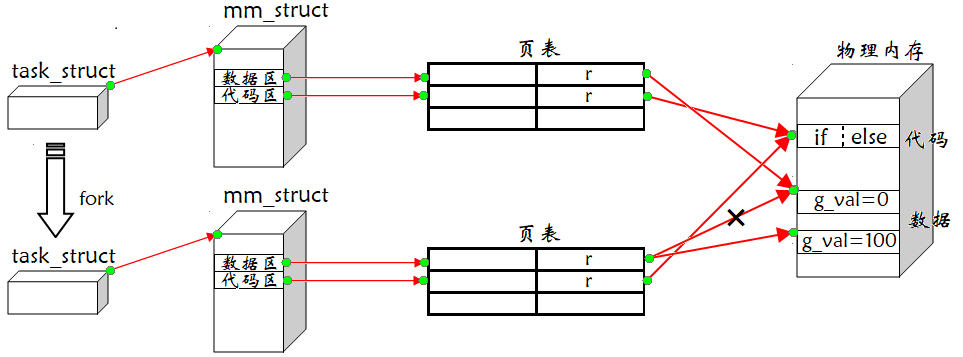
父进程在 fork 时,操作系统一定是多了一个进程,而子进程需要创建自己的 mm_struct、页表,其中子进程中的大多数属性是以父进程为模板。代码里是通过 if 和 else 来分流的 —— 父进程执行 if,子进程执行 else,实际上,不管是父进程还是子进程都能看到所有的代码,只不过不会全部执行。因为子进程中的大多数属性是以父进程为模板,所以父子进程 &g_val 的虚拟地址是相同的,当子进程尝试对 g_val 写入,而操作系统发现对于 g_val,父子进程只有 r 权限 (因为它们指向同一块内存),你居然想 w,操作系统又发现,你俩是父子关系,所以没有杀掉子进程, 而给你重新开辟一块空间,把旧空间的内容拷贝,子进程的页表就不再映射至父进程的 g_val,而是子进程的 g_val 自己私有一份,所以子进程再修改时,就可以把 g_val = 100 了,其过程的本质是 写时拷贝。所以我们就能解释为啥 g_val 的值改变后,而 &g_val 的值却是相同的。
进程和程序有什么区别 ❓
从现在开始我们再提到进程,就应该立马能联想到 task_struct、mm_struuct、页表、代码和数据。
四、Linux2.6 内核进程调度队列 —— 了解
不是本文的重点,所以了解一下即可。
Linux2.6 内核中进程队列的数据结构
一个 CPU 拥有一个 runqueue
- 如果有多个 CPU 就要考虑进程个数的负载均衡问题。
优先级
-
普通优先级:100~139 (我们都是普通的优先级,想想 nice 值的取值范围,可与之对应!)。
-
实时优先级:0~99 (不关心)
活动队列
-
时间片还没有结束的所有进程都按照优先级放在该队列。
-
nr_active:总共有多少个运行状态的进程。
-
queue[140]:一个元素就是一个进程队列,相同优先级的进程按照 FIFO 规则进行排队调度,所以,数组下标就是优先级。
-
从该结构中,选择一个最合适的进程,过程是怎么的呢 ?
1、从 0 下标注开始遍历 queue[140]。
2、找到第一个非空队列,该队列必定为优先级最高的队列。
3、拿到选中队列的第一个进程,开始运行,调度完成。
4、遍历 queue[140] 时间复杂度是常数,但还是太低效了。
- bitmap[5]:一共 140 个优先级,一共 140 个进程队列,为了提高查找非空队列的效率,就可以用 5*32 个比特位表示队列是否为空,这样,便可以大大提高查找效率。
过期队列
-
过期队列和活动队列结构一模一样。
-
过期队列上放置的进程,都是时间片耗尽的进程。
-
当活动队列上的进程都被处理完毕之后,对过期队列的进程进行时间片重新计算。
active 指针 and expired 指针
-
active 指针永远指向活动队列。
-
expired 指针永远指向过期队列。
-
可是活动队列上的进程会越来越少,过期队列上的进程会越来越多,因为进程时间片到期时一直都会存在的。
-
没关系,在合适的时候,只要能够交换 active 指针和 expired 指针的内容,就相当于有具有了一批新的活动进程。
总结
- 在系统当中查找一个最合适调度的进程的时间复杂度是一个常数,不随着进程增多而导致时间成本增加,我们称之为进程调度 O (1) 算法。
Linux | 进程相关概念(进程、进程状态、进程优先级、环境变量、进程地址空间)
TT-Kun 已于 2025-02-14 13:42:20 修改
进程概念
1、冯诺依曼体系结构

简单来说,计算机中是由一个个硬件构成
- 输入单元:键盘、鼠标、写字板等
- 中央处理器(CPU):含有运算器和控制器等
- 输出单元:显示器,打印机等
对于冯诺依曼一些结构,有以下几点注意:
- 存储器指的是内存
- 不考虑缓存情况,这里的CPU能且只能对内存进行读写, 不能访问外设
- 外设(输入设备或输出设备)要输入或者输出数据,也只能写入内存或者从内存中读取
- 总结就是:所有设备只能直接和内存打交道
2、进程
2.1基本概念
程序的一个执行实例,正在执行的程序等。担当分配系统资源(CPU时间,内存)的实体。
2.2描述进程-PCB
进程信息被放在进程控制块(一个数据结构),叫做PCB,Linux操作系统下的PCB是task_struct
进程 = 内核数据结构(PCB) + 程序段 + 数据段
task_struct内容分类
- 标识符:描述本进程的唯一标识符,用来区别其他进程
- 状态:任务状态,推出代码,推出信号
- 优先级:相对于其他进程的优先级
- 程序技术器:程序中即将被执行的下一条指令的地址
- 内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
- 上下文数据:进程执行时处理器的寄存器中的数据
- io状态信息:包括显示器的io请求,分配给进程的io设备和被进程使用的文件列表
- 记账信息:可能包括处理器时间总和,使用的时钟数总和,时间限制,记帐号等
2.3组织进程
可以在内核源代码里找到,所有运行系统里的进程都以task_struct链表的形式存在内核里
2.4查看进程
如:要获取PID为1的进程信息,你需要查看 /proc/1 这个文件夹。
大多数进程信息同样可以使用top和ps这些用户级工具来获取

2.5通过系统调用获取进程标识符
- 进程id(PID)
- 父进程id(PPID)
获取进程识别码(getpid函数与getppid函数)
-
函数原型:
pid_t getpid(void) pid_t getppid(void)其中返回值类型pid_t是一种有符号整型,也可以使用整形int类型变量来接收
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
printf("pid: %d\n", getpid());
printf("ppid: %d\n", getppid());
return 0;
}
2.6通过系统调用创建进程-fork初识
- 使用man手册运行man fork认识fork函数
- fork有两个返回值
- 父子进程代码共享,数据各自开辟空间,私有一份(采用写时拷贝)
fork の 头文件与返回值
-
头文件:
unistd.h -
函数原型:
pid_t fork(void); -
父进程中,fork返回新创建子进程的进程ID
-
子进程中,fork返回0
fork函数的调用逻辑和底层逻辑
在上文介绍PCB的时候有提到过,进程由内核数据结构和代码、数据两部分组成。因此每个进程都会有自己的PCB即task_struct结构体。当调用了fork函数后,系统创建子进程,即创建一个属于子进程的task_struct,将父进程的大部分属性拷贝过去(不在内的如pid、ppid),由于父子进程属于同一个程序,他们的代码是共用的,但是两个进程同时访问一个变量的时候会出现冲突问题,因此子进程会将它将要访问的数据做一份额外的拷贝,也就是子进程访问拷贝出来的数据,然后父子进程就有了属于各自的数据,对变量的操作也是独立的。
fork函数创建子进程过程
- 创建子进程PCB
- 填充PCB对应的内容属性
- 让子进程和赴京城指向同样的代码
- 父子进程都是有独立的task_struct,已经可以被CPU调度运行了
问:为什么fork函数调用完后会返回两个值,这和寻常的函数不是不一样么?
在fork函数中,创建子进程的步骤完成后,在return返回之前,父子进程已经可以被CPU调度运行了,也就是说,在return前fork函数执行了父子两个进程,return是作为父子进程的共有程序,他们都会各自返回一个值,因此整体看fork函数会返回两个值,分别属于调用fork函数中父子进程的返回值。
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
int ret = fork();
printf("hello proc : %d!, ret: %d\n", getpid(), ret);
sleep(1);
return 0;
}
-
由于父子进程的代码是一样的,因此如果需要使得父子进程执行不一样的代码,可以使用if加上返回值的条件限定来进行父子进程分流
#include <stdio.h> #include <sys/types.h> #include <unistd.h> int main() { int ret = fork(); if(ret < 0){ perror("fork"); return 1; } else if(ret == 0){ //child printf("I am child : %d!, ret: %d\n", getpid(), ret); }else{ //father printf("I am father : %d!, ret: %d\n", getpid(), ret); } return 0; }
3、进程状态
在程序运行的时候,如果遇到一个scanf等语句,进程会暂停知道输入相应的数据,才继续运行,由此可见进程需要有不同的状态(例如运行、阻塞、挂起等),不然进程无法按照预期正常执行。
3.1状态
-
R运行状态(running): 并不意味着进程一定在运行中,它表明进程要么是在运行中要么在运行队列里
-
S睡眠状态(sleeping): 可中断睡眠状态,意味着进程在等待事件完成(这里的睡眠有时候也叫做可中断睡眠 (interruptible sleep))
-
D磁盘休眠状态(Disk sleep):不可中断睡眠状态,在这个状态的 进程通常会等待IO的结束。
-
T停止状态(stopped): 可以通过发送 SIGSTOP 信号给进程来停止(T)进程。这个被暂停的进程可 以通过发送 SIGCONT 信号让进程继续运行。
-
X死亡状态(dead):这个状态只是一个返回状态,你不会在任务列表里看到这个状态。
-
z僵尸状态(zombie): 进程结束运行后大部分资源被回收,但进程描述符仍保留,直到父进程获取其退出状态。处于该状态的进程已死亡却占据一定系统资源,会在任务列表里显示为
Z,过多僵尸进程会造成系统资源浪费。
运行队列
进程需要执行的时候,会被加入到运行队列中,并由调度器对队列进行调度,在CPU中执行运行的进程,无论是在运行中的还是在运行队列中的进程都是在R运行状态。示意图如下:

3.2进程状态查看命令
3.2.1 ps命令
用于查看当前系统中的进程状态。
- 语法:
ps [选项] - 常用选项:
- -a:显示所有与终端相关的进程,包括其他用户的进程。
- -u:以用户格式显示进程信息,包括用户名、启动时间等。
- -x:显示所有进程,包括没有控制终端的进程。
- -ef:显示所有进程的详细信息,包括进程ID(PID)、父进程ID(PPID)等。
- -j: 会以作业格式显示进程信息,这种格式输出的内容比默认格式更丰富,会额外展示一些进程的上下文信息,常见的有:
- PPID:父进程 ID,用于表明该进程是由哪个进程创建的。
- PGID:进程组 ID,它将相关的进程组织在一起形成一个进程组。
- SID:会话 ID,代表进程所属的会话,有助于对进程进行更宏观的管理和分类。
例如,想要查看常用的指令可以使用:
ps ajx | head -1; ps axj | grep test1来查看test1可执行程序的进程相关信息,如下:

当执行
ps axj | grep test1时,你可能会看到输出结果中包含一个grep进程,这是因为grep命令本身也是一个进程,并且它在执行搜索时,ps axj的输出中也包含了grep test1这个命令行字符串,所以grep会把自身这个进程也匹配出来并显示在结果中。
3.2.2 top命令
动态地显示系统中各个进程的资源占用情况,如CPU使用率、内存使用率等。
- 语法:
top [选项] - 常用选项:
- -d:指定更新间隔时间,单位为秒。例如,
top -d 5表示每5秒更新一次显示内容。 - -b:以批处理模式运行,可用于将输出重定向到文件。
- -n:指定显示的次数。例如,
top -n 3表示只显示3次更新后的结果。
- -d:指定更新间隔时间,单位为秒。例如,
在top命令的交互界面中,还可以使用一些按键进行操作,如按M键可以按照内存使用量对进程进行排序,按P键可以按照CPU使用率进行排序等。
3.2.3 htop命令
是top命令的增强版,提供了更友好的交互式界面,支持鼠标操作,并且可以更直观地显示进程树等信息。
- 语法:
htop
直接在终端输入htop即可启动该命令,使用方法与top类似,但界面更加丰富和易于操作。
3.2.4 pidof命令
用于查找指定名称的进程的PID。
- 语法:
pidof [进程名称]
例如,要查找名为nginx的进程的PID,可以使用命令:pidof nginx。
3.2.5pgrep命令
根据进程名称或其他条件查找进程的PID。
- 语法:
pgrep [选项] [进程名称] - 常用选项:
- -l:显示进程名称和PID。
- -u:指定用户,只查找该用户的进程。
例如,要查找用户ubuntu下名为python的进程的PID,并显示进程名称和PID,可以使用命令:pgrep -lu ubuntu python。
- ps -l 列出与本次登录有关的进程信息;
- ps -aux 查询内存中进程信息;
- ps -aux | grep + 程序名字 查询该程序进程的详细信息;
- top 查看内存中进程的动态信息;
- kill -9 + pid 杀死进程。
举例如下图:


其中,在使用ps -l命令时,注意到几个信息,有下:
- **UID **: 代表执行者的身份
- **PID **: 代表这个进程的代号
- **PPID **:代表这个进程是由哪个进程发展衍生而来的,亦即父进程的代号
- **PRI **:代表这个进程可被执行的优先级,其值越小越早被执行
- **NI **:代表这个进程的nice值
3.2.6 /proc文件系统:
-
Linux的
/proc文件系统包含了大量关于系统和进程的信息。-
每个进程都有一个以其PID命名的目录,如
/proc/1234,其中包含了该进程的详细信息。 -
可以查看
/proc/[PID]/status文件来获取进程的状态信息。
-
例如执行
ls /proc/45311 -dl:
/proc/45311是目标路径,其中/proc是系统中用于反映进程运行状态的虚拟文件系统,45311代表特定进程的 ID,此路径指向该进程对应的目录;-dl是选项组合,-d使ls仅列出目录本身而非其内部内容,-l让ls以长格式输出详细信息
3.3僵尸进程(Z状态)
- 僵死状态(Zombies)是一个比较特殊的状态。当进程退出并且父进程(使用wait()系统调用) 没有读取到子进程退出的返回代码时就会产生僵死(尸)进程
- 僵死进程会以终止状态保持在进程表中,并且会一直在等待父进程读取退出状态代码
- 所以,只要子进程退出,父进程还在运行,但父进程没有读取子进程状态,子进程进入Z状态
下面是一个僵尸进程例子:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int main(){
pid_t ret = fork();
if(ret == 0){
printf("child process exit\n");
exit(0);
}
else{
while(1){
}
}
return 0;
可以复制一个当前会话便于观察进程信息,下图一为上面代码运行效果,下图二为运行中的进程信息,可以看到由于子进程代码中有exit(0)而提前退出,而父进程一直等待子进程的反馈未果,因而子进程处于z状态。想要结束程序可以使用Ctrl + c 退出或使用kill命令。


进程一般退出的时候,如果父进程没有主动回收子进程信息,子进程会一直让自己处于Z状态,进程的相关资源尤其是
task_struct结构体不能被释放
僵尸进程的危害
- 进程的退出状态必须被维持下去。父进程如果一直不读取,那子进程就一直处于Z状态
- 维护退出状态本身就是要用数据维护,也属于进程基本信息,所以保存在task_struct(PCB)中,换句话 说,Z状态一直不退出,PCB一直都要维护
- 那一个父进程创建了很多子进程,就是不回收,会造成内存资源的浪费。因为数据结构 对象本身就要占用内存,想想C中定义一个结构体变量(对象),是要在内存的某个位置进行开辟空间的,不会受会造成内存泄漏
3.4孤儿进程
- 父进程如果提前退出,那么子进程后退出,进入Z之后,那该如何处理呢?
- 父进程先退出,子进程就称之为“孤儿进程”
- 孤儿进程被1号systemd进程”领养“,当然要有systemd进程回收。
下面是一个孤儿进程的例子。
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main() {
pid_t ret = fork(); // 创建子进程
if (ret == 0) {
// 子进程逻辑
for (int i = 0; i < 60; i++) {
printf("child process %d\n", getpid());
sleep(1);
}
} else {
// 父进程逻辑
for (int i = 0; i < 8; i++) {
printf("father process %d\n", getpid());
sleep(1);
}
exit(0); // 父进程提前退出
}
return 0;
}
可以看到父进程提前退出,子进程继续执行,如果观察进程信息会发现子进程在父进程提前退出后它的PPID变成了1。使用ps ajx | grep systemd会发现PID是1,即1号进程就是操作系统本身。我们把这种子进程称为孤儿进程。
为什么孤儿进程的PPID会变成1?
因为子进程将来需要被释放,原来的父进程提前退出,因此子进程被系统进程”领养“,在结束后进程后释放掉子进程。
4、进程优先级
4.1基本概念
- cpu资源分配的先后顺序,就是进程的优先权
- 优先权高的进程有优先执行权,配置进程优先权对多任务环境的linux很有用,可以改善系统性能
- 还可以把进程运行到指定的CPU上,把不重要的进程安排到某个CPU,可以大大改善系统整体性能
4.2查看系统进程
4.2.1 ps -l

在使用ps -l命令时,注意到几个信息,有下:
- UID: 代表执行者的身份
- PID: 代表这个进程的代号
- PPID:代表这个进程是由哪个进程发展衍生而来的,即父进程的代号
- PRI:代表这个进程可被执行的优先级,其值越小越早被执行
- NI:代表这个进程的nice值,nice值:进程优先级的修正数据(可以用来改)
4.2.2 PRI & NI
- PRI,即进程的优先级,或者通俗点说就是程序被CPU执行的先后顺序,此值越小进程的优先级别越高
- NI就是我们所要说的nice值了,其表示进程可被执行的优先级的修正数值
- PRI值越小越快被执行,那么加入nice值后,将会使得PRI变为:PRI(new)=PRI(old)+nice
- 这样,当nice值为负值的时候,那么该程序将会优先级值将变小,即其优先级会变高,则其越快被执行
- 所以,调整进程优先级,在Linux下,就是调整进程nice值
- nice其取值范围是**-20至19**,一共40个级别。
- 需要强调一点的是,进程的nice值不是进程的优先级,他们不是一个概念,但是进程nice值会影响到进 程的优先级变化。
- 可以理解nice值是进程优先级的修正修正数据
4.3用top命令更改已存在进程的nice:
- top
- 进入top后按 “r“ -> 输入进程PID -> 输入nice值
5、环境变量
5.1常见环境变量
- PATH : 指定命令的搜索路径
- HOME : 指定用户的主工作目录(即用户登陆到Linux系统中时,默认的目录)
- SHELL : 当前Shell,它的值通常是/bin/bash。
5.2查看环境变量
环境变量相关命令
echo $NAME显示某个环境变量的值,其中NAME是环境变量名称- export: 设置一个新的环境变量
- env: 显示所有环境变量
- unset: 清除环境变量
- set: 显示本地定义的shell变量和环境变量
5.3测试PATH
- 举一个简单的例子
#include<stdio.h>
int main()
{
int i;
for(i=0;i<5;i++){
printf("I am a process\n");
}
return 0;
}
我们将他编译为叫process的可执行程序,当需要执行这个程序的时候我们应该使用./process来执行,直接输入process会显示”command not found“。但是在执行命令的时候比如touch命令、ls命令等,我们只需要输入命令名字即可,如果我们想让process这个程序像命令一样执行,即输入process就能执行,那么可以将程序所在路径加入到环境变量PATH当中
配置环境变量
PATH=$PATH:/root/workspace/Linux将当前程序所在的路径加入到环境变量PATH当中PATH=/root/workspace/Linux将当前程序所在的路径覆盖至环境变量PATH当中,相当于把PATH当中全部覆盖掉,然后ls等指令就会失效了。
执行完后,我们就可以直接输入process来执行程序,不需要带上路径了,甚至用mv将process改名后也能正常运行。使用which process也能找到~/root/workspace/Linux。
5.4代码中获取环境变量
getnev函数
-
函数声明:
char *getenv(const char *name)其中name是需要获取的环境变量名 -
使用举例:
#include <stdio.h>
#include <stdlib.h>
int main() {
// 打印环境变量 PATH 的值
printf("PATH:%s\n", getenv("PATH"));
return 0;
}
6、进程地址空间
6.1程序地址空间
地址空间一共有如下的几个区域,从下到上地址逐渐增加,其中栈区的空间是从上往下使用,即从高地址往低地址增长;堆区的空间是从下往上使用,即从低地址往高地址增长,需要注意的是,在不同位操作系统下或者不同编译器下,内存的分配规则都可能是不同的,这里以linux为例,也是最经典的一种。
我们平时敲代码使用程序地址空间的时候,当我们定义一个局部变量,它的空间就是在栈区上开辟的,有临时性;当我们使用malloc申请空间的时候,是在堆区开辟的空间;当我们定义一个全局变量的时候,它的空间就是在全局变量中开辟的,其中也分为未初始化全局变量和已初始化全局变量。在32位系统下的寻址空间是4GB

为了直观地体现出地址分配的规则,我们使用一些例子来做演示:
#include <stdio.h>
#include <stdlib.h>
// 全局变量
int val1 = 10; // 已初始化全局变量
int val2; // 未初始化全局变量
int main() {
// 以下均为存储在各区地址空间中的实例
// 打印代码区地址
printf("代码区: %p\n", main);
// 打印字符常量区地址
const char* str = "hello linux";
printf("字符常量区: %p\n", str);
// 打印已初始化全局变量区地址
printf("已初始化全局变量区: %p\n", &val1);
// 打印未初始化全局变量区地址
printf("未初始化全局变量区: %p\n", &val2);
// 打印堆区地址
char* a = (char*)malloc(sizeof(char));
printf("堆区: %p\n", a);
// 打印栈区地址
printf("栈区: %p\n", &str);
// 释放堆区分配的内存
free(a);
return 0;
}
运行结果如下图所示:

通过运行结果会发现打印出来的地址从代码区到栈区依次递增。
6.2进程地址空间
当我们使用fork()函数生成一个子进程的时候,子进程会对将要访问的父进程的内容进行写时拷贝,但是会发现子进程和父进程对于同一个全局变量进行访问更改等操作的时候,这个变量的地址是不变的,也就是说同一个地址可能会有两个值,因为这里的地址并不是物理地址,而是虚拟地址(我们平时写程序用到的地址相关的内容一般都是虚拟地址)。如果是物理地址,这是绝对不可能的,可以配合下面案例理解:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int val = 0;
int main() {
pid_t id = fork();
if (id < 0) {
// fork失败,打印错误信息并返回0
perror("fork");
return 0;
} else if (id == 0) { // 子进程
// 子进程修改全局变量val
val = 100;
printf("child: %d : %p\n", val, &val);
} else { // 父进程
// 父进程暂停3秒
sleep(3);
printf("parent: %d : %p\n", val, &val);
}
// 程序暂停1秒
sleep(1);
return 0;
}
运行结果如图

会发现前文所说的现象,同一个变量,子进程对其将要访问的变量进行写时拷贝,但是父子进程中的val确是同一个地址,因此这里的地址是虚拟地址而非物理地址。他们地址上的逻辑应该对应下图(简化):


- 当父进程创建出来,系统创建了父进程的PCB和父进程的进程地址空间,PCB指向进程地址空间
- 这里创建的进程地址空间是虚拟地址,虚拟地址和物理内存是通过页表来映射的
- 当访问某个地址时,页表通过映射关系,查找到物理地址,并读取存在当中的数据
- 当父进程创建子进程的时候,系统也根据父进程为模板创建子进程对应的PCB和进程地址空间
- 由于子进程时以父进程为模板创建的,因此他们页表是一样的,因此子进程和父进程能够共享代码
- 对于同一个全局变量,当子进程需要对其进行写入等操作时,由于父子进程的虚拟地址对应同一块物理地址,为保证独立性,系统会在物理内存中额外开辟一块空间
- 至此,父子进程各自页表中对于此全局变量的虚拟地址是相同的,但是对应的物理地址是不同的。
Linux-- 进程(进程概念、PCB、进程状态、孤儿进程、进程优先级、进程切换、进程调度)
みずいろ于 2025-02-19 01:03:36 发布
一、进程概念和PCB
1.什么是进程?
进程是操作系统中的一个核心概念,指的是正在执行的程序实例。它不仅包含程序的代码,还涉及程序运行时的状态和资源。
程序与进程的区别:
-
程序:静态的指令集合;比如:通过语言编写的程序。
-
进程:程序的一次动态执行,包括代码、数据和状态(将磁盘的代码加载到内存中,运行的程序称之为进程 )。
进程 = 内核数据结构(例如:PCB) + 程序的代码和数据
运行程序本质是系统启动一个进程:
- 执行完就退出 – 例如:ls,pwd等指令
- 一直不退,直到用户退出 – 常驻进程(例如:杀毒软件)
2.进程的描述方式–PCB
操作系统的管理核心方式为“先描述再组织”,对进程管理时,需要先对进程信息及属性进行描述。
- PCB:进程控制块(process control block),是一种数据结构,用于存放进程信息,可以理解为进程属性的集合。
- task_struct:PCB的一种,在Linux中描述进程的结构体叫做task_struct;是Linux内核的一种数据结构,它存在于RAM(内存) 里并包含进程的信息(属于内存级的数据对象)。
task_struct的内容:
- 标示符: 描述本进程的唯一标示符,用来区别其他进程。
- 状态: 任务状态,退出代码,退出信号等。
- 优先级:相对于其他进程的优先级。
- 程序计数器: 程序中即将被执行的下一条指令的地址。
- 内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
- 上下文数据: 进程执行时处理器的寄存器中的数据。
- I/O状态信息:包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
- 记账信息:可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
- 其他信息
对进程进行组织:
所有运行在系统里的进程都以**task_struct链表(双链表)**的形式存在内核里,对进程的管理就变为了对链表的增删查改。
查看进程信息:
进程的信息可以通过 /proc 系统文件夹查看
/proc 是 Linux 系统中一个特殊的虚拟文件系统,它提供了内核和进程信息的接口。/proc 目录中的文件和目录并不是真实的磁盘文件(并不是磁盘级的文件),而是由内核动态生成的,用于反映系统状态和进程信息。 进程的信息以文件的形式呈现,/proc目录内分别以每个进程的PID为名创建一个目录(实时创建:进程启动时,同时创建对应目录),一个目录代表一个进程,目录内存放着一个进程的信息;当进程结束时,对应的目录也会被自动删除掉了。
查看PID为1的进程信息:
ps命令可以查看进程的相关属性,ps的底层就是通过/proc进行文本分析来实现的
| 指令 选项 | ps aux | ps ajx |
|---|---|---|
| 显示内容 | 显示所有用户的进程详细信息。 | 显示进程的作业信息(PGID、SID 等)。 |
| 常用场景 | 查看进程的资源使用情况(CPU、内存)。 | 查看进程的父子关系、进程组和会话信息。 |
| 输出字段 | 包含 USER, %CPU, %MEM 等。 | 包含 PPID, PGID, SID 等。 |

进程信息:
/proc和task_struct的关系:
task_struct 是 Linux 内核用于表示进程或线程的核心数据结构,存储进程各类关键信息。/proc 是虚拟文件系统,将 task_struct 中的信息以文件和目录形式映射到用户空间,每个进程对应 /proc 下以其 PID 命名的目录,目录里文件包含该进程 task_struct 部分信息。它为用户提供查看和监控进程状态的便捷方式,是内核与用户空间交互的桥梁,信息随 task_struct 动态更新。
二、task_struct – 进程标识符PID和PPID
- PID:描述本进程的唯一标示符,用来区别其他进程。
- 系统对PID的维护:累加增长且连续,所以同一个程序在不同时间运行时进程PID不同
- PPID:表示当前进程的父进程的PID。(在Linux系统中,启动之后,新创建的任何进程都是由自己的父进程创建的)
通过系统调用获取当前进程标识符:
- 进程id(PID):getpid()
- 父进程id(PPID):getppid()
- 头文件:<unistd.h>
- 返回值类型:pid_t(本质是整型类型的封装)
//循环打印当前进程的PID和PPID
#include <iostream>
#include <algorithm>
#include <unistd.h>
using namespace std;
int main()
{
while(1)
{
pid_t pid = getpid();
pid_t ppid = getppid();
cout << "PID:" << getpid() << endl;
cout << "PPID:" << getppid() << endl << endl;
sleep(1);
}
return 0;
}
命令行中,执行命令/执行程序,本质是bash作为父进程,创建的子进程,由子进程执行程序(bash–命令行解释器shell的一种,每一次登录,都会创建一个bash进程)
三、通过系统调用fork()创建进程
- 头文件:<unistd.h>
- 原型:pid_t fork(void)
- 返回值:当前进程作为父进程创建一个子进程,如果创建成功fork返回给父进程新创建子进程的PID,返回给子进程0;如果创建失败fork返回给父进程-1。所以根据父子进程的返回值不同可以进行分流,由返回值判断是父进程还是子进程并执行不同的操作。
- 父子进程代码共享,数据各自开辟空间私有一份(采用写时拷贝);进程具有很强的独立性,多个进程之间,运行时互不影响,即便是父子进程,代码是只读的,数据是私有的。
#include <iostream>
#include <unistd.h>
using namespace std;
int main() {
pid_t pid = fork(); // 创建子进程
if (pid == 0) { // 子进程
while (1) {
cout << "子进程PID:" << getpid() << " PPID:" << getppid() << endl;
sleep(1); // 每秒打印一次
}
} else if (pid > 0) { // 父进程
while (1) {
cout << "父进程PID:" << getpid() << " PPID:" << getppid() << endl;
sleep(1); // 每秒打印一次
}
} else { // 进程创建失败
perror("process create fail");
}
return 0;
}

由此可知,父进程有多个子进程,子进程只有一个父进程,所以Linux进程整体是树形结构。
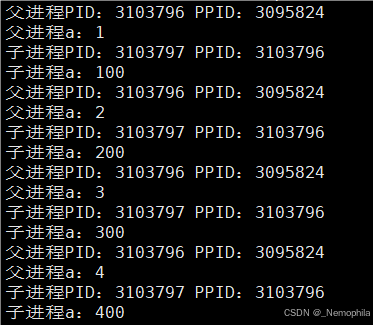
验证父子进程代码共享,数据各自私有(全局变量举例):
#include <iostream>
#include <unistd.h>
using namespace std;
// 全局变量
int a = 0;
int main() {
pid_t pid = fork(); // 创建子进程
if (pid == 0) { // 子进程
while (1) {
cout << "子进程PID:" << getpid() << " PPID:" << getppid() << endl;
a += 100; // 子进程修改全局变量 a
cout << "子进程a:" << a << endl;
sleep(1); // 每秒打印一次
}
} else if (pid > 0) { // 父进程
while (1) {
cout << "父进程PID:" << getpid() << " PPID:" << getppid() << endl;
a++; // 父进程修改全局变量 a
cout << "父进程a:" << a << endl;
sleep(1); // 每秒打印一次
}
} else { // 进程创建失败
perror("process create fail");
}
return 0;
}
fork函数如何实现返回两个返回值?
调用fork内部执行过程:
- 操作系统会复制调用
fork()的进程(即父进程)的大部分上下文和task_struct,包括代码段、数据段、堆栈等,从而创建一个新的子进程。这个新的子进程几乎是父进程的一个副本,但拥有自己独立的进程 ID(PID) - 调整新进程的部分属性
- 将task_struct连入到进程列表中,此时子进程已经创建完成
- 父进程和子进程分别返回不同的值
fork之后运行顺序由OS的调度器自主决定。
四、task_struct – 进程状态
补充知识:
1.并行和并发:CPU执行进程代码,不是把进程代码执行完毕,才开始执行下一个的,而是给每个进程分配一个时间片,基于时间片进行调度轮转(单个CPU下)
- 并行:多个进程在多个CPU下分别同时进行运行,这称之为并行
- 并发:多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,这称之为并发
2.时间片:时间片是指操作系统分配给每个正在运行的进程的一段短暂的 CPU 使用时间。在多任务操作系统中,多个进程需要共享 CPU 资源,时间片就是为了实现多个进程能够看似同时运行而采取的一种机制。操作系统会以一定的时间间隔,轮流让各个进程使用 CPU,每个进程每次使用 CPU 的时间就是一个时间片。Linux/Windows民用级别的操作系统采用分时操作系统,采用时间片轮转调度算法,调度任务追求公平;还有采用基于优先级的抢占式调度算法的实时操作系统。
3.进程具有独立性:进程的数据各自私有
1.进程状态
进程是操作系统中正在运行的程序的实例,它具有多种状态,以反映进程在不同时刻的执行情况和资源占用情况。
kernel源码定义:
/*
* The task state array is a strange "bitmap" of
* reasons to sleep. Thus "running" is zero, and
* you can test for combinations of others with
* simple bit tests.
*/
static const char *const task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)" /* 32 */
};
| 状态描述 | 对应的字符 | 数值(十六进制) | 数值(十进制) | 作用 |
|---|---|---|---|---|
| 运行状态 | R | 0x00 | 0 | 表示进程当前正在运行,或者处于就绪状态等待 CPU 调度执行(处于运行队列中)。这是进程的活跃状态,意味着它正在使用 CPU 资源执行代码。 |
| 休眠状态(可中断睡眠) | S | 0x01 | 1 | 表示进程处于可中断睡眠状态(浅睡眠)。进程主动放弃 CPU 资源,等待某个事件的发生(如 I/O 完成、信号到达等),当事件发生后,进程会被唤醒并重新进入就绪队列等待调度。 |
| 磁盘休眠状态(不可中断睡眠) | D | 0x02 | 2 | 表示进程处于不可中断的睡眠状态,通常是在等待磁盘 I/O 操作完成。在这种状态下,进程不会响应任何信号,即使是终止信号也无法将其唤醒,直到磁盘 I/O 操作完成。这是为了保证数据的一致性和完整性。 |
| 暂停状态 | T | 0x04 | 4 | 表示进程已经停止执行。通常是由于接收到了 SIGSTOP、SIGTSTP 等停止信号,进程暂停执行,直到接收到 SIGCONT 信号才会继续执行。 |
| 跟踪暂停状态 | t | 0x08 | 8 | 表示进程由于被调试器跟踪而停止。当一个进程被调试器(如 gdb)跟踪时,调试器可以控制进程的执行,在某些断点或者单步执行等操作时,进程会进入这种跟踪暂停状态。 |
| 死亡状态 | X | 0x10 | 16 | 表示进程已经死亡,即进程已经结束执行,并且相关的资源已经被操作系统回收。这是进程生命周期的最后阶段,此时进程在系统中已经不存在了。 |
| 僵尸状态 | Z | 0x20 | 32 | 表示进程处于僵尸状态**。当一个进程结束执行后,它的退出状态会被保留,直到其父进程调用 wait () 或 waitpid () 等系统调用来获取这些信息。在父进程获取这些信息之前,该进程就处于僵尸状态。僵尸进程虽然已经不再执行代码,但仍然占用着一定的系统资源(如进程表项)。** |
进程状态查看:命令ps aux / ps axj


2.运行状态R
在较老的内核中,只要进程在运行队列中,该进程就叫做运行状态,可以被CPU随时调度。正在运行和在运行队列未被调度的状态都叫运行状态;在现代操作系统中,正在运行的进程处于运行状态,而在运行队列中未被调度的进程处于就绪状态,而不是严格意义上的运行状态。但这里以老内核为例。
#include <iostream>
#include <unistd.h>
using namespace std;
// 全局变量
int a = 0;
int main() {
while (1) {
// 打印语句被注释掉了,因此这个循环什么也不会做
// cout << "1" << endl;
}
return 0;
}
3.休眠状态S
表示进程处于可中断睡眠状态(浅睡眠)。进程主动放弃 CPU 资源,等待某个事件的发生(如 I/O 完成、信号到达等),当事件发生后,进程会被唤醒并重新进入就绪队列等待调度。在休眠状态时,进程可以被杀掉。
#include <iostream>
#include <unistd.h>
using namespace std;
// 全局变量
int a = 0;
int main() {
while (1) {
cout << "1" << endl;
sleep(1); // 每秒打印一次,避免过快的输出
}
return 0;
}
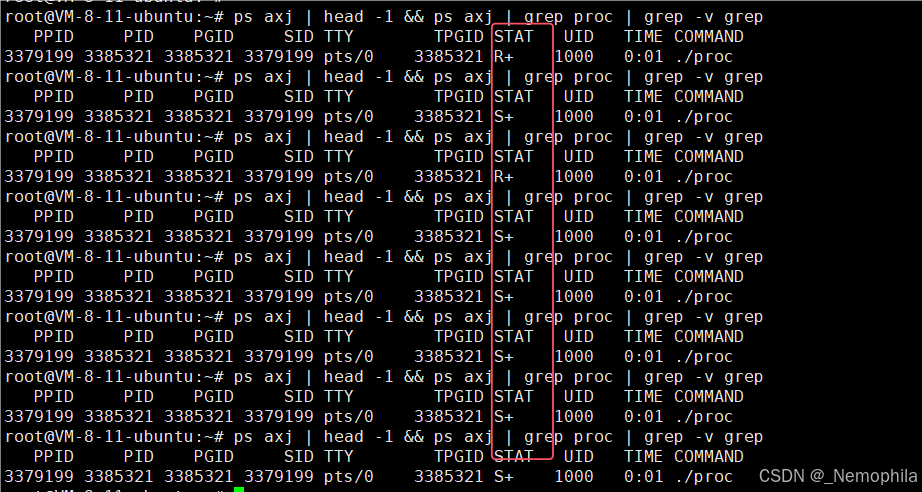
这里代码比上面的代码多了一句printf语句,查看进程状态可以发现该进程大部分时间处于休眠状态,这是因为IO的速度非常慢,使进程大部分时间都是在做IO,所以进程大部分时间都是处在休眠状态等待IO完成。
4.磁盘休眠状态D
表示进程处于不可中断的睡眠状态,通常是在等待磁盘 I/O 操作完成。在这种状态下,进程不会响应任何信号,即使是终止信号也无法将其唤醒,**直到磁盘 I/O 操作完成。这是为了保证数据的一致性和完整性。**如果长时间处于D状态,此时内存资源可能不足(比如,内存管理进程无法将内存数据及时交换到磁盘,会导致内存资源紧张且无法有效释放,进而影响整个系统的资源分配和调度,系统容易挂掉。
5.暂停状态T
表示进程已经停止执行。通常是由于接收到了 SIGSTOP、SIGTSTP 等停止信号,进程暂停执行,直到接收到 SIGCONT 信号才会继续执行;或是进程做了非法但是不致命的操作,被OS暂停了。
例如:执行一个程序 -> 使用kill命令发送停止信号 -> 进程处于暂停状态 -> 再发送继续信号进程继续执行


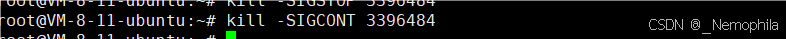
命令:kill 选项 PID,向指定PID的进程发送信号
6.跟踪暂停状态t
表示进程由于被调试器跟踪而停止。当一个进程被调试器(如 gdb)跟踪时,调试器可以控制进程的执行,在某些断点或者单步执行等操作时,进程会进入这种跟踪暂停状态。
7.僵尸状态Z
表示进程处于僵尸状态**。当一个进程结束执行后,它的退出状态会被保留,直到其父进程调用 wait () 或 waitpid () 等系统调用来获取这些信息。在父进程获取这些信息之前,该进程就处于僵尸状态。僵尸进程虽然已经不再执行代码,代码资源被释放,但仍然占用着一定的系统资源(如task_struct,用于记录进程退出信息)。**

例子:父进程创建一个子进程,子进程退出,父进程没退出且没有获取子进程的退出信息(退出码),子进程此时处于僵尸状态。
#include <iostream>
#include <unistd.h>
using namespace std;
// 全局变量
int a = 0;
int main() {
pid_t pid = fork(); // 创建子进程
if (pid == 0) {
// 子进程
cout << "子进程退出" << endl;
} else if (pid > 0) {
// 父进程
while (1) {
// 父进程进入无限循环,模拟长时间运行的父进程
}
} else {
// 进程创建失败
perror("fork failed");
}
return 0;
}

僵尸进程的危害:
进程的退出状态必须被维持下去,因为子进程需要告诉父进程该子进程任务执行的情况如何,如果父进程一直不读取退出状态,那子进程就一直处于Z状态,就需要一直用task_struct维护退出状态,如果父进程创建了很多子进程同时不获取子进程的退出状态,就会造成内存资源的浪费。
命令:echo $?,查看最近一个程序退出时的退出信息(返回值),0–表示执行成功,非0–表示执行出错。
8.死亡状态X
表示进程已经死亡,即进程已经结束执行,并且相关的资源已经被操作系统回收。这是进程生命周期的最后阶段,此时进程在系统中已经不存在了。
僵尸状态和死亡状态的关系:通常情况下,进程先进入僵尸状态,之后才会进入死亡状态。当进程执行完任务调用 exit 系统调用退出后,会先转变为僵尸状态;只有当父进程调用 wait 或 waitpid 等系统调用获取该进程的退出状态信息后,内核才会将其彻底销毁,进程从而进入死亡状态。
9.阻塞挂起状态
背景:内存资源严重不足时
在操作系统中,阻塞挂起状态(Blocked Suspended State)是进程状态的一种,表示进程因为等待某些资源或事件(如等待硬件资源)而无法继续执行(阻塞),同时被操作系统挂起(Suspended),即从内存中换出到外存(如磁盘)中,该磁盘的区域为swap分区。
- 挂起:进程被操作系统从内存中换出到外存中,以释放内存资源供其他进程使用。
- 进程的PCB保留,代码和数据从内存中换出到磁盘中;当获得硬件资源时,将代码和数据从磁盘中唤出到内存中,从阻塞挂起状态变为运行状态
- swap分区做挂起的本质:用时间换空间;云服务器上的系统的swap分区一般会被禁用掉,因为换入换出实际上就是做IO,IO的效率非常慢,禁用掉是因为更注重效率
- 如果阻塞挂起还是没能解决内存资源不足,操作系统为了保障自身安全,会强行杀死进程
10.进程从创建到退出
- 一个进程创建时,先创建内核数据结构(例如:PCB),再加载代码和数据(新建状态:进程已经被创建,但尚未被操作系统纳入调度队列(此时只有内核数据结构,还没加载代码和数据),也就是说它还不能被 CPU 执行。当操作系统完成了新进程的初始化工作,并将其插入到就绪队列中后,进程就从新建状态转换为就绪状态,等待 CPU 的调度。)
- 一个进程退出时,先是将代码和数据的资源释放,再将task_struct通过OS维护起来,方便用户未来进行获取进程退出的信息,此时就是僵尸状态。
五、前台进程和后台进程
1.概念
- 前台进程:指那些在当前终端上运行,并且会占用终端的控制权的进程。在前台进程运行期间,用户无法在该终端进行其他命令的输入,直到该进程执行完毕或被终止。
- 后台进程:指那些在系统后台运行的进程,它们不会占用终端的控制权,用户可以在终端继续输入和执行其他命令。
| 比较项 | 前台进程 | 后台进程 |
|---|---|---|
| 用户交互 | 可以直接与用户进行交互,接收用户的输入并输出结果到终端。适用于需要频繁人机交互的场景,如文本编辑、交互式调试程序等。 | 通常不能直接与用户进行交互,输出结果可能会在终端随机显示,影响正常操作。适合不需要人工频繁操作的任务,如数据备份、日志收集等。 |
| 终端占用 | 占用当前终端,在进程运行期间,用户无法在该终端执行其他命令。降低了终端的使用效率,尤其是执行长时间任务时影响较大。 | 不占用终端,用户可以在终端继续执行其他命令。提高了终端的利用率,用户可以同时进行多个任务。 |
| 进程管理 | 可以使用 Ctrl + C(中断进程)、Ctrl + Z(暂停进程)等组合键直接控制,操作简便快捷。 | 需要使用特定的命令(如 jobs、fg、bg、kill 等)进行管理,相对复杂,需要一定的命令使用知识。 |
| 进程状态 | 通常是可见的,用户可以直接看到进程的运行状态和输出信息,方便实时了解进程的进展情况。 | 通常是不可见的,用户需要使用特定的命令(如 ps、top 等)来查看进程的运行状态,增加了查看进程状态的操作步骤和难度。 |
| 优点 | - 便于交互操作,能实时获取反馈和调整。 | - 提高系统资源利用率,可同时处理多任务。 |
| - 易于调试和监控,方便开发者定位问题。 | - 持续稳定运行,不受终端状态影响。 | |
| - 实时响应需求,适合对实时性要求高的任务。 | - 避免干扰用户操作,不影响终端的其他使用。 | |
| 缺点 | - 独占终端资源,降低终端使用效率。 | - 交互性差,不利于需频繁交互的任务。 |
| - 易受终端影响,终端异常可能导致进程中断。 | - 监控和调试困难,定位问题较麻烦。 | |
| - 可能造成界面阻塞,影响用户体验。 | - 可能占用过多资源,影响系统性能。 |
2.启动方式
- 前台进程:直接在终端输入命令并回车,默认情况下启动的进程就是前台进程(终端退出,进程也退出)。例如:
# 该命令会在前台运行,直到文件复制完成,期间无法在该终端执行其他命令
cp largefile1.txt largefile2.txt
后台进程:
-
在命令后面加上
&符号,这样命令就会在后台启动(终端退出,进程也退出)。例如: -
# 该命令会在后台运行,用户可以继续在终端执行其他命令 cp largefile1.txt largefile2.txt & -
使用
nohup命令可以让进程在后台运行,并且不受用户退出终端的影响(终端退出,进程不会退出)。例如: -
# 即使关闭当前终端,该脚本也会继续在后台运行 nohup ./long_running_script.sh & -
对一个进程暂停再重新启动,这个进程自动变到后台去运行(s+ -> s),无法直接使用ctrl + c杀掉进程,需要使用kill -9 进程 pid 来杀掉进程。
3.管理方法
-
查看进程:
-
jobs 命令:用于查看当前终端的后台作业。例如:
-
jobs -
ps 命令:可以查看系统中所有进程的信息。例如,查看所有进程并按照 PID 排序:
ps -ef | sort -k 2n
-
前后台进程切换:
-
fg命令:将后台进程切换到前台运行。例如,将编号为 1 的后台作业切换到前台: -
fg %1 -
bg命令:将暂停的进程放到后台继续运行。例如,将最近暂停的作业放到后台继续运行:
bg %+
- 终止进程:
Ctrl + C:用于终止当前正在运行的前台进程(不能结束后台进程)。kill命令:用于终止指定 PID 的进程。例如,终止 PID 为 1234 的进程:
kill 1234
killall命令:用于终止指定名称的所有进程。例如,终止所有名为firefox的进程:
killall firefox
六、孤儿进程
子进程还在执行,父进程已经退出,此时的子进程就是孤儿进程,孤儿进程的PPID变为1,PID为1的进程是系统(init进程)(即子进程变成孤儿进程时被系统自动领养)。成为孤儿进程时,默认是后台进程。
例子:父进程提前退出
#include <iostream>
#include <unistd.h>
using namespace std;
// 全局变量
int a = 0;
int main() {
pid_t pid = fork(); // 创建子进程
if (pid == 0) {
// 子进程逻辑
while (1) {
cout << "子进程" << endl;
sleep(2); // 每2秒打印一次
}
} else if (pid > 0) {
// 父进程逻辑
cout << "父进程退出" << endl;
} else {
// 进程创建失败
perror("fork failed");
}
return 0;
}

STAT:如果是 状态+ 的形式,表示是前台进程;如果是只有 状态 的形式,表示是后台进程。
七、进程优先级
系统进程数目众多,而CPU资源只有少量,甚至1个,所以进程之间是具有竞争属性的。为
了高效完成任务,更合理竞争相关资源,便具有了优先级;
CPU资源分配的先后顺序,就是指进程的优先级;
用数值表示优先级,数值越小,优先级越高,进程有优先执行权力。
- PRI:当前进程的优先级,数字越小,优先级越高
- NI:nice,优先级的nice数据,优先级的修正数据;nice取值范围是-20~19,一共40个级别。
- 最终优先级=PRI(默认/老的优先级,default 80)+ nice
- UID:当前用户的用户标识符(用户ID),可以根据UID知晓进程是谁启动的
- Linux下一切皆为文件,文件会记录拥有者、所属组和对应的权限,而所有操作都是进程操作,进程会通过UID记录是由哪个用户启动的,进而实现权限的控制

查看进程优先级:
命令:ps -la,显示所有用户的进程,不仅仅当前用户的进程,并且包含UID、PID、PPID、PRI、NI等信息
修改进程优先级:
命令:top -> 键入“r” -> 输入进程PID -> 输入nice值
命令:
renice [优先级] -p [进程ID1] [进程ID2] ...
renice [优先级] -g [进程组ID1] [进程组ID2] ...
renice [优先级] -u [用户名1] [用户名2] ...
[优先级]:要设置的新 Nice 值,范围为 -20 到 19。
-p:指定要修改优先级的进程 ID(PID),可以指定多个进程 ID,用空格分隔。
-g:指定要修改优先级的进程组 ID(PGID),可以同时修改一个进程组内所有进程的优先级。
-u:指定要修改优先级的用户名下的所有进程。
注意:
权限限制:普通用户只能将进程的 Nice 值调高(即向 19 方向调整),不能将其调低(向 -20 方向调整),因为调低 Nice 值会提高进程的优先级,可能会影响系统的稳定性和其他进程的正常运行。只有超级用户(root)可以将 Nice 值调低,拥有更高的权限来调整进程优先级。
实时进程:renice 命令对实时进程无效。实时进程使用不同的调度策略,其优先级的设置和管理方式与普通进程不同。
确认修改结果:修改进程优先级后,可以使用 ps -l 或 top 命令来确认进程的新 Nice 值是否已成功修改。例
如,使用 ps -l 命令查看进程信息时,NI 列会显示进程的 Nice 值。
需要注意:
- 不建议修改或高频修改优先级
- 修改PRI,只能通过修改NI来修改最终优先级
- OS禁止频繁修改或没有权限修改
- nice值的取值范围:[-20~19],每次修改进程优先级时,老的优先级会重置为80
启动新进程时指定优先级:
命令:
nice [选项] [优先级] [命令] [命令参数]
[选项]:常见的选项是-n,用于指定 Nice 值。若不使用-n,直接跟数值,系统也会默认将其作为 Nice 值。[优先级]:要设置的 Nice 值,取值范围为 -20 到 19;没有指定Nice值,会使用默认的Nice(通常是0)启动进程。[命令]:要启动的命令或程序。[命令参数]:传递给命令的参数。
例如:
nice ls -l //没有指定Nice
nice -n 10 gzip test.txt //指定Nice为10
nice 10 gzip test.txt //指定Nice为10,但没有-n,效果一样
注意:
- 权限限制:普通用户只能设置大于等于 0 的 Nice 值,也就是只能降低进程的优先级,不能提高。因为提高进程优先级可能会影响系统的稳定性和其他进程的正常运行。只有超级用户(root)可以设置负的 Nice 值,从而提高进程的优先级。
- 实时进程:
nice命令对实时进程无效。实时进程使用不同的调度策略,其优先级的设置和管理方式与普通进程不同。 - 查看优先级:可以使用
ps -l命令查看进程的 Nice 值,NI列会显示进程的当前 Nice 值。
八、进程切换
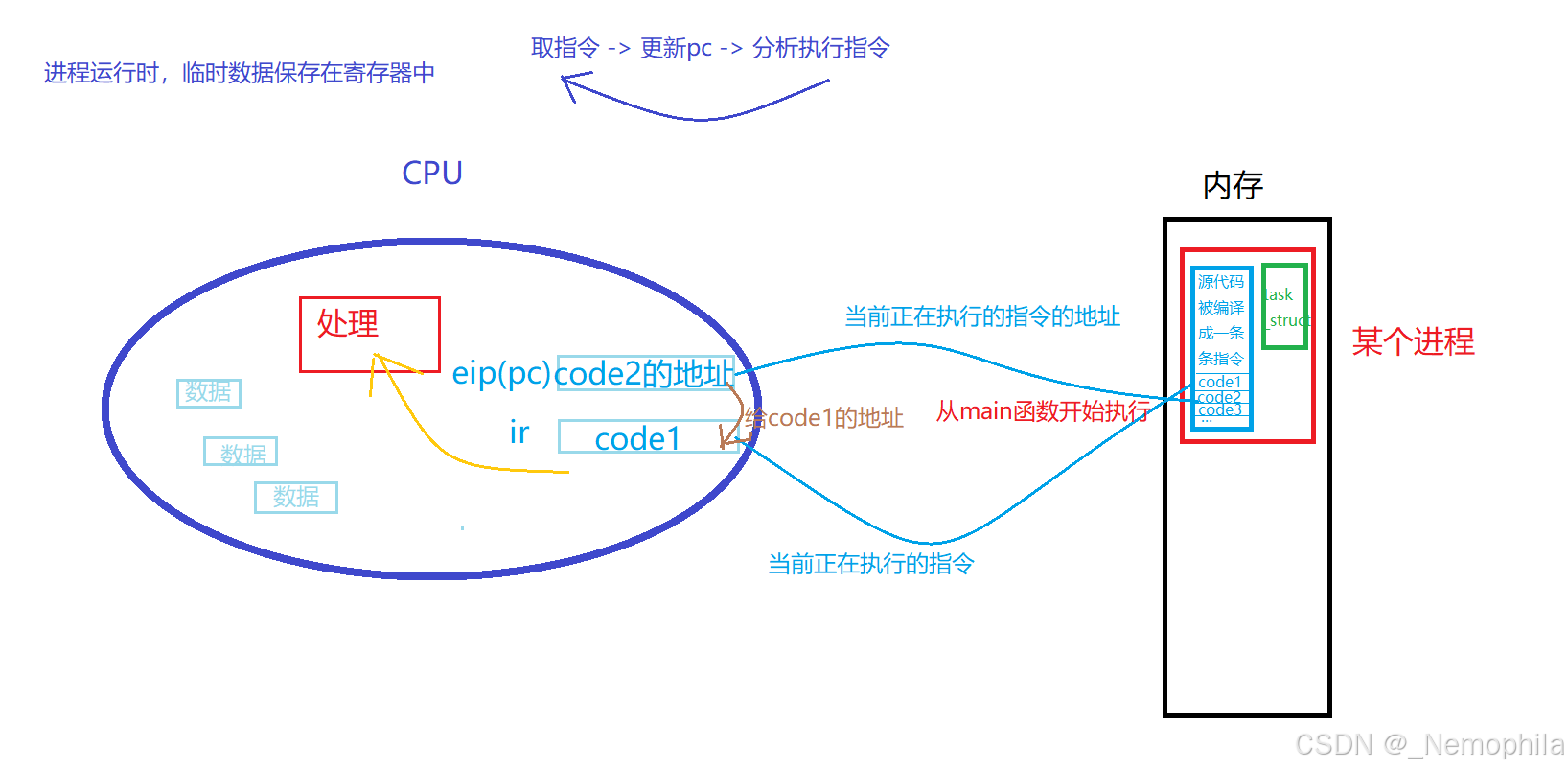
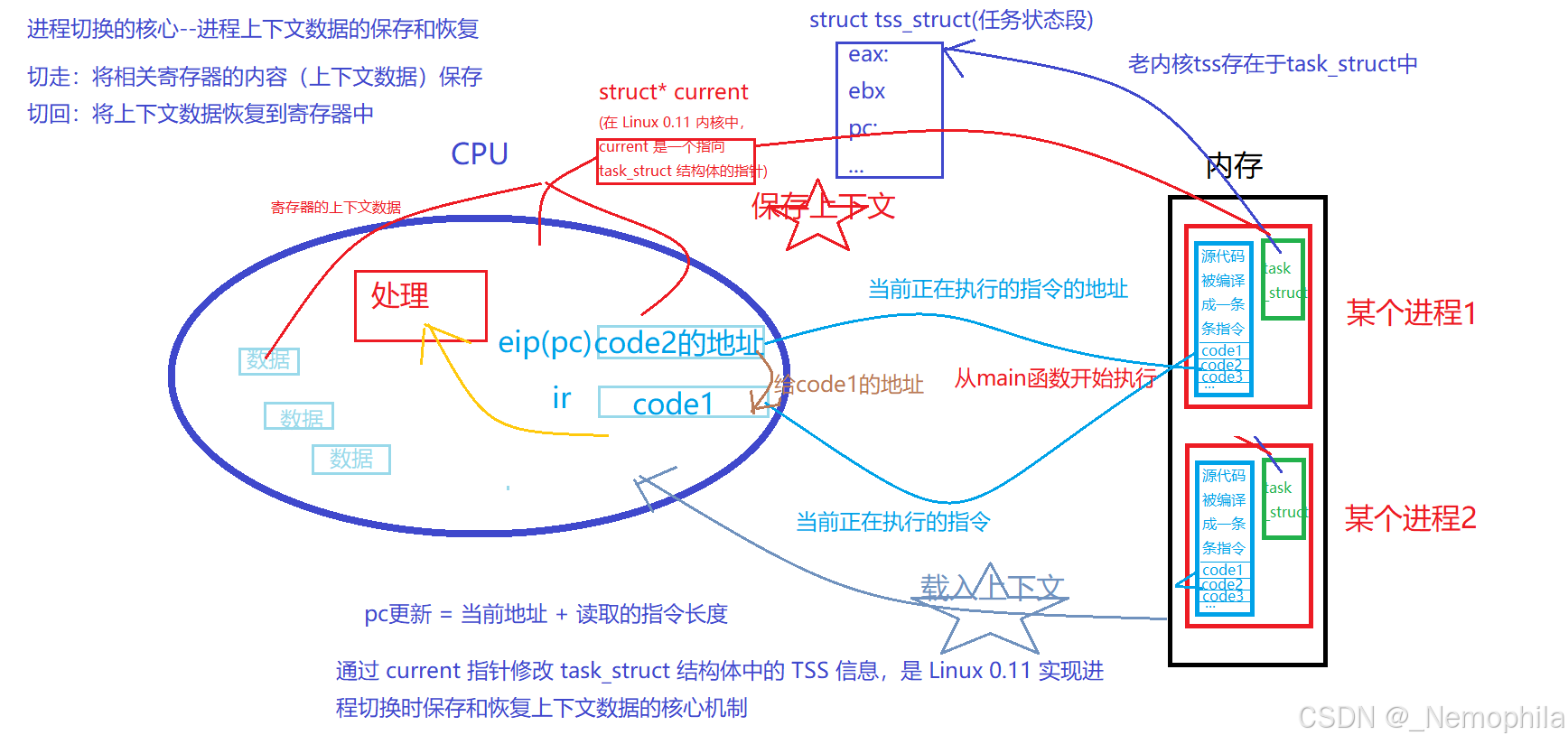
CPU上下文切换:其实际含义是任务切换,或者CPU寄存器切换。当多任务内核决定运行另外的任务时(时间片到达),它保存正在运行任务的当前状态,也就是CPU寄存器中的全部内容(进程运行时,会有很多临时数据,都在CPU的寄存器中保存)。这些内容被保存在任务自己的堆栈中(任务状态段),入栈工作完成后就把下一个将要运行的任务的当前状况从该任务的栈中重新装入CPU寄存器并开始下一个任务的运行,这一过程就是context switch。
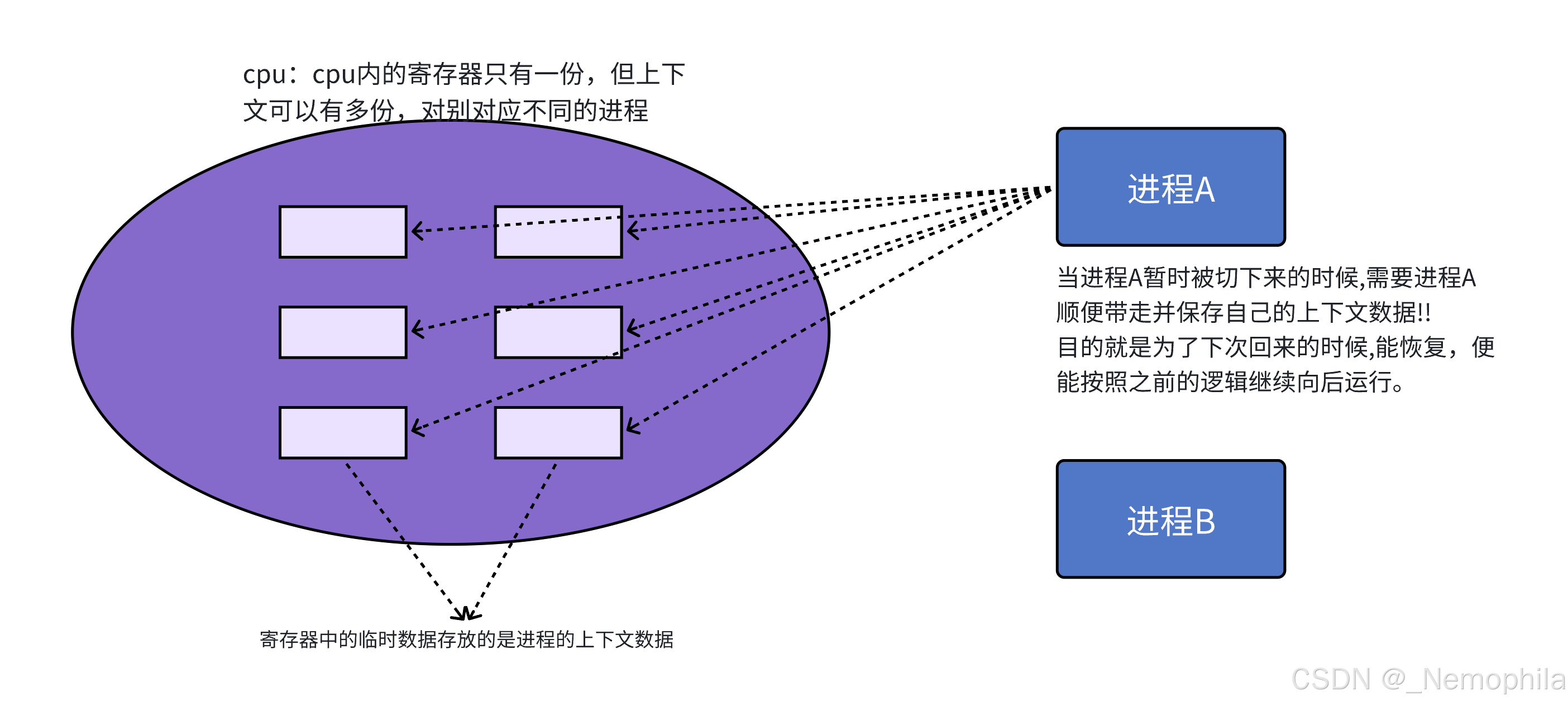
Linux内核0.11版本代码中的tss(早期操作系统内核中,将进程上下文数据保存于 PCB(进程控制块)以及 PCB 中任务状态段(TSS)结构里 ):

- eip(pc)寄存器:保存当前正在执行指令的下一条指令的地址
- ir寄存器:指令寄存器,保存正在执行的指令
- CPU内部有很多个寄存器,合为一套寄存器,寄存器的数据,是进程执行时的瞬时状态信息数据,这些寄存器的数据就是上下文数据
进程被调度执行的大概流程:
进程切换的大概流程:
九、进程调度(进程O(1)调度队列)
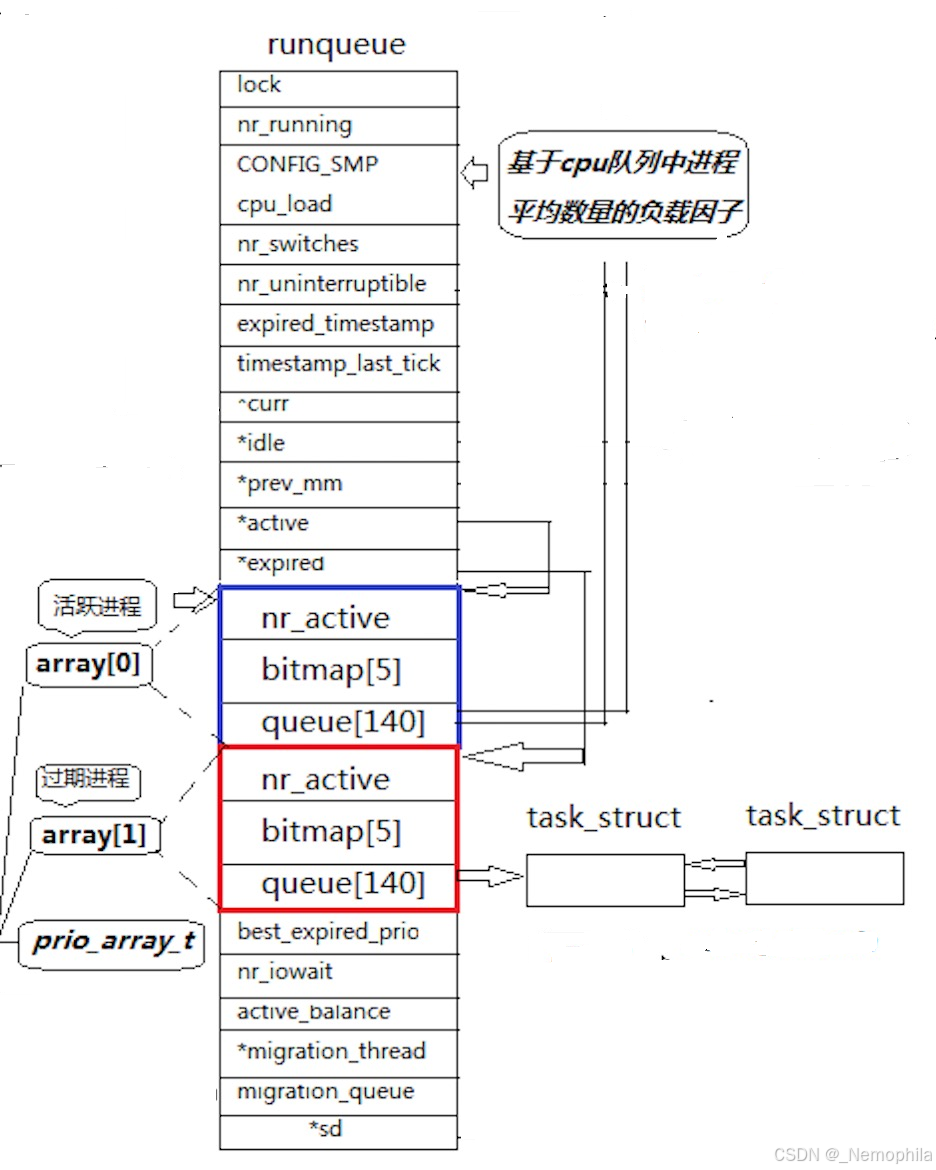
Linux2.6内核中**进程运行队列(runqueue)**的数据结构:
 一个CPU拥有一个runqueue
一个CPU拥有一个runqueue- 如果有多个CPU就要考虑进程个数的负载均衡问题
1.优先级–优先级数组queue[140]
runqueue中,可以发现无论时活跃进程还是过期进程,都有queue[140]数组。
- 数组大小与优先级范围:数组的大小为 140,这是因为在该调度算法里,进程的优先级范围是 0 - 139,其中 0 - 99 是实时进程的优先级,100 - 139 是普通进程的优先级。数组的每个元素对应一个特定的优先级,即
queue[i]对应优先级为i的进程队列。 - 队列结构:数组的每个元素实际上是一个双向链表的头指针,这些链表用于存放具有相同优先级的可运行进程(task_struct)。也就是说,所有处于可运行状态且优先级相同的进程会被组织成一个双向链表,而
q**ueue[i]**指向优先级为i的进程链表的头部。 - 普通进程优先级计算:数组下标 = PRI - StarPRI(60) + 100
通过上面的学习已知,Nice:[-20,19],PRI:[80-20, 80+19]=[60,99],所以数组下标可以映射到[100,139]
2.进程饥饿问题
进程饥饿指的是在系统中,某些进程由于长期无法获得必要的资源或调度机会,从而一直无法向前推进的现象。这些进程可能会被无限期地延迟,尽管它们处于就绪状态,有能力运行,但却始终得不到 CPU 等资源来执行。(例如,在一个基于优先级的调度系统中,如果高优先级的进程不断到来,那么低优先级的进程可能会一直处于饥饿状态。)
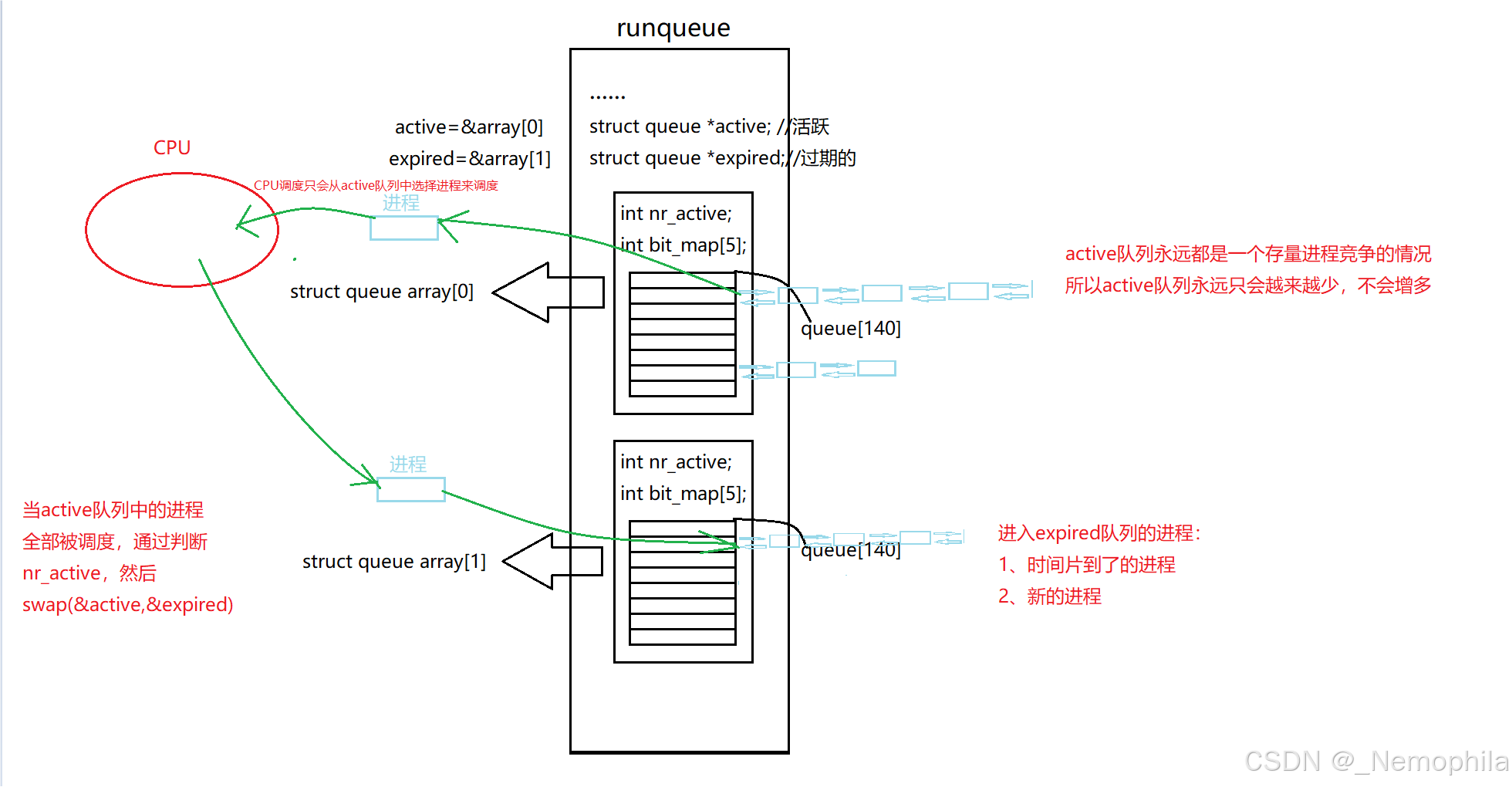
这就需要活跃队列(active)和过期队列(expired)来解决进程饥饿。
3.活跃队列(active)和过期队列(expired)
活跃队列:
- 定义:活跃队列是一个存储当前可运行进程的队列集合。在 O (1) 调度器中,活跃队列由一个优先级数组组成,数组大小为 140,对应 0 - 139 的优先级范围(其中 0 - 99 为实时进程优先级,100 - 139 为普通进程优先级)。数组的每个元素是一个双向链表,用于存放具有相同优先级的可运行进程。
- 作用:调度器从活跃队列中选择下一个要执行的进程。调度器会优先选择优先级最高的非空链表中的进程,以保证高优先级进程能够优先获得 CPU 资源。
过期队列:
- 定义:过期队列同样是一个优先级数组,结构与活跃队列相同。当一个进程的时间片用完后,它会被从活跃队列移动到过期队列。
- 作用:过期队列用于存储那些已经用完时间片的进程。当活跃队列中的所有进程都执行完毕后,调度器会交换活跃队列和过期队列,将过期队列变为新的活跃队列,继续进行调度。这样可以避免频繁地计算进程的优先级,提高调度效率。
调度流程:
- 进程入队:当一个进程进入可运行状态时,它会被添加到活跃队列中对应优先级的链表尾部。
- 进程调度:调度器从活跃队列中选择优先级最高的非空链表中的第一个进程执行。当该进程的时间片用完后,它会被移动到过期队列中。
- 队列交换:当活跃队列中的所有进程都执行完毕后,调度器会交换活跃队列和过期队列,即将过期队列变为新的活跃队列,同时将原来的活跃队列清空,准备接收新的过期进程。
int nr_active记录队列中有多少进程,这个变量决定了active和expired指针指向什么时候进程交换。
4.进程调度O(1)算法
当选择一个进程来调度时,正常的顺序是:
- 从0下标开始遍历 queue[140]
- 找到第一个非空队列,该队列必定为优先级最高的队列
- 拿到选中队列的第一个进程,开始运行,调度完成
- 继续选择选中队列的第一个进程,如果该队列已经为空,继续遍历queue直到遇到下一个非空队列再继续第3步
虽然遍历 queue[140]的时间复杂度是常数,但还是太低效了,还有优化的空间。
调度算法优化:bitmap[5]有5*32个比特位,queue一共有140个进程优先级队列;可以利用bitmap[5]前140个比特位来充当位图,来表示140个进程队列是否为空,这样可以大大提高查找效率。
代码模拟:
for(int i = 0; i < 5; i++)
{
if(bit_map[i] == 0) continue; //一次就可以检测32个位置
else
{
//32个比特位中确定哪个队列--用位运算实现 x &= (x - 1)
}
}
在没有使用 bitmap[5] 时,调度器需要遍历整个 queue[140] 数组,直到找到第一个非空队列,时间复杂度为 O (140)。而使用 bitmap[5] 后,通过 find_first_bit 函数可以在常数时间内找到第一个为 1 的比特位,即最高优先级的非空队列,大大提高了查找效率。
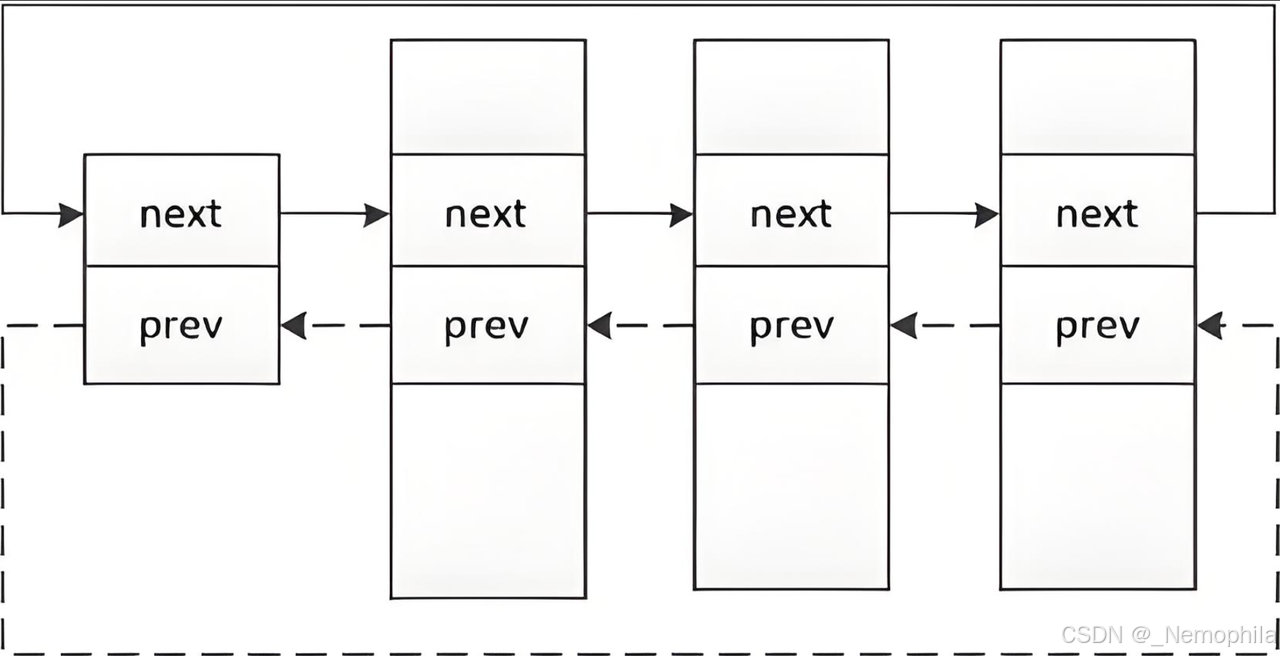
十、进程存在于多个数据结构中
所有进程的task_struct都是用双链表的形式连接,无论是在运行队列里,还是在阻塞队列里,又或在其他数据结构中。
一个进程的task_struct是怎么做到同时存在于多个数据结构呢?
常规的做法是在task_struct内部添加next和prev指针,来连接其他节点:
struct task_struct {
// 其他属性
// ...
struct task_struct *next; // 指向下一个任务结构
struct task_struct *prev; // 指向前一个任务结构
};
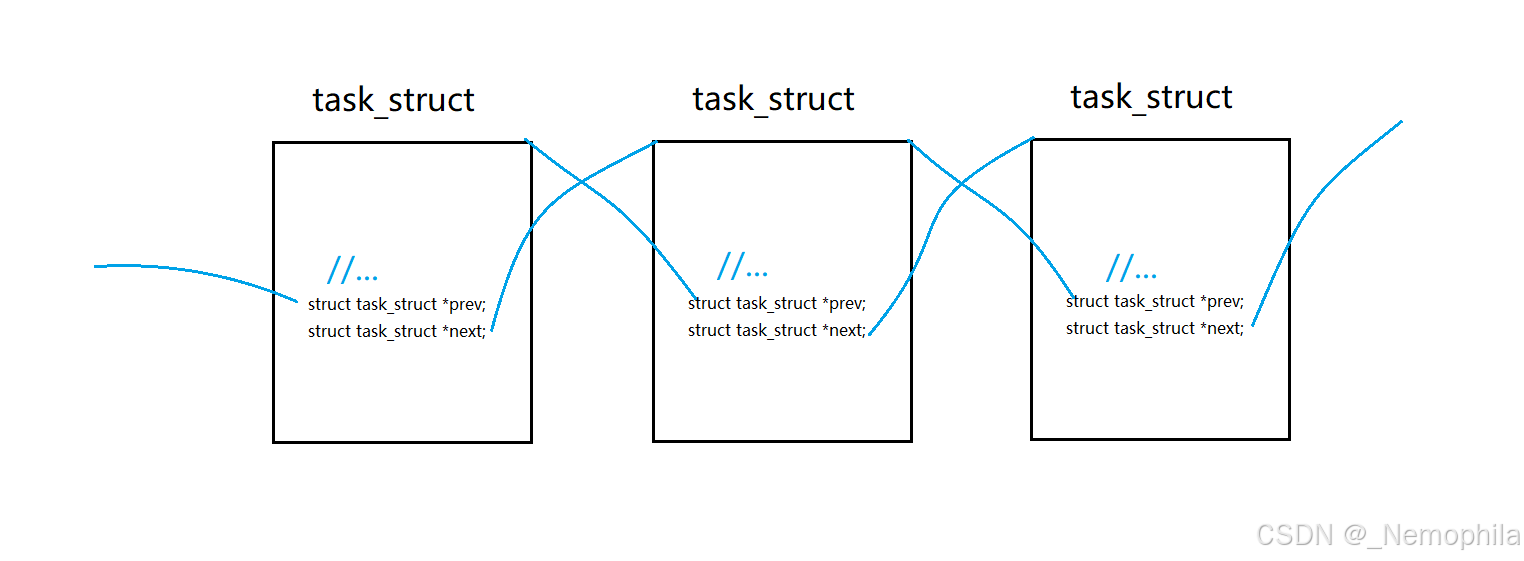
但常规做法会发现,如果在多个数据结构中,就要多添加几个prev和next指针,这不便于数据结构分离,没有灵活性。
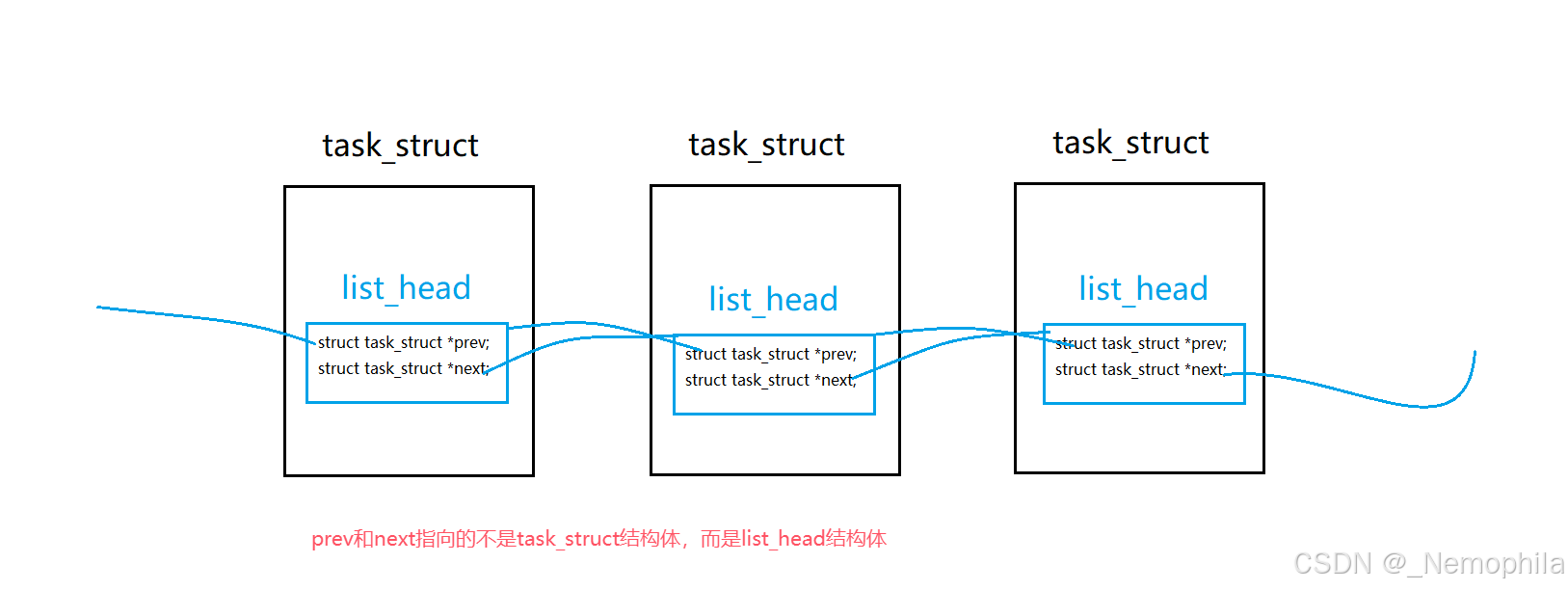
在 Linux 内核里,task_struct 并不直接添加 prev 和 next 指针,而是通过内部包含结构体(通常是 struct list_head),该结构体再包含 prev 和 next 指针
#include <stdio.h>
#include <stdlib.h>
// 定义链表节点结构
struct list_head {
struct list_head *next, *prev;
};
// 定义任务结构
struct task_struct {
// 进程的其他属性
pid_t pid;
int priority;
// 嵌入的链表结构
struct list_head run_list;
};
// 初始化进程列表
static struct list_head task_list = {&task_list, &task_list};
// 将进程添加到列表中
void add_task_to_list(struct task_struct *task) {
// 将任务的链表节点添加到任务列表的尾部
task->run_list.next = task_list.next;
task->run_list.prev = &task_list;
task_list.next->prev = &task->run_list;
task_list.next = &task->run_list;
}
// 遍历进程列表
void traverse_task_list() {
struct task_struct *task;
struct list_head *pos;
// 遍历任务列表
for (pos = task_list.next; pos != &task_list; pos = pos->next) {
task = list_entry(pos, struct task_struct, run_list);
// 处理进程
printf("Task PID: %d, Priority: %d\n", task->pid, task->priority);
}
}
// 示例:创建并添加任务
int main() {
struct task_struct task1 = {1001, 10, {0}};
struct task_struct task2 = {1002, 20, {0}};
add_task_to_list(&task1);
add_task_to_list(&task2);
traverse_task_list();
return 0;
}
这样做的优点:
- 代码复用:
内核中很多数据结构都需要使用链表来组织元素,例如进程列表、文件描述符列表等。通过在不同的数据结构(如task_struct)中嵌入struct list_head,可以复用内核提供的一系列通用链表操作函数,像list_add、list_del、list_for_each等。
若每个数据结构都自己实现链表指针和操作函数,会造成代码的大量重复,增加维护成本。而使用struct list_head可以避免这种情况,提高代码的复用性和可维护性。 - 数据结构分离:
将链表指针和操作与具体的数据结构分离,能使代码的逻辑更加清晰。task_struct主要用于描述进程的各种属性和状态,如进程 ID、优先级、寄存器上下文等。将链表指针封装在struct list_head中,可以使task_struct的定义更加专注于进程本身的属性,而链表操作的逻辑则由通用的链表函数来处理。
便于修改:当需要修改链表的实现或者添加新的链表操作时,只需修改struct list_head及其相关的操作函数,而不会影响到task_struct以及其他使用该链表结构的数据结构。 - 类型安全和可移植性
类型安全:使用struct list_head可以保证链表操作的类型安全。内核提供的链表操作函数会处理struct list_head类型的指针,而不是直接操作task_struct指针,这样可以避免在链表操作过程中出现类型错误。
可移植性:由于struct list_head是一个独立的、通用的链表结构,它可以很方便地在不同的数据结构和内核模块中使用,提高了代码的可移植性。
prev和next指向的不是task_struct结构体,而是list_head结构体,那要怎么访问task_struct的内容呢?
原理:内核提供了一个宏 list_entry 来完成从 struct list_head 指针到包含它的外部结构体指针的转换。这个宏利用了结构体成员在内存中连续存储的特性,通过计算 struct list_head 成员在 task_struct 结构体中的偏移量,结合 struct list_head 指针的地址,就能得到 task_struct 结构体的起始地址。
list_entry宏的定义:
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \
(type *)( (char *)__mptr - offsetof(type, member) );})
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
offsetof宏:用于计算结构体TYPE中成员MEMBER的偏移量。它通过将一个空指针强制转换为TYPE类型的指针,然后取成员MEMBER的地址,由于空指针的起始地址为 0,所以得到的地址值就是成员MEMBER在结构体中的偏移量。container_of宏:根据struct list_head指针ptr,结合成员member在结构体type中的偏移量,计算出包含该struct list_head的type结构体的起始地址。list_entry宏:实际上是对container_of宏的封装,方便在链表操作中使用。
【Linux 进程概念】—— 操作系统中的 “生命体”,计算机里的 “多线程”
一整颗红豆于 2025-02-19 14:24:34 发布
引言导入
在计算机系统的底层架构中,操作系统肩负着资源管理与任务调度的重任。当我们启动各类应用程序时,其背后复杂的运作机制便悄然展开。程序,作为静态的指令集合,如何在系统中实现动态执行?
-
进程,这一关键概念应运而生。 -
进程是程序在操作系统中的一次执行实例,它承载着程序运行所需的系统资源、内存空间、执行状态等关键信息,是操作系统进行资源分配和调度的基本单位。深入剖析进程概念,不仅能让我们洞悉操作系统的核心运行机制,更能为后续学习多线程、并发编程等前沿技术筑牢根基。接下来,让我们一同踏上这场探索进程世界的技术之旅。
冯诺依曼体系结构

冯诺依曼体系结构(Von Neumann Architecture)是现代计算机的理论基础,由美籍匈牙利科学家约翰・冯・诺依曼在 1945 年提出(基于早期科学家如埃克特、莫奇利等人的工作)。这一架构的核心思想是 “存储程序”(Stored-Program),即计算机的指令和数据以二进制形式共同存储在同一个存储器中,通过逐条读取指令并按顺序执行来完成任务。
- 我们常见的计算机,如笔记本。我们不常见的计算机,如服务器,大部分都遵守冯诺依曼体系。
关键组成部分
-
运算器(ALU):负责算术和逻辑运算。 -
控制器(CU): 指挥其他部件协调工作(如从内存读取指令、解码并执行)。 -
存储器(内存):存储程序和数据,按地址访问。 -
输入设备(如键盘、鼠标):将外部信息输入计算机。 -
输出设备(如显示器、打印机):将计算结果反馈给用户。 -
(注:运算器 + 控制器 = 中央处理器 CPU)
五大模块的详细功能
-
运算器(ALU, Arithmetic Logic Unit)
负责执行所有算术运算(加减乘除)和逻辑运算(与、或、非、移位)。
通过寄存器(如累加器)临时存储运算数据。
-
控制器(CU, Control Unit)
指令周期:通过 “取指 - 解码 - 执行” 循环驱动计算机工作:
取指(Fetch):从内存中读取下一条指令。
解码(Decode):解析指令含义(如 “将数据从地址 A 加载到寄存器”)。
执行(Execute):向相关部件(如 ALU、内存)发送控制信号完成操作。
通过程序计数器(PC)追踪下一条指令的地址,通过指令寄存器(IR 存储当前指令)
-
存储器(Memory)
按地址访问的线性存储空间,存储程序指令和数据。
内存分级:现代计算机扩展为多级存储(
寄存器→高速缓存→主存→磁盘),缓解速度与容量矛盾。 -
输入 / 输出设备(I/O)
通过总线与 CPU 交互,例如键盘输入数据到内存,或显示器从内存读取结果。
-
总线(Bus)
数据总线:传输指令和数据。
地址总线:指定内存或设备的访问位置。
控制总线:传递控制信号(如读 / 写、中断请求)。
核心特点
-
“存储程序” 思想:程序和数据以二进制形式存储在同一个存储器中,计算机通过读取指令逐条执行,无需物理上重新布线(早期计算机的痛点)。
-
顺序执行:CPU 按内存中的指令顺序依次执行(除非遇到跳转指令)。
-
共享总线:指令和数据通过同一总线传输,可能导致性能瓶颈(即 “冯・诺依曼瓶颈”)。
意义与局限性
-
意义:结束了早期计算机 “专用化” 的设计模式,使通用计算成为可能,推动计算机小型化与普及。
-
局限性:指令和数据共享总线,导致效率受限。现代计算机通过缓存、多级存储、并行计算(如哈佛结构分离指令与数据总线)等方式优化。
关于冯诺依曼,必须强调几点:
-
这里的
存储器指的是内存 -
不考虑缓存情况,这里的 CPU 能且只能对内存进行读写,不能访问外设 (输入或输出设备)
-
外设 (输入或输出设备) 要输入或者输出数据,也只能写入内存或者从内存中读取。
-
⼀句话,所有设备都只能直接和内存打交道。
一句话总结
冯・诺依曼体系结构通过 “存储程序” 和五大模块的协同,定义了计算机如何存储、处理信息,成为现代计算机的基石。
操作系统 (Operator System)
大家熟悉的操作系统:

什么是操作系统
操作系统(Operating System,简称 OS)是计算机系统的核心软件,扮演着 “管理者” 的角色,负责协调硬件资源(如 CPU、内存、硬盘等)与软件应用之间的交互,并为用户和应用程序提供简单、高效的使用环境。
任何计算机系统都包含⼀个基本的程序集合,称为操作系统 (OS)。笼统的理解,操作系统包括:
-
内核(进程管理,内存管理,⽂件管理,驱动管理)
-
其他程序(例如函数库,shell 程序等等)

一句话总结
- 操作系统是一款管理计算机所有软硬件资源的软件
为什么要设计操作系统
-
直接操作硬件的复杂性:普通用户和开发者无法手动管理 CPU 指令、内存地址等底层细节。
-
资源冲突问题:如果没有操作系统协调,多个程序可能同时争夺同一硬件资源,导致崩溃。
-
效率提升:通过优化资源分配(如内存缓存、磁盘调度算法),最大化硬件性能。
简单来说就是
-
对下,与硬件交互,管理所有的软硬件资源
-
对上,为用户程序(应用程序)提供⼀个良好的执行环境

操作系统的构成
内核(Kernel)
- 操作系统的核心,直接管理硬件和关键资源(如内存、进程)。
类型:
-
宏内核(如 Linux):功能集中在内核中,效率高但复杂度高。
-
微内核(如 QNX):仅保留核心功能,其他服务以模块形式运行,稳定性强。
系统服务层
- 提供文件管理、网络通信、设备驱动等基础服务。例如:Windows 的服务管理器(Services.msc)、Linux 的守护进程(Daemon)。
用户界面(Shell)
- 用户与系统交互的入口,如 Windows 资源管理器、macOS 的 Finder。
应用程序接口(API)
- 供开发者调用的标准化接口,例如:Windows 的 Win32 API、Linux 的 POSIX 标准。

操作系统的定位
- 在整个计算机软硬件架构中,操作系统的定位是:⼀款纯正的 “搞管理” 的软件
如何理解 “管理”?
在生活中,所有的管理,无论是校长管理学生,老板管理员工,还是政府管理公民,都离不开一句话 ——先描述,再组织!
就拿校长管理学生的例子来说,校长可以先对每个学生进行全面的描述,一个学生的姓名,学号,性别,年龄,籍贯,紧急联系人,入学年份,毕业年份,高考成绩,绩点,学分,在学校的职位,体测情况,各科成绩…
有了所有学生的描述后,将这些学生组织起来,比如分为班级,学院,宿舍等…
进行统一的管理
站在计算机的角度
-
操作系统就是校长,即管理者
-
各种软硬件资源就是学生,即被管理者
操作系统对软硬件的管理,也遵循着**先描述,再组织!**,即操作系统将各种软硬件通过各自的 结构体 进行描述,再将这些结构体统构成一个全局的 双链表,即操作系统对软硬件的管理就转换成了对链表的 增删查改!

一句话总结
计算机管理软硬件
-
描述起来,用
struct 结构体 -
组织起来,用
链表或其他高效的数据结构
操作系统的核心功能
系统的核心功能是管理和协调计算机硬件与软件资源,为用户和应用程序提供高效、安全且易用的环境。
资源管理:协调硬件与软件资源
处理器(CPU)管理
-
任务调度:通过算法(如轮转调度、优先级调度)决定哪个进程使用 CPU,平衡响应时间和效率。
-
多任务处理:在单核上通过时间片轮转 “模拟” 并行,或在多核上真正并行执行任务。
内存管理
-
分配与回收:为程序分配内存空间,释放不再使用的内存(如关闭程序后)。
-
虚拟内存:利用磁盘空间扩展物理内存,允许运行比实际内存更大的程序。
-
内存保护:防止程序越界访问其他进程的内存(避免崩溃或安全漏洞)。
设备管理
-
驱动程序:为不同硬件(如打印机、显卡)提供统一接口,简化操作。
-
I/O 调度:优化外设访问顺序(如电梯算法减少磁盘寻道时间)。
存储管理(文件系统)
-
文件组织:以目录树形式管理数据,用户无需关心物理存储位置。
-
磁盘空间分配:跟踪空闲区块,高效分配文件存储空间。
用户接口:提供人机交互方式
-
图形界面(GUI)
例如:Windows 的桌面、macOS 的访达,用户通过点击图标、拖拽文件操作。
-
命令行界面(CLI)
例如:Linux 的 Terminal,输入命令(如 ls、cp)直接控制系统。
-
应用程序接口(API)
开发者调用系统功能(如 “打开摄像头”),无需重写底层代码。
抽象与简化:隐藏硬件复杂性
-
硬件抽象层(HAL)
将硬件差异(如不同厂商的 CPU 指令)封装成统一指令,实现跨设备兼容。
例如:游戏开发者调用 DirectX API,无需为每款显卡单独适配。
-
系统调用(System Call)
提供标准接口供程序请求服务(如读写文件、创建进程)。
多任务与进程管理
-
进程与线程
-
进程:独立运行的程序实例(如同时打开两个浏览器窗口)。
-
线程:进程内的子任务(如浏览器同时下载文件和渲染页面)。
-
-
进程同步与通信
- 协调多个进程访问共享资源(如信号量、互斥锁)。
- 例如:防止两个程序同时修改同一文件导致数据损坏。
安全与权限控制
-
用户身份验证
登录密码、指纹识别等确保合法用户访问。
-
访问控制列表(ACL)
限制用户或程序对文件、设备的操作权限(如只读、不可执行)。
-
沙箱机制
隔离高风险程序(如浏览器插件),防止其破坏系统。
错误检测与容错
-
异常处理
捕获硬件错误(如内存溢出)或软件崩溃,避免系统宕机。
-
日志记录
记录系统事件(如错误、用户操作),便于故障排查。
操作系统的核心功能本质是让复杂变得简单,用户无需理解硬件细节即可高效使用计算机,同时确保资源公平、安全地服务于所有任务。
库函数和系统调用
-
在开发角度,操作系统对外会表现为⼀个整体,但是会暴露自己的部分接口,供上层开发使用,这部分由操作系统提供的接口,叫做
系统调用。 -
系统调用在使用上,功能比较基础,对用户的要求相对也比较高,所以,有心的开发者可以对部分系统调用进行适度封装,从而形成库,有了
库函数,就很有利于更上层用户或者开发者进行⼆次开发。

核心定义
| 库函数 | 系统调用 |
|---|---|
由编程语言或第三方库提供的预定义函数(如 C 标准库的 printf ()) | 操作系统内核提供的底层接口(如 Linux 的 read ()) |
| 运行在用户态,无权限切换开销 | 需切换至内核态(通过软中断或特殊指令) |
示例:fopen () 内部可能调用 open () 系统调用 | 示例:直接操作硬件资源(如内存分配、进程调度) |
交互关系
库函数调用系统调用的方式
-
直接封装
示例:
fopen ()→open () -
间接组合
示例:
printf ()→ 格式化数据 →write ()
系统调用的独立性
-
可通过汇编直接调用(如 Linux 汇编调用
exit ()) -
实际开发中通常通过库函数间接调用
典型示例
| 场景 | 库函数 | 系统调用 |
|---|---|---|
| 文件操作 | fread (), fwrite () | read (), write () |
| 内存管理 | malloc (), free () | brk (), mmap () |
| 网络通信 | send (), recv () | sendto (), recvfrom () |
| 进程控制 | system () | fork (), execve () |
关键设计差异
系统调用的限制
-
安全性:受严格权限控制(如普通用户无法调用
reboot ()) -
易用性:隐藏底层细节(如
printf ()自动类型转换) -
跨平台:通过适配不同系统调用实现 “一次编写,多处编译”
总结:两者协作的意义
-
效率与安全平衡:高频操作用户态处理,敏感操作内核态管控
-
抽象层级分离:开发者友好接口 vs 硬件直接控制
-
生态兼容性:屏蔽系统差异,提升代码可移植性
库函数与系统调用对比指南
基础对比表(单层结构)
| 对比维度 | 库函数 | 系统调用 |
|---|---|---|
| 定义 | 编程语言或第三方库提供的函数(如 printf ()) | 操作系统内核提供的底层接口(如 read ()) |
| 运行模式 | 始终在用户态执行 | 需从用户态切换到内核态(通过中断 / 特殊指令) |
| 性能开销 | 低(无权限切换) | 高(上下文切换消耗资源) |
| 可移植性 | 依赖库的跨平台能力 | 与操作系统强绑定 |
| 功能特性 | 封装逻辑或组合多个系统调用 | 直接操作硬件资源(内存 / 设备 / 进程等) |
快速记忆表格(高亮关键区别)
| 特性 | 🧩 库函数 | ⚙️ 系统调用 |
|---|---|---|
| 调用方式 | 直接函数调用 | 需通过软中断(如 int 0x80) |
| 失败处理 | 通常返回错误码 | 设置全局 errno 变量 |
| 执行速度 | 纳秒级(无上下文切换) | 微秒级(涉及内核切换) |
| 版本依赖 | 随库更新可能变化 | 保持长期兼容性 |
| 典型示例 | strlen (), qsort () | getpid (), sched_yield () |
操作系统是怎么管理进行进程管理的呢?
很简单,先把进程描述起来,再把进程组织起来
进程概念和查看
进程是操作系统中资源分配和调度的基本单位,是计算机程序运行的实例化体现。
-
课本概念:程序的⼀个执行实例,正在执行的程序等
-
内核观点:担当分配系统资源(CPU 时间,内存)的实体。
进程控制块 — PCB
进程的描述信息被放在⼀个叫做 进程控制块 的数据结构中,可以理解为进程属性的集合。课本上称之为 PCB(process control block)
在 Linux 中描述进程的结构体叫做 task_struct,task_struct 是 PCB 的⼀种
task_struct是 Linux 内核的⼀种数据结构,它会被装载到 RAM (内存) ⾥并且包含着进程的信息。
Linux 下的 task_struct
内容分类:
-
标识符:描述本进程的唯⼀标识符,用来区别其他进程。
-
状态:任务状态,退出代码,退出信号等。
-
优先级:相对于其他进程的优先级。
-
程序计数器:程序中即将被执行的下⼀条指令的地址。
-
内存指针:包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
-
上下文数据:进程执行时处理器的寄存器中的数据 [要加图 CPU,寄存器 ]。
-
I/O 状态信息:包括显⽰的 I/O 请求,分配给进程的 I∕O 设备和被进程使用的文件列表。
-
记账信息:可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
进程标识信息
pid_t pid; // 进程 ID
pid_t tgid; // 线程组 ID(主线程 PID)
struct task_struct *group_leader; // 线程组领导者
进程状态管理
volatile long state; // 进程状态
/* 典型状态值:
TASK_RUNNING (0) 可运行
TASK_INTERRUPTIBLE (1) 可中断睡眠
TASK_UNINTERRUPTIBLE (2) 不可中断睡眠
__TASK_STOPPED (4) 停止状态
EXIT_DEAD (16) 终止状态 */
进程调度相关
int prio; // 动态优先级
int static_prio; // 静态优先级(nice 值映射)
const struct sched_class *sched_class; // 调度器类指针
struct sched_entity se; // CFS 调度实体
虚拟内存管理
struct mm_struct *mm; // 内存描述符(用户空间)
struct mm_struct *active_mm; // 活跃内存描述符(内核线程使用)
文件系统
struct files_struct *files; // 打开文件表
struct fs_struct *fs; // 根目录 / 工作目录信息
进程信号处理
struct signal_struct *signal; // 信号处理结构体
struct sighand_struct *sighand; // 信号处理函数表
sigset_t blocked; // 被阻塞信号掩码
进程关系
struct task_struct *real_parent; // 实际父进程(fork 创建者)
struct task_struct *parent; // 法定父进程(接收 SIGCHLD)
struct list_head children; // 子进程链表
struct list_head sibling; // 兄弟进程链表
时间统计
u64 utime; // 用户态 CPU 时间(纳秒)
u64 stime; // 内核态 CPU 时间
struct task_cputime cputime_expires; // CPU 时间限制
组织进程
可以在内核源代码里找到它。所有运行在系统里的进程都以 task_struct 链表的形式存在内核里。

查看系统中的进程
基本命令与工具
ps 命令(Process Status)静态快照显示当前进程信息。
ps aux # 查看所有用户的所有进程(BSD 风格)
ps -ef # 全格式显示进程(System V 风格)
ps -u root # 查看指定用户(如 root)的进程
ps -p 1234 # 查看特定 PID(如 1234)的进程
输出字段:
-
PID:进程 ID -
USER:进程所有者 -
% CPU/% MEM:CPU 和内存占用率 -
STAT:进程状态(如 R = 运行,S = 睡眠,Z = 僵尸) -
COMMAND:启动进程的命令
例如:(只截取了一部分进程)
[zwy@iZbp1dkpw5hx2lyh7vjopaZ ~]$ ps aux
USER PID % CPU % MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.2 191052 4084 ? Ss Jan14 0:34 /usr/lib/systemd/systemd --switch
root 2 0.0 0.0 0 0 ? S Jan14 0:00 [kthreadd]
root 4 0.0 0.0 0 0 ? S< Jan14 0:00 [kworker/0:0H]
root 5 0.0 0.0 0 0 ? S Jan14 0:08 [kworker/u4:0]
root 6 0.0 0.0 0 0 ? S Jan14 0:00 [ksoftirqd/0]
root 7 0.0 0.0 0 0 ? S Jan14 0:00 [migration/0]
top /htop 命令,动态实时监控进程资源占用。
例如:top 命令

例如:(有些系统下可能没有预装 htop 命令,需要手动下载)
Centos 下:
sudo yum install -y htop
htop 命令

关键操作:
-
按 P(CPU 排序)、M(内存排序)、k(终止进程)。
-
htop 支持直接展开线程(按 F2 配置显示项)。
pstree 命令以树形结构显示进程父子关系。
pstree -p # 显示 PID
pstree -A # 用 ASCII 字符简化显示
例如:
pstree -p 命令

例如:
pstree-A 命令

查看进程详细信息
进程状态文件(/proc 文件系统)
路径:/proc/<PID>/
其中 PID 是要查看的进程 id
cat /proc/PID/status # 查看进程状态(内存、线程数等)
cat /proc/PID/cmdline # 查看启动命令的完整参数
例如:
查看 PID 为 1 的进程状态,实际上 PID 为 1 的进程是操作系统,Linux 下叫做 systemd

例如:
同样查看 systemd 进程的启动命令的完整参数
[zwy@iZbp1dkpw5hx2lyh7vjopaZ process]$ cat /proc/1/cmdline
/usr/lib/systemd/systemd--switched-root--system--deserialize22
根据名称或内容过滤
例如:
ps ajx | grep process #查找过滤叫做 process 的进程

[zwy@iZbp1dkpw5hx2lyh7vjopaZ ~]$ ps ajx | grep process
31995 32114 32114 31995 pts/0 32114 S+ 1000 0:00 ./process
32114 32115 32114 31995 pts/0 32114 S+ 1000 0:00 ./process
32119 32147 32146 32119 pts/1 32146 S+ 1000 0:00 grep --color=auto process
结合 head 命令将头一行提取出来
ps ajx | head -1 && ps ajx | grep process

[zwy@iZbp1dkpw5hx2lyh7vjopaZ ~]$ ps ajx | head -1 && ps ajx | grep process
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
31995 32114 32114 31995 pts/0 32114 S+ 1000 0:00 ./process
32114 32115 32114 31995 pts/0 32114 S+ 1000 0:00 ./process
32119 32151 32150 32119 pts/1 32150 S+ 1000 0:00 grep --color=auto process
也可以根据进程的 PID 进行过滤查找
例如:
ps ajx | head -1 && ps ajx | grep 32114

[zwy@iZbp1dkpw5hx2lyh7vjopaZ ~]$ ps ajx | head -1 && ps ajx | grep 32114
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
31994 31995 31995 31995 pts/0 32114 Ss 1000 0:00 -bash
31995 32114 32114 31995 pts/0 32114 S+ 1000 0:00 ./process
32114 32115 32114 31995 pts/0 32114 S+ 1000 0:00 ./process
32119 32155 32154 32119 pts/1 32154 S+ 1000 0:00 grep --color=auto 32114
其中过滤出来的 grep --color=auto 32114 这个进程,是因为使用 grep 过滤时,其本身也是一个进程,包含了要过滤进程的信息,所以也会被找出来,如果不想让其显示,可以使用 grep -v grep 反向过滤掉。
例如:

[zwy@iZbp1dkpw5hx2lyh7vjopaZ ~]$ ps ajx | head -1 && ps ajx | grep 32114 | grep -v grep
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
31994 31995 31995 31995 pts/0 32114 Ss 1000 0:00 -bash
31995 32114 32114 31995 pts/0 32114 S+ 1000 0:00 ./process
32114 32115 32114 31995 pts/0 32114 S+ 1000 0:00 ./process
根据资源占用排序
ps aux --sort=-% cpu | head -10 # 按 CPU 占用降序显示前 10 进程
ps aux --sort=-% mem | head -10 # 按内存占用降序显示前 10 进程
例如:查看 CPU 占用前 10 进程
ps aux --sort=-% cpu | head -10

例如:查看内存占用前 10 内存
ps aux --sort=-% mem | head -10

拓展阅读:
task_struct 数据结构
jurrah 于 2009-03-07 11:11:00 发布
在 Linux 中,每一个进程都由 task_struct 数据结构来定义。task_struct 通常被称为进程控制块(PCB),它是对进程控制的唯一且最有效的手段。当我们调用 fork() 时,系统会为我们生成一个 task_struct 结构,然后从父进程继承一些数据,并将新的进程插入到进程树中,以便进行进程管理。因此,了解 task_struct 的结构对于我们理解任务调度(在 Linux 中,任务和进程是同一概念)至关重要。
在剖析 task_struct 的定义之前,我们先根据理论推导它的结构:
- 进程状态:记录进程在等待、运行或死锁等状态。
- 调度信息:由哪个调度函数调度,以及如何调度等信息。
- 进程的通信状况。
- 父子兄弟关系指针:因为要插入进程树,必须有联系父子兄弟的指针,类型为
task_struct。 - 时间信息:例如计算好执行的时间,以便 CPU 分配。
- 标号:决定该进程的归属。
- 可读写文件信息。
- 进程上下文和内核上下文。
- 处理器上下文。
- 内存信息。
每一个 PCB 都包含这些结构,只有这些结构才能满足一个进程的所有要求。打开 /include/linux/sched.h 可以找到 task_struct 的定义:
struct task_struct {
volatile long state; /* 说明该进程是否可以执行,还是可中断等信息 */
unsigned long flags; /* Flags 是进程号,在调用 fork() 时给出 */
int sigpending; /* 进程上是否有待处理的信号 */
mm_segment_t addr_limit;
/******************/
/* 进程地址空间,区分内核进程与普通进程在内存存放的位置不同 */
/* 0-0xBFFFFFFF for user-thread ****** */
/* 0-0xFFFFFFFF for kernel-thread ****** */
/******************/
volatile long need_resched;
/******************/
/** 调度标志,表示该进程是否需要重新调度 **/
/** 若非 0,则当从内核态返回到用户态时,会发生调度 **/
/******************/
int lock_depth; /* 锁深度 */
long nice; /* 进程的基本时间片 */
unsigned long policy;
/******************/
/* 进程的调度策略,有三种 */
/* 实时进程:SCHED_FIFO, SCHED_RR */
/* 分时进程:SCHED_OTHER */
/******************/
/******************/
struct mm_struct mm; /* 进程内存管理信息 */
int processor;
/******************/
/* 若进程不在任何 CPU 上运行,
cpus_runnable 的值是 0,否则是 1。
这个值在运行队列被锁时更新。 */
/******************/
unsigned long cpus_runnable, cpus_allowed;
struct list_head run_list; /* 指向运行队列的指针 */
unsigned long sleep_time; /* 进程的睡眠时间 */
struct task_struct *next_task, *prev_task;
/******************/
/* 用于将系统中所有的进程连成一个双向循环链表,
其根是 init_task。 */
/******************/
struct mm_struct *active_mm;
struct list_head local_pages; /* 指向本地页面 */
unsigned int allocation_order, nr_local_pages;
struct linux_binfmt binfmt; /* 进程所运行的可执行文件的格式 */
int exit_code, exit_signal;
int pdeath_signal; /* 父进程终止时向子进程发送的信号 */
unsigned long personality;
/* Linux 可以运行由其他 UNIX 操作系统生成的符合 iBCS2 标准的程序 */
int did_exec:1;
/******************/
/* 按 POSIX 要求设计的布尔量,区分进程正在执行从
父进程中继承的代码,还是执行由 execve 装入的新程序代码 */
/******************/
pid_t pid; /* 进程标识符,用来代表一个进程 */
pid_t pgrp; /* 进程组标识,表示进程所属的进程组 */
pid_t tty_old_pgrp; /* 进程控制终端所在的组标识 */
pid_t session; /* 进程的会话标识 */
pid_t tgid;
int leader; /* 标志,表示进程是否为会话主管 */
struct task_struct p_opptr, p_pptr, p_cptr, p_ysptr, *p_osptr;
struct list_head thread_group; /* 线程链表 */
struct task_struct pidhash_next; /* 用于将进程链入 HASH 表 pidhash */
struct task_struct pidhash_pprev;
wait_queue_head_t wait_chldexit; /* 供 wait4() 使用 */
struct completion vfork_done; /* 供 vfork() 使用 */
unsigned long rt_priority;
/* 实时优先级,用它计算实时进程调度时的 weight 值 */
/* it_real_value,it_real_incr 用于 REAL 定时器,单位为 jiffies */
/* 系统根据 it_real_value 设置定时器的第一个终止时间。
在定时器到期时,向进程发送 SIGALRM 信号,同时根据 it_real_incr 重置终止时间 */
/* it_prof_value,it_prof_incr 用于 Profile 定时器,单位为 jiffies。
当进程运行时,不管在何种状态下,每个 tick 都使 it_prof_value 值减一,
当减到 0 时,向进程发送信号 SIGPROF,并根据 it_prof_incr 重置时间 */
/* it_virt_value,it_virt_value 用于 Virtual 定时器,单位为 jiffies。
当进程运行时,不管在何种状态下,每个 tick 都使 it_virt_value 值减一,
当减到 0 时,向进程发送信号 SIGVTALRM,根据 it_virt_incr 重置初值 */
/* Real 定时器根据系统时间实时更新,不管进程是否在运行 */
/* Virtual 定时器只在进程运行时,根据进程在用户态消耗的时间更新 */
/* Profile 定时器在进程运行时,根据进程消耗的时间(不管在用户态还是内核态)更新 */
unsigned long it_real_value, it_prof_value, it_virt_value;
unsigned long it_real_incr, it_prof_incr, it_virt_incr;
struct timer_list real_timer; /* 指向实时定时器的指针 */
struct tms times; /* 记录进程消耗的时间 */
unsigned long start_time; /* 进程创建的时间 */
long per_cpu_utime[NR_CPUS], per_cpu_stime[NR_CPUS]; /* 记录进程在每个 CPU 上所消耗的用户态时间和核心态时间 */
/******************/
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
/* 内存缺页和交换信息: */
/* min_flt, maj_flt 累计进程的次缺页数(Copy on Write 页和匿名页)和主缺页数(从映射文件或交换设备读入的页面数) */
/* nswap 记录进程累计换出的页面数,即写到交换设备上的页面数 */
/* cmin_flt, cmaj_flt, cnswap 记录本进程为祖先的所有子孙进程的累计次缺页数,主缺页数和换出页面数 */
/* 在父进程回收终止的子进程时,父进程会将子进程的这些信息累计到自己结构的这些域中 */
/******************/
unsigned long min_flt, maj_flt, nswap, cmin_flt, cmaj_flt, cnswap;
int swappable:1; /* 表示进程的虚拟地址空间是否允许换出 */
/******************/
/* process credentials *进程认证信息 */
/* uid,gid 为运行该进程的用户的用户标识符和组标识符,通常是进程创建者的 uid,gid */
/* euid,egid 为有效 uid,gid */
/* fsuid,fsgid 为文件系统 uid,gid,这两个 ID 号通常与有效 uid,gid 相等,在检查对于文件系统的访问权限时使用他们 */
/* suid,sgid 为备份 uid,gid */
/******************/
uid_t uid, euid, suid, fsuid;
gid_t gid, egid, sgid, fsgid;
int ngroups; /* 记录进程在多少个用户组中 */
gid_t groups
[NGROUPS]; /* 记录进程所在的组 */
kernel_cap_t cap_effective, cap_inheritable, cap_permitted; /* 进程的权能,分别是有效位集合,继承位集合,允许位集合 */
int keep_capabilities:1;
struct user_struct user;
/******************/
/* limits */
struct rlimit rlim[RLIM_NLIMITS]; /* 与进程相关的资源限制信息 */
unsigned short used_math; /* 是否使用 FPU */
char comm[16]; /* 进程正在运行的可执行文件名 */
/******************/
/* file system info *///文件系统信息
int link_count, total_link_count;
struct tty_struct tty; /* NULL if no tty 进程所在的控制终端,如果不需要控制终端,则该指针为空 */
unsigned int locks; /* How many file locks are being held */
/******************/
/* ipc stuff *///进程间通信信息
struct sem_undo *semundo; /* 进程在信号灯上的所有 undo 操作 */
struct sem_queue semsleeping; /* 当进程因为信号灯操作而挂起时,他在该队列中记录等待的操作 */
/******************/
/* CPU-specific state of this task ///进程的 CPU 状态,切换时,要保存到停止进程的 task_struct 中 */
struct thread_struct thread;
/******************/
/* filesystem information文件系统信息 */
struct fs_struct fs;
/******************/
/* open file information *///打开文件信息
struct files_struct files;
/******************/
/* signal handlers ///信号处理函数 */
spinlock_t sigmask_lock; /* Protects signal and blocked */
struct signal_struct sig; /* 信号处理函数 */
sigset_t blocked; /* 进程当前要阻塞的信号,每个信号对应一位 */
struct sigpending pending; /* 进程上是否有待处理的信号 */
unsigned long sas_ss_sp;
size_t sas_ss_size;
int (*notifier)(void *priv);
void *notifier_data;
sigset_t notifier_mask;
/******************/
/* Thread group tracking */
u32 parent_exec_id;
u32 self_exec_id;
/******************/
/* Protection of (de-)allocation: mm, files, fs, tty */
spinlock_t alloc_lock;
void *journal_info; /* journalling filesystem info */
};
本文到这里就结束了!
【Linux 进程状态】—— 从创建到消亡的全生命周期
一整颗红豆 于 2025-02-26 20:57:21 发布
引言
在开始之前,我先给大家灌输一个观点:
进程 = 内核数据结构 + 自己的代码和数据
- 内核数据结构就是
进程控制块 PCB,(process control block),在 Linux 操作系统下叫做task_struct,是 Linux 内核中定义的结构体。 - 自己的代码就是进程所对应的要执行的程序指令序列,在进程运行时被操作系统加载到内存中由
CPU执行。 - 自己的数据就是进程在运行过程中需要处理和操作的数据集合,包括全局变量、局部变量、堆内存中分配的数据等。
如何理解,进程 = 内核数据结构 + 自己的代码和数据呢?
举个例子,大学生毕业之后要找工作,找工作需要投递简历吧?那么你的简历里就记录了你的详细信息,包括毕业学校,实习经历,项目经验,包括你的学校的学习状况等等。那么你的简历就相当于进程的内核数据结构,Linux下叫做task_struct,其中包含了进程的所有详细信息,包括 PID(进程标识符),PPID(父进程标识符),exit_code(进程的退出码),exit_signal(进程的退出信号)等等。
你自己本人就相当于进程的代码和数据,当你的简历被HR选中要求你去公司面试时,本质上就是进程的代码和数据加载到内存被 CPU 执行!
系统调用fork
在继续探索 Linux 系统中的进程状态之前,我先带大家认识一个系统调用fork,这是我们初次接触系统调用函数,后面我们会遇到更多系统调用,也会对系统调用了解的更加深刻!
我们在Linux系统中使用 man 2 fork 指令可以看到fork系统调用的详细说明。
FORK(2) Linux Programmer's Manual
FORK(2)
NAME
fork - create a child process
SYNOPSIS
#include <unistd.h>
pid_t fork(void);
- 头文件为
<unistd.h> - 函数原型为
pid_t fork(void);
接下来我们为大家详细介绍fork函数
函数功能
- fork 函数用于创建一个新的进程,称为子进程。
- 子进程是调用 fork 函数的进程(父进程)的一个副本,它几乎与父进程完全相同,包括
程序计数器、内存内容、打开的文件描述符等。这里我还不能给大家展开,只要记住子进程的内核数据结构以及代码和数据都是从父进程拷贝过来的,并且做了小部分的修改,例如修改 PID 和 PPID 等。
总结一句话就是,哪个进程调我,我就给它创建子进程。
子进程和父进程可以同时执行,它们各自有独立的执行路径,可以分别进行不同的操作。互不影响!
返回值
对父进程:
- 如果函数调用成功,fork 函数返回子进程的进程
ID(PID)。这个 PID 是一个正整数,用于标识新创建的子进程,父进程可以通过这个PID来对特定的子进程进行后续的操作,如等待子进程结束、向子进程发送信号等。
为什么要给父进程返回子进程的PID呢?
- 因为一个父进程可以通过 fork 函数创建多个子进程,
父进程:子进程=1:N如果不把子进程的 PID 返回给父进程,那么父进程将来如何管理自己的多个子进程呢?换句话说,父进程怎么知道哪个孩子是哪个呢?
所以给父进程返回子进程的 PID 是为了父进程能够更好的管理子进程!
- 如果fork函数调用失败,它将在父进程中返回
-1,并设置errno变量来指示错误原因。常见的错误原因包括系统资源不足、达到了系统对进程数量的限制等。
对子进程:
- 在子进程中,如果函数调用成功,fork 函数返回 0。这是子进程识别自己的方式,通过判断 fork 的返回值为 0,子进程可以知道自己是新创建的进程,从而执行特定于子进程的代码逻辑。
- 如果调用失败,子进程没有被创建,无返回值。
代码层面理解
- 创建子进程:当父进程调用
fork函数时,操作系统内核会为子进程分配新的进程控制块(PCB)和其他必要的资源,如内存空间等。子进程的内存空间最初是父进程内存空间的一个副本,但它们之间的内存是相互独立的,后续对内存的修改不会相互影响。
我们通过代码来让大家进一步的理解 fork 函数,在开始之前,我们需要补充两个函数,同样是系统调用。
getpid()和getppid()
GETPID(2) Linux Programmer's Manual
GETPID(2)
NAME
getpid, getppid - get process identification
SYNOPSIS
#include <sys/types.h>
#include <unistd.h>
pid_t getpid(void);
pid_t getppid(void);
getpid是一个用于获取进程标识符(PID)的系统调用,getppid则是获取父进程的进程标识符。
头文件:
#include <sys/types.h>和#include <unistd.h>- 返回值为调用进程的 PID,不在赘述
一句话总结,对于 getpid()来说哪个进程调我,我就返回哪个进程的 PID!
对于 getppid()来说,哪个进程调我,我就返回哪个进程的父进程的 PID!
代码示例:
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
int rid=fork();
if(rid < 0)
{
//返回值<0 说明创建子进程失败 打印错误信息并退出
perror("fork");
return 1;
}
else if(rid == 0)
{
//如果返回值rid为 0,说明这是子进程
//打印它的pid和父进程的pid
printf("我是子进程,我的pid是:%d,我的父进程pid是%d\n",getpid(),getppid());
}
else
{
//走到这里说明返回值不为0,则是父进程
printf("我是父进程,我的pid是:%d,我的父进程pid是%d\n",getpid(),getppid());
}
}
输出:
[zwy@iZbp1dkpw5hx2lyh7vjopaZ myshell]$ ./a.out
我是父进程,我的 pid 是:23558,我的父进程 pid 是 20723
我是子进程,我的 pid 是:23559,我的父进程 pid 是 23558
这里我们看到:
父进程的 PID 为 23558,PPID 为 20723子进程的 PID 为 23559,PPID 为 23558
确实父进程的 PID 对应着子进程的 PPID,表明 fork 函数确实为我们当前的进程创建了子进程!
- 第一个问题:为什么一个函数有两个返回值?
根据以往对 C 语言学习的经验,一个函数只能有 0 个或者 1 个返回值,那么这里为什么 fork 可以返回两个值呢?
可以这么理解,当一个函数执行到return 语句的时候,函数的主体功能是否已经做完了呢?答案是肯定的,当函数开始return时,函数的功能已经基本实现,对于fork函数来说,当它开始返回时,子进程已经被创建,此时fork函数会分别给父进程和子进程进行返回,此时fork就会返回两个值,分别作为父进程和子进程fork函数的返回值!

- 第二个问题:fork 是如何给父子进程分别返回不同的值?
我们之前讲过,子进程的内核数据结构以及代码和数据都是从父进程那里拷贝过来的,但是做了相应的修改.我们知道进程具有独立性! 如果父子进程中有任何一方想要修改共享的数据,那么就会触发操作系统的写时拷贝(后面会讲),操作系统会拷贝一份新的出来,让想要修改的进程去修改新拷贝出来的数据,从而保证进程之间的独立性。
那么无论是哪个进程先被 fork 返回,此时返回值rid已经有了值,那么当另一个进程返回时,操作系统发现它要修改父子进程的共享数据,那么就会触发写时拷贝,会拷贝新的数据用来给它返回修改(当然中间会有相当复杂的机制,包括进程地址空间,页表等操作系统层面的知识),此时就完成了 fork 给父子进程返回不同的值!

- 第三个问题:为什么一个变量既可以让
if成立,又可以让else成立?
对于这个问题,我们目前解释不清楚,但是我们可以肯定这个变量肯定不是存储在物理内存中,如果在物理内存中,根据地址拿到变量的值,为什么子进程和父进程的值不一样呢?实际上我们C语言中学的指针中指向的地址都是虚拟地址,并不是真实的物理地址,这个问题我们留到进程的虚拟地址空间给大家讲清楚!
进程状态
如同人一样,当你在上课时,你的状态是听课中,当你在睡觉时,你的状态时休息中,当你在排队打饭时,你的状态是等待中,当你在打篮球时,你的状态时运动中…
进程也同样如此,有着不同的状态,方便我们对进程更好的管理和操作!
我们先来看一下操作系统学科中,对于进程状态的划分:

Linux内核源代码
下面的进程状态在 kernel 源代码里定义:
/*
*The task state array is a strange "bitmap" of
*reasons to sleep. Thus "running" is zero, and
*you can test for combinations of others with
*simple bit tests.
*/
static const char *const task_state_array[] = {
"R (running)", /*0 */
"S (sleeping)", /*1 */
"D (disk sleep)", /*2 */
"T (stopped)", /*4 */
"t (tracing stop)", /*8 */
"X (dead)", /*16 */
"Z (zombie)", /*32 */
};
- R 运行状态(
running): 并不意味着进程⼀定在运行中,它表明进程要么是在运行中要么在运行队列里。 - S 睡眠状态(
sleeping): 意味着进程在等待事件完成(这里的睡眠有时候也叫做可中断睡眠 (interruptiblesleep)。 - D 磁盘休眠状态(
Disk sleep)有时候也叫不可中断睡眠状态uninterruptiblesleep,在这个状态的进程通常会等待IO的结束。 - T 停止状态(
stopped): 可以通过发送SIGSTOP信号给进程来停止(T)进程。这个被暂停的进程可以通过发送 SIGCONT 信号让进程继续运行。 - X 死亡状态(
dead):这个状态只是⼀个返回状态,你不会在任务列表里看到这个状态。
进程状态查看

ps aux / ps axj 命令
- a:显示⼀个终端所有的进程,包括其他用户的进程。
- x:显示没有控制终端的进程,例如后台运行的守护进程。
- j:显示进程归属的进程组ID、会话ID、父进程ID,以及与作业控制相关的信息
- u:以用户为中心的格式显示进程信息,提供进程的详细信息,如用户、CPU和内存使用情况等。
我们可以通过ps结合grep命令实现对指定进程状态的查看
ps ajx | grep Test
[zwy@iZbp1dkpw5hx2lyh7vjopaZ ~]$ ps ajx | grep Test
20723 30085 30085 20723 pts/1 20723 R 1000 6:32 ./Test
29974 32651 32650 29974 pts/0 32650 R+ 1000 0:00 grep --color=auto Test
同时结合head命令将第一行信息提取出来
ps ajx | head -1 && ps ajx | grep Test
[zwy@iZbp1dkpw5hx2lyh7vjopaZ ~]$ ps ajx | head -1 && ps ajx | grep Test
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
20723 30085 30085 20723 pts/1 20723 R 1000 7:52 ./Test
29974 32719 32718 29974 pts/0 32718 R+ 1000 0:00 grep --color=auto Test
还可以通过grep -v grep 将含有grep的信息过滤掉,防止干扰查找。
ps ajx | head -1 && ps ajx | grep Test | grep -v grep
[zwy@iZbp1dkpw5hx2lyh7vjopaZ ~]$ ps ajx | head -1 && ps ajx | grep Test | grep -v grep
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
20723 30085 30085 20723 pts/1 20723 R 1000 9:23 ./Test
top命令
终端中直接输入
top
启动后,你会看到一个动态的界面,界面中会显示系统的总体信息(如负载、CPU 使用率、内存使用率等)以及各个进程的详细信息。

常用交互操作
q:退出 top 界面。M:按内存使用率排序。P:按 CPU 使用率排序。1:显示每个 CPU 核心的使用情况。
- 运行状态(R,Running)
进程正在 CPU 上执行,或者正在等待 CPU 资源,只要获得 CPU资源就可以立即执行。处于该状态的进程是活跃的,正在参与系统的运算和处理。
int main()
{
while(1)
{
;
}
return 0;
}
我们写一个死循环的程序,成功编译运行后,成为一个进程。此时我们每隔一秒对进程状态查看一次,会发现进程一直处于运行状态。
命令:
while true; do ps ajx | head -1; ps ajx | grep "Test" | grep -v grep; sleep 1; done
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
20723 29872 29872 20723 pts/1 29872 R+ 1000 0:06 ./Test
其中R+,R表示进程处于运行状态,后面的+号表示该进程属于前台进程组的成员,在前台运行,会导致命令行占用,无法输入命令。这个我们可以不用关心!
如果想要让进程成为一个后台进程组的进程,即在后台运行,不影响命令行的输入,可以在启动进程时加上&符号。
例如:
[zwy@iZbp1dkpw5hx2lyh7vjopaZ myshell]$ ./Test &
[2] 791
此时进程会进入后台运行,不影响前台的操作。
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
20723 791 791 20723 pts/1 20723 R 1000 2:28 ./Test
20723 30085 30085 20723 pts/1 20723 R 1000 20:41 ./Test
- 睡眠状态(S,Sleeping) 也称为可中断睡眠状态。
进程正在等待某个事件完成或资源可用,比如等待 I/O操作完成、等待信号量等。在等待期间,进程会被挂起,不会占用 CPU 资源。当等待的事件发生或资源变为可用时,进程会被唤醒,进入运行队列等待CPU 调度。
同样的程序,我们加上一句printf输出。
int main()
{
while(1)
{
printf("pid:%d\n",getpid());
}
return 0;
}
编译运行后,成为一个进程,不断地在终端打印PID。
pid:2171
pid:2171
pid:2171
pid:2171
pid:2171
此时我们查看进程状态。
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
20723 2810 2810 20723 pts/1 2810 R+ 1000 0:09 ./Test
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
20723 2810 2810 20723 pts/1 2810 R+ 1000 0:09 ./Test
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
20723 2810 2810 20723 pts/1 2810 S+ 1000 0:10 ./Test
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
20723 2810 2810 20723 pts/1 2810 S+ 1000 0:10 ./Test
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
20723 2810 2810 20723 pts/1 2810 S+ 1000 0:11 ./Test
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
20723 2810 2810 20723 pts/1 2810 R+ 1000 0:11 ./Test
发现进程居然是一会处于R+状态,一会处于S+状态,这时就会有同学产生疑惑了?
我们程序的不是一止死循环的向终端打印吗?有R+状态我能理解,但是为什么会有S+状态呢??为什么会处于浅度休眠状态?
这是因为我们的程序中有printf函数,涉及到了IO操作,当程序要进行IO操作时,可能会处于浅度休眠状态,因为要占用硬件资源,向显示器打印,这时有可能其他进程正在使用,所以我们的进程就会进入浅度休眠状态,为S+状态,等硬件资源就绪后,就会进入运行状态,变为R+状态,被CPU调度执行,这就是为什么会一会R+状态,一会S+状态!
还有一种情况,当我们的程序中使用sleep函数时,进程也会进入S状态。
例如:我们让它每隔一秒钟打印一次,此时就会处于S状态。
int main()
{
while(1)
{
printf("pid:%d\n",getpid());
sleep(1);
}
return 0;
}
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
20723 3652 3652 20723 pts/1 3652 S+ 1000 0:00 ./Test
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
20723 3652 3652 20723 pts/1 3652 S+ 1000 0:00 ./Test
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
20723 3652 3652 20723 pts/1 3652 S+ 1000 0:00 ./Test
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
20723 3652 3652 20723 pts/1 3652 S+ 1000 0:00 ./Test
有同学又会问了,为什么进程会一直处于S+状态呢?我们不是还有printf打印操作吗,也需要转为R状态被CPU执行啊,那是因为printf执行的速度太快了,我们每隔一秒查一次进程状态,而CPU执行程序的时间可能只需要几微秒,甚至纳秒,大部分都处于sleep休眠时间,此时我们无法查到进程的R状态,进程表现为S浅度休眠状态!
- 阻塞状态(D,Disk Sleep)也叫不可中断睡眠状态。
与可中断睡眠状态类似,进程也是在等待某个事件或资源,但处于这种状态的进程不能被信号中断,通常用于一些特殊的情况 比如进程正在进行磁盘 I/O 操作,为了保证数据的完整性和一致性,在操作完成之前不允许被中断。
讲个故事理解:
浅度睡眠的进程是可以直接被操作系统杀掉的,因为操作系统是进程的管理者,有权力杀死一个进程。
例如,用户编写了一个程序要把10GB(这里只是假设数据量比较大)的数据写入磁盘的文件中,程序运行后,成为一个进程。
这时进程通过操作系统提供的接口找到磁盘,对着磁盘说:“磁盘,帮我存10GB的数据到一个指定的文件里”。
-
磁盘回答说:“好的进程,你等会啊,先别走,我看看我磁盘里面还有没有足够的空间,不管存不存的下,我等会给你答复,你先别走啊!”说着便一头扎进去找地方了。
进程答道:“行,我在这等你,快点回来奥。”此时进程躺在椅子上睡着了,进入了浅度睡眠状态,即S状态。 -
这时操作系统正在忙的焦头烂额,看到了躺在椅子上睡着的进程,非常生气,大喊道:“进程,你在干什么!你没看看我都忙成什么样子了,你居然还在这里睡觉,我看你是不想活了”说着就要把进程杀掉。
-
进程急忙回答:“操作系统你别生气,用户让我把这10GB的数据写入磁盘,我给磁盘说了让它赶紧把数据找个地方写进去,它让我在这等它,到现在也没出来,也不知道存进去了没有,我也没办法,用户交给我的任务,我必须得完成啊”
操作系统此时正处于气头上,二话不说的将进程杀掉了!此时进程瞬间消失的无影无踪。 -
操作系统便急忙走了,系统内存空间严重不足了,操作系统此时任务很艰巨,它知道它无论如何绝不能让系统崩溃,这是它的使命!
-
过了不大一会,磁盘探出来个头问道“进程啊,不行了,我里面没有空间了,你快去告诉用户,磁盘空间不足,这10GB数据存不下去了,让用户想想办法吧!进程?进程??进程???”磁盘大喊道,可是只传来空荡荡的回音,进程已经死了。这10GB的数据也丢失了。
-
用户发现它的数据迟迟没有写入磁盘,惊恐的发现自己的进程已经被操作系统杀掉了,同时10GB数据也丢失了。非常生气,找来操作系统,进程,磁盘三个人当面对质!你们三个怎么搞的,到底谁的错,一个一个说吧!!
-
进程先说到:“用户啊,你让我去告诉磁盘把这10GB的数据写入磁盘,我跟他说了,他让我在外面等他,能不能存进去它会给我个回答,我再告诉你,我一直再尽职尽责啊,我总不能任务没完成,也不知道写没写进去就回来吧,万一没写进去,10GB的数据也丢了,我必须得在那等磁盘啊!”
-
用户看了看进程,觉得它说的很有道理。
-
此时,操作系统立马说到:“用户啊,你知道的,我一直都是你最衷心的的追随者,一年365天没日没夜的给你干活,只要你需要,我从来没喊过一句苦,一句累,不管多难我都帮你每时每刻维护着系统的稳定和安全,今天系统的内存空间已经严重不足了,随时都有挂掉的风险,我看他还在那里睡觉,我实在忍不了了,就把他杀了,这才勉强让系统挺了过去,你也不想让我挂掉吧,这要是我挂掉了,可就不是丢掉10GB数据这么简单了。”
-
用户一直都比较信赖操作系统,听操作系统这么一说,觉得它一点都没错!
-
此时用户看着磁盘,磁盘吓得赶忙说道:“用户啊,你知道的,我就是整个计算机里最底层的人,人家让我干啥我就干啥,人家让我怎么干,我就怎么干,今天人家进程让我把你的10GB数据写进去,我立马就在里面找空间了,虽然我一直很努力的找,但是我实在找不到这么大的地方了,我出来告诉进程的时候,他已经被操作系统杀了,那我也没办法啊,我就是个跑腿的”
-
用户看着磁盘可怜的模样,觉得它也没错。
-
用户想了想说,这样吧,你们三个都没错,以后我给进程新增一个特权,当进程在进行大规模的IO操作时,操作系统你无权杀掉它,只能等它IO操作结束自行退出,无论系统多忙你都无权杀掉他!出了问题我负责。进程你也别怕,以后你在和磁盘IO时没有人能打扰你,更不敢杀掉你,你就放心大胆的完成我交给你的任务!此时三个人都觉得不错
这个给进程新增的特权就叫做D状态,也叫做不可中断休眠状态!
这个状态我们目前观察不到,需要涉及大文件块的传输。
- 僵尸状态(Z,Zombie)
当子进程已经终止运行,但它的父进程还没有调用wait()或waitpid()系统调用来获取它的退出状态时,进程就会进入僵尸状态。处于僵尸状态的进程已经释放了大部分资源,但仍保留了一些进程控制块信息,等待父进程来回收。
举个例子:
int main()
{
pid_t id = fork();
if (id < 0)
{
perror("fork failed!\n");
exit(1);
}
else if (id == 0)
{
int cnt = 3;
while (cnt--)
{
sleep(1);
printf("我是一个子进程 我的pid:%d,我的父进程pid: %d\n", getpid(), getppid());
}
}
else
{
printf("我是一个父进程 我的pid:%d,我的父进程pid:%d\n", getpid(), getppid());
while (1);
}
return 0;
}
通过 fork() 系统调用创建了一个子进程,然后父进程和子进程分别执行不同的代码逻辑:
- 父进程:打印自身及其父进程的 PID,随后进入一个无限循环,持续运行而不回收子进程的资源。
- 子进程:打印 3 次自身及其父进程的 PID,每次打印间隔 1 秒。当子进程完成 3 次打印后,会自然退出。
由于父进程没有调用 wait() 或 waitpid() 来回收子进程的退出状态,子进程退出后会变成僵尸进程。
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
20723 6726 6726 20723 pts/1 6726 R+ 1000 0:02 ./process
6726 6727 6726 20723 pts/1 6726 S+ 1000 0:00 ./process
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
20723 6726 6726 20723 pts/1 6726 R+ 1000 0:03 ./process
6726 6727 6726 20723 pts/1 6726 Z+ 1000 0:00 [process] <defunct>
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
20723 6726 6726 20723 pts/1 6726 R+ 1000 0:04 ./process
6726 6727 6726 20723 pts/1 6726 Z+ 1000 0:00 [process] <defunct>
可以看到
- 前3秒,子进程处于S状态,父进程处于R状态。
- 3秒后,子进程运行完毕退出,父进程处于死循环的R状态,但是父进程没有对子进程的退出状态进行回收,此时子进程就会进入僵尸状态,成为一个僵尸进程。
举个例子,理解僵尸进程
正常情况
- 在一个小镇上,每个人就像系统里的进程,警察负责管理人口信息。假设居民张三,他的活动就类似进程在执行任务。张三的家属好比进程的父进程。
当张三正常离世时,家属会立刻通知警察,告知张三的死亡情况以及可能的死因等信息。警察接到通知后,会从人口记录里把张三的信息正式注销,释放掉原本为张三记录预留的空间,这就如同父进程在子进程正常结束后,调用
wait()或者waitpid()函数,获取子进程的退出状态并释放子进程占用的系统资源。此时,系统资源得以正常回收,不会有多余的负担。
僵尸进程情况
- 然而,某天居民李四意外死亡了。李四的家属(父进程)由于沉浸在悲痛中,或者因为一些特殊原因,没有及时向警察(系统)报告李四的死讯。
- 这时,李四虽然已经去世(子进程已经终止),但警察那边的人口记录里,李四的信息依然存在(进程控制块仍然保留),而且一直处于一种待处理的状态。警察既不能把李四的信息直接删除,因为不确定他是否真的死亡;也不能让新的居民使用这个记录位置,因为李四的记录还在占用着。这就好比子进程结束后,父进程没有调用
wait()或waitpid()来获取子进程的退出状态,子进程就变成了僵尸进程,虽然不再运行,但依旧占用着系统的进程表项资源。
僵尸进程的特点体现
- 占用资源但不工作:就像小镇上李四的人口记录一直占着系统表格的位置,僵尸进程占用着系统的进程表空间,可实际上它已经不进行任何有效的工作了。
- 等待处理:李四的信息等待家属来告知警察进行处理,僵尸进程等待父进程调用相应的函数来获取退出状态并释放资源。只要父进程不采取行动,僵尸进程就会一直存在。
一句话总结,子进程退出后,父进程不对子进程的退出信息回收,子进程就会进入僵尸状态,父进程一直不处理,子进程就一直处于僵尸状态!
僵尸进程的危害:
- 资源占用:占据进程表空间,使系统无法创建新进程;保留进程控制块,消耗内存。
- 性能下降:增加系统调度开销,干扰资源分配,影响正常进程运行。
- 管理混乱:干扰系统监控与调试,混淆系统信息,妨碍问题排查。
对于僵尸进程的解决方法,我们到进程等待的话题会给大家处理,现在大家只需要知道僵尸进程是怎么形成的以及它的危害
- 暂停状态(T,Stopped)
进程由于某种原因被暂停执行,比如收到了SIGSTOP信号、正在被调试等。暂停的进程不会占用 CPU资源,也不会继续执行,直到收到SIGCONT信号等恢复执行的信号才会继续运行。
int main()
{
while(1)
{
printf("Hello World!\n");
}
return 0;
}
我们可以在一个程序运行时,按下CTRL+Z,使其暂停,此时进程就处于暂停状态。
Hello World!
Hello World!
Hello World!^Z
[2]+ Stopped ./test
[zwy@iZbp1dkpw5hx2lyh7vjopaZ process]$
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
10218 10261 10261 10218 pts/0 10261 S+ 1000 0:08 ./test
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
10218 10261 10261 10218 pts/0 10218 T 1000 0:08 ./test
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
10218 10261 10261 10218 pts/0 10218 T 1000 0:08 ./test
可以看到进程进入了T状态,即暂停状态。
或者对进程发送信号,也会让其进入暂停状态。
使用kill -19 PID命令,可以让指定PID的进程进入T状态。
kill -19 11392
pid:11392
pid:11392
pid:11392
[2]+ Stopped ./test
- 追踪状态(t,tracing stop)
这是一种特殊的暂停状态,通常是因为进程正在被调试器等工具追踪。调试器可以通过系统调用对处于追踪状态的进程进行控制和观察,获取进程的运行信息、修改进程的状态等。
当我们使用cgdb对进程调试时,可以使进程进入t状态,例如:
[zwy@iZbp1dkpw5hx2lyh7vjopaZ process]$ gcc test.c -o test -g
[zwy@iZbp1dkpw5hx2lyh7vjopaZ process]$ cgdb test
PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND
10218 12817 12817 10218 pts/0 12817 S+ 1000 0:00 cgdb test
12817 12818 12818 12818 pts/3 12818 Ss+ 1000 0:00 gdb --nw --annotate=2 -x /home/zwy/.tgdb/a2_gdb_init test
12818 13094 13094 13094 pts/4 13094 ts+ 1000 0:00 /home/zwy/code/linux/process/test
其中我们使用cgdb调试的test进程就处于t状态,至于s状态则代表表明该进程是会话组长,+意味着该进程属于前台进程组,这个我们都不用关注,只需要了解使用调试器gdb或者cgdb调试程序时,进程会进入t状态。
本文有关进程状态的话题到这里就结束了
Linux 进程控制
一整颗红豆 于 2025-04-11 09:13:58 发布
生生不息:起于鸿蒙,守若空谷,归于太虚
进程创建
fork 函数
在 Linux 中 fork 函数是非常重要的函数,它从已存在进程中创建⼀个新进程。创建出来的新进程叫做子进程,而原进程则称为父进程。
在 Linux 参考手册中,fork 函数的原型如下:(man 2 fork 指令查看)
NAME
fork - create a child process
SYNOPSIS
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);
如上不难看出:
fork函数的功能是创建一个子进程- 头文件有
<sys/types.h>和<unistd.h> - 参数为
void,返回值为pid_t(实际上是Linux内核中typedef出来的一个类型)
进程调用 fork,当控制转移到内核中的 fork 代码后,内核做如下几件事:
- 分配新的内存块和内核数据结构给子进程
- 将父进程部分数据结构内容拷贝至子进程
- 添加子进程到系统进程列表当中
- fork返回,开始调度器调度
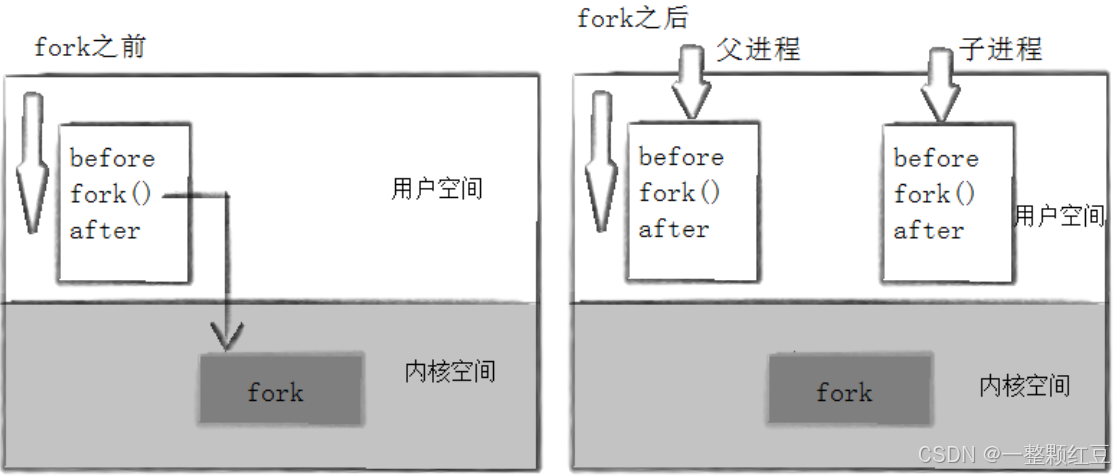
当⼀个进程调用fork之后,就有两个⼆进制代码相同的进程。并且它们都运行到相同的地方。但每个进程都将可以开始属于它们自己的旅程,看如下程序:
int main(void)
{
pid_t pid;
printf("Before: pid is %d\n", getpid());
if ((pid = fork()) == -1)
perror("fork()"), exit(1);
printf("After:pid is %d, fork return %d\n", getpid(), pid);
sleep(1);
return 0;
}
输出:
Before: pid is 40176
After:pid is 40176, fork return 40177
After:pid is 40177, fork return 0
这里看到了三行输出,⼀行before,两行after。其中 40176就是父进程啦,40177就是子进程。进程40176先打印before消息,然后它有打印after。另⼀个after消息是进程40177打印的。注意到进程40177没有打印before,为什么呢?
如下图所示:
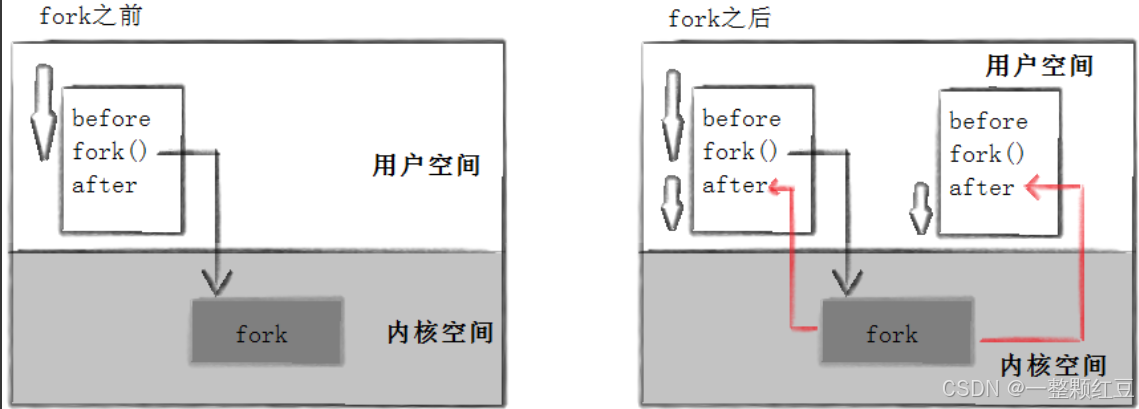
当父进程执行到fork创建出子进程时,已经执行了上面的before代码,而创建出子进程后,子进程不会去执行父进程已经执行过的代码,而是和父进程一同执行fork之后的代码。这就是为什么子进程没有打印before的原因
所以,fork之前父进程独立执行,fork之后,父子进程两个执行流分别执行之后的代码。值得注意的是,fork之后,谁先执行完全由调度器决定,并没有明确的先后关系!
fork函数返回值
类型定义:fork() 返回
pid_t类型(通常为 int 通过 typedef 定义),用于表示进程ID(PID)。
fork创建成功:
- 子进程返回0
- 父进程返回的是子进程的 pid
为什么给父进程返回子进程的pid,这个问题我们之前已经讨论过:
一个父进程可以创建一个或者多个子进程,父进程需要通过返回值获得新创建的子进程的唯一标识符(正整数),从而可以管理创建的多个子进程(如发送信号、等待终止等)
为什么子进程返回0
子进程返回0,标识自己为子进程,子进程通过返回值 0 确认自己的身份。子进程无需知晓父进程的PID(实际上可以通过
getppid()获取)
fork创建失败:
返回 -1并设置错误码:
- 当系统资源不足(如进程数超限、内存耗尽)时,fork() 失败。
错误码:
- 需检查 errno 确定具体原因
if (pid == -1) {
perror("fork failed"); // 输出类似 "fork failed: Resource temporarily unavailable"
}
常见错误码:
EAGAIN:进程数超过限制(RLIMIT_NPROC)或内存不足。ENOMEM:内核无法分配必要数据结构所需内存。
写时拷贝 Copy-On-Write
写时拷贝(COW)是 Linux 中 fork() 系统调用的核心优化机制,它使得进程创建变得高效且资源友好,通常,父子代码共享,父子再不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自⼀份副本。
为什么需要写时拷贝?
在传统的进程创建方式中,fork() 会直接复制父进程的所有内存空间给子进程。这种方式存在明显问题:
- 内存浪费:如果父进程占用 1GB 内存,子进程即使不修改任何数据,也会立即消耗额外 1GB 内存。
- 性能低下:复制大量内存需要时间,尤其是对大型进程而言,fork() 会显著延迟程序运行。
COW 的解决思路:
- 推迟实际的内存复制,直到父子进程中某一方尝试修改内存页时,才进行真正的拷贝。在此之前,父子进程共享同一份物理内存。
具体见下图:
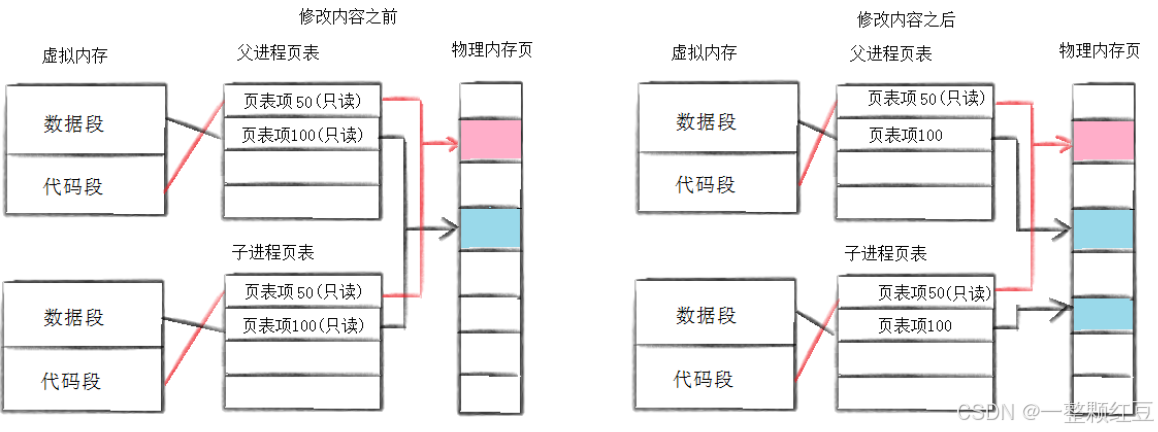
因为有写时拷贝技术的存在,所以父子进程得以彻底分离!完成了进程独立性的技术保证! 写时拷贝,是⼀种延时申请技术,可以提高整机内存的使用率。
写时拷贝的工作流程
1、 fork() 调用时
- 共享内存页:内核仅为子进程创建虚拟内存结构(页表),但物理内存页仍与父进程共享。
- 标记为只读:内核将共享的物理内存页标记为只读(即使父进程原本可写)。
2、进程尝试写入内存
- 触发页错误:当父进程或子进程尝试修改某个共享内存页时,由于页被标记为只读,CPU 会触发页错误(
Page Fault)。
内核介入处理:操作系统会由用户态陷入内核态处理异常
- 分配新的物理内存页,复制原页内容到新页。
- 修改触发写入的进程的页表,使其指向新页。
- 将新页标记为可写,恢复进程执行。
3、后续操作
- 修改后的进程独享新内存页,另一进程仍使用原页。
- 未修改的内存页继续共享,不做复制,操作系统不做任何无意义的事情。
进程等待
之前我们在讲进程概念的时候讲过,如果父进程创建出子进程后,如果子进程已经退出,父进程却没有对子进程回收,那么就子进程就会变成 “僵尸进程” ,造成内存泄露等问题。
在Linux系统中,进程等待是父进程通过系统调用等待子进程终止并获取其退出状态的过程,主要目的是避免僵尸进程并回收子进程资源。
进程等待的必要性
僵尸进程问题:
- 子进程终止后,其退出状态会保留在进程表中,直到父进程读取。若父进程未处理,子进程将保持僵尸状态(
Zombie),占用系统资源。 - 状态收集:父进程需知晓子进程的执行结果(成功、错误代码、信号终止等)。
- 资源回收:内核释放子进程占用的内存、文件描述符等资源。
进程等待的方法
wait
#include<sys/types.h>
#include<sys/wait.h>
pid_t wait(int* status);
具体功能:
- 阻塞父进程,直到等待到任意一个子进程终止。
参数:
status:输出型参数,用来存储子进程退出状态的指针(可为NULL,表示不关心状态)。
返回值:
- 成功:返回终止的子进程PID。失败:返回-1(如无子进程)。
waitpid
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int *status, int options);
- 功能:更灵活的等待方式,可指定子进程或非阻塞等待模式。
参数:
pid:
>0:等待指定 PID 的子进程。-1:等待任意子进程(等效于 wait)。0:等待同一进程组的子进程。
status:同 wait,输出型参数,表明子进程的退出状态。
options: 默认为0,表示阻塞等待
WNOHANG:非阻塞模式,无子进程终止时立即返回 0。WUNTRACED:报告已停止的子进程(如被信号暂停)。
返回值:
- 成功:返回子进程PID。
WNOHANG且无子进程终止:返回0。- 失败:返回-1。
做个总结:
- 如果子进程已经退出,调用 wait / waitpid 时,wait / waitpid 会立即返回,并且释放资源,获得子进程退出信息。
- 如果在任意时刻调用 wait / waitpid,子进程存在且正常运行,则进程可能阻塞。 如果不存在该子进程,则立即出错返回。
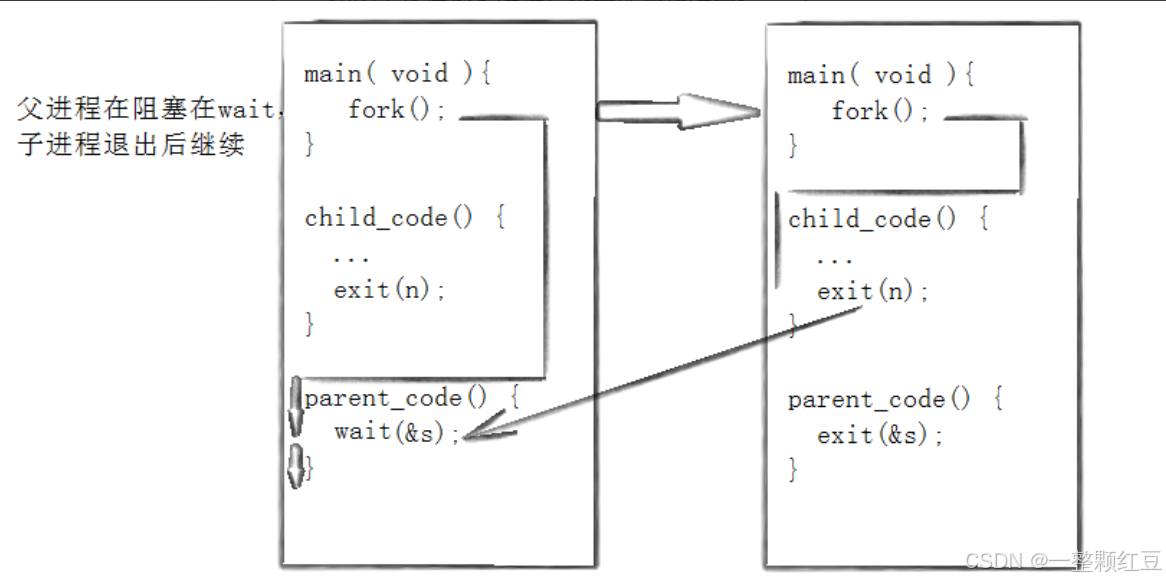
获取子进程 status
wait 和 waitpid,都有⼀个 status 参数,该参数是⼀个输出型参数,由操作系统填充。
- 如果传递
NULL,表示不关心子进程的退出状态信息。 - 否则,操作系统会根据该参数,将子进程的退出信息反馈给父进程。
status 不能简单的当作整形来看待,可以当作位图来看待,具体细节如下图
(只研究 status 低16比特位):
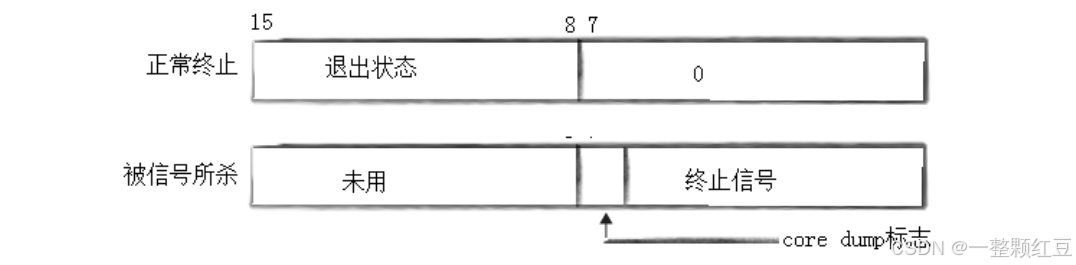
如何理解呢?
子进程的退出分为两种情况:
- 正常终止
高 8 位(第 8 ~ 15 位):保存子进程的退出状态(退出码)(即 exit(code) 或 return code 中的 code 值)。
第 7 位:通常为 0,表示正常终止。
示例:
若子进程调用 exit(5),表明子进程是正常退出,则 status 的高 8 位为 00000101(即十进制 5)。
- 被信号所杀导致终止
低 7 位(第 0 ~ 6 位):保存导致子进程终止的信号编号。
第 7 位:若为 1,表示子进程在终止时生成了 core dump 文件(用于调试)。有关 core dump 文件,后面会讲,大家这里先了解一下即可。
第 8 ~ 15 位:未使用(通常为 0)。
示例:
若子进程因 SIGKILL(信号编号 9)终止,则 status 的低 7 位为 0001001(即十进制 9)。
- 做个小总结:
低 16 位结构:
| 15 14 13 12 11 10 9 8 | 7 | 6 5 4 3 2 1 0 |
---
正常终止 → [ 退出状态(高8位) ] 0 [ 未使用 ]
被信号终止 → [ 未使用(全0) ] c [ 信号编号 ]
如何解析 status?
难道真的需要我们将 status 当作位图,使用位操作来提取子进程的退出信息吗?
这么做对我们程序员来说当然小菜一碟,不过有点多余了,没必要。Linux系统为我们定义了多种宏用来提取 status,方便且专业。
使用宏定义检查 status 的值:
| 宏 | 功能 |
|---|---|
| WIFEXITED(status) | 若子进程正常终止(exit 或 return)返回真。 |
| WEXITSTATUS(status) | 若 WIFEXITED 为真,返回子进程的退出码(exit 的参数或 return 的值)。 |
| WIFSIGNALED(status) | 若子进程因信号终止返回真。 |
| WTERMSIG(status) | 若 WIFSIGNALED 为真,返回导致终止的信号编号。 |
| WCOREDUMP(status) | 若子进程生成了核心转储文件返回真。 |
常用的两个宏:
WIFEXITED(status): 若为正常终止子进程返回的状态,则为真。(查看进程是 否是正常退出)WEXITSTATUS(status): 若WIFEXITED非零,提取子进程退出码。(查看进程的 退出码)
示例一:子进程正常退出
int main()
{
pid_t pid = fork();
if (pid == 0)
{ // 子进程
printf("子进程运行中... PID=%d\n", getpid());
// 1. 正常退出:调用 exit(42)
exit(42);
}
else
{ // 父进程
int status;
waitpid(pid, &status, 0); // 等待子进程结束
if (WIFEXITED(status))
{ // 正常退出
printf("子进程正常退出,退出码: %d\n", WEXITSTATUS(status));
}
else if (WIFSIGNALED(status))
{ // 被信号终止
printf("子进程被信号终止,信号编号: %d\n", WTERMSIG(status));
}
}
return 0;
}
输出:
子进程运行中... PID=56153
子进程正常退出,退出码: 42
示例二:子进程被信号终止
int main()
{
pid_t pid = fork();
if (pid == 0)
{ // 子进程
printf("子进程运行中... PID=%d\n", getpid());
int *p = NULL;
*p = 100; // 对空指针解引用,触发 SIGSEGV 被信号终止
}
else
{ // 父进程
int status;
waitpid(pid, &status, 0); // 等待子进程结束
if (WIFEXITED(status))
{ // 正常退出
printf("子进程正常退出,退出码: %d\n", WEXITSTATUS(status));
}
else if (WIFSIGNALED(status))
{ // 被信号终止
printf("子进程被信号终止,信号编号: %d\n", WTERMSIG(status));
}
}
return 0;
}
输出:
子进程运行中... PID=56203
子进程被信号终止,信号编号: 11
阻塞等待与非阻塞等待
在 Unix/Linux 中,父进程通过 wait 或 waitpid 函数等待子进程结束。它们的核心区别在于是否允许父进程在等待子进程时继续执行其他任务。
阻塞等待(Blocking Wait)
父进程调用 waitpid 后,会一直挂起(阻塞),直到目标子进程终止。在阻塞期间,父进程无法执行其他操作,直到子进程退出。
pid_t waitpid(pid_t pid, int *status, 0); // options 参数为 0
示例:
int main()
{
int status;
pid_t child_pid = fork();
if (child_pid == 0)
{
// 子进程执行任务
exit(10);
}
else
{
// 父进程阻塞等待子进程结束
waitpid(child_pid, &status, 0);
if (WIFEXITED(status))
{
printf("子进程退出码: %d\n", WEXITSTATUS(status));
}
}
}
非阻塞等待(Non-blocking Wait)
父进程调用 waitpid 时,若子进程未结束,则父进程立即返回,而不是挂起。父进程可以继续执行其他任务,同时定期检查子进程状态。需结合循环实现非阻塞式轮询(
polling)。
关键选项:宏 WNOHANG(定义在 <sys/wait.h> 中)。
pid_t waitpid(pid_t pid, int *status, WNOHANG);
示例:非阻塞轮询方式
int main()
{
int status;
pid_t child_pid = fork();
if (child_pid == 0)
{
sleep(3); // 子进程休眠 3 秒后退出
exit(10);
}
else
{
while (1)
{
pid_t ret = waitpid(child_pid, &status, WNOHANG);
if (ret == -1)
{
perror("waitpid");
break;
}
else if (ret == 0)
{
printf("子进程未结束,父进程继续工作...\n");
sleep(1); // 避免频繁轮询消耗 CPU
}
else
{
if (WIFEXITED(status))
{
printf("子进程退出码: %d\n", WEXITSTATUS(status));
}
break;
}
}
}
}
阻塞等待和非阻塞等待的对比:
| 场景 | 阻塞等待 | 非阻塞等待 |
|---|---|---|
| 父进程任务优先级 | 必须立即处理子进程结果 | 需同时处理其他任务 |
| 子进程执行时间 | 较短或确定 | 较长或不确定 |
| 资源消耗 | CPU 空闲,无额外开销 | 需轮询,可能占用更多 CPU |
| 典型应用 | 简单脚本、单任务场景 | 多进程管理、事件驱动程序 |
进程终止
进程= 内核数据结构 + 进程自己的代码和数据
进程终止是进程生命周期的最后一个阶段,涉及资源释放、状态通知及父进程回收等关键步骤。进程终止的本质是释放系统资源,就是释放进程申请的相关内核数据结构和对应的代码和数据。
进程退出场景
- 代码运行完毕,结果正确
- 代码运行完毕,结果不正确
- 代码异常终止
如何理解这三种进程退出的场景呢?举个例子
代码运行完毕,结果正确
- 程序完整执行了所有逻辑,未触发任何错误或异常。
- 输出结果与预期完全一致,符合功能需求或算法目标。
int sum(int a, int b)
{
return a + b;
}
int main()
{
int result = sum(3, 5);
printf("Result: %d\n", result); // 输出 8,结果正确
return 0;
}
输出:
Result: 8
代码运行完毕,结果不正确
- 程序正常结束(无崩溃或异常),但输出结果与预期不符。
- 通常由逻辑错误、算法错误或数据处理错误导致。
例如:
// 错误实现:本应计算阶乘,但初始值错误
int factorial(int n)
{
int result = 0; // 错误!应为 result = 1
for (int i = 1; i <= n; i++)
{
result *= i;
}
return result;
}
int main()
{
printf("5! = %d\n", factorial(5)); // 输出 0,结果错误
return 0;
}
代码未执行完毕,异常终止
- 程序未执行完毕就中途崩溃或被强制终止。
- 通常由运行时错误、资源限制或外部信号触发。
- 比如除零错误,对空指针解引用等异常
例如:
int main()
{
int *ptr = NULL;
*ptr = 42; // 对空指针解引用,触发段错误
printf("Value: %d\n", *ptr);
return 0;
}
段错误:
Segmentation fault
再比如:
int main()
{
int a = 10;
int b = a / 0; // 程序除零异常
printf("Value: %d\n", b);
return 0;
}
浮点数异常:
Floating point exception
进程常见退出方法
正常终止(可以通过 echo $? 查看进程退出码)
- 从main返回
- 调用exit
- _exit
异常退出:
ctrl + c,信号终止
进程退出码
进程退出码(退出状态)可以告诉我们最后⼀次执行的命令的状态。在命令结束以后,我们可以知道命令是成功完成的还是以错误结束的。通常是你程序中mian函数的返回值,其基本思想是,程序返回退出代码 0 时表示执行成功,没有问题。 0 以外的任何代码都被视为不成功。
退出码是一个 8 位无符号整数(8-bit unsigned integer),因此取值范围为 2^8=256 个值。
Linux Shell 中的常见退出码:

- 退出码 0 表示命令执行有误,这是完成命令的理想状态。
- 退出码 1 我们也可以将其解释为 “不被允许的操作”。例如在没有
sudo权限的情况下使用yum; - 130 (
SIGINT 或 ^C)和 143 (SIGTERM)等终止信号是非常典型的,它们属于128+n信号,其中 n 代表信号编号。
这里需要补充一点:
进程退出码和错误码是两个完全不同的概念,不要混为一谈!
错误码
在 Linux 系统中,错误码(
Error Codes)是操作系统用于标识程序运行中遇到的各类问题的核心机制。这些错误码通过全局变量errno(定义在<errno.h>头文件中)传递,帮助开发者快速定位和调试问题。
要理解错误码,首先要认识全局变量 error
例如:fork函数调用失败后,会立刻返回-1,并设置全局变量 error
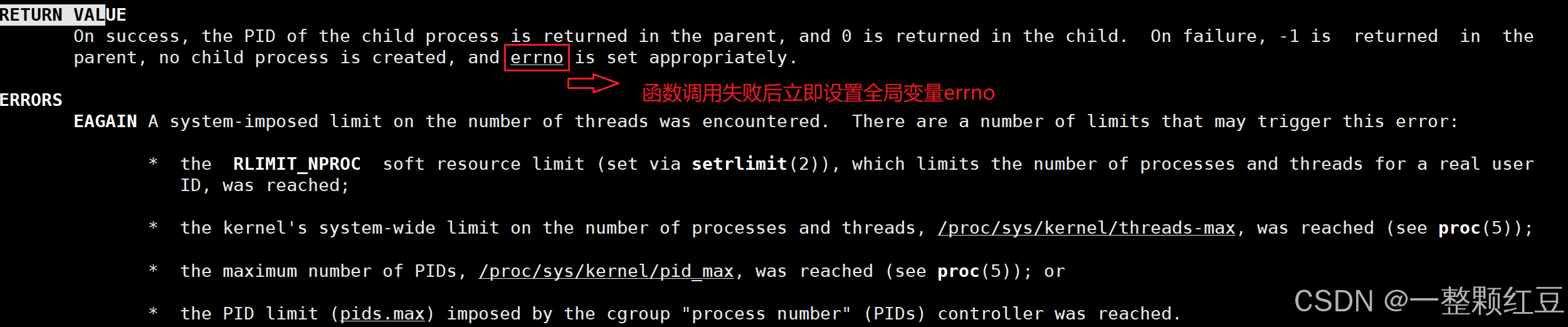
- 定义:
errno是一个线程安全的整型变量,用于存储最近一次系统调用或库函数调用失败的错误码。
特性:
- 成功调用不会重置 errno,因此必须在调用后立即检查其值。
- 每个线程有独立的 errno 副本(多线程安全)。
头文件:
#include <errno.h>
与之对应的是 strerror 函数,该函数可以将对应的错误码转化成字符串描述的错误信息打印出来,方便程序员调试代码。
实际上,我们可以通过 for 循环来打印查看Linux系统下所有的错误码以及其错误信息:
int main()
{
for (int i = 0; i < 135; ++i)
{
printf("%d-> %s\n", i, strerror(i));
}
return 0;
}
不难看出,在Linux系统下,一共有 0 ~ 133 总共134个错误码,其中 0 表示 success ,即程序运行成功, 1 ~ 133 则分别对应一个错误信息。
0-> Success
1-> Operation not permitted
2-> No such file or directory
3-> No such process
4-> Interrupted system call
5-> Input/output error
6-> No such device or address
7-> Argument list too long
8-> Exec format error
9-> Bad file descriptor
10-> No child processes
11-> Resource temporarily unavailable
12-> Cannot allocate memory
13-> Permission denied
14-> Bad address
15-> Block device required
16-> Device or resource busy
17-> File exists
18-> Invalid cross-device link
19-> No such device
20-> Not a directory
21-> Is a directory
22-> Invalid argument
23-> Too many open files in system
24-> Too many open files
25-> Inappropriate ioctl for device
26-> Text file busy
27-> File too large
28-> No space left on device
29-> Illegal seek
30-> Read-only file system
31-> Too many links
32-> Broken pipe
33-> Numerical argument out of domain
34-> Numerical result out of range
35-> Resource deadlock avoided
36-> File name too long
37-> No locks available
38-> Function not implemented
39-> Directory not empty
40-> Too many levels of symbolic links
41-> Unknown error 41
42-> No message of desired type
43-> Identifier removed
44-> Channel number out of range
45-> Level 2 not synchronized
46-> Level 3 halted
47-> Level 3 reset
48-> Link number out of range
49-> Protocol driver not attached
50-> No CSI structure available
51-> Level 2 halted
52-> Invalid exchange
53-> Invalid request descriptor
54-> Exchange full
55-> No anode
56-> Invalid request code
57-> Invalid slot
58-> Unknown error 58
59-> Bad font file format
60-> Device not a stream
61-> No data available
62-> Timer expired
63-> Out of streams resources
64-> Machine is not on the network
65-> Package not installed
66-> Object is remote
67-> Link has been severed
68-> Advertise error
69-> Srmount error
70-> Communication error on send
71-> Protocol error
72-> Multihop attempted
73-> RFS specific error
74-> Bad message
75-> Value too large for defined data type
76-> Name not unique on network
77-> File descriptor in bad state
78-> Remote address changed
79-> Can not access a needed shared library
80-> Accessing a corrupted shared library
81-> .lib section in a.out corrupted
82-> Attempting to link in too many shared libraries
83-> Cannot exec a shared library directly
84-> Invalid or incomplete multibyte or wide character
85-> Interrupted system call should be restarted
86-> Streams pipe error
87-> Too many users
88-> Socket operation on non-socket
89-> Destination address required
90-> Message too long
91-> Protocol wrong type for socket
92-> Protocol not available
93-> Protocol not supported
94-> Socket type not supported
95-> Operation not supported
96-> Protocol family not supported
97-> Address family not supported by protocol
98-> Address already in use
99-> Cannot assign requested address
100-> Network is down
101-> Network is unreachable
102-> Network dropped connection on reset
103-> Software caused connection abort
104-> Connection reset by peer
105-> No buffer space available
106-> Transport endpoint is already connected
107-> Transport endpoint is not connected
108-> Cannot send after transport endpoint shutdown
109-> Too many references: cannot splice
110-> Connection timed out
111-> Connection refused
112-> Host is down
113-> No route to host
114-> Operation already in progress
115-> Operation now in progress
116-> Stale file handle
117-> Structure needs cleaning
118-> Not a XENIX named type file
119-> No XENIX semaphores available
120-> Is a named type file
121-> Remote I/O error
122-> Disk quota exceeded
123-> No medium found
124-> Wrong medium type
125-> Operation canceled
126-> Required key not available
127-> Key has expired
128-> Key has been revoked
129-> Key was rejected by service
130-> Owner died
131-> State not recoverable
132-> Operation not possible due to RF-kill
133-> Memory page has hardware error
134-> Unknown error 134
错误码的应用:
int main()
{
FILE *fp = fopen("invalid.txt", "r");//以只读方式打开不存在的文件会出错
if (fp == NULL)
{
// 使用 strerror 获取错误描述
printf("%d->%s\n", errno,strerror(errno));
return 1; //退出码设为1
}
return 0;
}
输出:
2->No such file or directory
使用错误码和对应的错误信息可以帮助程序员快速定位错误模块,调试程序,掌握错误码的使用与调试技巧,是提升 Linux 编程效率和系统可靠性的关键。
_exit函数和exit函数
_exit函数
在 Linux 系统中,
_exit()是一个直接终止进程的系统调用,它会立即终止当前进程,并通知操作系统回收资源,但不执行任何用户空间的清理操作。
#include <unistd.h>
void _exit(int status);
- 参数
status:进程的退出状态码,范围是0~255。父进程可以通过wait()或waitpid()获取该状态码。 - 返回值:无(进程直接终止,不会返回调用者)。
当前进程调用 _exit() 后,操作系统会立即介入,会从用户态陷入内核态,执行以下操作:
- 关闭所有文件描述符:内核会关闭进程打开的文件、套接字、管道等资源,但不会刷新标准 I/O 库(如
stdio)的缓冲区。 - 释放用户空间内存:回收进程的代码段、数据段、堆、栈等内存资源。
- 发送
SIGCHLD信号: 通知父进程子进程已终止,并传递退出状态码status。 - 终止进程:进程的状态变为
ZOMBIE(僵尸进程),直到父进程通过wait()回收其资源。
本质上,_exit() 最终会调用 Linux 内核的 exit_group 系统调用(sys_exit_group),终止整个进程及其所有线程。其内核处理流程如下:
释放进程资源:
- 关闭所有文件描述符。
- 释放内存映射(mmap)和虚拟内存区域。
- 解除信号处理程序绑定。
更新进程状态:
- 将进程状态设为
TASK_DEAD - 向父进程发送
SIGCHLD信号。
调度器介入:
- 从运行队列中移除进程。
- 切换到下一个进程执行。
exit函数
在 C/C++ 语言中,
exit是一个用于正常终止程序执行的标准库函数。它会执行一系列清理操作后终止进程,并将控制权交还给操作系统。
#include <stdlib.h>
void exit(int status); // C
#include <cstdlib>
void exit(int status); // C++
- 参数
status:进程的退出状态码,范围0~255(0 通常表示成功,非零表示异常)。 - 返回值:无(进程终止,不会返回调用者)。
进程调用 exit 时,按以下顺序执行操作:
- 调用
atexit注册的函数:按注册的逆序执行所有通过atexit或
at_quick_exit(若使用quick_exit)注册的函数。 - 刷新所有标准 I/O 缓冲区:清空
stdout、stderr等流的缓冲区。 注意: stderr 默认无缓冲,stdout 在交互式设备上是行缓冲。 - 关闭所有打开的文件流:调用
fclose关闭所有通过fopen打开的文件。 注意:不会关闭底层文件描述符(需手动close)。 - 删除临时文件:删除由
tmpfile创建的临时文件。 - 终止进程:向操作系统返回状态码
status。父进程可通过wait或waitpid获取该状态码。
其实本质上,exit 是一个标准库函数,最后也会调用_exit,但是在这之前,exit还做了其他的清理工作:

我们举个例子,帮大家直观的感受一下这两者的区别:
示例一:使用 exit 函数
int main()
{
printf("hello");
exit(0);
}
输出:
[root@localhost linux]# ./a.out
hello[root@localhost linux]#
示例二:使用 _exit 函数
int main()
{
printf("hello");
_exit(0);
}
输出:
[root@localhost linux]# ./a.out
[root@localhost linux]#
聪明的同学很快就知道了,我们通过
printf打印 “hello” 并没有加上换行符,所以“hello”
在缓冲区内没有被立即刷新,所以当我们使用exit终止进程时,exit会帮我们做相应的清理工作,包括刷新I/O缓冲区。而调用_exit时则不会刷新,进程直接退出。
return 退出
return是⼀种更常见的进程退出方法。执行
return n等同于执行exit(n),因为调用main的运行时函数会将main函数的返回值当做 exit 的参数。
状态码传递:
main函数中的 return 语句返回一个整数值(通常称为退出状态码),表示程序的执行结果:
- 0:表示程序成功执行。
- 非0:表示程序异常终止(具体数值由程序员定义)。
return与exit()的关系
隐式调用exit():
- 在 main 函数中使用 return 时,C/C++运行时会自动调用 exit() 函数,并将返回值作为参数传递给它。
int main()
{
return 42; // 等价于 exit(42);
}
return的执行流程
当在main函数中执行return时,程序会做以下几件事:
- 返回值传递:将返回值传递给运行时环境。
清理操作:
- 调用局部对象的析构函数(按照创建顺序的逆序)。
- 调用全局对象的析构函数(同样逆序)。
调用exit():运行时调用exit(),执行以下操作:
- 刷新所有I/O缓冲区(如
std::cout)。 - 关闭通过
fopen打开的文件流。 - 执行通过
atexit()注册的函数。
终止进程:将控制权交还给操作系统。
值得注意的一点是:在非main函数的其他函数中使用 return 仅退出当前函数,返回到调用者,不会终止进程。
_exit、exit 和 return 对比
以下是一个详细的表格供大家理解参考
| 特性 | _exit() (系统调用) | exit() (标准库函数) | return (在 main 中) |
|---|---|---|---|
| 所属标准 | POSIX 系统调用 | C/C++ 标准库函数 | C/C++ 语言关键字 |
| 头文件 | <unistd.h> | <stdlib.h>(C)、<cstdlib>(C++) | 无(语言内置) |
| 执行流程 | 立即终止进程,不执行任何用户空间清理。 | 1. 调用 atexit 注册的函数 | |
| 2. 刷新 I/O 缓冲区 | |||
| 3. 关闭文件流 | 1. 调用 C++ 局部对象析构函数 | ||
| 2. 隐式调用 exit() 完成后续清理 | |||
| 清理操作 | 内核自动回收进程资源(内存、文件描述符),不刷新缓冲区、不调用析构函数 | 清理标准库资源(刷新缓冲区、关闭文件流),但不调用 C++ 局部对象析构函数 | 调用 C++ 局部和全局对象析构函数,并触发 exit() 的清理逻辑 |
| 多线程行为 | 立即终止所有线程,可能导致资源泄漏 | 终止整个进程,但可能跳过部分线程资源释放(如线程局部存储) | 同 exit(),但在 C++ 中会正确析构主线程的局部对象 |
| C++ 析构函数调用 | ❌ 不调用任何对象的析构函数(包括全局对象) | ❌ 不调用局部对象析构函数 | |
| ✅ 调用全局对象析构函数(C++) | ✅ 调用局部和全局对象析构函数(C++) | ||
| 缓冲区处理 | ❌ 不刷新 stdio 缓冲区(如 printf 的输出可能丢失) | ✅ 刷新所有 stdio 缓冲区 | ✅ 通过隐式调用 exit() 刷新缓冲区 |
| 适用场景 | 1. 子进程退出(避免重复刷新缓冲区) | ||
| 2. 需要立即终止进程(绕过清理逻辑) | 1. 非 main 函数的程序终止 | ||
| 2. 需要执行注册的清理函数(如日志收尾) | 1. 在 main 函数中正常退出 | ||
| 2. 需要确保 C++ 对象析构(RAII 资源管理) | |||
| 错误处理 | 直接传递状态码给操作系统,无错误反馈机制 | 可通过 atexit 注册错误处理函数,但无法捕获局部对象析构异常 | 可通过 C++ 异常机制处理错误(需在 main 中捕获) |
| 信号安全 | ✅ 可在信号处理函数中安全调用(如 SIGINT) | ❌ 不可在信号处理函数中调用(可能死锁) | ❌ 不可在信号处理函数中使用(仅限 main 函数流程) |
| 资源泄漏风险 | 高(临时文件、未释放的手动内存等需内核回收) | 中(未关闭的文件描述符、手动内存需提前处理) | 低(依赖 RAII 自动释放资源) |
| 底层实现 | 直接调用内核的 exit_group 系统调用 | 调用 C 标准库的清理逻辑后,最终调用 _exit() | 编译器生成代码调用析构函数,并跳转到 main 结尾触发 exit() |
最后总结下:
_exit():最底层的终止方式,适合需要绕过所有用户空间清理的场景(如子进程退出)。exit():平衡安全与效率,适合非 main 函数的程序终止,但需注意 C++ 对象析构问题。return:C++ 中最安全的退出方式,优先在 main 函数中使用,确保资源自动释放。
(linux 操作系统) 从冯诺依曼体系结构到初识进程
coffee_lake_于 2025-03-14 13:00:36 发布
什么是冯诺依曼体系结构
我们可以先查看下面的这张图片:
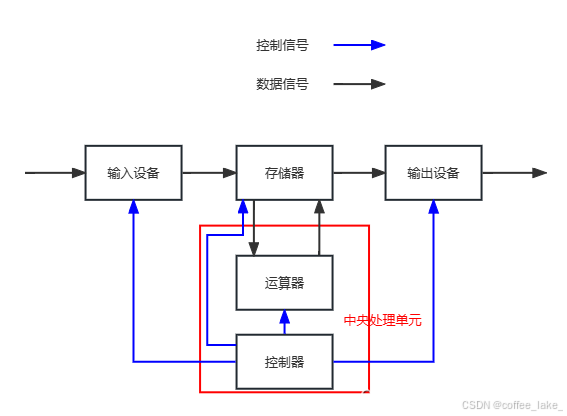
到目前为止,我们所使用的电脑、手机,大多由一个个硬件组成,且大多数都遵循冯诺依曼架构。例如,输入设备包括电脑上的键盘、笔记本上的触控板、电脑硬盘等;输出设备有电脑的显示器、手机的触摸屏等。电脑配备中央处理器(CPU),手机配备系统级芯片(SoC),它们内部均由运算器和控制器单元构成,并且电脑和手机都有运行内存,因此它们都遵循冯诺依曼架构。
根据冯诺依曼体系结构可知,CPU 仅能与内存进行数据交互,所有需要 CPU 处理的数据都必须先加载到内存中。基于上述理解,当我们要打开软件时,CPU 若要处理软件信息,软件就必须先加载到内存中,才能被 CPU 访问。软件的信息会输出到屏幕上供用户查看,而软件在打开之前存储于硬盘中,硬盘中的数据以文件形式存在。因此,硬盘类似于冯诺依曼体系结构中的输入设备,内存是存储器,CPU 包含运算器和控制器,屏幕则是输出设备。
从数据层面理解冯诺依曼体系结构
通过上述例子,我们对冯诺依曼体系结构有了初步认识。现在,我们从数据流动的角度进一步深入理解。假设我们在电脑上登录了 QQ,并要与他人聊天,这本质上是两个冯诺依曼体系结构之间的相互通信。对方的电脑上也登录了 QQ,当我们要发送 “你好” 给对方的 QQ 时,首先需要打开 QQ 软件,此时 QQ 会从硬盘加载到内存中。这一加载过程实际上是拷贝过程,即将硬盘中的 QQ 拷贝到内存中,使得原本处于硬盘中的冷数据转变为可供 CPU 处理的热数据。此时,内存会分配一个区块供 QQ 使用。当我们从键盘输入 “你好” 时,从硬件层面来看,本质上是将键盘输入的内容通过键盘映射成一个值,并拷贝到内存中;从软件层面来看,是将键盘输入的数据交给 QQ 进行处理。在 QQ 应用程序中,会使用自身的加密算法对输入内容进行加密,这一过程会调用 CPU 的运算器和控制器执行特定的加密算法。加密完成后,要发送的数据会从内存拷贝到计算机的网卡,再由网卡输出。网卡会对数据进行特定的格式封装,将其封装成 IP 数据包,使其离开计算机并进入网络,然后通过交换机、路由器进行 IP 数据包的路由,最终到达对方计算机的网卡。此时,对方计算机的网卡充当输入设备,网卡会将数据拷贝到内存中。当数据到达内存后,对方的 QQ 接收到数据,并调用 CPU 中的运算器和控制器对数据进行解密,解密完成后将数据输出到对方电脑的屏幕上,从而完成数据的处理与传输。
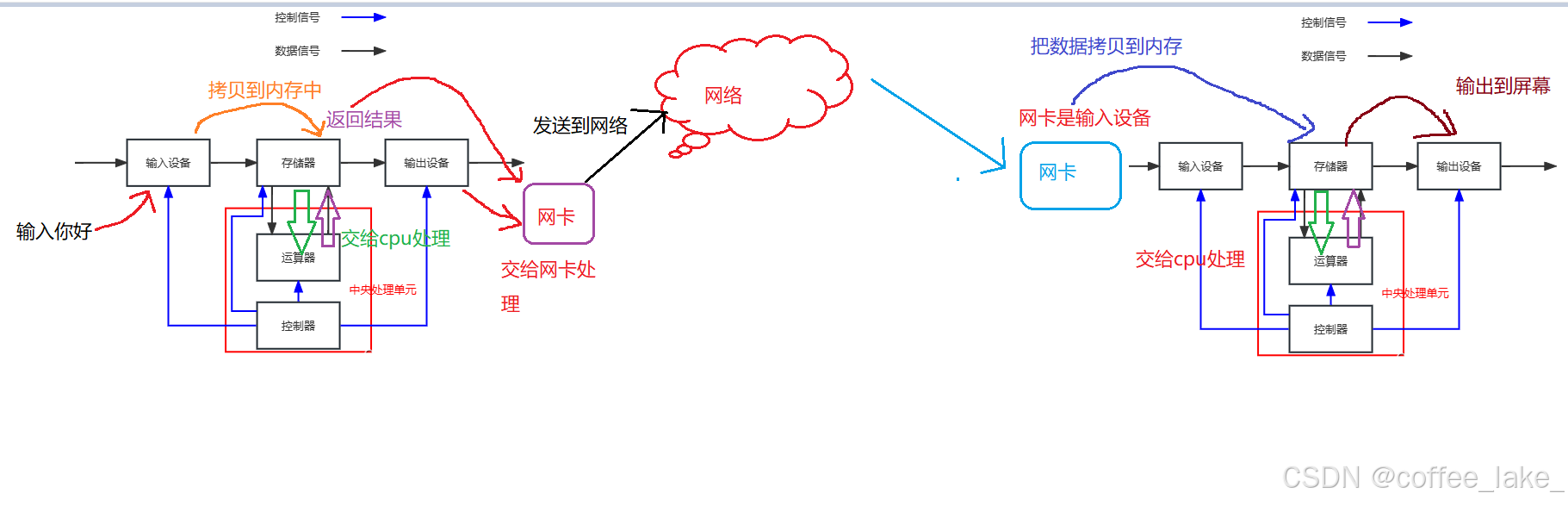
在具备上述认知后,我们来探讨现代计算机为何要遵循冯诺依曼体系结构。这主要是因为冯诺依曼体系结构引入了一个关键组成部分,即存储器,也就是我们计算机上的内存。

为何如此呢?我们可以查看下面的计算机存储分级结构图片:
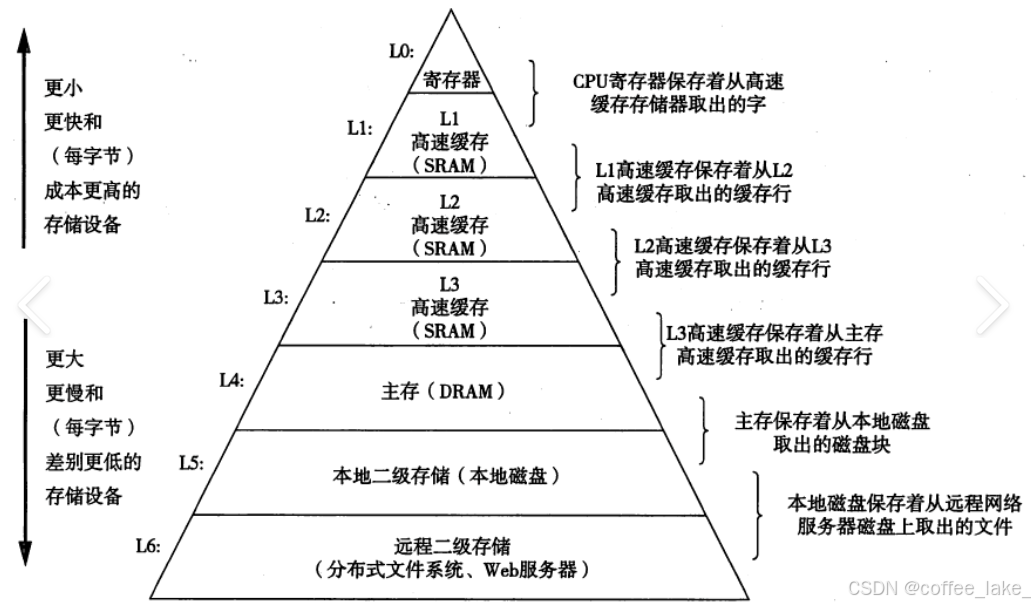
计算机硬盘

内存
CPU 缓存
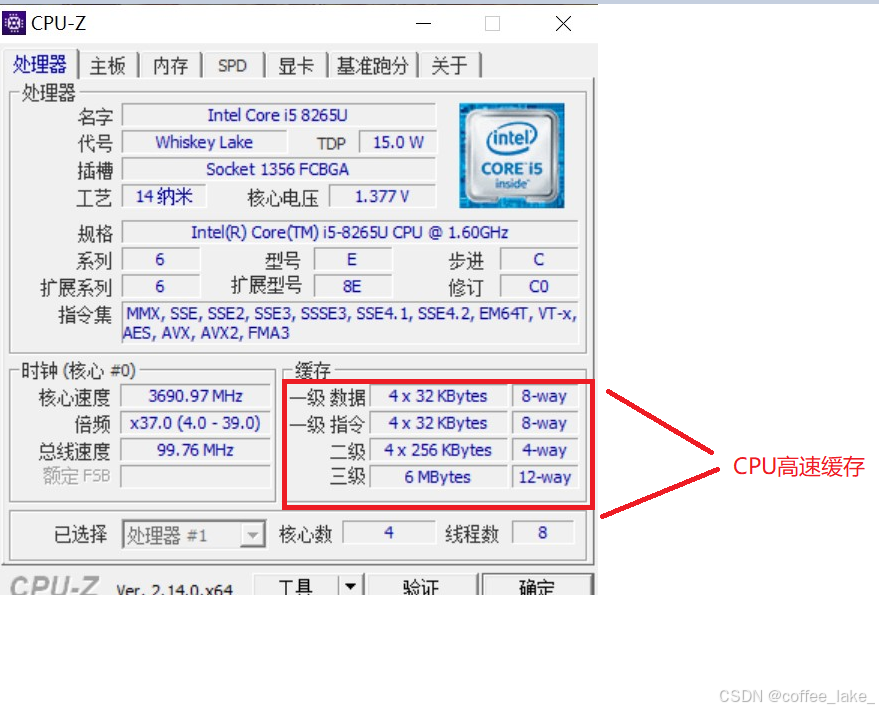
其中,内存对应分级图中的主存(DRAM),L3-L0 是 CPU 内部的存储器。内存的响应时间以纳秒计算,而磁盘的响应时间以毫秒计算。CPU 的运算速度极快,内存作为中间媒介,使我们能够以较低成本大幅提升 CPU 的运算速度。通过上述图片可以发现,随着存储器等级的升高,其速度越快,但存储容量越小,价格也越昂贵;反之,价格越便宜,存储空间越大。如果冯诺依曼体系结构不使用存储器,而是直接用 CPU 的缓存替代,虽然理论上可行,但成本极高,超出了一般用户的承受范围。因此,现代计算机是追求性价比的产物,可以说,没有冯诺依曼架构,计算机就难以普及,计算机网络也难以产生。这就是现代计算机采用冯诺依曼架构的原因。
在具备上述认知后,我们再来探讨计算机中另一个重要的组成部分,即操作系统。
操作系统
概念
任何计算机系统都包含一个基本的程序集合,称为操作系统(OS)。从广义上理解,操作系统包括:
- 内核(进程管理、内存管理、文件管理、驱动管理);
- 其他程序(例如函数库、shell 程序等)。
我们计算机中为何需要操作系统呢?我们可以查看下面的图片:
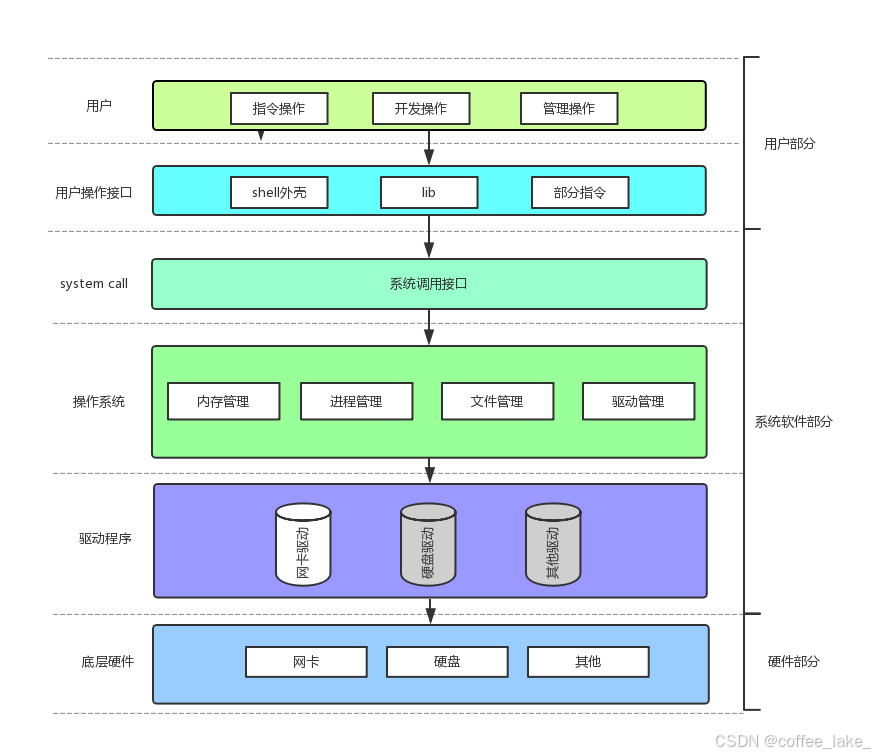
上述结构本质上也属于冯诺依曼结构体系。
我们不难发现,操作系统处于用户与计算机硬件交互的中间层,在该体系中起到承上启下的作用。具体而言,操作系统对下与硬件交互,管理所有的软硬件资源;对上为用户程序(应用程序)提供一个良好的执行环境。当用户使用 printf 函数在屏幕上打印内容时,这一过程会贯穿整个结构,因为该过程涉及硬件操作(显示器)。
操作系统的目的是为上层用户提供更好的服务,手段是管理所有的软硬件资源!
有了操作系统,用户才能更便捷地与计算机硬件进行交互。
在整个计算机软硬件架构中,操作系统的定位是一款纯粹的“管理”软件。
操作系统作为“管理”软件,其核心职责是确保计算机系统的各个部分能够高效、稳定、安全地协同工作,为用户提供一个可靠的计算平台,同时也为应用程序的开发和运行提供必要的支持和服务
那么,如何理解操作系统的“管理”功能呢?
我们可以通过一个生活中的例子来理解,以大学中校长、辅导员和学生之间的关系为例。校长想要管理学生,通常不会直接与学生接触,而是通过辅导员传达自己的要求,由辅导员执行并通知学生。从这个例子可以看出,校长管理学生时,无需与学生直接见面。由此我们可以得出一个结论:管理方与被管理方在管理过程中,无需直接见面。
校长若要管理学生,了解学生的个人基本信息,不会逐一询问学生,而是通过一份包含所有学生基本信息的数据表进行管理。数据表中的每一行记录一个学生的基本数据,校长通过对表中的数据进行增删查改操作,并将结果反馈给辅导员,由辅导员执行并通知学生。由此我们又可以得出一个结论:管理方对被管理方的管理,是通过数据进行的。
那么,校长如何获取所有学生的数据呢?显然是通过辅导员的统计,辅导员将统计结果反馈给校长。
这里我们又可以得出一个结论:在管理方与被管理方不见面的情况下,管理方获取数据的方式是通过中间层,这里的中间层即辅导员。
操作系统中的管理机制也是如此。在操作系统管理硬件的过程中,操作系统相当于校长,硬件相当于学生,各个硬件的驱动程序相当于辅导员。操作系统通过数据对硬件进行管理,无需与硬件直接交互,而数据是通过驱动程序获取的。
那么,操作系统究竟是如何管理硬件的呢?
操作系统管理硬件的过程是一个先描述后组织的过程。通过上述例子我们也可以看出,校长管理学生时,先描述每个学生的基本信息,再按照特定方式进行组织(例如使用 Excel 表格或其他方式)。操作系统也是如此,它会为每个硬件创建一个结构体对象,然后通过某种数据结构将这些结构体对象组织起来。每个结构体中描述了硬件的基本信息,便于操作系统对硬件进行增删查改操作。
总结
计算机管理硬件的过程如下:
- 使用 struct 结构体对硬件进行描述;
- 使用链表或其他高效的数据结构对硬件进行组织。
系统调用和库函数概念
在阐述这一概念之前,我们需要明确一点:操作系统要为用户提供服务,但它并不信任任何用户。
这与现实生活中的银行类似,银行要为客户提供存钱和取钱的服务,但客户无法进入银行的金库,而是通过取号、排号到窗口办理业务。我们可以将操作系统内核比作银行的金库,它不信任任何用户,但会向上层用户暴露一些接口供用户调用,这些接口就如同银行的窗口柜台。
系统调用在使用上,功能相对基础,对用户的要求也相对较高。因此,一些开发者会对部分系统调用进行适度封装,形成库。有了库,更有利于上层用户或开发者进行二次开发。
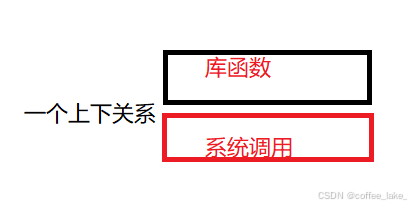
在具备上述了解后,我们来探讨进程的相关内容。
进程
基于上述内容,我们知道操作系统管理进程的方式是先对每个进程进行描述,再进行组织管理,同样是一个先描述后组织的过程。
我们来看一下教科书对进程的定义:
课本概念:程序的一个执行实例,正在执行的程序等;
内核观点:担当分配系统资源(CPU 时间,内存)的实体。
这一概念看似抽象。在日常生活中,我们通常认为进程是硬盘中的一个可执行程序,被 CPU 加载到内存中后,内存中的应用程序就是进程。但实际情况并非如此。根据上述结论,操作系统管理进程是一个先描述后组织的过程,而上述简单理解中缺乏对进程的描述,那么操作系统又如何组织管理进程呢?实际上,进程在操作系统内核中有自己的数据结构对象,在内核之外的内存中有自己的代码和数据。因此,进程可以表示为:进程 = 内核数据结构对象 + 自己的代码和数据。
我们通过画图来进一步理解:
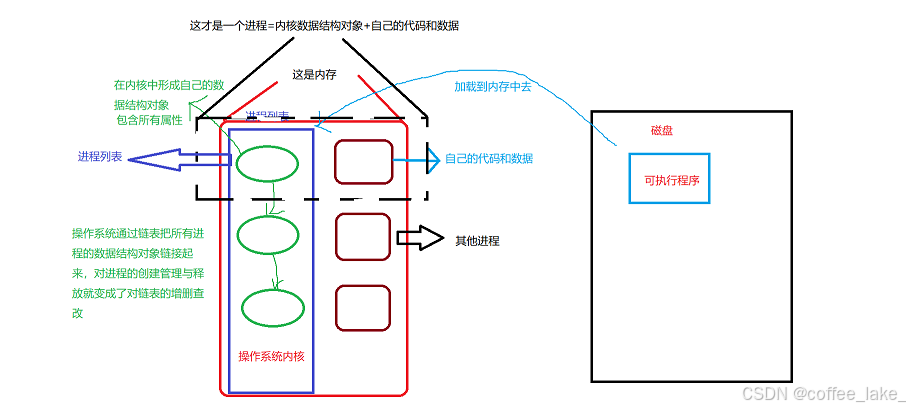
内核数据结构对象是一个结构体,在 Linux 系统中,该结构体被称为 PCB(process control block),对应的结构体是 task_struct。
这个结构体包含以下内容:

可以将 PCB 理解为进程的简介,其中包含了进程的基本信息。操作系统可以根据这些基本信息找到进程的具体位置,从而对进程进行管理。进程的所有属性都可以在 task_struct 中找到。
task_struct 是 Linux 内核的一种数据结构,它会被装载到 RAM(内存)中,并包含进程的相关信息。
task_struct 内容分类
- 标识符:用于描述本进程的唯一标识符,以区分其他进程;
- 状态:包括任务状态、退出代码、退出信号等;
- 优先级:相对于其他进程的优先级;
- 程序计数器:指向程序中即将被执行的下一条指令的地址;
- 内存指针:包括指向程序代码和进程相关数据的指针,以及指向与其他进程共享的内存块的指针;
- 上下文数据:进程执行时处理器寄存器中的数据(可结合 CPU 和寄存器的相关知识理解);
- I/O 状态信息:包括显示的 I/O 请求、分配给进程的 I/O 设备以及进程使用的文件列表;
- 记账信息:可能包括处理器时间总和、使用的时钟数总和、时间限制、记账号等;
- 其他信息。
在具备上述了解后,我们在 Linux 实体机上查看一个进程。
我们切换到 proc 文件夹目录下,该目录中存储的是当前正在运行的进程,目录中的所有内容都位于内存中,类似于 Windows 下的任务管理器,且与磁盘无关。
我们历史上执行的所有命令,如 ls、pwd 等,以及我们自己运行的程序,本质上都是进程。只不过像命令这类进程创建和销毁的速度都很快。

我们可以编写一个程序来查看自己创建的进程:
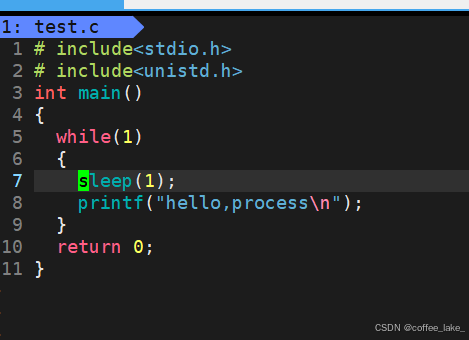
当程序运行后,我们使用以下命令抓取运行的进程:ps ajx | head -1;ps axj | grep test 。
ps 是用于查看进程的命令,ps axj 中的 a 表示显示所有进程。如果我们只想查看自己创建的进程,可以使用 ps axj | grep test 命令。在 Linux 中,| 是管道操作符,允许我们同时输入多条指令。这里输入的命令的含义是:显示进程信息的首行摘要;查找包含“test”的进程。

我们可以看到进程对应的 pid 号是 8093 ,ppid 号是 6461 。PID 是进程标识号,PPID 是父进程标识号。当我们使用上述方法查找任何进程时,都会发现 grep 进程始终存在。这是因为我们输入的命令本身也是一个进程,grep 自然也是一个进程,所以它会被查询出来(因为我们在查找进程时调用了 grep)。如果我们不希望 grep 进程显示,可以使用以下命令:ps ajx | head -1;ps axj | grep test | grep -v grep ,其中 grep -v 表示反向匹配,即不显示包含 grep 的内容。

如果要终止进程,一种方法是使用 ctrl + c 组合键,另一种方法是使用 kill -9 + pid 号的命令来终止进程。

在对进程有了上述认识后,我们再回到 proc 文件夹下:

左边蓝色部分代表进程号,它是一个目录。我们运行 test 进程,然后进入其对应的进程号文件夹查看:
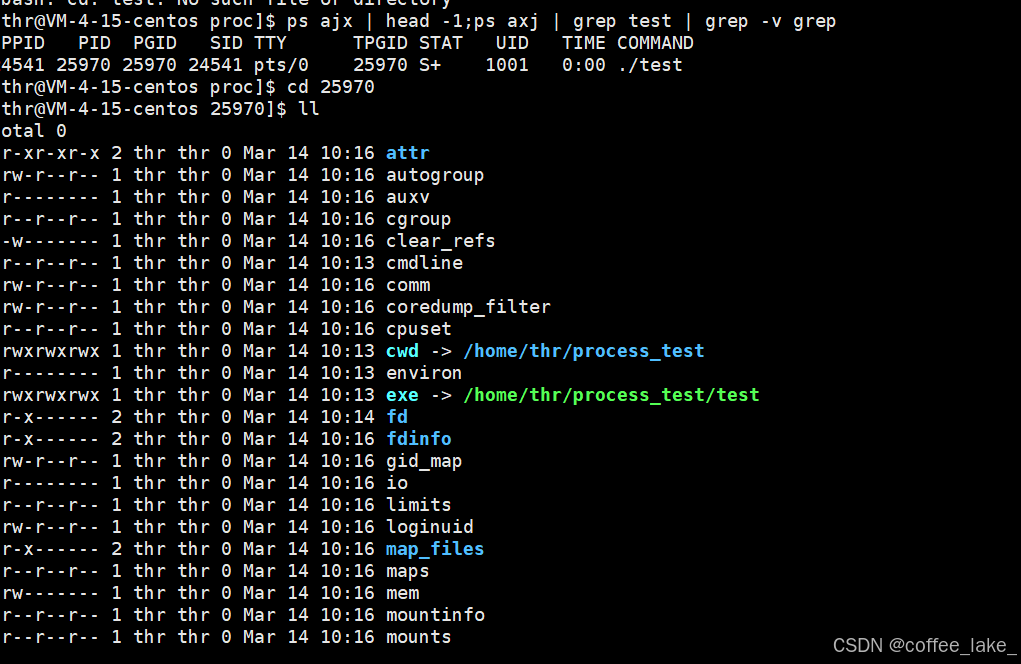
该文件夹中包含了对应进程的一些描述信息。我们主要关注两个内容:exe 和 cwd。exe 表示可执行程序,后面跟随的目录是可执行程序的具体位置;cwd 是 current work dir 的缩写,意为当前工作目录。当程序运行时,该程序的进程会记录当前的工作路径。由此我们可以得出一个结论:C 语言中的 fopen 函数在找不到指定文件时,会在程序运行的当前目录下创建一个新文件,它是通过 cwd 找到该路径的。
我们知道程序运行时会加载到内存中。如果我们此时删除磁盘中的可执行程序,会发生什么情况呢?我们来进行一个实验:

当我们执行完删除操作后,我们发现进程仍然在运行。我们再去查看一下当前目录的 exe 文件:
可以看到 exe 这个地方标红了,提示 test 已经被删除。这也从反面证明了进程在运行时确实会被加载到内存中,即使磁盘中的可执行程序被删除,只要进程已经在内存中运行,它依然可以继续执行。
接下来,我将讲解在编程中如何不使用命令手动创建进程。在讲解之前,我们需要先了解两个函数。
首先是 getpid 函数,我们来看一下它的定义:
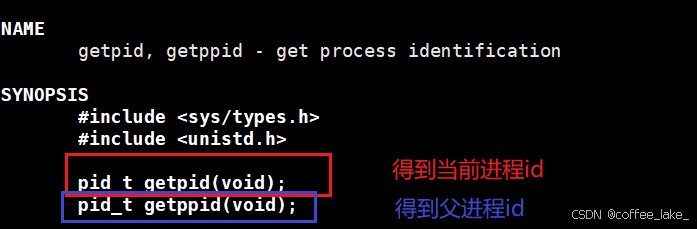
然后是 fork 函数:
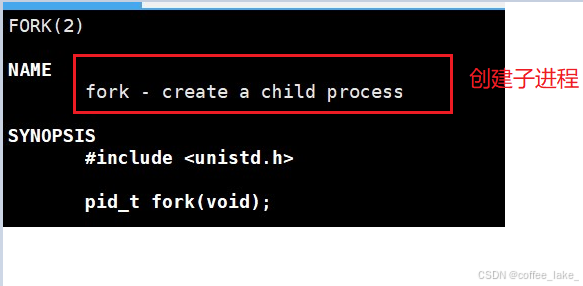
在 Linux 系统中,所有的进程都是由其父进程创建的,并且 Linux 系统中不存在母进程的概念,可以说 Linux 是一个单亲繁殖的系统。
下面我们通过编写一个代码示例来进一步理解:
我们运行一下这个代码:
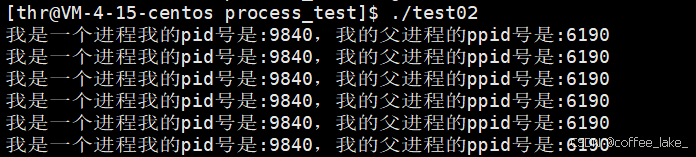
我们多次运行看看:

我们发现这个父进程的进程号一直是 6190 ,那么这个是什么进程呢?我们可以去查看一下:

我们发现这个父进程是一个 bash 进程,bash 是 Linux 中的命令行解释器。Linux 会为每个登录用户分配一个 bash 进程,这个 bash 进程本质上也是一个进程。它会先启动 printf 函数进行打印操作,然后再执行 scanf 函数。当我们向其中输入一些命令,比如 pwd、ls 等之后,输入的值会创建一个新的进程,用于提供 pwd、ls 等命令对应的服务,这些新进程都是由 bash 进程创建的。所以在这种情况下,bash 是父进程,pwd、ls 等命令对应的进程是子进程,我们自己编写并运行的程序也是如此。在 Windows 系统中,我们运行的应用程序的父进程一般是文件资源管理器。
那么进程是如何创建新进程的呢?
这就涉及到我们上面提到的 fork () 函数了。
我们来看一个具体的样例:
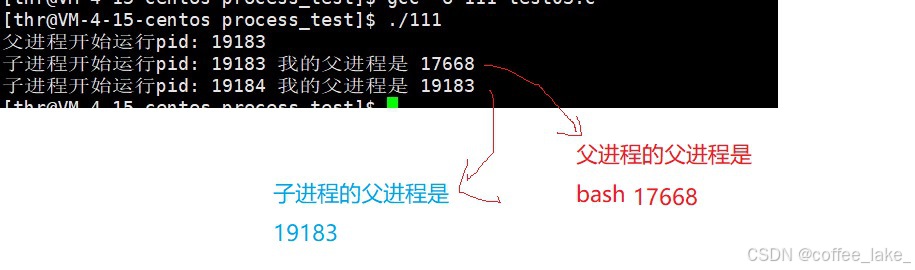

现在我们让子进程和父进程执行两个不同的代码逻辑。
我们来分析一下 fork 函数返回的值:

当 fork 函数执行成功时,父进程会得到子进程的 PID,而子进程会得到 0。
当 fork 函数执行失败时,父进程会得到 - 1,并且不会创建子进程,同时会返回一个错误码来指明失败的原因。
根据上面的返回值情况,我们来创建一个能够让子父进程执行不同代码的程序:
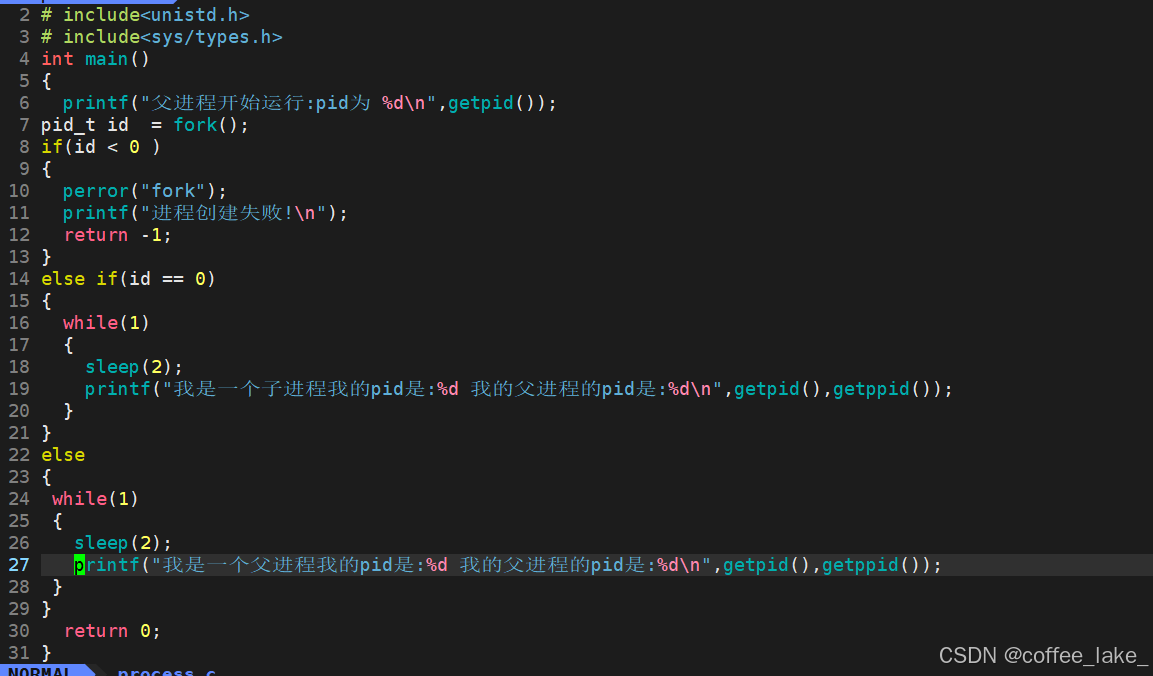
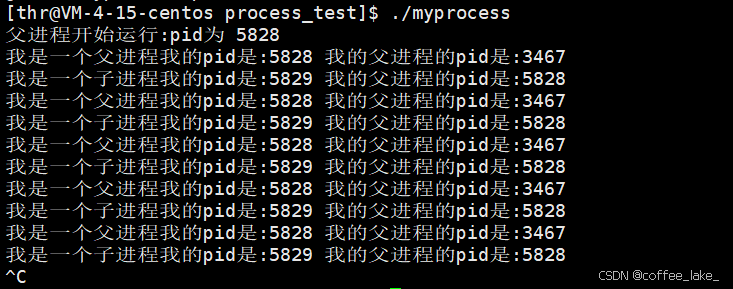
现在我们这个代码可以根据子父进程不同的返回值来执行不同的代码。
现在我们提出几个问题
- 为什么 fork 函数会给父子进程不同的返回值?
- 为什么一个函数能返回两次?
- 为什么一个变量既可以等于 0 又大于 0,从而导致 if - else 语句同时成立?
首先我们来回答第一个问题,我们需要明确一点,一个父进程可以创建多个子进程,即父进程和子进程的关系是 1:n(一对多的关系),而子进程只有一个父进程。fork 函数给父子进程不同的返回值,是为了让父进程和子进程能够在后续的代码中根据返回值来区分自己的身份,从而执行不同的代码逻辑。
然后我们来说第二个问题,我们通过画图来进一步理解:
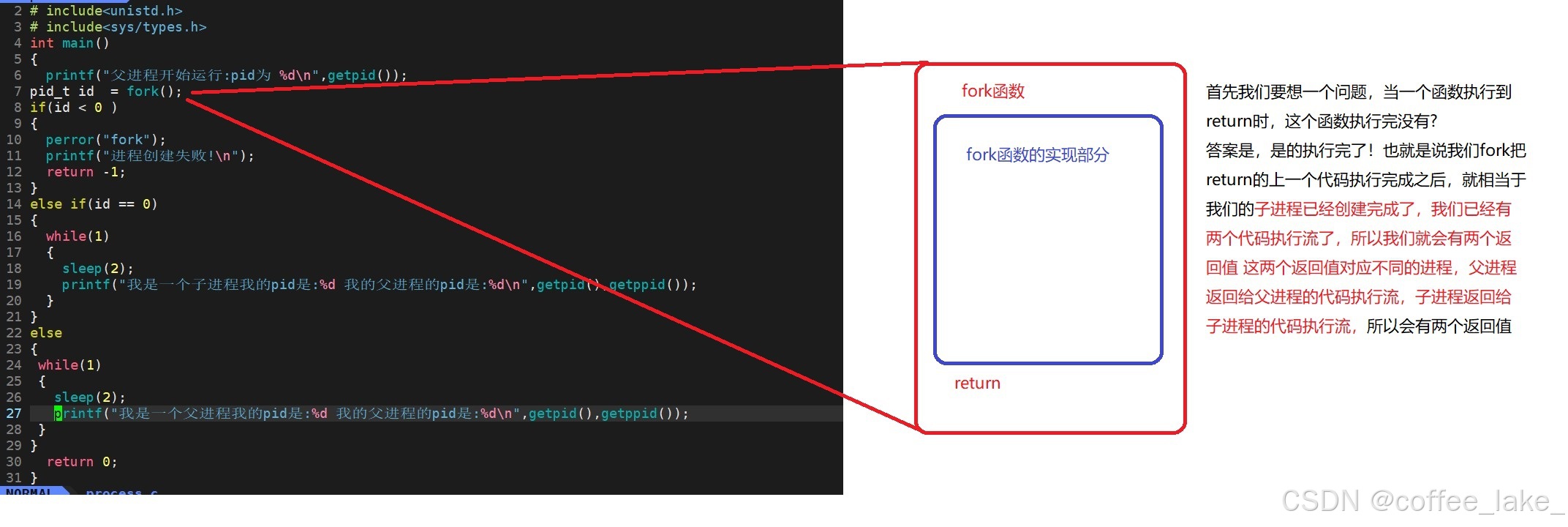
当调用 fork 函数时,操作系统会创建一个新的子进程。子进程会复制父进程的代码和数据空间。在 fork 函数执行的过程中,父进程和子进程都会从 fork 函数处继续执行后续代码。因此,从效果上看,fork 函数就像是返回了两次,一次是在父进程中返回子进程的 PID,一次是在子进程中返回 0。
对于第三个问题,我们先来谈谈 return 语句的本质。return 的本质是返回数据,当我们用一个变量来接收这个返回的数据时,就相当于修改了这个变量的值,也就是在对变量进行写入操作。
我们要知道,当子进程创建的时候,它会和父进程共享代码和数据。但是需要注意的是,代码是只读的。如果子进程或者父进程要修改数据,那么操作系统会在内存中拷贝一份数据供子进程或者父进程进行修改,而不会影响到其他进程,这个过程被称为写时拷贝。写时拷贝机制使得进程具有独立性,子父进程之间不会相互影响。就像我们上面的例子中,id 这个变量被父子进程进行写入操作时,操作系统会在内存中开辟两个空间,将变量值拷贝到这两个空间中,分别供父子进程使用。
所以,一个变量既可以等于 0 又大于 0,导致 if - else 语句同时成立,是因为在子进程和父进程中,变量的值分别在各自独立的内存空间中被修改,从而出现了不同的取值情况。
我们可以通过一个实验来验证一下:

通过上面的实验现象,我们可以看到修改子进程的数据并没有影响到父进程,这进一步证明了写时拷贝机制的存在以及进程的独立性。
via:
-
Linux 进程概念(精讲)_linux 进程 - CSDN 博客
https://blog.csdn.net/m0_58523831/article/details/120778444 -
【Linux 进程概念 —— 上】冯・诺依曼体系结构 | 操作系统 | 进程 | fork | 进程状态 | 优先级_while:;do ps ajx | head -1 && ps ajx | grep myproc-CSDN 博客
https://blog.csdn.net/wh128341/article/details/124602732 -
【Linux 进程概念 —— 下】验证进程地址空间的基本排布 | 理解进程地址空间 | 进程地址空间如何映射至物理内存 (页表的引出) | 为什么要存在进程地址空间 | Linux2.6 内核进程调度队列_linux c 进程空间篡改 - CSDN 博客
https://blog.csdn.net/wh128341/article/details/124797675 -
Linux 的进程优先级 NI 和 PR - 简书
https://www.jianshu.com/p/84b1f44706db -
Linux | 进程相关概念(进程、进程状态、进程优先级、环境变量、进程地址空间)-CSDN 博客
https://blog.csdn.net/TTKunn/article/details/145631564 -
Linux-- 进程(进程概念、PCB、进程状态、孤儿进程、进程优先级、进程切换、进程调度)_进程和线程 的 pcb 和 tcp-CSDN 博客
https://blog.csdn.net/cookies_s_/article/details/145692440 -
【Linux进程概念】—— 操作系统中的“生命体”,计算机里的“多线程”-CSDN博客
https://blog.csdn.net/bite_zwy/article/details/145648485 -
【Linux 进程状态】—— 从创建到消亡的全生命周期_linux进程生命周期-CSDN博客
https://blog.csdn.net/bite_zwy/article/details/145863781 -
【Linux 进程控制】—— 进程亦生生不息:起于鸿蒙,守若空谷,归于太虚-CSDN博客
https://blog.csdn.net/bite_zwy/article/details/147062981 -
task_struct 数据结构-CSDN博客
https://blog.csdn.net/jurrah/article/details/3965437 -
(linux 操作系统) 从冯诺依曼体系结构到初识进程 - CSDN 博客
https://blog.csdn.net/2302_80245587/article/details/146236096 -
Linux 进程 (进程概念、特征、状态、优先级、进程地址空间、环境变量)_linux 中进程的基本特征 - CSDN 博客
https://blog.csdn.net/weixin_50168448/article/details/113697415

















 2357
2357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









