







原url:http://cpmarkchang.logdown.com/posts/184192-python-nltk-sinica-treebank
以下为原文:
今天我們來談談如何用python nltk做中文的的自然語言處理
nltk有內建的中文treebank,是中研院的sinica treebank
是免費的中文treebank
至於要如何使用呢?
首先 先載入模組
>>> from nltk.corpus import sinica_treebank
>>> import nltk
接下來我們來看看treebank裡面的東西:
1.words, tags, sentence, tree:
>>> sinica_treebank.words()
['\xe4\xb8\x80', '\xe5\x8f\x8b\xe6\x83\x85', ...]其中’\xe4\xb8\x80’是以utf-8編碼的中文字
如果想知道它是什麼字,可以輸入print ‘\xe4\xb8\x80’, 輸出結果為”一”
再來是Tag和sentence
>>> sinica_treebank.tagged_words()
[('\xe4\xb8\x80', 'Neu'), ('\xe5\x8f\x8b\xe6\x83\x85', 'Nad'), ...]
>>> sinica_treebank.sents()[15]
['\xe5\xa4\xa7\xe8\x81\xb2', '\xe7\x9a\x84', '\xe5\x8f\xab', '\xe8\x91\x97']接下來,我們來看看如何印出tree的結構
>>> sinica_treebank.parsed_sents()[15]
Tree('VP', [Tree('V\xe2\x80\xa7\xe5\x9c\xb0', [Tree('VH11', ['\xe5\xa4\xa7\xe8\x81\xb2']), Tree('DE', ['\xe7\x9a\x84'])]), Tree('VE2', ['\xe5\x8f\xab']), Tree('Di', ['\xe8\x91\x97'])])結果印出來了,但看起來結構不清楚的樣子
沒關係,可以試試看用圖形介面呈現
>>> sinica_treebank.parsed_sents()[15].draw()執行這行時會跳出一個視窗,如下:
這樣就可以很清楚地把樹狀結構呈現出來了
但如果你執行這行會有error出現
請先安裝python-tk
https://wiki.python.org/moin/TkInter
2.concordance:
concordance的作用就是找某個字的前後文,例如要找”我”這個字的前後文,用法如下:
>>> sinica_text=nltk.Text(sinica_treebank.words())
>>> sinica_text.concordance('我')
Displaying 25 of 724 matches:
我 住在 同一條 巷子 我們 是
�� 一起 回家 有一天 上學 時 我 到 她 家 等候 按 了 門鈴 卻
��鈴 卻 沒有 任何 動靜 正當 我 想 離開 時 門 內 突然 傳來
�� 了 門 大聲 的 叫 著 快 點 我 媽媽 暈倒 了 嘉珍 抓起 我
� 我 媽媽 暈倒 了 嘉珍 抓起 我 的 手 急忙 往 屋 裡 跑 進入
......以下省略
若以上程式因為編碼的error而跑不出結果,可以試試
sinica_text.concordance(u’我’.encode(‘utf-8’))
3.frequency distribution:
frequency distribution就是計算字詞在語料庫中出現的頻率
如果要計算前一百個常出現的字詞,可以這樣寫
>>> sinica_fd=nltk.FreqDist(sinica_treebank.words())
>>> top100=sinica_fd.items()[0:100]
>>> for (x,y) in top100:
>>> print x,y
的 6776
、 1482
在 1331
是 1317
了 1190
有 759
我 724
他 688
就 627
......以下省略
結語:
以上是很粗淺的python nltk sinica treebank介紹
至於treebank還有什麼用呢?
用途實在太多了,在此說不完
請參考自然語言處理(Natural language processing)相關領域的教科書
以下为测试代码:
# -*- coding:utf-8 -*-
# __author__ = 'Janvn'
# 2015/08/18
import nltk
from nltk.corpus import sinica_treebank
'''
#显示中文
words=sinica_treebank.words()
for word in words:
print word.encode('gbk'),
'''
'''
#nltk中文词性标注
sinica_text=nltk.Text(sinica_treebank.words())
print sinica_text
for (key,var) in sinica_treebank.tagged_words()[:8]:
word_tag='%s/%s' % (key,var)
print word_tag.encode('gbk'),
'''
'''
#nltk中文句法树
sent=sinica_treebank.sents()[15]
print sent
for word in sent:
print word.encode('gbk'),
parse_sent=sinica_treebank.parsed_sents()[15]
print parse_sent
parse_sent.draw()
'''
'''
#搜索中文文本
sinica_text=nltk.Text(sinica_treebank.words())
sinica_text.concordance(u'我') #查找关键字
'''
#nltk计算中文高频词,测试的时候貌似只计算了词频,却没得到前100个高频词?why,why,why?
sinica_fd=nltk.FreqDist(sinica_treebank.words())
top100=sinica_fd.items()[0:100]
for (x,y) in top100:
print x,y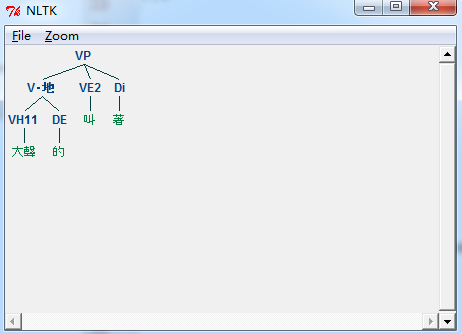















 398
398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









