








Linux Environment
理想情况下,上一节中提到的所有内容现在都应该在 Linux 操作系统的上下文中重复。 然而,事实是 Linux 上的 .NET 在 2018 年仍然非常新鲜。初始生产部署才刚刚开始出现。 因此,该平台上的开发才刚刚开始显现。 由于这是一个全新的领域,因此与 Windows 环境相比,在知识和良好实践的建立方面存在巨大差异。 正如我们所见,在 Windows 中,有许多不同的工具可用:免费的和商业的。 就 Linux 而言,这种选择实际上并不引人注目。 该领域没有标准程序,甚至没有真正经验丰富的专家。 我们正在进入未受破坏的地区。
概述
Linux 的兴起和发展是开源社区无数贡献者的非凡创造。 它并不是像 Windows 操作系统那样从一开始就由一家公司设计和实现。 某些领域缺乏严格的标准化也就不足为奇了。 其中一个方面是监控和跟踪我们特别感兴趣的应用程序。有许多可用的机制; 其中一些正在慢慢失去人气,而另一些则刚刚开始流行。 在这种情况下,Linux 中的监控基础设施变得不如 Windows 环境中的同质化。
没有在所有发行版和系统内核中使用的广泛接受的诊断跟踪标准。 将 CoreCLR 迁移到 Linux 环境时,必须决定使用什么机制。 它在 https://github.com/dotnet/coreclr/blob/master/Documentation/coding-guidelines/cross-platform-performance-and-eventing.md 的 CoreCLR 文档中有详细记录。 例如,还考虑了其他机制,如 SystemTap、DTrace4Linux、FTrace 和扩展伯克利数据包过滤器 (eBPF)。
目前,以下机制在不同级别上使用:
-
.NET 应用程序 - 与 Windows 一样,我们可以使用 EventSource 库或显然任何其他库来直接登录到文件和许多其他可能的目标,
-
NET Core 运行时 - 发出 LTTng(“下一代 Linux 跟踪工具包”)事件,
-
操作系统 API 和内核本身 - 发出所谓的 perf_events 数据。
最后,为了更好地了解 Linux 上的 CoreCLR 流程,应结合使用两种机制:
-
perf_events - 它提供基于硬件和软件(包括操作系统库和内核本身)的各种数据。 这包括系统范围的测量,例如 CPU 采样、上下文切换、内存使用情况。
-
LTTng - 用户模式端的事件跟踪,但具有内核大小的模块和缓冲区。 它提供强类型事件,因此与 Windows 事件跟踪 (ETW) 非常相似。 不幸的是,默认情况下它不支持跟踪堆栈跟踪(程序已重新编译以启用或禁用它们,这不适用于像 CoreCLR 这样的通用框架)。 此处使用与 Windows 上的 ETW 事件相同的事件名称。
虽然 perf_events 是系统范围的,但 LTTng 机制可以连接到各个进程。
请查找表 3-3,它可以帮助您了解 Windows 和 Linux 中跟踪机制之间的异同。
表 3-3。 Linux 和 Windows 跟踪机制比较
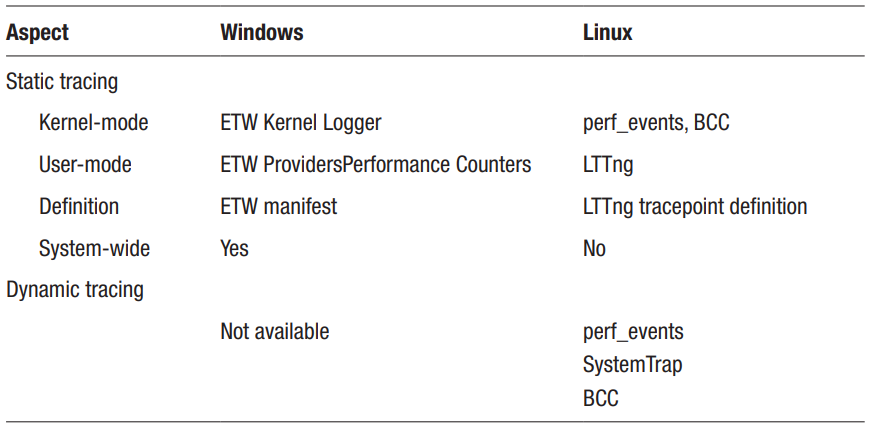
最显着的区别是 Windows 中缺乏动态跟踪机制。 动态跟踪是指您可以在应用程序运行时启用或禁用单函数调用跟踪。
Perfcollect(性能收集)
获取跟踪数据的最简单方法是使用官方的 perfcollect bash 脚本,然后使用 Windows 上的 Perfview 来分析记录的数据。 这种方法有一些缺点。 主要的一个是 PerfView 中可用的分析结果相当有限 - 只有可用的事件的原始列表。 第二个不太麻烦的问题是 Windows 需要…分析 Linux 数据。
要开始监控 .NET Core 应用程序,请按照 https://github.com/dotnet/coreclr/blob/master/Documentation/project-docs/linux-performance-tracing.md 上的官方 CoreCLR 说明进行操作。 这并不复杂。 您应该从 CoreCLR Github 存储库(http://aka.ms/perfcollect)获取 perfcollect 脚本。 然后你只需要执行 sudo ./perfcollect install,这将在你的 Linux 机器上安装 perf_event 和 LLTng 工具。 然后,要启动跟踪会话,您需要导出两个环境变量(第一个环境变量可以生成所谓的解码映射,需要从记录的跟踪中解码符号,该映射将存储在 /tmp/perf-PID.map 中),如图所示 如清单 3-10 所示。
清单 3-10。 设置 CoreCLR 监控所需的环境变量
> export COMPlus_PerfMapEnabled=1
> export COMPlus_EnableEventLog=1
> sudo ./perfcollect collect sampleTrace [-pid <PID>] [-threadtime]
停止会话后,将生成一个包含注册数据的 ZIP 文件。 perfcollect 脚本到底有什么作用? 简而言之,它管理会话并准备结果文件:
- 它配置 LTTng 会话:
- 上下文由 procname、vpid(进程 ID)和 vtid(线程 ID)组成
- 默认情况下,从 DotNetRuntime:* 和 DotNetRuntimePrivate:* 组添加的所有事件(我们可以在脚本本身中看到详细列表和可用设置)
- 它启动 LTTng 会话
- 它启动 perf 会话,每 1 ms 采集一次 CPU 样本(频率为 999 Hz)
- 它会准备包含所有必要数据的结果 ZIP 文件:
- lttngTrace 子文件夹包含记录的 LTTng 跟踪
- 主文件夹包含:
- 会话期间创建的所有 perf.map 文件
- 借助 crossgen 工具为本机映像 (AOT/NGEN) 生成的所有符号文件
- 所有性能数据和相关日志
- debuginfo 子文件夹 - 包含所有其他模块的 debuginfo(符号文件)
记录会话后,我们还可以使用 perfcollect 脚本查看它(参见清单 3-11)。
清单 3-11。 查看 perfcollect 数据
> sudo ./perfcollect view <tracefile>
> sudo ./perfcollect view <tracefile> -viewer lttng
第一个命令将性能数据显示为调用树,第二个命令只是所有 LTTng 事件的文本列表,没有任何解释。
当然,您可以手动管理 LTTng 会话(即在 perfcollect 中编写的脚本),以更好地控制创建的会话和记录的事件(参见清单 3-12)。
清单 3-12。 手动管理 LTTng 会话
> lltng create sample_trace
> lltng add-context --userspace --type procname // or vpid, vtid
> lltng enable-event --userspace --tracepoint DotNetRuntime:Exception*
> lltng enable-event --userspace --tracepoint DotNetRuntime:GC*
> lltng start
> lltng stop
> lltng destroy
同样,您可以手动管理 perf_events 来创建 perf 会话(参见清单 3-13)
清单 3-13。 手动管理 perf 会话
> perf record -g -F 999 --pid=<PID> -e cpu-clock
这将启动一个带有调用图记录(-g 选项)的会话,并以 999 Hz 频率采样,这实际上意味着每 1 毫秒(-F 999 选项)。
Trace Compass(追踪指南针)
正如该工具主页所述:“Eclipse Trace Compass 是一个开源应用程序,用于查看和分析任何类型的日志或跟踪。 它的目标是提供视图、图表、指标等,以帮助从跟踪中提取有用的信息,其方式比巨大的文本转储更加用户友好且信息丰富。”
在各种支持的格式中,对我们来说最重要的是CTF格式(Common Trace Format),其中事件由CoreCLR使用的LTTng机制生成。 Trace Compass 看起来像是 PerfView 和 Windows 性能分析器工具的混合体 - 如果您接触过它们,您可能会猜到我的意思。 它很强大,可以让我们创造伟大的事物。 但不幸的是,就像上面提到的两个程序一样,它的学习曲线非常陡峭。 大量的配置选项使您第一次运行它时很难知道从哪里开始。 如果您对 Linux 诊断不感兴趣,或者只是不想花时间阅读 Trace Compass 适应我们需求的相当详细的描述,请暂时忽略本子章节的其余部分。
省略。。
概括
在这一章中,我们回顾了在 .NET 内存管理分析环境中有用的各种工具——无论是从诊断方面还是从监视方面。 不可避免地,这只是一个简短的回顾,而没有深入每个服务工具的细节。 尽管如此,该章节的规模仍然相当大。 Windows操作系统上运行的工具很多,Linux操作系统上运行的工具较少。 大多数情况下,这些程序都不是简单的程序,它们的手册是单独的专门书籍的主题。 我强烈建议您在日常工作中使用这些工具,并将本章中包含的列表作为进一步探索的起点。 下载并尝试它们。 当然,您会比其他人更喜欢其中一些。
作为一点帮助,请在表 3-4 和 3-5 中找到迄今为止提到的工具的简短摘要。
表 3-4。 适用于 Windows 的 .NET 相关工具摘要。
| 工具 | 目的 | 优点和缺点 |
|---|---|---|
| Performance monitor | 性能计数器查看器。 记录并可视化性能计数器数据。 | + 易于使用 + 低开销 - 有时可能会产生误导 |
| Windows Performance Toolkit | 记录并直观地分析 ETW 数据。 主要侧重于 Windows/驱动程序分析。 | + 非常强大 + 可能的低开销 - 陡峭的学习曲线 |
| Perfview | 借助许多预定义视图记录和分析 ETW 数据。 主要关注.NET相关分析。 | + 对于.NET 非常强大 + 可能的低开销 - 陡峭的学习曲线 |
| ProcDump, DebugDiag | 获取进程的内存转储。 无论是临时的还是基于各种指标。 | + 易于使用 |
| WinDbg | 调试托管代码和本机代码。 借助强大的扩展,提供了广泛的分析可能性。 | + 对可能的过程的非常低水平的洞察 - 非常陡峭的学习曲线 - 对于许多日常用途来说可能水平太低 |
| dnSpy | 即使源代码不可用,也可以编辑和调试 .NET 程序集。 | |
| BenchmarkDotNet | 基准测试库允许我们对 .NET 代码的执行时间和资源利用率进行基准测试。 | |
| Visual Studio (commercial) | 众所周知的通用 IDE。 包括调试、分析和内存转储分析功能。 | + .NET 开发人员众所周知 - 与其他专用商业工具相比,分析和转储分析略有限制 |
| Scitech .NET Memory Profiler (commercial) | 专用于 .NET 内存分析的工具。 | + 易于使用的用户界面 + 许多预定义的分析 - 付费工具 |
| JetBrains DotMemory (commercial) | 同上 | 同上 |
| RedGate ANTS Memory Profiler (commercial) | 同上 | 同上 |
| Intel VTune Amplifier and AMD CodeAnalyst Performance Analyzer | 本机代码和托管代码的硬件级分析,包括深入了解缓存利用率、CPU 管道利用率等。 | + 对硬件性能的非常深入的了解 - 对于许多典型场景来说可能过于详细 - 至少需要一些基本的硬件知识 |
| Dynatrace & Appdynamics (commercial) | 持续监控工具,包括收集 .NET 相关数据(取决于工具) | + 对正在运行的应用程序的深入洞察 - 付费工具 |
| Perfcollect | 用于收集和简单查看 LLTng 和性能数据的脚本。 | + 帮助配置 LLTng 和 perf 会话 - 分析非常有限 |
| Trace Compass | 记录并直观地分析 LLTng 数据。 创建用于通用分析,并且可以针对 .NET 相关事件进行调整。 | + 相当强大的可视化 - 需要大量定制 - 陡峭的学习曲线 |
| lldb | 本机调试器通过 sos 扩展具有托管代码调试功能。 | + 对流程的深入了解可能 - 陡峭的学习曲线 |
| Intel VTune Amplifier 和 AMD CodeAnalyst 性能分析器 | 请参阅 Windows 对应项的说明。 |
本章介绍的一些工具将在本书后面使用来向您展示所讨论的主题。 这就是为什么在我们实际使用它们之前展示它们是如此重要。 稍后我们将有机会在不同的情况下进行练习。 由于我们还没有介绍有关 .NET 中 GC 的任何详细信息,因此在本章中讨论具体的诊断问题还为时过早。 后面还会用到一些其他的小工具,这里就不说了。 如果在这里一一列举的话就太宽泛了。
您刚刚阅读的前三章是对内存管理的一般介绍。 在第一章中,我们了解了有关该主题的许多理论概念。 在第二章中我们学习了它的硬件和系统细节。 现在我们将在关于可用工具的第三章中结束这一广泛的介绍。 我们将进入正确的部分,描述 .NET 本身、其内部结构和常见的最佳实践。 我邀请你来阅读!
规则 5 - 尽早测量 GC
理由:持续监控不同的指标可以回答“我们是否有内存问题?”的问题。 从我们应用程序存在的一开始。 更重要的是,我们可以观察揭示流程性能下降的趋势。 当然,这个原则足够普遍,不仅适用于 GC 环境。 同样,我们应该衡量整体性能(例如响应时间)或同步问题(例如上下文切换数量)等。
如何应用:从较低环境的首次部署到生产环境的持续监控,尽早养成测量GC参数的习惯很重要。 因为它更多的是概念性的而不是实际的建议,所以如何使用它的答案可能非常广泛。 毫无疑问,目标应该是,最好是自动连续监控应用程序的内存使用情况和 GC 操作。 本书中列出的其他规则应该是创建此过程的起点。 感谢他们,我们将知道要测量什么以及如何解释结果。 这个过程的外观在很大程度上取决于我们使用什么工具。 对于 Windows,大多数情况下测量将基于相关性能计数器的读数(第 3.2 节)或循环 ETW 事件分析(第 3.3 节)。 对于 Linux,它将自动分析 perf_events 和 LTTng 数据。 此类自动检查可以集成到我们的持续集成和交付流程中,例如在每次构建新产品版本之后。 绝对最低限度的方法应该是手动监控每次生产部署后选择的指标,并将它们与以前版本的行为进行比较。 我们应该衡量什么? 你的旅费可能会改变。 这完全取决于我们监控过程的严重程度。 但我无法想象一个经过深思熟虑的系统不衡量我们应用程序的以下功能:
- 我们的进程中有多少内存并且不会随着时间的推移而失去控制;
- 垃圾收集器被调用的频率和时间以及整个过程是否有明显的开销。














 118
118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









