






Facebook开源的Segment Anything是一个基于大型预训练模型的计算机视觉工具,它使用一种新的范式来处理图像分割任务。这个范式不依赖于传统的预训练加微调(pretrain+finetune)方法,而是通过提示(prompt)加上预训练的基础模型(foundation model)来实现。Segment Anything的目标是能够处理包括交互式分割、边缘检测、超级像素化、目标提议生成、前景分割、语义分割、实例分割、全景分割等多种计算机视觉领域的任务1。
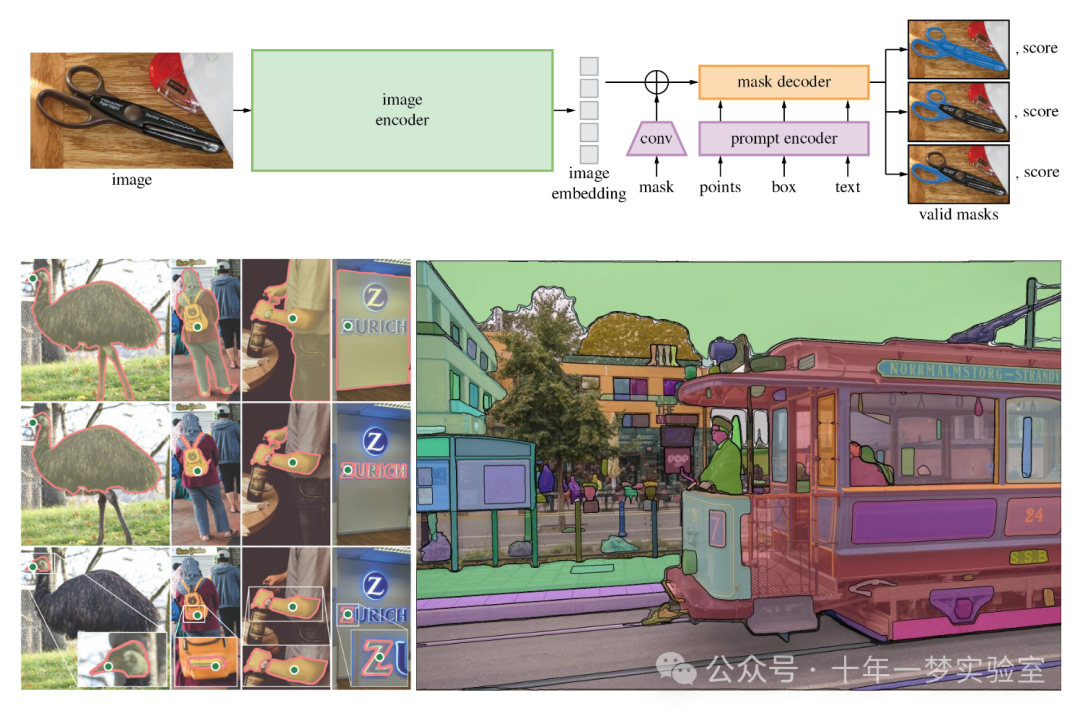
Segment Anything模型(SAM)的架构主要包括三个部分:
图像编码器:使用标准的ViT(Vision Transformer)作为图像编码器,将原始图像编码成向量。
提示编码器:将支持的提示内容编码成向量。
掩码解码器:输出原图尺寸上的前后景概率以及IoU分数。
SAM模型通过构造合适的提示,可以实现对新样本的零样本(zero-shot)能力,这意味着它可以在没有额外训练数据的情况下处理新的图像类型。例如,通过提供一个点或边界框作为提示,SAM能够生成与之相关的图像分割掩码。这种方法的优势在于它可以灵活地应用于各种不同的分割任务,并且具有很强的泛化能力。
此外,Facebook还发布了与Segment Anything配套的数据集,这是一个非常大的图像注释数据集,包含超过11亿个分割掩码,这些掩码具有高质量和多样性。这个数据集被称为Segment Anything 1-Billion (SA-1B),它可以帮助研究人员训练图像分割的基础模型2。
总的来说,Segment Anything代表了计算机视觉领域的一个重要进展,它将NLP领域的提示范式引入到计算机视觉中,为图像分割任务提供了一种新的解决方案。这个工具的开源性质也意味着它可以被广泛地应用于学术和工业界的研究中。
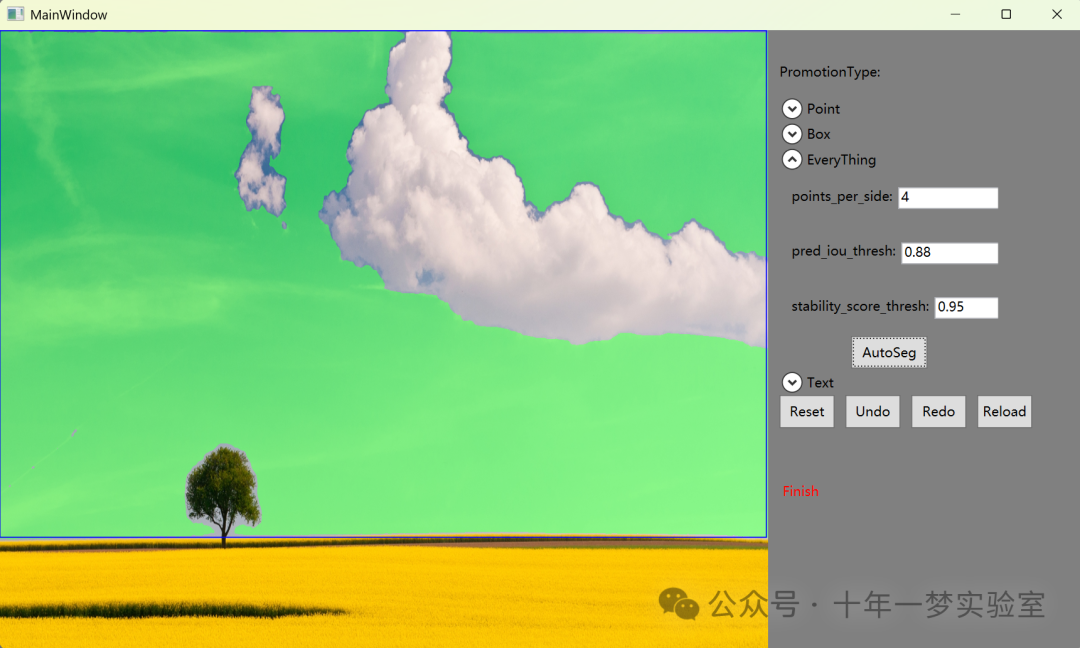
CSharp ONNX 推理
点Promot:展开Point栏,点击AddPoint后,鼠标点击左侧图像选择点。Add Mask表示正向点,Remove Mask表示负向点。

Box Promot: 展开Box栏,点击AddBox后,鼠标点击左侧图像选择起始点,易懂鼠标改变Box大小。

AutoSeg:自动分割,展everythin栏,设置阈值,根据points_per_side值在图像上均匀选择候选点,每个点都作为promot,然后根据阈值对结果后处理。
参考网址:
https://github.com/facebookresearch/segment-anything/
https://github.com/AIDajiangtang/Segment-Anything-CSharp
https://github.com/AIDajiangtang/Segment-Anything-CSharp/releases/download/v1.0.1/ONNXModels.zip

















 2284
2284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









